
大数据计算服务MaxCompute(原名ODPS)为您提供完善的数据导入方案,能够快速解决海量数据的计算问题。
准备工作
配置MaxCompute输出节点前,您需要先配置好相应的输入或转换组件。
操作步骤
写入数据不支持去重,即如果任务重置位点或者Failover后再启动,会导致重复数据写入。
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
鼠标悬停至
 图标,单击。
图标,单击。 您也可以展开业务流程,右键单击目标业务流程,选择。
在新建节点对话框中,选择同步方式为单表(Topic)到单表(Topic)ETL,输入名称,并选择路径。
单击确认。
-
在实时同步节点的编辑页面,单击并拖拽至编辑面板,连线已配置好的输入或转换节点。
-
单击MaxCompute节点,在节点配置对话框中,配置各项参数。

参数
描述
数据源
选择已经配置好的MaxCompute数据源,此处仅支持MaxCompute数据源。
如果您未配置数据源,请单击右侧的新建数据源,进入页面新建,详情请参见配置MaxCompute数据源。
Tunnel资源组
即Tunnel Quota,默认选择公共传输资源,即MC的免费quota。
MaxCompute的数据传输资源选择,具体请购买与使用独享数据传输服务资源组。
说明如果独享tunnel quota因欠费或到期不可用,任务在运行中将会自动切换为“公共传输资源”。
schema
选择MaxCompute下已创建的schema。
表
选择当前数据源下需要同步的表名称。
您可以单击右侧的一键建表创建新表,也可以单击数据预览进行确认。
说明新建目标数据表前,请先连线输入节点,并确认有输出字段。
分区讯息
为您展示MaxCompute分区表的信息。
分区方式
包括时间自动分区及根据字段内容动态分区。其中时间自动分区是根据_execute_time_字段进行分区的,详情请参见实时同步字段格式。根据字段内容动态分区通过指定源端表某字段与目标MaxCompute表分区字段对应关系,实现源端对应字段所在数据行写入到MaxCompute表对应的分区中。
字段映射
单击字段映射,设置源端和目标端字段的映射。同步任务会根据字段的映射关系同步数据。
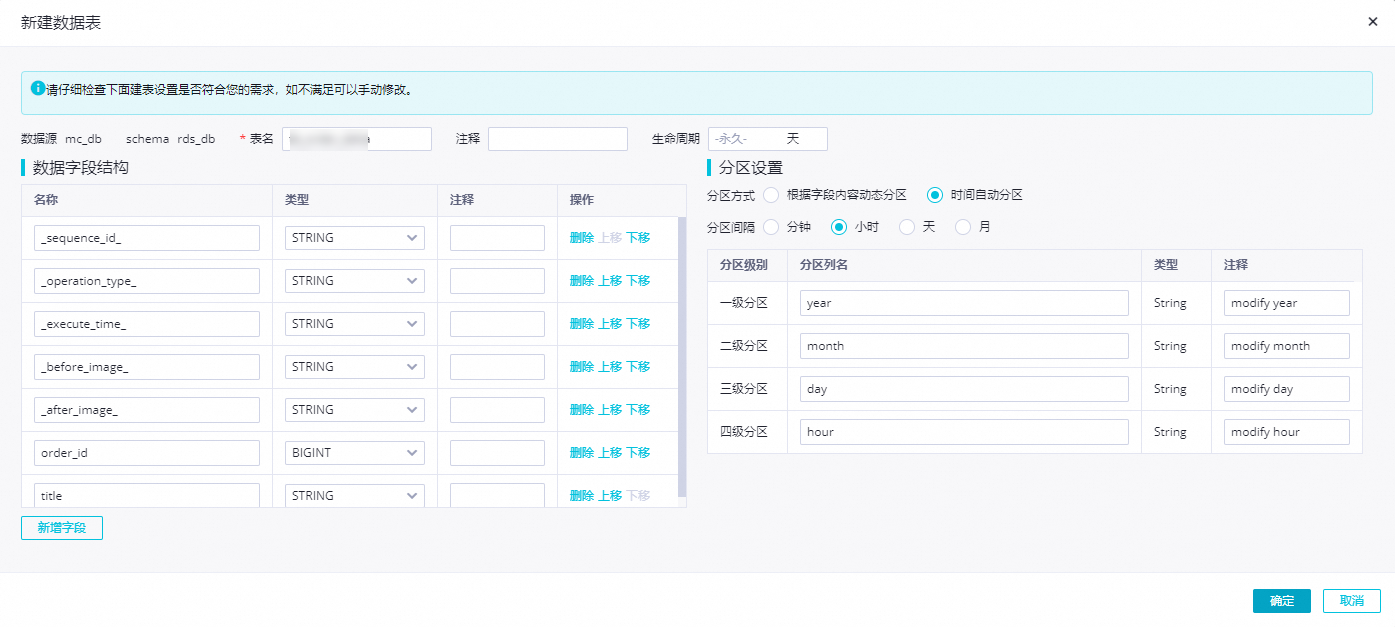
如果您需要新建表,请单击一键建表,然后在新建数据表对话框中,配置各项参数。
参数
描述
表名称
实时同步写入的MaxCompute表的名称。
生命周期
实时同步写入的MaxCompute表的生命周期长度,详情请参见生命周期。
数据字段结构
实时同步写入的MaxCompute表的字段结构。如果您需要新增字段,请单击添加。
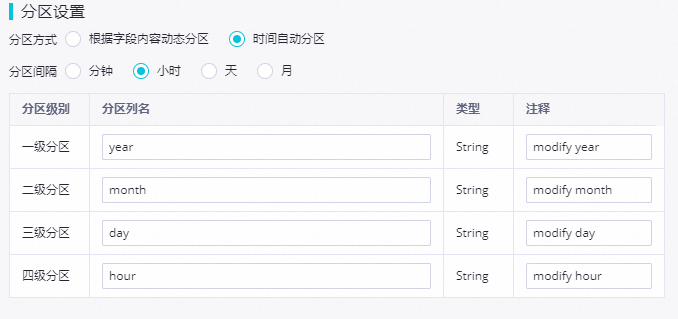
分区设置
实时同步写入的MaxCompute表的分区信息。 实时同步写MaxCompute表支持时间自动分区与根据字段内容动态分区两种分区方式。
-
时间自动分区:根据_execute_time_字段将数据写入到对应时间分区中,详情请参见实时同步字段格式。
 重要
重要-
您最少需要设置二级分区(月和年),最多支持设置五级分区(分钟、小时、天、月和年)。
-
关于MaxCompute表的介绍可参考文档:分区。
-
-
根据字段内容动态分区:通过指定源端表某字段与目标MaxCompute表分区字段对应关系,实现源端对应字段所在数据行写入到MaxCompute表对应的分区中。
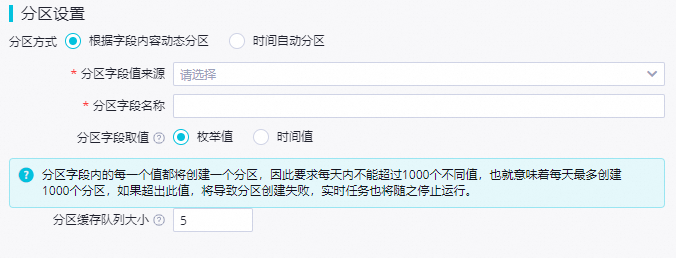 例如:配置MaxCompute表分区字段值来源为源端字段A,当A字段值为aa时,实时同步会将数据写入到MaxCompute表对应的aa分区中,当A字段值为bb时,实时同步会将数据写入到MaxCompute表对应的bb分区中。
例如:配置MaxCompute表分区字段值来源为源端字段A,当A字段值为aa时,实时同步会将数据写入到MaxCompute表对应的aa分区中,当A字段值为bb时,实时同步会将数据写入到MaxCompute表对应的bb分区中。
-
-
单击工具栏中的
 图标。
图标。