Dataphin元数据仓库(简称:元仓),是统一管理Dataphin内部业务元数据和相应计算引擎元数据的数据仓库,存在于Dataphin元仓租户中(OPS租户)的一个Dataphin项目空间中,由一系列的周期性数据集成节点、SQL脚本节点、Shell节点组成。元仓初始化即配置Dataphin系统的计算引擎类型并初始化元数据的过程。本文将为您介绍如何使用Hadoop作为元仓计算引擎进行元仓初始化。
前提条件
以Hadoop作为元仓时,需开放元数据库或提供Hive Metastore服务,用于获取元数据。
背景信息
Dataphin支持通过直连元数据库或Hive Metastore Service服务方式获取元数据。各方式获取元数据优劣势对比详情如下:
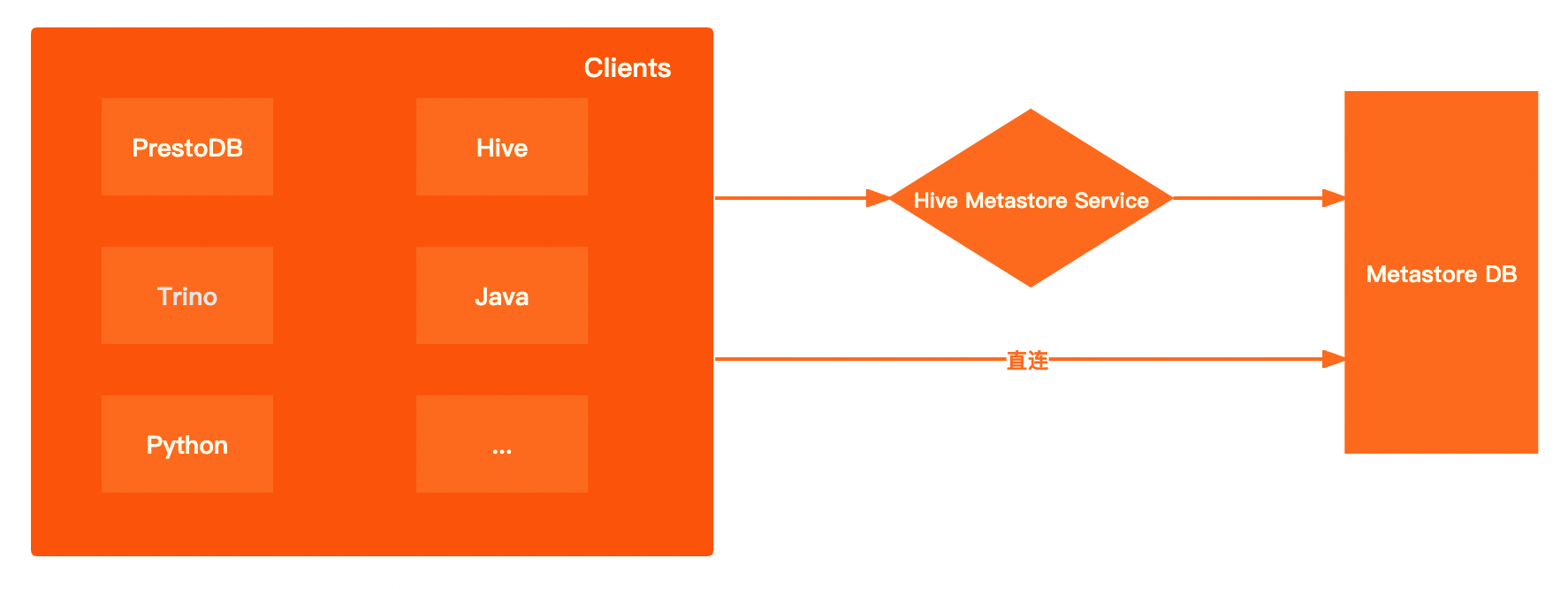
元数据获取方式 | 优势与劣势 |
直连元数据库 | 高性能:直接连接底层的元数据库,省去了中间的HMS服务环节,客户端在获取meta(元数据)时性能更好,同时能够减少网络传输上的耗时。 更开放:通过HMS服务查询metastore,只能使用metastoreclient提供的几种方法进行查询。而直接连接元数据库后,可以自由使用SQL进行查询。 |
Hive Metastore Service服务 | 更安全:可以为metastore开启kerberos认证,客户端需要进行kerberos认证才能读取到metastore中的数据。 更灵活:客户端仅感知到HMS服务,并不能感知到后台的元数据库。因此底层的原数据库可以随时进行切换,而对应的客户端无需变更。 |
通过DLF方式获取元数据的性能与通过Hive Metastore Service服务的方式相近。
使用限制
系统仅支持元仓租户超级管理员或系统管理员角色的账号初始化系统。
请妥善保管元仓租户超级管理员或系统管理员的账号和密码。同时,元仓租户超级管理员账号登录系统后,请谨慎操作。
操作步骤
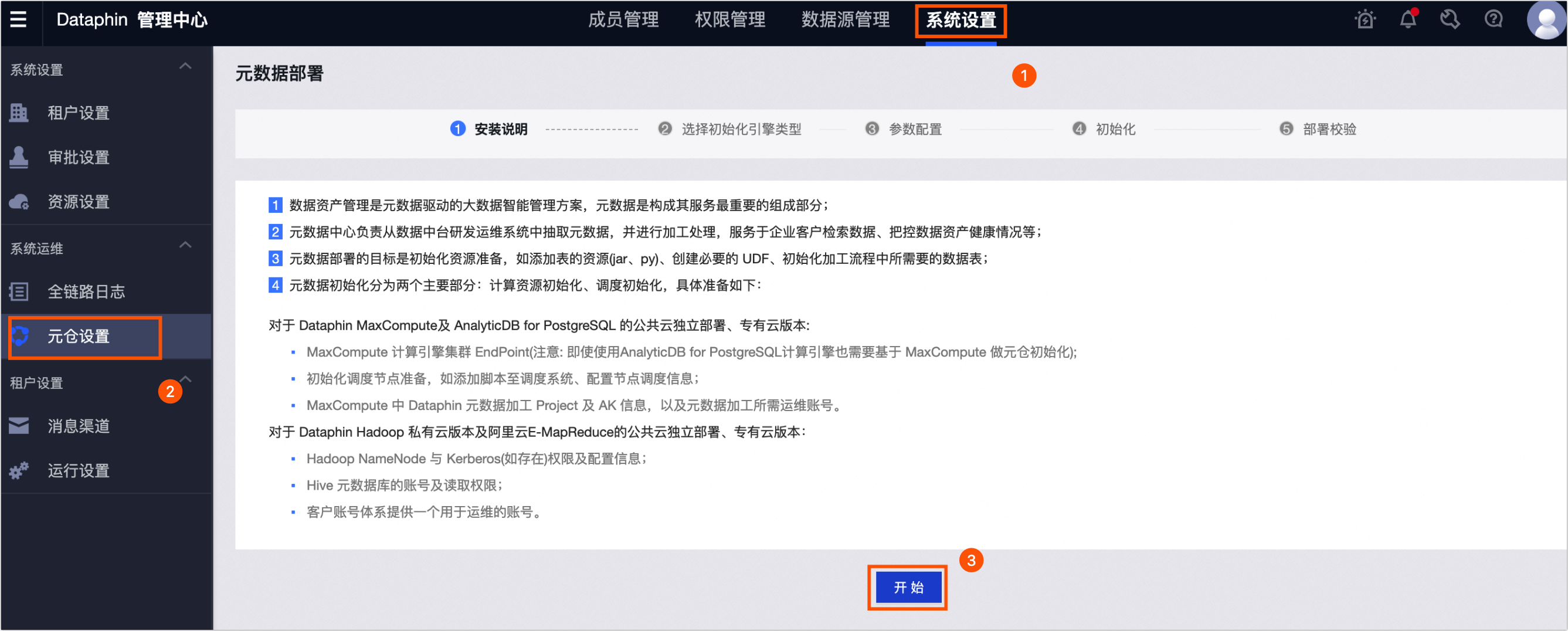
在Dataphin首页,单击顶部菜单栏的管理中心。
按照下图操作指引,在元数据部署配置向导页面仔细阅读安装说明后,单击开始。
在选择初始化引擎类型页面,选择Hadoop引擎类型。
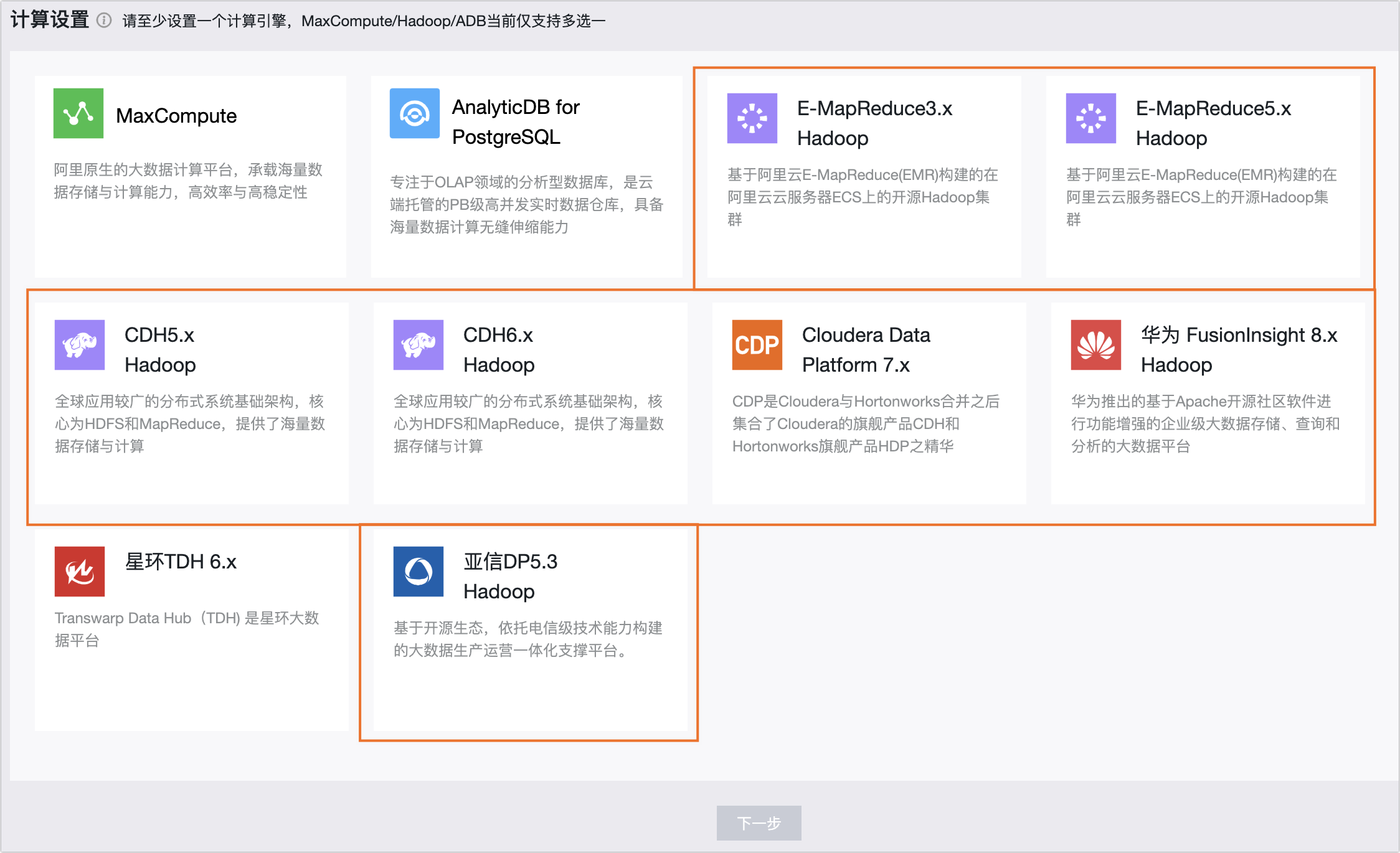 重要
重要若元仓已经初始化,则默认选择上次初始化成功的元仓。当切换成不兼容的计算引擎时,会导致治理功能不可用。
Hadoop类型引擎包括E-MapReduce 3.X、E-MapReduce 5.x、CDH 5.X、CDH 6.X、FusionInsight 8.X、亚信DP 5.3 Hadoop、Cloudera Data Platform 7.x计算引擎。Hadoop类型计算引擎参数配置相同,此处以E-MapReduce 3.X为例。
集群配置
说明OSS-HDFS集群存储仅在E-MapReduce5.x Hadoop引擎类型时支持。
HDFS集群存储
参数
描述
NameNode
NameNode用于管理HDFS中的文件系统名称空间及外部客户机的访问权限。
单击新增。
在新增NameNode对话框,填写NameNode的Hostname名称以及端口号,单击确定。
填写后自动生成对应的格式,例如
host=hostname,webUiPort=50070,ipcPort=8020。
配置文件
上传集群配置文件,用于配置集群参数。系统支持上传core-site.xml、hdfs-site.xml等集群配置文件。
若需使用HMS方式获取元数据,配置文件中必需上传hdfs-site.xml、hive-site.xml、core-site xmI 、hivemetastore-site.xml文件。若计算引擎类型为FusionInsight 8.X和E-MapReduce5.x Hadoop,还需上传hivemetastore-site.xml文件。
History Log
配置集群的日志路径。例如
tmp/hadoop-yarn/staging/history/done。认证方式
支持无认证和Kerberos认证方式。Kerberos是一种基于对称密钥技术的身份认证协议,常用于集群各组件间的认证。开启Kerberos能够提升集群的安全性。
如果您选择开启Kerberos认证,需配置以下参数:
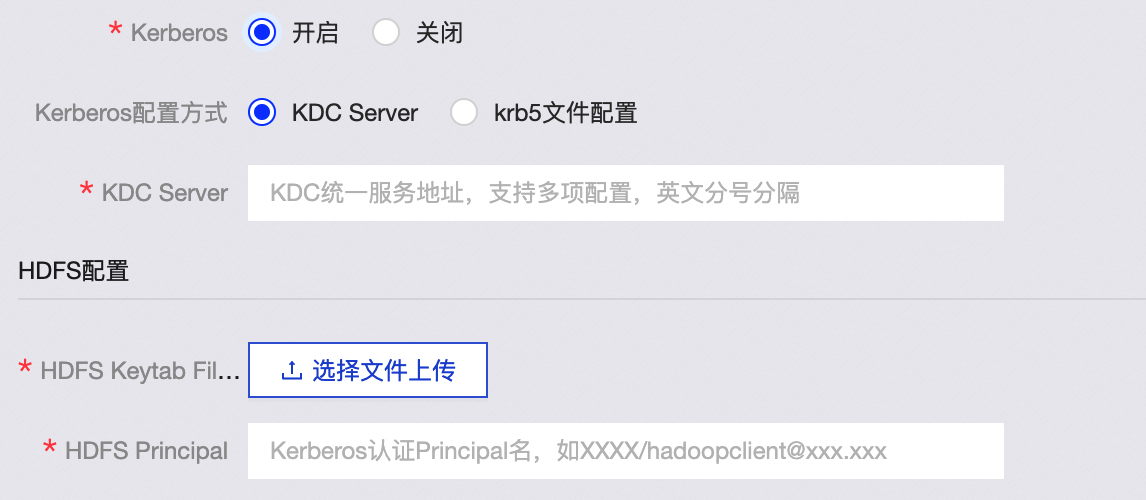
Kerberos配置方式
KDC Server:需输入KDC统一服务地址,辅助完成Kerberos认证。
krb5文件配置:需要上传Krb5文件进行Kerberos认证。
HDFS配置
HDFS Keytab File:需上传HDFS Keytab文件。
HDFS Principal:输入Kerberos认证的Principal名。例如
XXXX/hadoopclient@xxx.xxx。
OSS-HDFS集群存储(E-MapReduce5.x Hadoop)
初始化引擎类型选择为E-MapReduce5.x Hadoop时,支持配置集群存储类型为OSS-HDFS。
参数
描述
集群存储
可以通过以下方式查看集群存储类型。
未创建集群:可以通过E-MapReduce5.x Hadoop集群创建页面查看所创建的集群存储类型。如下图所示:

已创建集群:可以通过E-MapReduce5.x Hadoop集群的详情页查看所创建的集群存储类型。如下图所示:
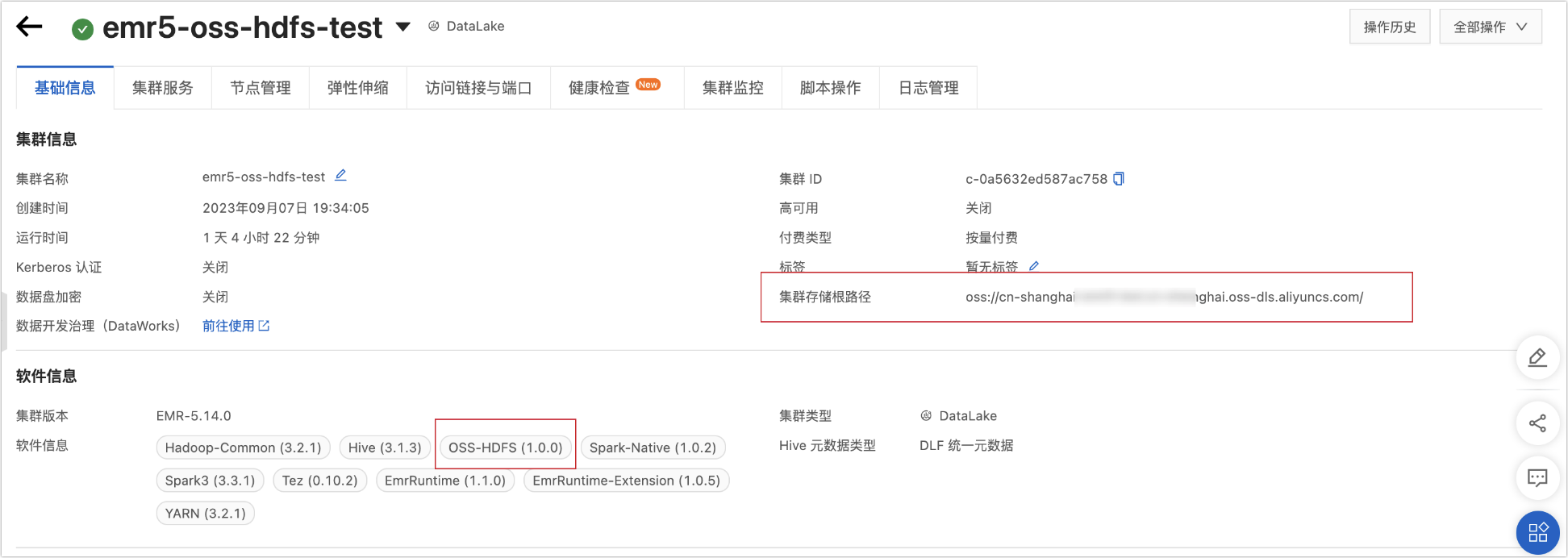
集群存储根目录
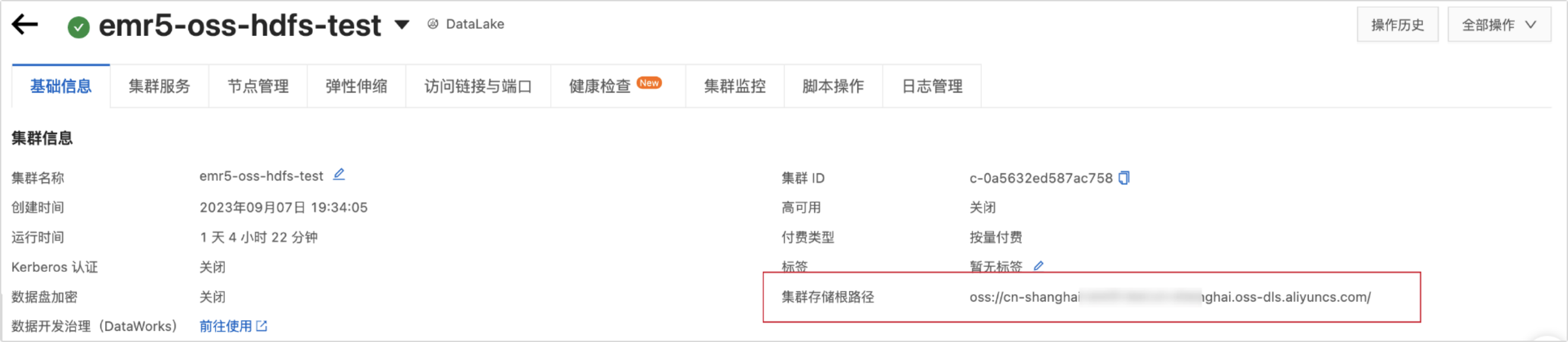
填写集群存储根目录。可以通过查看E-MapReduce5.x Hadoop集群信息获取进行。如下图所示:
 重要
重要若填写的路径中包括Endpoint,则Dataphin默认使用该Endpoint;若不包含,则使用core-site.xml中配置的Bucket级别的Endpoint;若未配置Bucket级别的Endpoint,则使用core-site.xml中的全局Endpoint。更多信息。请参见阿里云OSS-HDFS服务(JindoFS 服务)Endpoint配置。
配置文件
上传集群配置文件,用于配置集群参数。系统支持上传core-site.xml、hive-site.xml等集群配置文件。若需使用HMS方式获取元数据,配置文件中必需上传hive-site.xml、core-site xmI 、hivemetastore-site.xml文件。
History Log
配置集群的日志路径。例如
tmp/hadoop-yarn/staging/history/done。AccessKey ID、AccessKey Secret
填写访问集群OSS的AccessKey ID和AccessKey Secret。查看AccessKey,请参见查看AccessKey。
重要此处填写的配置优先级高于core-site.xml中配置的AccessKey。
认证方式
支持无认证和Kerberos认证方式。Kerberos是一种基于对称密钥技术的身份认证协议,常用于集群各组件间的认证。开启Kerberos能够提升集群的安全性。如果您选择开启Kerberos认证,需要上传Krb5文件进行Kerberos认证。
Hive配置
参数
描述
JDBC URL
填写链接Hive的JDBC URL。
认证方式
当集群认证选择无认证时,Hive的认证方式支持选择无认证和LDAP。
当集群认证选择Kerberos时,Hive的认证方式支持选择无认证、LDAP和Kerberos。
说明认证方式仅支持E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform 7.x、亚信DP5.3、华为 FusionInsight 8.X。
用户名、密码
访问Hive的用户名和密码。
无认证方式:需填写用户名;
LDAP认证方式:需填写用户名和密码。
Kerberos认证方式:无需填写。
Hive Keytab File
开启Kerberos认证后需配置该参数。
上传keytab文件,您可以在Hive Server上获取keytab文件。
Hive Principal
开启Kerberos认证后需配置该参数。
填写Hive Keytab File文件对应的Kerberos认证Principal名。例如
XXXX/hadoopclient@xxx.xxx。执行引擎
根据实际情况,选择合适的执行引擎。各计算引擎所支持的执行引擎不同。支持情况如下:
E-MapReduce 3.X:MapReduce、Spark。
E-MapReduce 5.X:MapReduce、Tez。
CDH 5.X:MapReduce。
CDH 6.X:MapReduce、Spark、Tez。
FusionInsight 8.X:MapReduce。
亚信DP 5.3 Hadoop:MapReduce。
Cloudera Data Platform 7.x:Tez。
说明设置了执行引擎后,元仓租户的计算设置、计算源、任务等都使用设置的Hive执行引擎。重新初始化后,计算设置、计算源、任务等将被初始化为新设置的执行引擎。
元数据获取方式
元数据获取方式支持元数据库和HMS(Hive Metastore Serivce)、DLF三种方式获取元数据。不同获取方式所配置信息不同。详情如下:
元数据库方式获取
参数
描述
数据库类型
选择Hive的元数据库类型。Dataphin支持选择MySQL。
支持MySQL数据库的版本包括MySQL 5.1.43、MYSQL 5.6/5.7和MySQL 8版本。
JDBC URL
填写目标数据库JDBC的连接地址。例如:
MySQL数据库的连接地址格式为
jdbc:mysql://host:port/dbname用户名、密码
目标数据库的用户名和密码。
HMS获取方式
使用HMS方式获取元数据库,开启Kerberos后,需上传Keytab File文件和填写Principal。
参数
描述
Keytab File
Hive metastore的Kerberos认证的Keytabl文件。
Principal
Hive metastore的Kerberos认证的Principal。
DLF获取方式
重要DLF获取方式仅支持EMR5.x Hive 3.1.x版本。
参数
描述
Endpoint
填写集群在DLF数据中心所在地域的Endpoint。如何获取,请参见DLF Region和Endpoint对照表。
AccessKey ID、AccessKey Secret
填写集群所在账号的AccessKey ID和AccessKey Secret。
您可在用户信息管理页面,获取账号的AccessKey ID和AccessKey Secret。
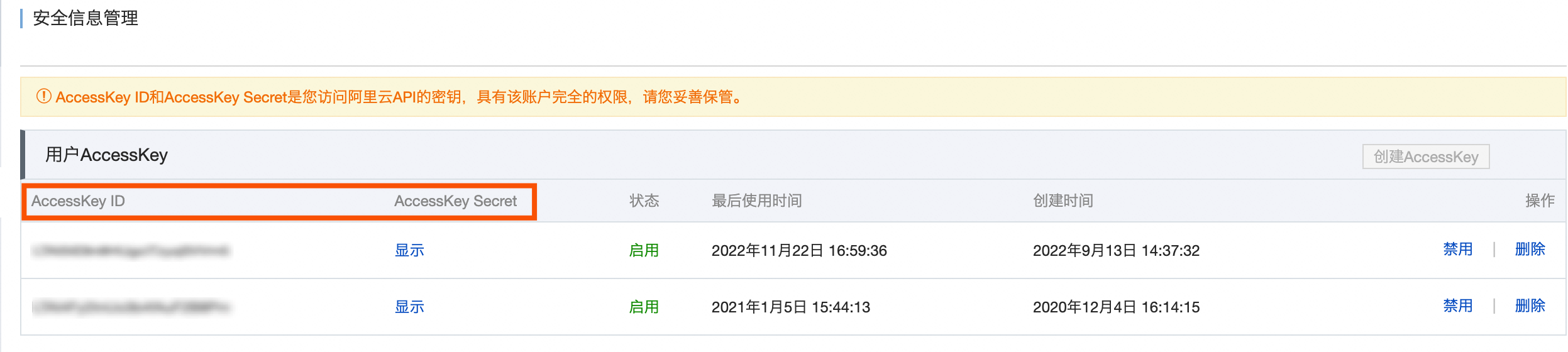
元数据生产项目
参数
描述
Meta Project
用于元数据生产,加工的逻辑项目空间。推荐配置为
dataphin_meta,重新初始化时请保持名称不变,否则初始化失败。
单击测试连接。连接测试通过后,单击下一步。
在初始化页面,单击开始。
说明初始化系统约15分钟左右,请您耐心等待。
页面提示执行成功后,单击完成,即可完成配置。
后续步骤
完成系统的元数据初始化后,即可设置Dataphin实例的计算引擎。设置方法请参见计算设置概述。
- 本页导读 (0)