识别规则创建完成后,您可根据业务情况进行调整识别规则的扫描方式,支持定时扫描、手动扫描、实时扫描,此外,您也可配置基于血缘关系自动继承上游的分类分级,通过继承任务生成识别结果。本文为您介绍如何配置识别规则及识别结果的生成方式。
前提条件
已创建识别规则。如需创建,请参见新建及管理识别规则。
权限说明
安全管理员支持创建及管理识别规则、修改规则运行配置及开启自动继承配置。
配置识别规则的调度周期
在Dataphin首页,单击顶部菜单栏的资产。
按照下图操作指引,进入规则运行配置对话框。

在规则运行配置对话框,配置参数。
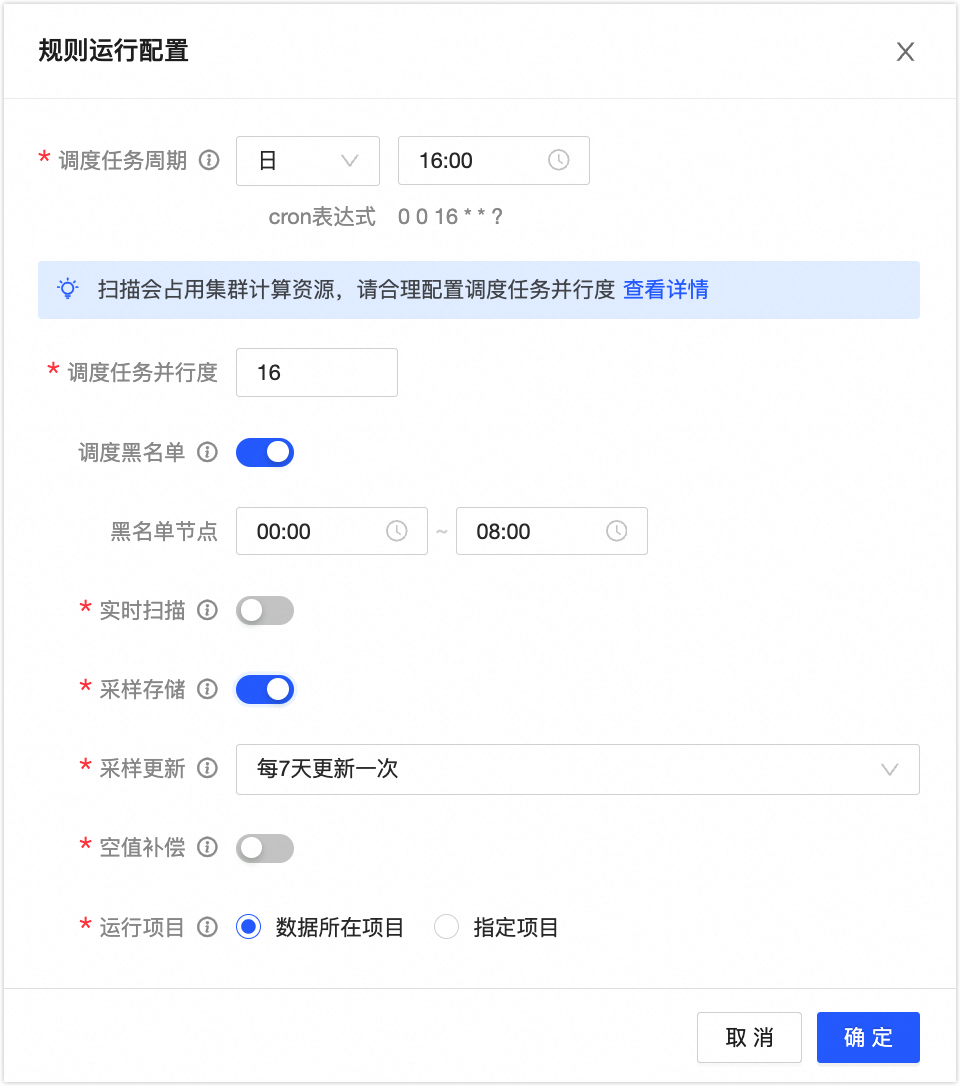
参数
描述
调度任务周期
识别规则默认每天调度一次,可根据业务情况进行调整调度周期。调度周期调长可以优化性能,但会有敏感数据识别滞后的风险。支持选择日、周和月调度周期。
调度任务并行度
用于控制同时扫描的资产对象数量,默认为16,支持配置1~100的正整数。
说明增大并行度可加快扫描进度,但会占用更多的集群计算资源,请您根据业务需求进行合理配置。
调度黑名单
默认关闭,开启后,可以设置调度黑名单,在指定的时间段内,所有识别任务(包括定时扫描、手动扫描、实时扫描、血缘继承任务等)将不会运行,避免占用较多计算资源影响生产环境的正常运行,以保障线上数据任务。
黑名单节点:配置调度黑名单的开始时间和结束时间。
实时扫描
默认关闭,开启实时扫描后,若新建表时或者表的元数据变更时(如创建/删除表、增加/删除字段),则会对表执行一次扫描,并对扫描结果进行打标。
说明实时扫描开启后,能更快的发现敏感数据并对其进行保护,但会消耗部分计算资源,请您合理评估。
采样存储
为了降低每次识别任务的成本,提高识别准确率,安全模块支持对采样数据进行加密存储。需要注意的是节约计算资源的同时会消耗部分存储资源。
开启后会存储数据采样,后续识别任务只会扫描采样数据。采样数据的更新频率可以根据业务需求设置。开启后需配置以下参数:
采样更新:更新采样存储数据,提高长期识别的准确率。
有新数据则更新:识别时,若数据表有新数据(以DDL/DML时间判断)则更新采样数据。
每7天更新一次:识别时,如果距离上次采样成功超过7天则重新采样。
每30天更新一次:识别时,如果距离上次采样成功超过30天则重新采样。
不更新:仅采样存储一次,如果采样成功,则后续不主动更新数据。
空值补偿:当采样数据中单个字段全是空值时,会无法按照内容识别。
开启空值补偿后,如果抽样的字段全是空值,会再次进行一次非空采样,采样成功进入识别流程,采样失败则该字段不进行识别。
开启后会提升识别的准确率,但可能也会导致识别成本上升,请根据业务需求判断是否需要开启。
运行项目
安全识别任务会占用一定的计算资源,正常情况选择数据所在项目即可。
对于部分项目是按量付费、部分项目是包年包月付费的情况下,推荐选择包年包月项目执行识别任务,以减少识别任务计算费用;对于有专门分配的项目资源/队列的情况下,也可以指定项目执行,减少对正常业务项目的干扰。
选择项目的计算源需要有访问其他项目的权限,否则可能会出现无法扫描的情况。
说明当计算引擎为Impala时,扫描的数据表为Kudu表,需选择开启Impala任务的项目,方可使用Impala SQL扫描成功。
单击确定,完成识别规则调度周期的配置。
自动继承配置
单击自动继承配置,进入基于血缘自动继承配置对话框。

在基于血缘自动继承配置对话框,配置参数。
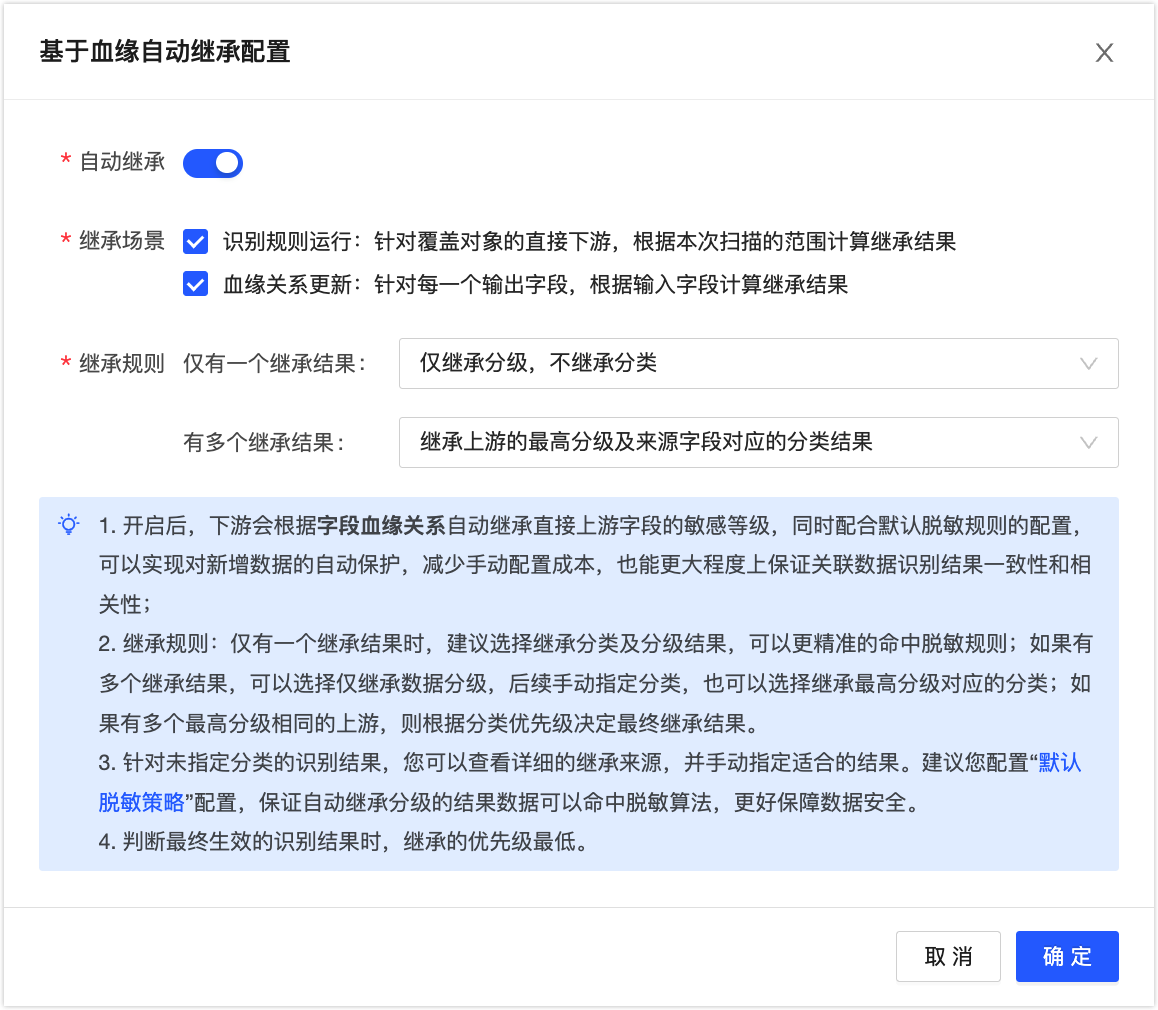
参数
描述
自动继承
默认关闭,开启后配置血缘自动继承的场景及规则。
说明自动继承开启后,下游会根据字段血缘关系自动继承直接上游字段的敏感等级,同时根据默认脱敏规则的配置,以实现对新增数据的自动保护,减少手动配置成本,也能更大程度上保证关联数据识别结果一致性和相关性。
继承场景
支持选择识别规则运行、血缘关系更新。
识别规则运行:针对覆盖对象的直接下游,根据本次扫描的范围计算继承结果。
说明每次识别规则运行时,针对规则圈选的对象,按照字段血缘关系查询下游字段并根据规则配置生成自动继承结果。
如果上游字段不同,但是继承结果对应的分类分级相同,则会更新继承结果的来源字段;如果生成新的分类分级继承结果,则会新增一条对应的记录。
血缘关系更新:针对每一个输出字段,根据输入字段计算继承结果。
说明每次任务提交至开发环境或发布至生产环境时,根据输出表查询输入表并获取输入字段的血缘关系,按照规则配置生成自动继承结果。
如果上游字段不同,但是继承结果对应的分类分级相同,则会更新继承结果的来源字段;如果生成新的分类分级继承结果,则会新增一条对应的记录。
需至少选择一种继承场景。
继承规则
当继承结果仅有一个时,支持选择继承分类及分级结果、仅继承分级,不继承分类。
继承分类及分级结果:可实现对该字段更精准的命中脱敏规则。
仅继承分级,不继承分类:继承直接上游字段的数据分级,后续可在识别记录中手动指定数据分类。
当继承结果仅有多个时,支持选择仅继承最高分级,不继承分类、继承上游的最高分级及来源字段对应的分类结果。
仅继承最高分级,不继承分类:继承直接上游字段的最高数据分级,后续可在识别记录中手动指定数据分类。
继承上游的最高分级及来源字段对应的分类结果:若多个字段敏感等级相同但分类不同,则按照分类优先级>识别记录的更新时间>分类修改时间决定分类结果。
说明针对未指定分类的识别结果,您可根据继承来源手动指定适合的识别结果。建议您配置默认脱敏策略,保证自动继承分级的结果数据可以命中脱敏算法,更好保障数据安全。
判断最终生效的识别结果优先级从高到低为:手动执行>自动识别>自动血缘继承。
单击确定,完成基于血缘自动继承配置。
- 本页导读 (0)