Dataphin支持对开发的实时任务代码进行数据采样或者手动上传并进行本地调试或Session集群调试,以帮助您保障代码任务的正确性,避免人为错误或遗漏。本文将为您介绍如何调试实时任务。
调试方式说明
本地调试方式:即不通过集群进行调试,调试的数据非流式数据。该方式调试速度较快,但操作较为繁琐,需要手动上传或填写数据,仅支持特定的数据源进行自动采样。
Session集群调试方式:即通过Session集群进行调试,调试的数据为线上的真实数据且为流式数据(即来源表中写入数据时,将直接输出该条数据的计算结果,与真实线上运行任务的结果一致)。该方式下,Session集群提供Flink任务状态、日志和输出结果的实时查看功能,您可以通过观察任务的行为和输出来验证任务的正确性。以支持您迭代式地修改和调试任务代码,以便快速定位和解决问题。
说明Session集群调试方式的调试结果不会写入结果表中。
使用限制
Blink仅支持引擎版本3.6.0及以上进行本地调试。
不支持DataStream任务进行调试。
Session集群调试方式当前仅支持开源Flink引擎且基于最新架构部署的客户,详情请联系产品运维团队。
调试任务操作入口
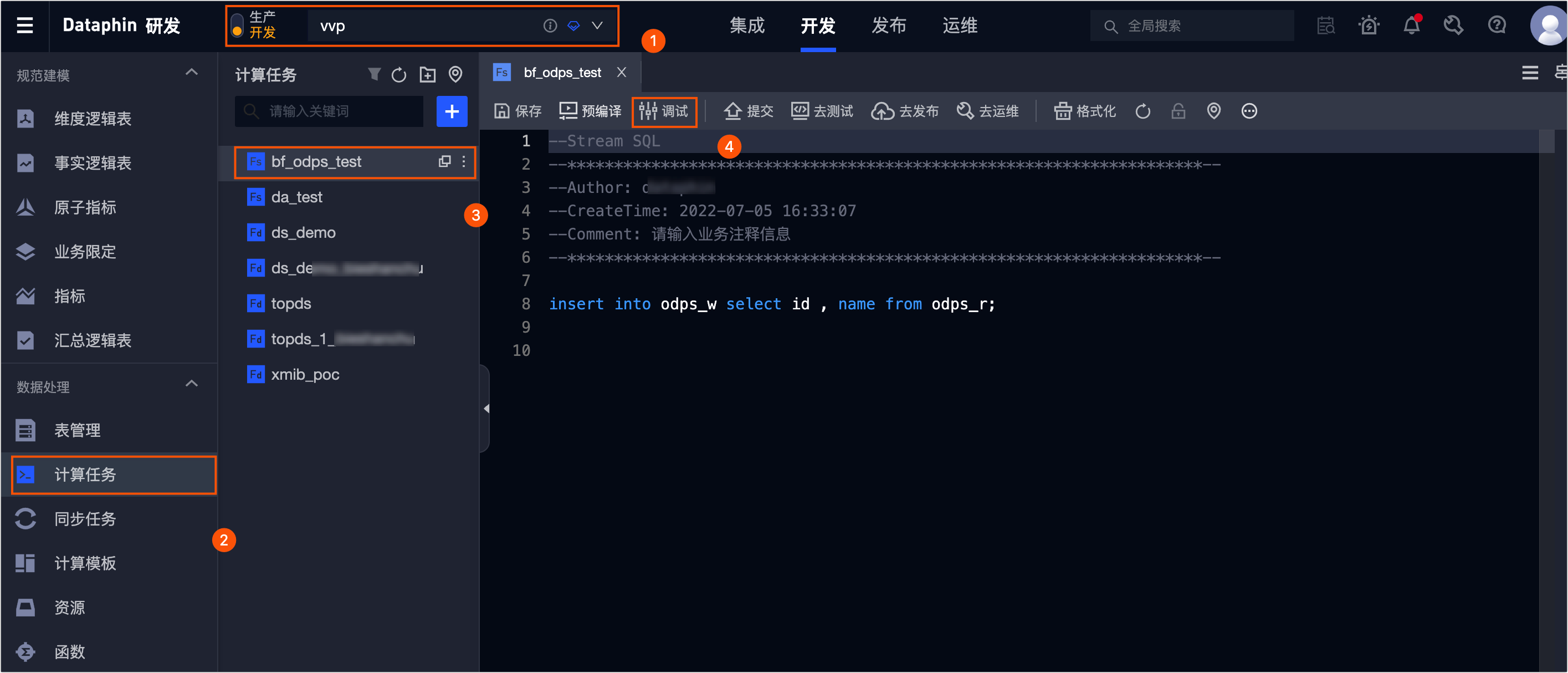
实时模式调试
在调试配置对话框的选择采样模式页签中,选择实时模式-FLINK Stream任务。
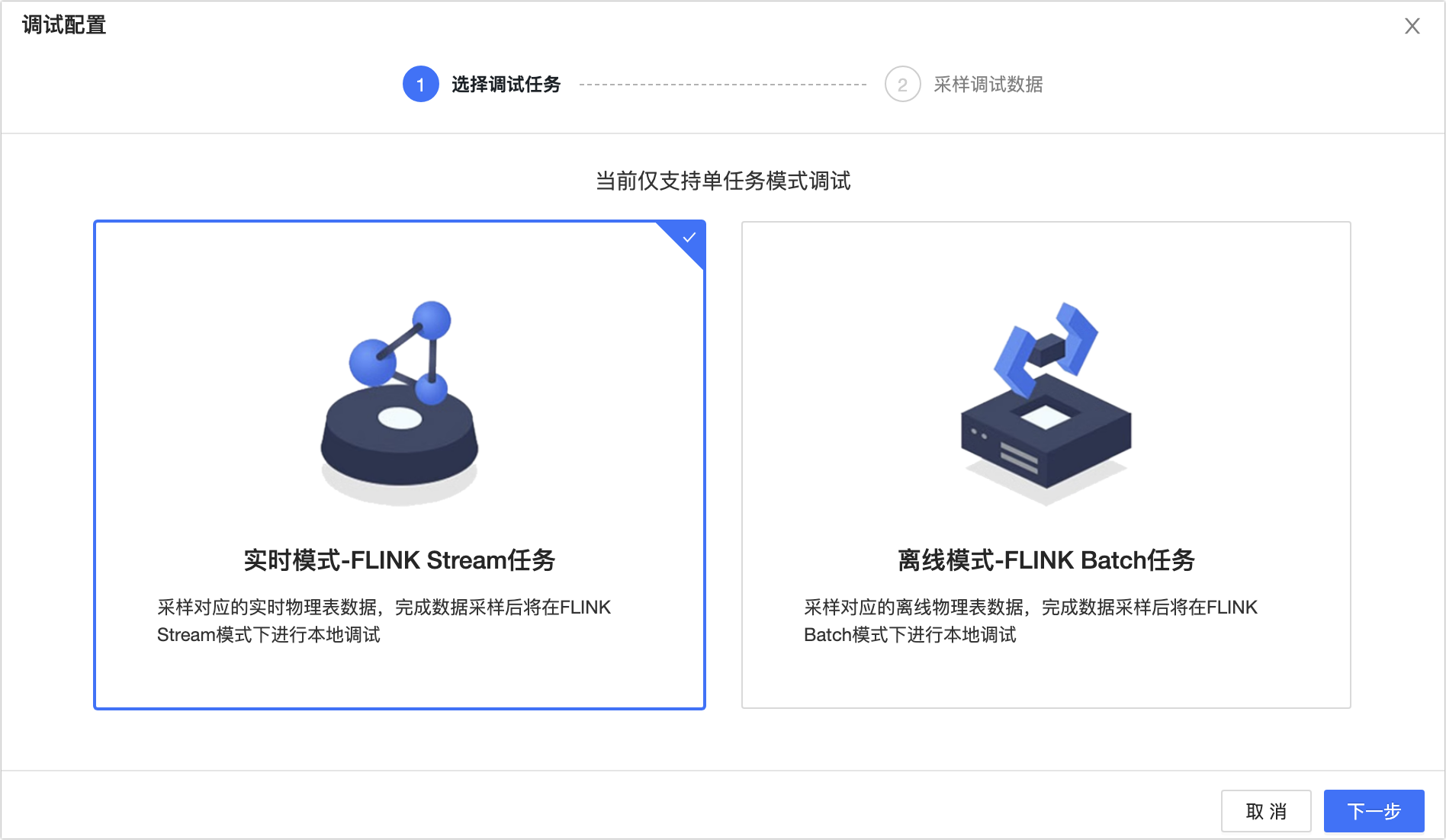
单击下一步。
在调试配置对话框中,选择调试数据来源。
手动上传数据(本地调试方式)
即通过本地调试方式手动上传数据进行调试。上传数据方式包括手动上传样例数据文件、手动输入数据、自动抽样数据。
手动上传样例数据文件
您可以通过上传数据的方式,手动上传本地数据。上传本地数据前需要先下载样例,样例由Dataphin自动识别读写的表和表的schema信息生成的csv格式样例模板,您可根据下载的样例编辑需要上传的数据,单击上传后,数据自动填充至元数据采样区域。
手动输入数据
适用于采集的数据比较少,或者需要修改已采集到的数据的场景。
自动抽样数据
自动抽样到的数据是随机的,所以适用于对采集到的数据没有限制的场景。针对HBase、MySQL、MaxCompute、DataHub、Kafka数据源支持自动抽样数据,您可以单击自动抽样,进行抽样数据。
说明Kafka中支持json、csv、canal-json、maxwell-json、debezium-json数据格式的自动抽样。
Kafka自动抽样仅支持无认证和用户名+密码认证方式,不支持SSL。
Kafka自动抽样时,支持选择读取数据范围,最大抽样条数为100条。
完成所有数据表的元数据采样后,单击的确定。
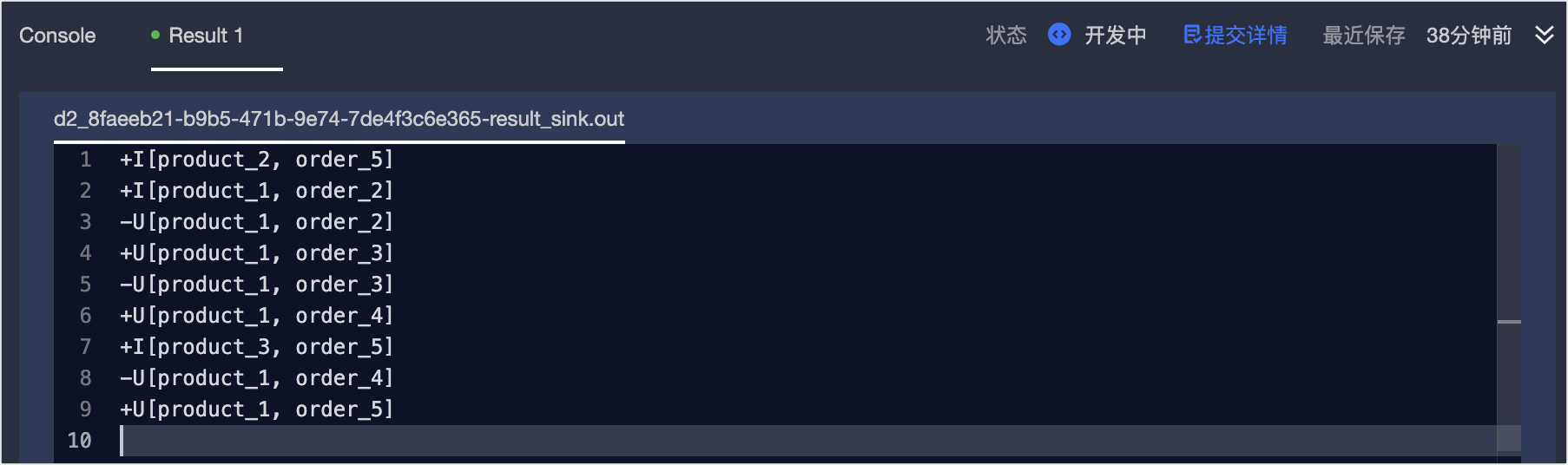
在Result页面,即可查看调试结果。
手动上传数据(本地调试方式)

采集线上数据(Session集群调试方式)
离线模式调试
在调试配置对话框的选择采样模式页签中,选择离线模式-FLINK Batch任务。
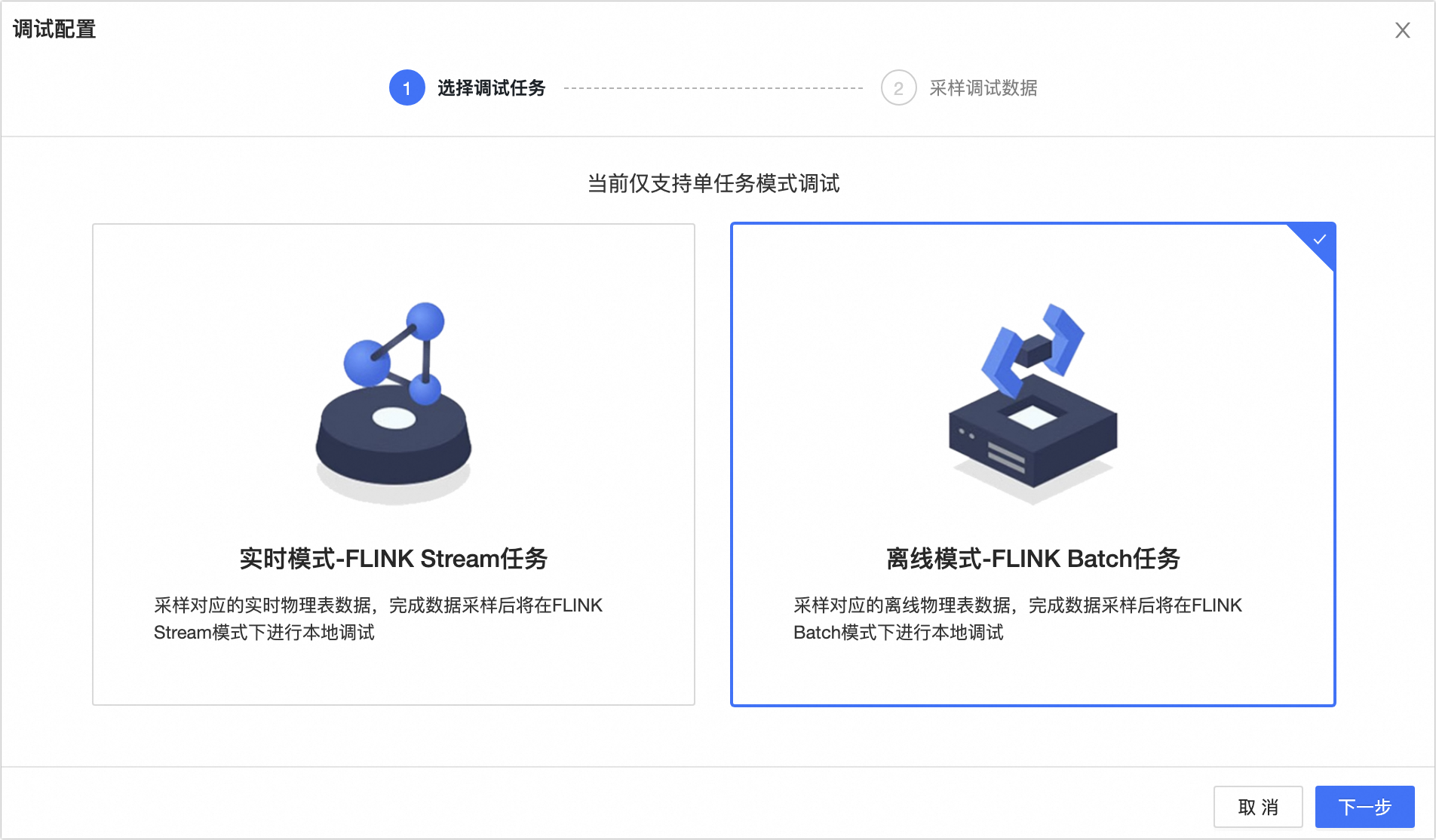
单击下一步。
在调试配置对话框中,选择调试数据来源。
手动上传数据(本地调试方式)
即通过本地调试方式手动上传数据进行调试。上传数据方式包括手动上传样例数据文件、手动输入数据、自动抽样数据。
手动上传样例数据文件
您可以通过上传数据的方式,手动上传本地数据。上传本地数据前需要先下载样例,样例由Dataphin自动识别读写的表和表的schema信息生成的CSV格式样例模板,您可根据下载的样例编辑需要上传的数据,单击上传后,数据自动填充至元数据采样区域。
手动输入数据
适用于采集的数据比较少,或者需要修改已采集到的数据的场景。
自动抽样数据
自动抽样到的数据是随机的,所以适用于对采集到的数据没有限制的场景。针对HBase、MySQL、MaxCompute、DataHub、Kafka数据源支持自动抽样数据,您可以单击自动抽样,进行抽样数据。
说明Kafka中支持json、csv、canal-json、maxwell-json、debezium-json数据格式的自动抽样。
Kafka自动抽样仅支持无认证和用户名+密码认证方式,不支持SSL。
Kafka自动抽样时,支持选择读取数据范围,最大抽样条数为100条。
完成所有数据表的元数据采样后,单击页面下方的确定。
在Result页面,即可查看调试数据、中间结果和调试结果。

附录:自动抽样的调试数据
通过本地调试的自动抽样调试任务时,读取的调试数据根据元表的配置决定。详细说明如下:
元表属性的任务调试时默认读取参数选中开发表。
若任务中使用的是
Project_Name_dev.元表名,则自动抽取开发元表。如果数据源无开发元表,则不支持自动抽样。若任务中使用的是
Project_Name.元表名,则自动抽取生产元表。如果您没有生产环境元表权限,则会报错。请先申请生产表权限,请参见申请表权限。若任务中使用的是
${Project_Name}.元表名或元表名,则自动抽取开发元表。如果数据源无开发元表,则不支持自动抽样。
元表的任务调试时默认读取参数选中生产表。
若任务中使用的是
Project_Name_dev.元表名,则自动抽取开发表。如果数据源无开发元表,则不支持自动抽样。若任务中使用的是
Project_Name.元表名,则自动抽取生产元表。若任务中使用的是
${Project_Name}.元表名或元表名,系统将自动根据参数中的设置替换${project_name}变量。并根据参数的实际项目(开发或生产项目),确定使用生产元表还是开发元表;若未指定${project_name},则自动抽取生产元表。
- 本页导读 (0)