当项目用户具备查询E-MapReduce项目中的某些敏感数据权限,担忧不希望用户能看到完整的敏感数据信息时,可以对查询结果进行数据动态脱敏。本文为您介绍如何开启E-MapReduce的动态脱敏功能,并提供参考示例。
使用限制
EMR集群仅支持数据保护伞的敏感数据发现和数据脱敏功能,不支持其它数据保护伞功能。
敏感数据发现和数据脱敏目前只支持部分EMR集群类型和表类型,详情请参见支持Hive表在数据地图中预览的类型。
保护伞元侧元数据为T+1更新,如需使用EMR数据脱敏,需提前一天创建好需要脱敏的数据。
仅支持独享调度资源组,详情请参见:独享调度资源组。
准备工作
前置条件
数据保护伞默认使用主账号映射的集群账号进行数据抽样,如果您的集群开启了 LDAP 或 Kerberos 认证、使用 Ranger 或 DLF-Auth 管理表权限,需要您为主账号配置账号映射,并保证映射后的集群账号有权限访问 EMR 集群中的表。详情请参见旧版数据开发:绑定EMR计算资源。
数据准备
创建E-MapReduce表
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在数据开发页面单击新建,选择创建Hive节点。
编辑节点代码,新建
onefall_test_dsg表。CREATE TABLE IF NOT EXISTS onefall_test_dsg ( username STRING ,gender STRING ,phone STRING ,email STRING ,card_no STRING ,address STRING ,zip_code STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY',' ;导入测试数据至
onefall_test_dsg表。本案例提供测试数据data.csv,下载该测试数据。
导入测试数据。
将data.csv 上传到 EMR 集群某个节点上,通过SQL加载测试数据。
LOAD DATA LOCAL INPATH '/…/data.csv' OVERWRITE INTO TABLE onefall_test_dsg;将data.csv上传至OSS对象存储中,通过SQL加载测试数据。
LOAD DATA INPATH 'oss://bucket-name.Endpoint/…/data.csv' OVERWRITE INTO TABLE onefall_test_dsg ;
数据保护伞元数据更新
保护伞元侧元数据为T+1更新,在创建并发布onefall_test_dsg表后,需要等至第二天再进行数据脱敏操作。
配置数据脱敏
步骤一:新建数据识别规则
DataWorks通过识别规则对E-MapReduce表中的字段进行识别,所以在配置脱敏规则之前,必须配置相应的识别规则,具体详情请参见配置数据识别规则并执行识别任务。
进入数据识别规则
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在右侧页面中单击进入安全中心。
单击左侧导航栏的,单击立即体验,进入数据保护伞。
说明若阿里云主账号已授权,则直接进入数据保护伞的首页。
若阿里云主账号未授权,则进入数据保护伞的授权页面。授权后才可使用保护伞的相关功能。
单击左侧导航栏的,进入数据识别规则页面。
配置识别规则
本示例以数据准备模块创建的表为例,来新建识别规则,目的为识别出onefall_test_dsg表中的gender、phone和email字段,并且将这三个字段进行脱敏处理。
选择敏感字段所在的数据分类。
在左侧的内置分类分级模板区域选择新增敏感字段所在的数据分类,详情请参见配置数据识别规则并执行识别任务。
新增敏感字段类型并配置识别规则。
单击右上角敏感字段类型,出现识别规则配置页面。详细配置请参见配置数据识别规则并执行识别任务。
说明为方便对敏感字段类型理解,可将敏感字段类型配置为
onefall_test_dsg表的字段名gender、phone和email配置完成数据识别规则后,单击右上角的批量发布,选中创建好的识别规则,即可进行批量发布。

步骤二:创建数据脱敏管理
DataWorks通过配置数据脱敏规则对E-MapReduce表中的字段进行脱敏,在配置脱敏规则之前,具体详情请参见创建数据脱敏规则。
进入数据脱敏规则
登录DataWorks控制台后,进入数据保护伞页面,操作详情请参见数据保护伞。
单击开始体验,默认进入数据保护伞的首页。
单击左侧导航栏中的,在数据脱敏管理页面您可以创建新的场景类型并配置脱敏规则。
新增脱敏场景
DataWorks提供的数据开发/数据地图展示脱敏、数据分析展示脱敏、MaxCompute引擎层脱敏、Hologres引擎层脱敏等动态脱敏,及数据集成静态脱敏等一级脱敏场景为固定场景,不支持执行新增、编辑、删除等操作,可基于业务需要,基于一级场景自定义二级场景。具体详情请参见创建数据脱敏场景。
本示例以数据开发/数据地图展示脱敏和数据分析展示脱敏为主。
数据开发/数据地图展示脱敏下的二级场景名:
开发展示。数据分析展示脱敏下的二级场景名:
SQL分析。
新增脱敏规则
完成脱敏场景创建后,即可单击右上角的脱敏规则来新建脱敏规则,依旧是新建三条脱敏规则,以gender、phone和email命名。具体详情请参见创建数据脱敏规则。
选择脱敏场景。
在数据脱敏管理页面,选择脱敏场景为,单击右侧+脱敏规则。
新建数据脱敏规则。
步骤三:开启数据敏感识别
生产环境保护伞每天获取完 E-MapReduce 元数据后,会继续调用 DataWorks 元数据 OpenAPI 获取表的抽样数据,根据敏感数据识别规则,识别出敏感字段,本案例为测试案例,可通过手动开启识别规则,识别出敏感字段。
单击左侧导航栏中的进入敏感数据识别页面。
在敏感数据识别左上角单击开启任务,即可进入开启敏感数据识别任务面板进行配置。
任务类型:手动任务。
识别账号:通过当前账号对数据进行抽样和扫描,账号权限不同可抽样的数据范围会有所不同。本案例选择主账号。
内容识别:可选择对表内容识别和元数据识别。本案例选择内容识别。
抽样数量:自定义抽样数量,保持默认100条即可。
扫描范围:配置为自定义范围,通过项目空间/数据库范围来框选扫描范围。
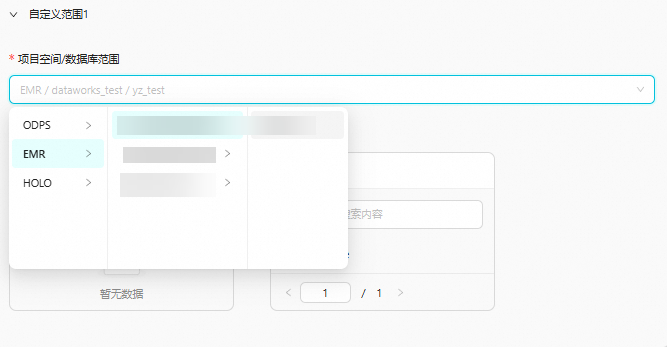
本示例的表名为
onefall_test_dsg。
圈选好范围后,单击面板右下角开启按钮,开启数据识别任务。
说明数据识别任务可在敏感数据识别页面,单击任务执行记录查看数据识别任务的执行详情。
查询SQL确认脱敏结果
查看E-MapReduce表预览脱敏
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在右侧页面中单击进入数据地图。
单击左侧
 按钮,切换至搜索页面后,单击页面上部下拉框,切换为E-MapReduce数据源后,搜索表名
按钮,切换至搜索页面后,单击页面上部下拉框,切换为E-MapReduce数据源后,搜索表名onefall_test_dsg。单击搜索到的表名,进入表详情侧面后,单击数据预览即可对本示例的表数据进行预览。
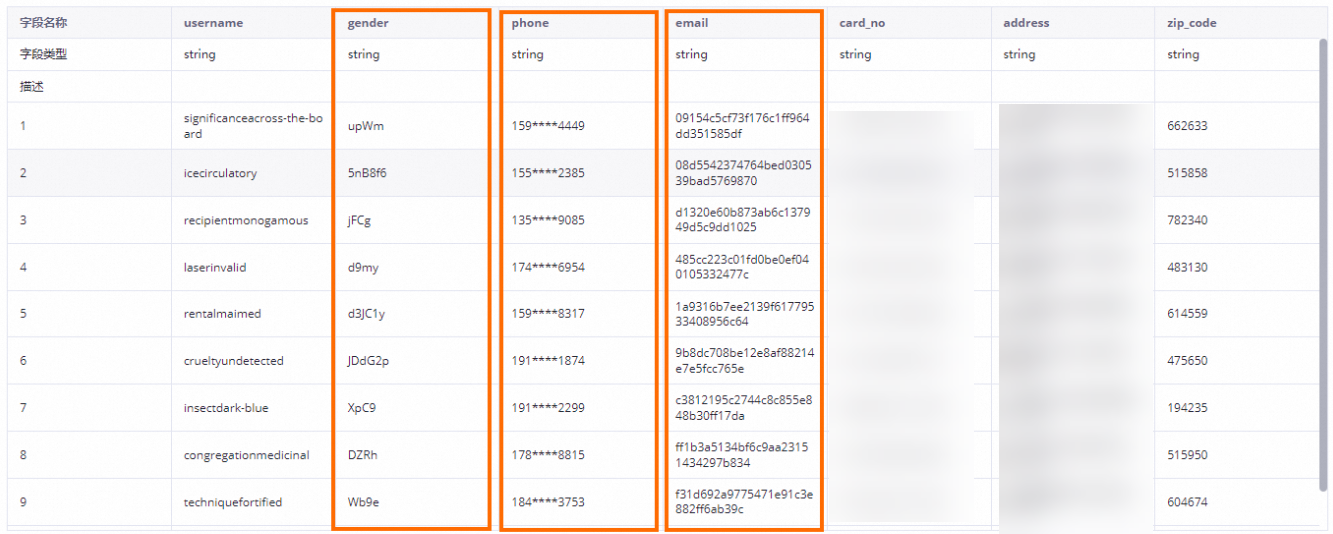
表中的字段在数据预览中已按照配置的识别规则和脱敏规则进行脱敏。
查看数据开发界面脱敏结果
DataWorks开发界面查询脱敏数据,受数据开发项目空间级别开关控制,打开步骤如下。
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
单击左侧功能栏的
 按钮,进入开发项目空间设置页面。
按钮,进入开发项目空间设置页面。在开发项目空间设置页面单击安全设置与其他,打开的开关。
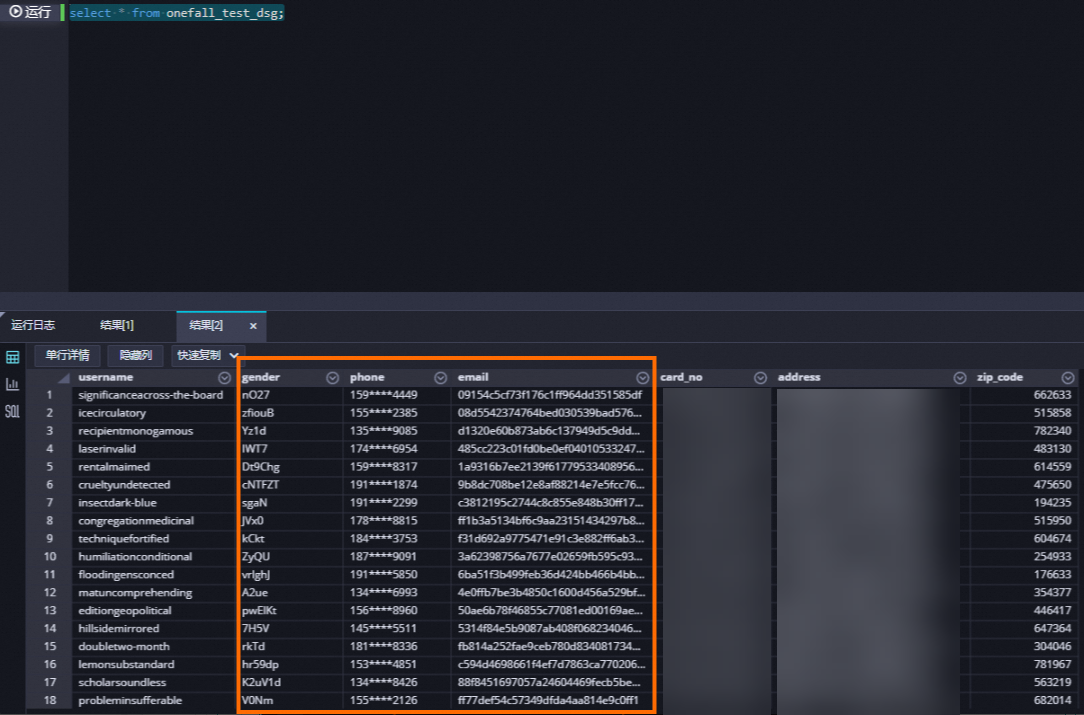
测试查询结果脱敏
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
单击左侧
 ,进入临时查询查询页面后单击,新建临时查询节点。
,进入临时查询查询页面后单击,新建临时查询节点。在节点查询
onefall_test_dsg表,即可查看在数据开发页面该表的脱敏展示。SELECT * FROM onefall_test_dsg;