
面对企业中散落在 OSS、NAS 的海量图片、文档、日志等非结构化数据,DataWorks 提供了统一的多模态元数据管理方案。该方案不仅支持对企业拥有的非结构化数据的注册、预览和关键词检索,也支持通过PAI同步增强数据集,为数据集赋予标签筛选、自然语言语义检索、以图搜图等高级 AI 能力。最终,帮助企业打破数据孤岛,实现跨团队、跨工具的数据可发现性与可用性。
功能概述
在数据驱动的业务中,企业往往拥有大量存储在对象存储(OSS)或文件存储(NAS)中的非结构化数据,例如图片、文档、日志文件等。这些数据如同散落各处的"暗箱",难以被统一发现、理解和使用。
DataWorks 数据地图 的多模态数据集管理功能,旨在解决这一难题。它允许您将这些非结构化数据注册为标准的数据资产,纳入企业统一的数据目录。您可以:
-
集中管理:将 OSS/NAS 上的文件、经由 PAI处理后的 AI 数据集,统一注册和管理。
-
轻松发现:通过关键词搜索、标签筛选、甚至自然语言(语义)检索,快速找到所需数据。
-
便捷使用:在 DataWorks 的任务节点(如 Python、Shell、PAI 任务)中直接引用这些数据集,实现数据处理和 AI 建模的无缝衔接。
核心概念:两种管理模式
根据您的数据来源和使用场景,我们提供两种管理模式:基础模式和增强模式。您可以根据下表快速选择适合自己的方案。
说明:两种模式可以在同一个 DataWorks 工作空间中并存。所有数据资产必须在同一个阿里云主账号下,才能被统一发现和管理。
|
管理模式 |
数据特点 |
目标用户 |
核心能力 |
依赖产品 |
|
基础模式 |
主要为存储在 OSS/NAS 中的原始文件或半结构化数据。 |
仅使用 DataWorks 的数据仓库或数据工程团队。 |
|
DataWorks + OSS/NAS |
|
增强模式 |
经 PAI 平台处理(如智能打标、向量索引)的 AI 数据集。 |
同时使用 DataWorks 和 PAI 平台的算法或 AI 团队。 |
在基础能力之上,增加:
|
DataWorks + PAI + OSS/NAS |
基础模式:原始多模态数据管理
通常适用于基于 MaxCompute 使用 DataWorks 进行数据处理和数据管理的团队,主要针对原始的非结构化数据,并在 Python、Notebook 和 MaxFrame 任务中使用。用户可以直接在 DataWorks 中注册 OSS 或 NAS 路径作为数据集,系统将自动采集基础元信息,并对部分格式(如 CSV、JSONL、压缩包)提供内容预览功能。注册后的数据集可被搜索、查看,并可挂载至 Python、Shell、Notebook 等任务节点中使用。
典型数据类型包括:
-
半结构化日志(JSONL、CSV)。
-
压缩归档文件(ZIP、GZIP,内含文本)。
-
原始图片、视频、PDF 等多媒体文件。
增强模式:增强型 AI 数据资产协同
适用于已经使用 PAI 平台,并基于 PAI EAS 或 PAI LangStudio 使用 AI 数据资产的团队。当用户在 PAI AI 数据集管理中完成图片数据集的智能打标或语义索引任务,或在 LangStudio 中启用文档知识库的向量索引后,相关的增强元数据将自动同步至 DataWorks 数据地图。用户可以在 DataWorks 中搜索到数据集,并对数据集执行标签筛选、自然语言语义检索、以图搜图等高级操作,而无需跳转至 PAI 控制台。此外,该数据集也可以作为 DataWorks 中相关 PAI DLC 节点任务的输入数据集。
支持的增强资产类型包括:
-
PAI - AI数据集 - 图片类数据集(经智能打标或语义索引)。
-
PAI - LangStudio 文档类知识库(配置向量索引)【公测中】。
元数据管理能力概览

|
能力 |
基础模式 |
增强模式 |
|
|
PAI AI数据集 |
PAI LangStudio知识库 |
||
|
数据集关键词搜索 |
|
|
|
|
基础元数据显示 |
|
|
|
|
文件列表 |
|
|
|
|
内容预览 |
(部分格式) |
(仅针对图片提供) |
|
|
单数据集/标签筛选文件 |
|
|
|
|
单数据集/语义检索文件 |
|
|
|
|
任务节点挂载 |
(Python、Shell、Notebook) |
(PAI DLC节点、PAI EAS服务) |
|
|
状态 |
正式发布 |
正式发布 |
公测中 |
场景选择:选择适合您的路径
|
需求场景 |
推荐路径 |
|
仅使用 DataWorks 管理 OSS/NAS 上的原始文件。 |
参考【场景一】,在 DataWorks 中直接注册数据集。 |
|
使用 PAI 对图片进行打标和 AI 训练。 |
参考【场景二】,在 PAI 中完成增强任务后,前往 DataWorks 发现和使用。 |
|
使用 PAI LangStudio 构建 RAG 知识库。 |
参考【场景三】,在 LangStudio 中构建向量索引后,前往 DataWorks 探索。 |
场景一:原始数据集管理
本场景适用于仅使用 DataWorks 和 OSS/NAS,需要对海量原始文件(如日志、文档、图片等)进行统一管理的团队,尤其是数据工程师、数据分析师等角色。如果您未使用 PAI 平台进行 AI 处理,建议使用基础模式。
核心价值:打破非结构化数据的“黑盒”
无需离开 DataWorks 平台,也无需编写复杂代码,您就可以轻量化地完成对 OSS/NAS 上原始文件的注册、预览、搜索和挂载,将它们作为标准的数据资产进行统一管理和治理。
示例场景:当“数据黑盒”成为工作瓶颈
在企业数据中台建设过程中,大量非结构化或半结构化数据以原始文件形式存储于对象存储(OSS)或网络文件系统(NAS)中,例如:
-
文本记录日志:JSONL 格式,按天分区存储于 OSS;
-
采购数据:CSV、JSONL 或压缩包(.gz/.zip),包含爬虫采集的相应数据行;
-
业务文档:TXT、PDF、Word、Excel 报告,用于后续 NLP 处理;
-
原始图片/视频:监控截图、产品图,尚未进入 AI 训练流程。
这些数据通常由采集系统自动写入存储,或通过外表方式关联,数据工程师/算法工程师在 DataWorks 上使用相应计算任务(如 MaxCompute MaxFrame、Python等)进行清洗、特征提取;团队需要用轻量、自助的方式,对这些原始文件进行注册、预览、搜索和任务引用。
然而,团队面临以下痛点问题:
-
非结构化数据不可见:“OSS 路径
oss://log-bucket/source-rule-doc-sets/2025/05/里到底是什么内容?是否是原始的规则文档内容?”目前需要手动记录或下载下来查看。
-
探查成本高:需手动下载文件或写脚本读取,效率不高且工作琐碎;
-
任务耦合路径:ETL 脚本硬编码 OSS 路径,迁移或复用困难;
-
数据难以管理:无法统一搜索、归档或追踪生命周期。
为此,DataWorks 和 PAI 共同提供 “数据集” 能力,让原始的多模态文件集合能像表一样被管理,用户也可以在数据地图中,通过关键词搜索和查看数据集。
支持的数据来源与格式
基础模式支持对存储在 OSS 和 NAS 上的多种文件格式进行注册,并对部分格式提供内容预览能力。
|
数据来源 |
支持格式 |
预览能力 |
说明 |
|
OSS |
|
|
自动解析并以表格或文本形式展示前 10 行内容。 |
|
OSS |
包含 |
有条件支持 |
可直接预览压缩包内首个可识别的文本文件(如 |
|
OSS |
图片(JPG/PNG 等)、视频、Parquet 等。 |
|
/ |
|
NAS |
所有格式。 |
操作步骤

本文以下述场景为例,介绍如何将在OSS上定期批量更新的数据集注册到数据地图,并进行预览。
假设有这样一个数据集:数据提供方会定期在OSS的同一路径下,通过新增子文件夹来发布新批次数据。每个子文件夹内均包含一个.zip压缩包,其内部是.JSONL格式的数据文件。例如,一个面向“智能辅导”应用的数据集,其每次更新的内容可能就是一批关于“各省市地图知识”的新增问答数据。
适用范围
-
拥有一个 OSS Bucket,并已存有数据。
-
操作账号拥有 DataWorks对应工作空间的空间管理员或数据开发角色,并具备目标 OSS的读权限。
一、注册数据集
-
在 DataWorks 控制台,单击进入数据地图。
-
在左侧导航栏,单击
 图标,进入数据地图 > 数据目录。
图标,进入数据地图 > 数据目录。 -
在左侧目录树中单击 DataSet,选择目标工作空间,单击工作详情页的新建数据集。
-
在弹出的对话框中,填写以下关键信息后,即可完成。
参数
说明
填写示例
名称
业务含义清晰的名称,便于搜索。
2025-高考内容语料-训练集存储类型
您的文件存储服务。
本示例选择对象存储(OSS)。
内容类型
帮助系统更好地解析和预览。
文本。
如果不确定,可选择通用。
描述
说明数据内容、用途、来源等。
用于“智能辅导”应用的高考试题原始语料,每日更新。
OSS 路径
文件或文件夹所在的路径。单击右侧文件夹按钮,选择OSS路径。
说明OSS文件路径设计实践建议:
-
按业务域、地区隔离:
/gaokao/math/,/iot/sensor/。 -
文件夹可按年份或日期分区:
/gaokao/math/2025/。 -
注册数据集的文件夹,需要能够是该文件夹的前缀路径,如:
/gaokao/2025/。 -
避免超大目录:单路径文件数建议 < 10 万。
/Demo/gaokao/train/默认挂载路径
选择数据的默认挂载路径,此路径将用于DataWorks中需要挂载文件的任务节点,例如Python和Shell等任务。
/mnt/data/gaokao/train表单顶部蓝色提示条提示:数据集创建后,开发角色默认具有读写权限。工作空间和负责人字段由系统自动填充。右侧包含数据集配置和版本配置两个选项卡,当前默认展开数据集配置中的基本信息区域。
-
更多详细操作,请参考:管理数据集。
二、搜索与预览
-
在数据地图页面,单击顶部搜索框,选择类型为数据集,在搜索框中输入关键词(例如,数据集名称
高考、描述内容语料或路径片段gaokao)。 -
在搜索结果中找到您的数据集,点击进入详情页。
-
在详情页中,您可以看到:
-
基础信息:负责人、存储路径、创建时间等元数据。
-
数据预览:默认展示为智能表格,如果文件格式受支持,系统会自动展示文件内容预览。双击字段,可查看字段详情。同时,支持切换成原始文本模式。
预览支持的数据格式情况请参见元数据管理能力概览。
-
血缘关系:查看该数据集被哪些任务节点所使用。
-
三、在任务中使用
将数据集作为输入,解耦代码与物理路径。
-
在数据开发Data Studio中,创建或打开一个 Python、Shell 或 Notebook 节点。
-
在节点详情右侧的调度配置 > 调度策略 > 数据集 中,点击+ 添加增加一个挂载数据集。
-
点击数据集,在弹出的列表中选择步骤一中注册的数据集。
-
在代码中,通过系统注入的环境变量来访问数据路径。详情请参见使用数据集。
重要运行时,DataWorks 会将数据集路径挂载到任务的本地文件系统(只读),无需担心存储复制和安全问题。实际访问仍受 OSS/NAS 原生权限控制。
更多详细操作,请参考:使用数据集。
常见问题 (FAQ)
-
Q: 为什么我的数据无法预览?
-
不支持预览:文件格式(如 Parquet、视频)本身不支持预览,这是正常现象。可跳转OSS查看文件列表。
-
文件读取失败:请检查您的账号是否具有该 OSS 路径的读取权限,或者压缩文件是否被加密。
-
预览为空白:可能是路径下的首个文件内容为空或已损坏。
-
-
Q: 一个数据集版本可以对应多个 OSS 路径吗?
-
不可以。一个数据集版本只能对应一个根路径。
-
-
Q:能否注册同一个 OSS 路径到多个数据集?
-
不建议进行该方式操作,会影响后续血缘相关解析。
-
-
Q: 预览的内容可以导出吗?
-
不可以直接在预览界面导出。但您可以通过挂载数据集到 Notebook 节点,然后编写代码读取并导出数据。
-
场景二:AI 增强型图片数据集(基于PAI标注与索引)
本场景适用于同时使用 DataWorks 和 PAI 平台的团队,特别是需要对海量图片进行高级检索和筛选的 AI 场景,如自动驾驶、工业质检、内容审核等。
核心价值:在 DataWorks 中实现对图片的智能检索
打通 PAI 的 AI 处理能力和 DataWorks 的元数据管理能力。让数据分析师、算法工程师甚至产品经理都能在 DataWorks 中,用更智能的方式与图片数据交互:
-
按业务标签筛选图片:例如,筛选出所有“天气为雨天”且“包含行人”的图片。
-
用自然语言搜索图片:例如,输入“红色轿车正在通过斑马线”,即可找到相关图片。
能力概览
该场景的能力完全依赖于 PAI 侧增强任务的成功执行。
|
PAI 增强任务 |
在 DataWorks 中解锁的能力 |
|
智能打标任务成功 |
标签筛选:提供标签筛选面板,支持“包含”、“排除”等逻辑组合。 |
|
语义索引任务成功 |
语义检索与以图搜图:提供自然语言搜索框和以图搜图功能,并可调整 TopK、相似度等参数。 |
|
两者均成功 |
联合检索:可同时使用标签和语义进行组合筛选(AND 关系),实现更精确的查找。 |
示例场景:自动驾驶场景下的图像数据供给
某自动驾驶公司基于 DataWorks 和 PAI 构建了数据与算法链路。算法团队在 PAI 中通过 Qwen-VL 模型,为百万级交通图像自动打上了“天气”、“光照”、“车辆类型”等业务标签,并利用 GME 模型构建了向量索引。
现在,数据团队和产品经理希望在 DataWorks 中快速筛选出“白天、晴天且包含行人的过街图片”,以挑选出新的数据集为后续新模型训练提供训练和验证数据。
PAI 侧创建智能打标和语义索引
为了在 DataWorks 数据地图中激活对图片数据集的标签筛选和语义检索能力,首先在 PAI 平台完成一系列准备和配置工作。
完整版详细操作流程,请查看多模态数据管理和使用。
|
条件 |
说明 |
|
数据集类型 |
必须为 PAI 高级型数据集(基础型不支持增强能力)。 |
|
内容类型 |
类型建议选择通用或图片,实际内容必须包含图片(支持 jpg/jpeg/png/gif/bmp/tiff/webp)。 |
|
地域支持 |
仅限杭州、上海、深圳、乌兰察布、北京、广州、新加坡等指定地域。 |
|
增强任务 |
至少完成以下之一:
|
|
向量存储 |
本案例使用 Milvus(2.4及以上版本),已创建实例并配置连接。 |
一、创建并配置高级型图片数据集
目标:创建一个用于承载图片数据和其增强元数据的容器。
-
创建数据集
-
操作路径:进入PAI 控制台,在工作空间列表中选择和DataWorks同名的工作空间后,前往AI 资产管理 > 数据集。
-
点击新建数据集,填写以下核心参数:
-
类型:务必选择高级型。
-
内容类型:选择图片。
-
OSS 路径:指定您存放原始图片的 OSS 目录。
-
-
为数据集指定一个有意义的名称(例如:
自动驾驶图片数据集_测试),然后点击确定。重要该名称直接作为DataWorks中的数据集名称。
-
-
初始化元数据
-
操作路径:返回数据集列表,进入刚刚创建的数据集详情页。
-
在版本详情 > 元数据标签页下,点击立即更新。
-
PAI 会启动一个后台任务,扫描您 OSS 路径下的所有图片文件并采集基础元数据。请耐心等待任务完成。
-
二、启用标签筛选能力
目标:利用大模型为图片自动生成业务标签。
-
创建智能打标模型连接:为了让 PAI 任务能访问到外部大模型服务,需要建立连接。
-
操作路径:进入AI 资产管理 > 连接。
-
点击模型服务 > 新建连接。
-
选择百炼大模型服务,并填入获取的API Key。

-
-
-
定义标签体系
-
操作路径:进入AI 资产管理 > 数据集 > 智能标签定义标签页。
-
点击新建智能标签定义,配置您的标签规则。
-
引导提示词: 给予模型一个角色和背景,例如:“
你是一名经验丰富的交通场景分析师...” -
标签定义: 使用 JSON 格式定义标签及其描述,例如:
{ "减速带": "一般为黄黑相间,横在路上的条状突起,用于车辆减速。", "非机动车": "包括自行车、电动车、轮椅等。" }
-
-
-
运行智能打标任务
-
操作路径:进入AI 资产管理 > 任务 > 数据集任务。
-
选择步骤一创建的OSS数据集,点击新建任务 > 智能打标。

-
配置以下参数:
-
智能打标模型连接:选择您已创建的百炼模型连接。
-
智能打标模型:选择
Qwen-VL Max或Plus。 -
智能标签定义:选择您刚刚创建的标签定义。
-
打标模式:首次打标可选择全量。
-
-
点击确定,启动任务。
-
三、启用语义检索能力
目标:为图片生成向量特征,并存入数据库以供语义搜索或以图搜图。
-
创建语义索引模型连接
-
进入AI 资产管理 > 连接 > 模型服务页签。
-
点击新建连接,选择通用多模态 Embedding 模型服务,并关联到您已部署的 GME EAS 服务。
若未部署EAS服务,请前往控制台首页 > 快速开始 > Model Gallery处部署。

-
-
创建向量数据库连接
-
进入AI资产管理 > 连接 > 数据库。
-
点击新建连接,选择您的数据库类型(如 Milvus),并填入实例的uri、token、database。
字段填写指南,可参见2.3 创建向量数据库连接。
-
-
配置索引库
-
操作路径:返回数据集详情页,找到索引库配置区域。
-
点击编辑,配置相关信息。
-
索引模型连接:选择您已创建的 GME 模型服务连接。
-
索引数据库连接:选择您已创建的向量数据库连接。
-
索引数据库表:填写您在向量数据库中用于存储向量的表名/集合名(例如:
traffic_image_embeddings)。
-
-
-
运行语义索引任务
-
操作路径:进入AI资产管理 > 任务 > 数据集任务标签页。
-
选择已创建的OSS数据集,点击新建任务 > 语义索引。
-
选择需要处理的数据集版本,然后点击确定,启动任务。
-



当 PAI 中的智能打标和语义索引任务状态显示为执行成功后,稍等片刻,您即可在 DataWorks 数据地图中看到对应数据集出现索引检索或标签搜索。
DataWorks侧发现和使用增强型数据集
一旦您在 PAI 平台成功创建并处理了数据集,DataWorks 数据地图会自动同步这些元数据。您无需在 DataWorks 中进行额外注册,可以直接开始探索和使用。
一、发现数据集
首先,您需要在 DataWorks 中找到您的数据集。
-
在 DataWorks 控制台,单击进入数据地图。单击左侧导航栏
,进入搜索页面。 -
在顶部的搜索框中,输入与您数据集相关的关键词进行搜索。支持多种方式:
-
按名称搜索:例如,输入
自动驾驶。 -
按描述搜索:例如,输入
交通、图像。 -
按路径搜索:例如,输入部分 OSS 路径片段
traffic_images。
-
-
系统会实时展示所有匹配的数据集。您可以:
-
排序:按相关性或更新时间对结果进行排序。
-
切换视图:在画廊和列表两种模式间切换,悬停可快速预览基本信息。
-
精确筛选:使用左侧的筛选栏,通过数据来源、所属工作空间等条件进一步定位资源。
-
二、探索数据集详情
找到目标数据集后,点击进入详情页,全面了解其信息。
-
查看核心属性
在详情页,您可以直观地看到数据集的名称、描述、负责人、更新时间等元数据。通过数据集版本列表,可以追溯和查看不同版本的详细配置,如存储路径、默认挂载路径等。 -
阅读使用说明
如果数据集负责人编写详细的使用说明,您可以在此找到操作手册、字段字典、示例代码或合规声明,帮助您更好地理解和使用数据。
三、与数据交互:预览、筛选与检索
这是体验 PAI 增强能力的核心环节。在数据集详情页,切换到数据查看标签页。
若未运行增强任务,DataWorks 仅显示基础元数据(名称、路径、文件列表),无标签、无语义搜索。
基础筛选:按元数据过滤
这是所有图片数据集都具备的基础能力。您可以通过文件元数据进行筛选。
-
示例:筛选出
文件最后修改时间 > 2025-05-01的所有图片。
增强能力 ①:多维标签组合筛选
此功能仅在 PAI 侧的“智能打标”任务成功运行后可用。
您可以像使用电商网站的筛选器一样,通过标签组合来精确定位图片。
-
示例:筛选出
包含任意标签: 机动车且排除以下标签: 斑马线的图片。
增强能力 ②:语义检索与以图搜图
此功能仅在 PAI 侧的“语义索引”任务成功运行后可用。
您可以直接用自然语言或上传图片来搜索您想要的数据。
-
自然语言搜索
在顶部的搜索框中,输入您想查找的场景描述。-
示例:输入“
道路中行驶的红色的车”。 -
系统将基于向量相似度,返回最匹配的图片列表。
-
-
查看单张图片详情
点击任意一张搜索结果图片,可以查看其大图和由 PAI 自动生成的所有标签。 -
以图搜图
点击搜索框旁的图片图标,您可以上传本地图片或指定 OSS 图片,系统会自动查找数据集中与该图片内容最相似的图片。
常见问题 (FAQ)
-
Q1: 为什么我在 DataWorks 中搜索不到我的 PAI 数据集?
-
可能原因:数据集与 DataWorks 不在同一个阿里云主账号下。系统不支持跨租户的数据同步。
-
解决方案:请确保您创建 PAI 数据集和使用 DataWorks 的是同一个主账号。
-
-
Q2: 为什么我的数据集详情页没有“标签筛选”功能?
-
可能原因:这是因为 PAI 平台的“智能打标”任务没有成功运行,或者仍在运行中。DataWorks 侧的功能依赖于 PAI 任务的成功结果。
-
解决方案:
-
前往 PAI 控制台,检查对应智能打标任务的运行状态,确保其显示为执行成功。
-
如果任务失败,请查看 PAI 任务日志,排查
Qwen-VL模型调用是否出错。
-
-
-
Q3: 为什么语义搜索(或以图搜图)没有任何结果?
-
可能原因:PAI 服务无法访问到您的向量数据库(如 Milvus),这通常是网络不通或白名单配置问题。
-
解决方案:
-
首先,请在 PAI 控制台确认“语义索引”任务已经成功运行。
-
然后,请将网络配置以及白名单配置添加到您 Milvus 实例的访问白名单中。
-
-
场景三:AI增强型文档知识库(基于PAI LangStudio)公测中
本场景适用于已在 PAI LangStudio 中构建文档型知识库(如企业制度、技术手册、合规文档)的用户。通过将知识库与 DataWorks 数据地图打通,您可以将这些宝贵的非结构化知识资产纳入企业统一的数据目录,并为其赋予强大的语义检索能力。
核心价值:让知识“搜得到、看得懂”
传统的关键词搜索难以理解复杂的自然语言问题,常常返回不相关的结果。本功能解决了这一痛点,其核心价值在于:
-
统一发现:将散落在各处的文档知识库,与结构化数据、图片数据一起,在 DataWorks 数据地图中进行统一的搜索和管理。
-
精准检索:支持直接用自然语言提问(例如:“跨境数据传输需要哪些审批流程?”),系统能理解问题意图,并从海量文档中精准定位到包含答案的段落。
-
支撑 RAG 应用:为构建更智能的 RAG(检索增强生成)应用(如企业智能问答机器人)提供了高质量、可检索的数据基础。
示例场景:从海量合规文档中快速定位关键条款
一家金融机构的风控团队面临一个难题:他们拥有数百份 PDF 格式的数据治理与合规文档,形成了一个庞大的内部知识库。当需要查找某个特定条款时,例如“关于跨境数据传输的具体审批要求”,传统的关键词搜索效果不佳,往往返回大量不相关的文档,需要耗费大量时间人工筛选。
通过 PAI LangStudio 对这些文档构建向量索引,并与 DataWorks 数据地图结合,团队成员现在可以直接在 DataWorks 中输入自然语言问题。系统能够理解问题的语义,并返回包含答案的法规条款原文,提升信息获取效率。
步骤一:在 PAI LangStudio 中准备知识库
本节所有操作均在 PAI LangStudio 控制台完成。DataWorks 侧只负责同步和呈现 PAI 的处理结果。语义检索能力能否生效,完全取决于以下步骤是否成功完成。
前提条件
在开始之前,请确认以下条件已满足:
|
条件 |
要求说明 |
|
主账号一致 |
使用 PAI LangStudio 和 DataWorks 的必须是同一个阿里云主账号。 |
|
知识库类型 |
必须是 文档型。当前支持 |
|
地域支持 |
您所在的地域需在 PAI LangStudio 支持的范围内(如杭州、上海、北京等)。 |
|
向量索引状态 |
知识库必须已成功构建向量索引,且状态为“就绪”。 |
关键操作指引
-
创建文档型知识库
-
操作路径:进入LangStudio,选择工作空间后,选择知识库页签。
-
点击新建知识库,并配置以下核心参数:
-
知识库名称:为您的知识库命名,例如
data_governance_kb。 -
知识库类型:选择文档。
-
数据源OSS路径:指定一个 OSS 目录,用于存放您的原始文档。
-
向量数据库类型:选择Milvus。
-
-
创建后,通过详情页的上传按钮,将您的文档(如 PDF、Word 等)上传到数据源。
推荐文档命名规范:
{领域}_{主题}_v{版本},例如finance_compliance_v2。
-
-
构建向量索引
-
操作路径:进入刚刚创建的知识库详情页。
-
点击页面右上角的更新索引。系统会启动一个后台任务,该任务会自动完成以下工作:
重要新增文档后如果期望自动处理,需要在LangStudio配置周期触发向量索引重建。
-
文档解析与分块:将长文档切分成包含完整语义的文本块(Chunk)。
-
向量化 (Embedding):调用内置的 Embedding 模型,将每个文本块转换为数字向量。
-
入库与索引:将生成的向量存入您选择的向量数据库(如 FAISS)并创建索引。
-
-
等待该任务完成,直到 文件状态 变为“已索引”,或在 操作记录 中看到任务状态为“成功”。
-
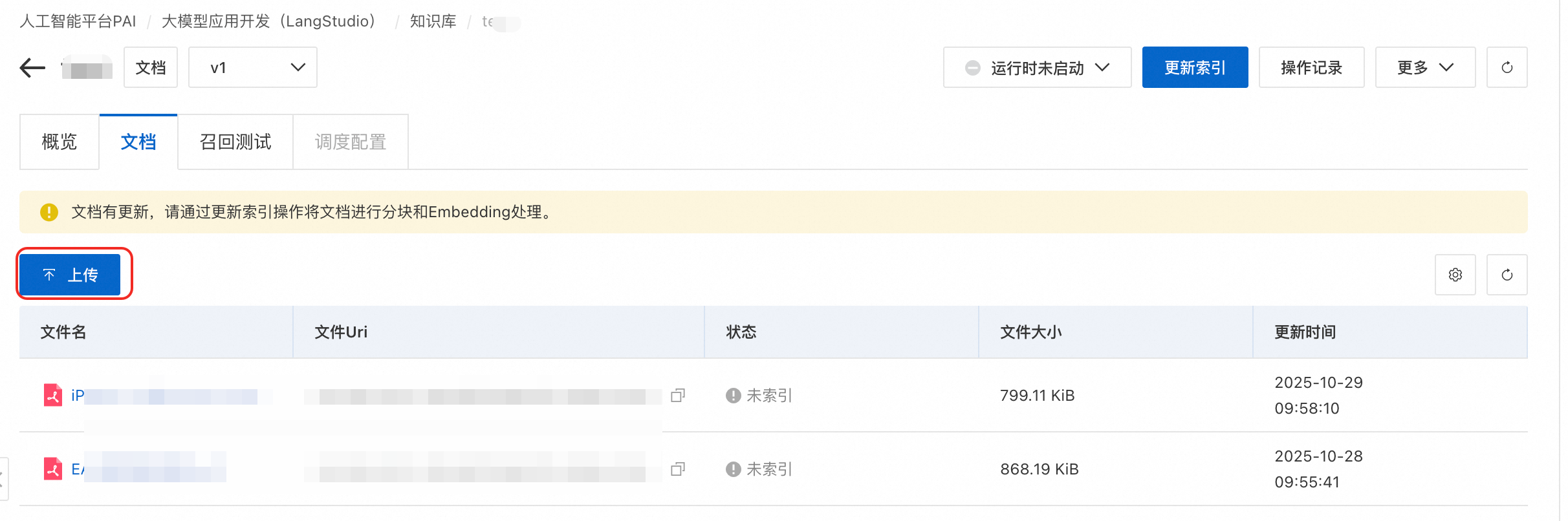
当 PAI LangStudio 中知识库的向量索引状态显示为“就绪”后,DataWorks 数据地图会自动同步该资产,并为其开启语义搜索功能。
步骤二:在 DataWorks 中检索和使用知识库
完成 PAI 侧的准备后,团队成员即可在 DataWorks 中享受便捷的知识检索体验。
-
搜索知识库资产
-
操作路径:进入 DataWorks > 数据地图 > 搜索 页面。
-
通过知识库名称(例如
governance)或描述中的关键词进行搜索,在结果中找到您的知识库资产。
-
-
进行语义检索
-
点击进入知识库详情页,切换到数据查看标签页。
-
在顶部的搜索框中,直接输入您的自然语言问题。
示例:
数据质量的规范包含哪些内容? -
系统将实时返回最相关的文档片段,并高亮显示匹配内容。每个片段下方都会标注其来源文件名和页码,方便您快速追溯原文。
-
-
使用与追溯
-
通过返回的文档片段,您可以快速获取答案。
-
如果需要查看完整上下文,可以根据来源文件名在原始知识库中找到并阅读整个文档。
-
常见问题 (FAQ)
-
Q: 为什么在 DataWorks 中搜不到我的 LangStudio 知识库?
-
原因 1:PAI 和 DataWorks 不在同一个阿里云主账号下。
-
原因 2:知识库类型不是“文档型”(例如,是“图片”或“结构化数据”类型)。
-
解决方案:请检查并确保满足上述两个前提条件。
-
-
Q: 为什么我的知识库详情页没有语义搜索框?
-
原因:知识库的向量索引没有成功构建或仍在构建中。
-
解决方案:请返回 PAI LangStudio,检查知识库的更新索引任务是否已成功完成,且状态为“就绪”。
-
-
Q: 语义搜索返回的结果不准确或不相关,怎么办?
-
原因:这通常与文档的分块策略有关。如果分块太小,可能导致语义不完整;如果太大,则可能引入过多无关信息。
-
解决方案:返回 PAI LangStudio,在知识库配置中调整文本分块大小和重叠大小,然后重新更新索引。这是一个需要根据您的文档特性进行迭代优化的过程。
-