
背景
随着业务复杂程度的提高、数据规模的增长,越来越多的公司选择对其在线业务数据库进行垂直或水平拆分,甚至选择不同的数据库类型以满足其业务需求。与此同时,业务的数据被“散落”在各个数据库实例中。如何方便地对这些数据进行汇总查询,已经成为困扰用户的一大问题。
例如,一家电商创业公司,最初的会员、商品、订单数据全部都存放在一个SQLServer实例中。但随着会员数量和交易规模的不断增长,单个SQLServer实例已经支撑不了巨大的业务压力,同时基于成本考虑,将商品和订单表从原来的SQLServer中拆分出来,分别存放到两个不同的MySQL实例中。原先用户连接到一个实例上即可执行一条SQL来关联汇总查询这三张表的数据,但现在由于数据库拆分,无法简易实现这一操作。
针对这类问题,我们提供了一套基于DBLink的解决方案,用户通过一条SQL就能实现跨越多个数据库实例的查询。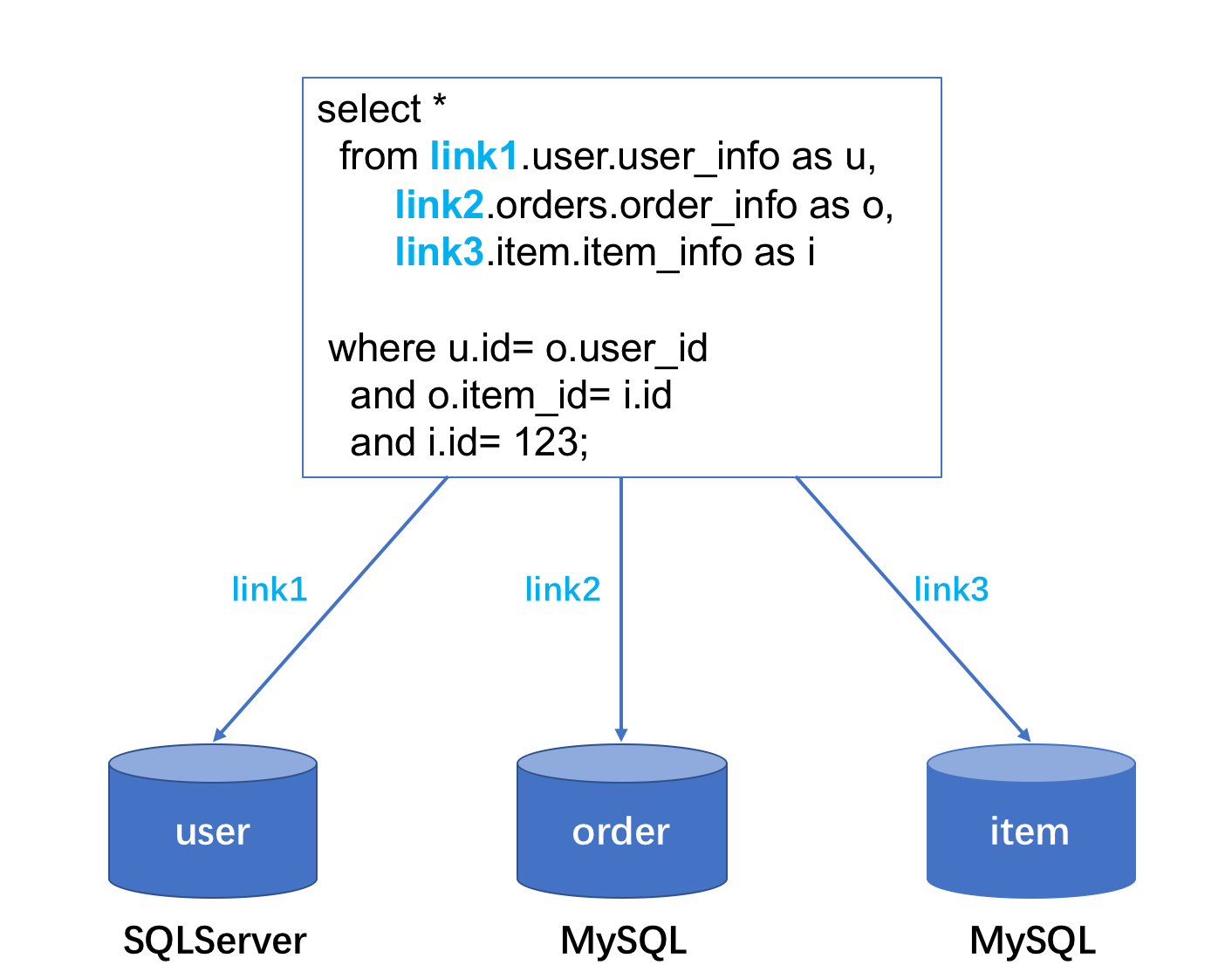
什么是DBLink
熟悉Oracle的人应该知道,我们可以在当前登录的Oracle上,建立一个DBLink指向另一个远程的Oracle数据库表。
类似的,跨数据库查询中的DBLink,是一个指向用户的任意数据库实例的虚拟连接,是数据库实例的别名:
DBLink和数据库实例一一对应,对于MySQL来说,对应的就是MySQL数据库所在的ip:port
DBLink可以指向MySQL、SQLServer、PostgreSQL、Oracle、Redis等;
用户需在SQL语句的库表名前加上DBLink前缀(DBLink.库.表),即可实现跨数据库查询。
DBLink的名字由英文字母、数字和下划线组成
DBLink/database/table对应关系
数据库系统通常把数据组织成层次结构,如:database、schema、table等,以方便命名空间隔离和权限管理。跨库查询也是类似,它以dblink、database和table这三层结构来组织。
在跨库查询中,用户访问一个表需要指定全名称,即:dblink.database.table。然而,不同数据库类型具有不同的层次组织,为了实现统一查询,需要将这些不同层次结构统一起来,形成DBLink、database和table三层结构。下表描述了跨库查询服务与MySQL、PostgreSQL、SQLServer和Redis之间层次结构的映射关系:
| 跨库查询 | MySQL | PostgreSQL | SQLServer | Redis |
|---|---|---|---|---|
| DBLink | ip+port | ip+port+database | ip+port | ip+port |
| database | database | schema | database | database,例如:db[0-16] |
| table | table | table | table | Redis本身无table的概念,跨库查询服务根据Redis数据类型,分别映射出固定的几张表:string、set、zset、list、hash、all |