TDH Inceptor计算源用于绑定Dataphin项目空间与TDH Inceptor,为Dataphin项目提供处理计算任务的计算源。如果Dataphin系统的计算引擎设置为TDH Inceptor,则只有项目空间添加了TDH Inceptor计算源,才支持规范建模、即席查询、Hive任务、通用脚本等功能。本文为您介绍如何新建TDH Inceptor计算源。
前提条件
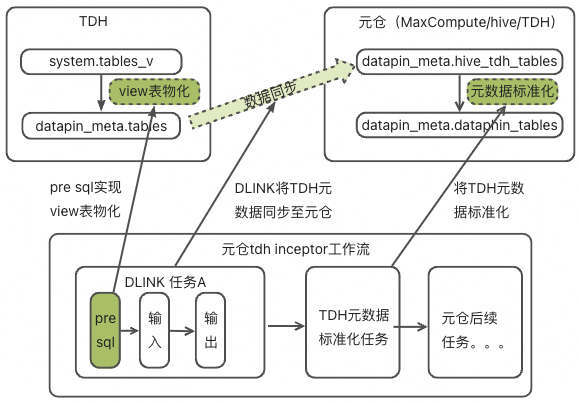
若以TDH Inceptor作为元仓,或元仓初始化中的元数据库配置使用TDH Incepor作为元数据库获取方式时,需要具备以下条件:
已在TDH Inceptor中创建dataphin_meta的项目。
元仓初始化中TDH Inceptor配置的用户,需具备dataphin_meta项目的写入表及创建表的权限。
客户引擎的账号需要有对dataphin_meta项目的物化表有读取的权限。
使用限制
不支持自定义函数(UDF):由于添加同名JAR包用于UDF注册,可能会导致Inceptor服务终止且无法重启成功;添加非同名的JAR包,但包含相同的CLASS文件,可能导致UDF执行结果不可预测。因此在TDH Inceptor引擎下,Dataphin不允许注册UDF。若需要添加UDF,您可以通过TDH Inceptor的客户端进行添加,但需要注意:
集群的UDF名称的唯一性及类名的一致性。
UDF JAR包中不应包含Hive开头的任何JAR包。
在UDF工程中,手动添加Hive等JAR包依赖时,需要保证添加的依赖包来自于运行此UDF JAR包的集群。
通过MySQL元数据库获取元数据信息时,不支持获取:
全景、数据板块、项目的数据量信息。
资产目录中表数据量、分区数据量、分区记录数。
资源治理的存储相关的指标信息。
元仓共享模型和 dim_dataphin_table及dim_dataphin_partition中的数据量和记录数。
通过TDH Inceptor System库获取元数据信息时,不支持获取:
资产目录的分区记录数信息。
元仓共享模型和 dim_dataphin_table及dim_dataphin_partition中的记录数。
注意事项
TDH Inceptor引擎不支持任务的优先级设置。如果需要分配不同的资源给不同优先级的任务,您可以给不同的优先级队列设置不同的用户名。在Inceptor SQL任务上设置不同的优先级后,Dataphin会将这些任务用对应的用户提交到TDH Inceptor引擎中。需要注意的是这里设置的用户需要有Incetpor资源队列的Submit权限。
关于如何设置Incetpor用户权限及Inceptor资源调度,请参见Inceptor使用手册。
操作步骤
请参见数仓规划入口,进入数仓规划页面。
在Dataphin首页,单击顶部菜单栏的规划。
按照下图指引,进入新建计算源页面。
在新建计算源页面,配置参数。
配置计算引擎源基本信息区域的参数。
参数
描述
计算源类型
选择计算源类型为TDH Inceptor。
计算源名称
命名规则如下:
只能包含汉字、数字、字母、下划线(_)和短划线(-)。
长度不能超过64字符。
计算源描述
对计算源的简单描述。
配置集群基本信息区域的参数。
参数
描述
nameNode
默认为初始化系统时配置的NameNode参数值,不支持修改。
配置文件
上传HDFS配置文件core-site.xml和hdfs-site.xml。
您可以联系星环运维人员或登录星环集群运维界面后,依次选择HDFS服务更多操作下载服务配置获取此文件。
认证方式
如果TDH Inceptor集群有Kerberos认证,则此处认证方式需要选择为Kerberos。Kerberos是一种基于对称密钥技术的身份认证协议,可以为其他服务提供身份认证功能,且支持SSO(即客户端身份认证后,可以访问多个服务,例如HBase和HDFS)。
选择了Kerberos认证后,需要上传Krb5认证文件或配置KDC Server地址:
Krb5认证文件:需要上传Krb5文件进行Kerberos认证。
KDC Server地址:KDC服务器地址,辅助完成Kerberos认证。支持配置多个KDC Server服务地址,使用英文逗号(,)分割。
配置HDFS连接信息区域参数。
参数
描述
执行用户名、密码
登录计算执行机器用户名和密码,用于执行MapReduce任务、读取写入HDFS读存等。
重要请确保有提交MapReduce任务的权限。
认证方式
您如果HDFS有Kerberos认证,则此处认证方式需要选择为Kerberos。Kerberos是一种基于对称密钥技术的身份认证协议,可以为其他服务提供身份认证功能,且支持SSO(即客户端身份认证后,可以访问多个服务,例如HBase和HDFS)。
选择了Kerberos认证后,需要上传Keytab File认证文件及配置Principal地址:
Keytab File:需要上传Keytab File文件进行Kerberos认证。
Principal:对应的Kerberos认证用户名。
选择了无认证后,需要配置访问HDFS的用户名。
配置Inceptor配置区域的参数。
参数
描述
JDBC URL
配置Hive Server的连接地址,格式为
jdbc:hive2://{连接地址}:{端口}/{数据库名称}。认证方式
选择Inceptor的认证文件。您需要根据引擎情况进行选择,支持选择无认证、LDAP、Kerberos:
无认证:即没有认证。
LDAP:需要配置访问的用户名和密码。
Kerberos:您需要上传HDFS Kerberos认证的文件及配置Hive Principal。
开发环境任务的执行用户
配置开发环境的任务的执行用户名。
周期性调度的任务的执行用户
配置周期性调度任务的执行用户名。
优先级任务队列
支持选择采用默认执行用户和自定义两种方式优先级执行的用户。
选择了自定义后,您需要配置不同优先级执行任务的用户名。
说明优先级队列是通过在Hadoop集群上创建不同的Yarn队列来分配资源。对应不同的任务的优先级,把相关的优先级的任务发送到对应的Yarn的队列来执行。
配置Hive元数据连接信息区域的参数。
参数
描述
数据库类型
选择Inceptor的元数据库类型。系统支持选择MySQL 5.6/5.7、MySQL 8、MySQL 5.1.43。
JDBC URL
填写对应元数据库的连接地址,格式为
jdbc:postgresql://{连接地址}:{端口}/{数据库名称}。用户名、密码
填写登录元数据库的用户名和密码。
单击测试连接,测试连接的计算源。
测试连接成功后,单击提交。
后续步骤
完成创建TDH Inceptor计算源后,即可为项目绑定TDH Inceptor计算源,请参见创建通用项目。
- 本页导读 (0)