
文档解析(大模型版)接口可进行通用文档抽取和理解,支持多种常见格式的文档,能从文档中提取出丰富的版面信息等,支持输出Markdown格式的内容。本文介绍如何调用该API,调用前请先阅读API使用指南。
调用方式
文档解析(大模型版)接口为异步接口,需要先调用文档解析异步提交服务SubmitDocParserJobAdvance或SubmitDocParserJob接口进行异步任务提交,然后调用文档解析(大模型版)状态查询服务QueryDocParserStatus接口进行处理状态查询,最后根据处理状态,调用GetDocParserResult接口进行结果查询。如下所示为文档解析(大模型版)使用流程图:

-
文档解析(大模型版)免费额度为每月3000页,用完即止。若您的免费额度或资源包消耗完毕,系统将默认采用按量付费的后付费计费方式。当异步任务处理提交后,用户可以在处理结束后的24小时之内查询处理结果,超过24小时后将无法查询到处理结果。
-
支持的文档格式:pdf、word、ppt、pptx、xls、xlsx、xlsm和图片,图片支持jpg、jpeg、png、bmp、gif,其余格式支持markdown、html、epub、mobi、rtf、txt。
-
支持的音视频格式:mp4、mkv、avi、mov、wmv、mp3、wav、aac。
-
文档解析(大模型版)支持解析文档中的图片和表格,图表类的图片会接入chart2table,将图表类的图片转换成表格形式输出。
-
从对文档中表格场景的解析效果来看,文档解析(大模型版)> 文档智能解析>电子文档解析,因此推荐优先使用文档解析(大模型版)解析文档。从整体解析速度来看,电子文档解析>文档解析(大模型版)>文档智能解析。
步骤一:调用文档解析(大模型版)异步提交服务SubmitDocParserJob接口
异步提交服务支持本地文件和url文件两种方式:
-
本地文件上传的异步提交服务接口为:SubmitDocParserJobAdvance接口。
-
url文件上传的异步提交服务接口为:SubmitDocParserJob接口。
-
异步处理的时长以实际测试为准,开通电子文档解析服务后我们会提供免费额度供您测试。
-
FileName、FileNameExtension参数,服务会根据后缀配置解析器,若不确定文档类型,可配置无后缀的文件名后台进行默认路由配置,避免非预期解析结果产生。
请求参数
|
名称 |
类型 |
必填 |
描述 |
示例值 |
|
FileUrl |
string |
否 |
以文档url上传方式调用接口时使用。 单个文档(支持1.5万页及以内且150 MB以内的PDF、Word等文档,支持20 MB以内的单张图片)。 |
https://example.com/example.pdf |
|
FileUrlObject |
stream |
否 |
以本地文件上传方式调用接口时使用。 单个文档(支持1.5万页及以内且150 MB以内的PDF、Word等文档,支持20 MB以内的单张图片)。 |
本地文件生成的FileInputStream |
|
FileName |
string |
否 |
文件名需带文件类型后缀,与FileNameExtension二选一。 |
example.pdf |
|
FileNameExtension |
string |
否 |
文件类型,与FileName二选一。 |
|
|
FormulaEnhancement |
bool |
否 |
开启公式识别增强选项,默认为False。 |
True |
|
LlmEnhancement |
bool |
否 |
开启大模型增强选项,默认为False。注意:若开启,接口响应时间可能会显著增加,请按需开启。开启后,以下2种情况会返回大模型解析结果:
|
False |
|
EnhancementMode |
string |
否 |
大模型增强模式,默认为空(关闭)。仅当设置 目前支持以下选项:
注意:若开启,接口响应时间可能会显著增加,同时每页费用会增加,请按需开启。 |
VLM |
|
Option |
string |
否 |
音视频文件解析支持配置选项,默认为Base。 base:基本识别功能,默认值。 advance:加强识别功能,在base结果基础上增加返回剧情解析结果。 |
Base |
|
OssBucket |
string |
否 |
个人的oss bucket名称,具体可查看OSS托管支持 |
docmind-trust |
|
OssEndpoint |
string |
否 |
个人的oss endpoint地址,具体可查看OSS托管支持 |
oss-cn-hangzhou.aliyuncs.com |
|
PageIndex |
string |
否 |
文件解析的页数。注:必须为1-n的格式。 |
1-5 |
|
OutputHtmlTable |
bool |
否 |
是否返回HTML格式的表格内容,默认为 False。开启后,对于 表格类型 的版面块,会返回此表格的HTML格式解析内容,存放在此版面块的 ⚠️ 请注意:若开启此参数,需同步开启LlmEnhancement参数,接口响应时间也可能会增加,请按需开启。 |
false |
|
EnableEventCallback |
bool |
否 |
是否开启事件回调,默认为 False。具体可查看事件总线支持。 |
false |
|
OutputFormat |
List<String> |
否 |
解析结果输出格式。 |
markdown |
|
MultimediaParameters |
object |
否 |
当文件类型为音视频时,可通过本字段设置可选功能。开启此参数后将忽略Option入参。 |
|
|
string |
否 |
帧解析prompt(0725已支持) |
##限制:- 不要输出过长的句子,忠实于原图、捕捉关键信息即可。##限制:- 不要输出过长的句子,忠实于原图、捕捉关键信息即可。 |
-
PageIndex参数只支持pdf、word、ppt三种格式的文件解析使用。
-
OutputFormat参数支持的类型如下:
-
markdown:状态查询服务中会返回文档的markdown结果。
-
visualLayoutInfo:QueryDocParserStatus状态查询服务中会返回文档页Page图片信息,GetDocParserResult结果查询服务中会返回layout的坐标信息。
-
-
VLM增强链路开启后支持33种语种:
-
中文、日语、韩语、印尼语、越南语、泰语、英语、法语、德语、俄语、葡萄牙语、西班牙语、意大利语、瑞典语、丹麦语、捷克语、挪威语、荷兰语、芬兰语、土耳其语、波兰语、斯瓦希里语、罗马尼亚语、塞尔维亚语、希腊语、哈萨克语、乌兹别克语、宿务语、阿拉伯语、乌尔都语、波斯语、印地语 / 天城语、希伯来语。
-
返回参数
|
名称 |
类型 |
描述 |
示例值 |
|
RequestId |
string |
请求唯一ID。 |
43A29C77-405E-4DC0-BC55-EE694AD0**** |
|
Data |
object |
返回数据。 |
{"Id": "docmind-20240712-b15f****"} |
|
Id |
string |
业务订单号,用于后续查询接口进行查询的唯一标识。 |
doc-mind-20220712-b15f**** |
|
Code |
string |
状态码。 |
200 |
|
Message |
string |
状态详细信息。 |
Message |
使用示例
本接口支持本地文件上传和url文件上传这两种调用方式。
-
本地文件上传:以Java SDK为例,本地文件上传调用方式的请求示例代码如下,调用PDF转Word异步提交服务用SubmitDocParserJobAdvance接口,通过fileUrlObject参数实现本地文档上传。
import com.aliyun.docmind_api20220711.models.*; import com.aliyun.teaopenapi.models.Config; import com.aliyun.docmind_api20220711.Client; import com.aliyun.teautil.models.RuntimeOptions; import java.io.File; import java.io.FileInputStream; public static void main(String[] args) throws Exception { submit(); } public static void submit() throws Exception { // 使用默认凭证初始化Credentials Client。 com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client(); Config config = new Config() // 通过credentials获取配置中的AccessKey ID .setAccessKeyId(credentialClient.getAccessKeyId()) // 通过credentials获取配置中的AccessKey Secret .setAccessKeySecret(credentialClient.getAccessKeySecret()); // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com"; Client client = new Client(config); // 创建RuntimeObject实例并设置运行参数 RuntimeOptions runtime = new RuntimeOptions(); SubmitDocParserJobAdvanceRequest advanceRequest = new SubmitDocParserJobAdvanceRequest(); File file = new File("D:\\example.pdf"); advanceRequest.fileUrlObject = new FileInputStream(file); advanceRequest.fileName = "example.pdf"; // 发起请求并处理应答或异常。 SubmitDocParserJobResponse response = client.submitDocParserJobAdvance(advanceRequest, runtime); System.out.println(com.alibaba.fastjson.JSON.toJSON(response.getBody())); }const Client = require('@alicloud/docmind-api20220711'); const Credential = require('@alicloud/credentials'); const Util = require('@alicloud/tea-util'); const fs = require('fs'); const getResult = async () => { // 使用默认凭证初始化Credentials Client const cred = new Credential.default(); const client = new Client.default({ // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com endpoint: 'docmind-api.cn-hangzhou.aliyuncs.com', // 通过credentials获取配置中的AccessKey ID accessKeyId: cred.credential.accessKeyId, // 通过credentials获取配置中的AccessKey Secret accessKeySecret: cred.credential.accessKeySecret, type: 'access_key', regionId: 'cn-hangzhou' }); const advanceRequest = new Client.SubmitDocParserJobAdvanceRequest(); const file = fs.createReadStream('./example.pdf'); advanceRequest.fileUrlObject = file; advanceRequest.fileName = 'example.pdf'; const runtimeObject = new Util.RuntimeOptions({}); const response = await client.submitDocParserJobAdvance(advanceRequest, runtimeObject); return response.body; };from alibabacloud_docmind_api20220711.client import Client as docmind_api20220711Client from alibabacloud_tea_openapi import models as open_api_models from alibabacloud_docmind_api20220711 import models as docmind_api20220711_models from alibabacloud_tea_util.client import Client as UtilClient from alibabacloud_tea_util import models as util_models from alibabacloud_credentials.client import Client as CredClient if __name__ == '__main__': # 使用默认凭证初始化Credentials Client。 cred=CredClient() config = open_api_models.Config( # 通过credentials获取配置中的AccessKey ID access_key_id=cred.get_credential().get_access_key_id(), # 通过credentials获取配置中的AccessKey Secret access_key_secret=cred.get_credential().get_access_key_secret() ) # 访问的域名 config.endpoint = f'docmind-api.cn-hangzhou.aliyuncs.com' client = docmind_api20220711Client(config) request = docmind_api20220711_models.SubmitDocParserJobAdvanceRequest( # file_url_object : 本地文件流 file_url_object=open("./example.pdf", "rb"), # file_name :文件名称。名称必须包含文件类型 file_name='123.pdf', # file_name_extension : 文件后缀格式。与文件名二选一 file_name_extension='pdf' ) runtime = util_models.RuntimeOptions() try: # 复制代码运行请自行打印 API 的返回值 response = client.submit_doc_parser_job_advance(request, runtime) # API返回值格式层级为 body -> data -> 具体属性。可根据业务需要打印相应的结果。如下示例为打印返回的业务id格式 # 获取属性值均以小写开头, print(response.body) except Exception as error: # 如有需要,请打印 error UtilClient.assert_as_string(error.message)import ( "fmt" "os" openClient "github.com/alibabacloud-go/darabonba-openapi/v2/client" "github.com/alibabacloud-go/docmind-api-20220711/client" "github.com/alibabacloud-go/tea-utils/v2/service" "github.com/aliyun/credentials-go/credentials" ) func submit(){ // 使用默认凭证初始化Credentials Client。 credential, err := credentials.NewCredential(nil) // 通过credentials获取配置中的AccessKey ID accessKeyId, err := credential.GetAccessKeyId() // 通过credentials获取配置中的AccessKey Secret accessKeySecret, err := credential.GetAccessKeySecret() // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com var endpoint string = "docmind-api.cn-hangzhou.aliyuncs.com" config := openClient.Config{AccessKeyId: accessKeyId, AccessKeySecret: accessKeySecret, Endpoint: &endpoint} // 初始化client cli, err := client.NewClient(&config) if err != nil { panic(err) } // 上传本地文档调用接口 filename := "D:\\example.pdf" f, err := os.Open(filename) if err != nil { panic(err) } // 初始化接口request request := client.SubmitDocParserJobAdvanceRequest{ FileName: &filename, FileUrlObject: f, } // 创建RuntimeObject实例并设置运行参数 options := service.RuntimeOptions{} response, err := cli.SubmitDocParserJobAdvance(&request, &options) if err != nil { panic(err) } // 打印结果 fmt.Println(response.Body.String()) } -
url文件上传:以Java SDK为例,传入文档url调用方式的请求示例代码如下,调用SubmitDocParserJob接口,通过fileUrl参数实现传入文档url。请注意,您传入的文档url必须为公网可访问下载的url地址,无跨域限制,url不带特殊转义字符。
说明获取并使用AccessKey信息的方式,可参考SDK概述中不同语言的SDK使用指南。
import com.aliyun.docmind_api20220711.models.*; import com.aliyun.teaopenapi.models.Config; import com.aliyun.docmind_api20220711.Client; public static void main(String[] args) throws Exception { submit(); } public static void submit() throws Exception { // 使用默认凭证初始化Credentials Client。 com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client(); Config config = new Config() // 通过credentials获取配置中的AccessKey ID .setAccessKeyId(credentialClient.getAccessKeyId()) // 通过credentials获取配置中的AccessKey Secret .setAccessKeySecret(credentialClient.getAccessKeySecret()); // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com"; Client client = new Client(config); SubmitDocParserJobRequest request = new SubmitDocParserJobRequest(); request.fileName = "example.pdf"; request.fileUrl = "https://example.com/example.pdf"; SubmitDocParserJobResponse response = client.submitDocParserJob(request); System.out.println(com.alibaba.fastjson.JSON.toJSON(response.getBody())); }const Client = require('@alicloud/docmind-api20220711'); const Credential = require('@alicloud/credentials'); const getResult = async () => { // 使用默认凭证初始化Credentials Client const cred = new Credential.default(); const client = new Client.default({ // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com endpoint: 'docmind-api.cn-hangzhou.aliyuncs.com', // 通过credentials获取配置中的AccessKey ID accessKeyId: cred.credential.accessKeyId, // 通过credentials获取配置中的AccessKey Secret accessKeySecret: cred.credential.accessKeySecret, type: 'access_key', regionId: 'cn-hangzhou' }); const request = new Client.SubmitDocParserJobRequest(); request.fileName = 'example.pdf'; request.fileUrl = 'https://example.com/example.pdf'; const response = await client.submitDocParserJob(request); return response.body; }from alibabacloud_docmind_api20220711.client import Client as docmind_api20220711Client from alibabacloud_tea_openapi import models as open_api_models from alibabacloud_docmind_api20220711 import models as docmind_api20220711_models from alibabacloud_tea_util.client import Client as UtilClient from alibabacloud_credentials.client import Client as CredClient if __name__ == '__main__': # 使用默认凭证初始化Credentials Client。 cred=CredClient() config = open_api_models.Config( # 通过credentials获取配置中的AccessKey ID access_key_id=cred.get_credential().get_access_key_id(), # 通过credentials获取配置中的AccessKey Secret access_key_secret=cred.get_credential().get_access_key_secret() ) # 访问的域名 config.endpoint = f'docmind-api.cn-hangzhou.aliyuncs.com' client = docmind_api20220711Client(config) request = docmind_api20220711_models.SubmitDocParserJobRequest( # file_url : 文件url地址 file_url='https://example.com/example.pdf', # file_name :文件名称。名称必须包含文件类型 file_name='123.pdf', # file_name_extension : 文件后缀格式。与文件名二选一 file_name_extension='pdf' ) try: # 复制代码运行请自行打印 API 的返回值 response = client.submit_doc_parser_job(request) # API返回值格式层级为 body -> data -> 具体属性。可根据业务需要打印相应的结果。如下示例为打印返回的业务id格式 # 获取属性值均以小写开头, print(response.body) except Exception as error: # 如有需要,请打印 error UtilClient.assert_as_string(error.message)import ( "fmt" openClient "github.com/alibabacloud-go/darabonba-openapi/v2/client" "github.com/alibabacloud-go/docmind-api-20220711/client" "github.com/aliyun/credentials-go/credentials" ) func submit(){ // 使用默认凭证初始化Credentials Client。 credential, err := credentials.NewCredential(nil) // 通过credentials获取配置中的AccessKey ID accessKeyId, err := credential.GetAccessKeyId() // 通过credentials获取配置中的AccessKey Secret accessKeySecret, err := credential.GetAccessKeySecret() // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com var endpoint string = "docmind-api.cn-hangzhou.aliyuncs.com" config := openClient.Config{AccessKeyId: accessKeyId, AccessKeySecret: accessKeySecret, Endpoint: &endpoint} // 初始化client cli, err := client.NewClient(&config) if err != nil { panic(err) } // 文件URL fileURL := "https://example.com/example.pdf" // 文件名 fileName := "example.pdf" // 初始化接口request request := client.SubmitDocParserJobRequest{ FileUrl: &fileURL, FileName: &fileName, } response, err := cli.SubmitDocParserJob(&request) if err != nil { panic(err) } // 打印结果 fmt.Println(response.Body.String()) }using Newtonsoft.Json; using System; using System.Collections; using System.Collections.Generic; using System.IO; using System.Threading.Tasks; using Tea; using Tea.Utils; public static void SubmitUrl() { // 使用默认凭证初始化Credentials Client。 var akCredential = new Aliyun.Credentials.Client(null); AlibabaCloud.OpenApiClient.Models.Config config = new AlibabaCloud.OpenApiClient.Models.Config { // 通过credentials获取配置中的AccessKey Secret AccessKeyId = akCredential.GetAccessKeyId(), // 通过credentials获取配置中的AccessKey Secret AccessKeySecret = akCredential.GetAccessKeySecret(), }; // 访问的域名 config.Endpoint = "docmind-api.cn-hangzhou.aliyuncs.com"; AlibabaCloud.SDK.Docmind_api20220711.Client client = new AlibabaCloud.SDK.Docmind_api20220711.Client(config); AlibabaCloud.SDK.Docmind_api20220711.Models.SubmitDocParserJobRequest request = new AlibabaCloud.SDK.Docmind_api20220711.Models.SubmitDocParserJobRequest { FileUrl = "https://example.pdf", FileNameExtension = "pdf" }; try { // 复制代码运行请自行打印 API 的返回值 client.SubmitDocParserJob(request); } catch (TeaException error) { // 如有需要,请打印 error AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message); } catch (Exception _error) { TeaException error = new TeaException(new Dictionary<string, object> { { "message", _error.Message } }); // 如有需要,请打印 error AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message); } }use AlibabaCloud\SDK\Docmindapi\V20220711\Docmindapi; use AlibabaCloud\SDK\Docmindapi\V20220711\Models\SubmitDocStructureJobRequest; use Darabonba\OpenApi\Models\Config; use AlibabaCloud\Tea\Utils\Utils\RuntimeOptions; use AlibabaCloud\Tea\Exception\TeaUnableRetryError; use AlibabaCloud\Credentials\Credential; // 使用默认凭证初始化Credentials Client。 $bearerToken = new Credential(); $config = new Config(); // 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com $config->endpoint = "docmind-api.cn-hangzhou.aliyuncs.com"; // 通过credentials获取配置中的AccessKey ID $config->accessKeyId = $bearerToken->getCredential()->getAccessKeyId(); // 通过credentials获取配置中的AccessKey Secret $config->accessKeySecret = $bearerToken->getCredential()->getAccessKeySecret(); $config->type = "access_key"; $config->regionId = "cn-hangzhou"; $client = new Docmindapi($config); $request = new SubmitDocParserJobRequest(); $runtime = new RuntimeOptions(); $runtime->maxIdleConns = 3; $runtime->connectTimeout = 10000; $runtime->readTimeout = 10000; $request->fileName = "example.pdf"; $request->fileUrl = "https://example.com/example.pdf"; try { $response = $client->submitDocParserJob($request, $runtime); var_dump($response->toMap()); } catch (TeaUnableRetryError $e) { var_dump($e->getMessage()); var_dump($e->getErrorInfo()); var_dump($e->getLastException()); var_dump($e->getLastRequest()); }
返回结果
{
"RequestId": "43A29C77-405E-4DC0-BC55-EE694AD0****",
"Data": {
"Id": "docmind-20240712-b15f****"
}
}步骤二:调用文档解析(大模型版)状态查询服务QueryDocParserStatus接口
调用查询接口的入参ID就是前面异步任务提交接口返回的出参ID,查询结果有Status状态和NumberOfSuccessfulParsing已处理的模块数,Status状态有处理中、处理成功、处理失败三种情况。
请求参数
|
名称 |
类型 |
必填 |
描述 |
示例值 |
|
Id |
string |
是 |
需要查询的业务订单号,订单号从提交接口的返回结果中获取。 |
docmind-20220712-b15f**** |
返回参数
|
名称 |
类型 |
描述 |
示例值 |
|
RequestId |
string |
请求唯一ID。 |
43A29C77-405E-4CC0-BC55-EE694AD0**** |
|
Data |
string |
返回数据。 |
- |
|
Status |
string |
任务处理完成的状态。Success表示处理成功,Fail表示处理失败。 |
success |
|
NumberOfSuccessfulParsing |
integer |
已处理的模块数。 |
166 |
|
Tokens |
long |
英文单词数,或中文字数。 |
4429 |
|
ParagraphCount |
integer |
段落数量。 |
91 |
|
TableCount |
integer |
表格数量。当上传的文档中存在表格时,该参数会返回对应表格数量,否则不返回该参数。 |
2 |
|
ImageCount |
integer |
图片数量。当上传的文档中存在图片时,该参数会返回对应图片数量,否则不返回该参数。 |
0 |
|
PageCountEstimate |
integer |
当前处理的页码(页码从0开始)。 |
3 |
|
Processing |
float |
文件处理进度百分比 |
100.0 |
|
OutputFormatResult |
array |
获取指定格式的返回结果,仅当设置OutputFormat参数后生效。查看outputFormatResult属性详情 |
|
|
Code |
string |
状态码。 |
200 |
|
Message |
string |
详细信息。 |
Message |
订单状态Status类型:
-
Init:订单处于待处理队列中。
-
Processing: 正在解析处理。
-
success:文件处理成功,此时NumberOfSuccessfulParsing将不再变化。
-
Fail:文件处理失败。
使用示例
以Java SDK为例,调用文档解析接口的结果查询类API示例代码如下:调用接口,通过传入ID参数查询流水号。
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;
public static void main(String[] args) throws Exception {
submit();
}
public static void submit() throws Exception {
// 使用默认凭证初始化Credentials Client。
com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();
Config config = new Config()
// 通过credentials获取配置中的AccessKey ID
.setAccessKeyId(credentialClient.getAccessKeyId())
// 通过credentials获取配置中的AccessKey Secret
.setAccessKeySecret(credentialClient.getAccessKeySecret());
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
Client client = new Client(config);
QueryDocParserStatusRequest resultRequest = new QueryDocParserStatusRequest();
resultRequest.id = "docmind-20220902-824b****";
QueryDocParserStatusResponse response = client.queryDocParserStatus(resultRequest);
System.out.println(com.alibaba.fastjson.JSON.toJSON(response.getBody()));
}const Client = require('@alicloud/docmind-api20220711');
const Credential = require('@alicloud/credentials');
const getResult = async () => {
// 使用默认凭证初始化Credentials Client
const cred = new Credential.default();
const client = new Client.default({
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
endpoint: 'docmind-api.cn-hangzhou.aliyuncs.com',
// 通过credentials获取配置中的AccessKey ID
accessKeyId: cred.credential.accessKeyId,
// 通过credentials获取配置中的AccessKey Secret
accessKeySecret: cred.credential.accessKeySecret,
type: 'access_key',
regionId: 'cn-hangzhou'
});
const resultRequest = new Client.QueryDocParserStatusRequest();
resultRequest.id = "docmind-20220902-824b****";
const response = await client.queryDocParserStatus(resultRequest);
return response.body;
}from typing import List
from alibabacloud_docmind_api20220711.client import Client as docmind_api20220711Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_docmind_api20220711 import models as docmind_api20220711_models
from alibabacloud_tea_util.client import Client as UtilClient
from alibabacloud_credentials.client import Client as CredClient
if __name__ == '__main__':
# 使用默认凭证初始化Credentials Client。
cred=CredClient()
config = open_api_models.Config(
# 通过credentials获取配置中的AccessKey ID
access_key_id=cred.get_credential().get_access_key_id(),
# 通过credentials获取配置中的AccessKey Secret
access_key_secret=cred.get_credential().get_access_key_secret()
)
# 访问的域名
config.endpoint = f'docmind-api.cn-hangzhou.aliyuncs.com'
client = docmind_api20220711Client(config)
request = docmind_api20220711_models.QueryDocParserStatusRequest(
# id : 任务提交接口返回的id
id='docmind-20220902-824b****'
)
try:
# 复制代码运行请自行打印 API 的返回值
response = client.query_doc_parser_status(request)
# API返回值格式层级为 body -> data -> 具体属性。可根据业务需要打印相应的结果。获取属性值均以小写开头
# 获取返回结果。建议先把response.body.data转成json,然后再从json里面取具体需要的值。
print(response.body)
except Exception as error:
# 如有需要,请打印 error
UtilClient.assert_as_string(error.message) import (
"fmt"
openClient "github.com/alibabacloud-go/darabonba-openapi/v2/client"
"github.com/alibabacloud-go/docmind-api-20220711/client"
"github.com/aliyun/credentials-go/credentials"
)
func submit(){
// 使用默认凭证初始化Credentials Client。
credential, err := credentials.NewCredential(nil)
// 通过credentials获取配置中的AccessKey ID
accessKeyId, err := credential.GetAccessKeyId()
// 通过credentials获取配置中的AccessKey Secret
accessKeySecret, err := credential.GetAccessKeySecret()
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
var endpoint string = "docmind-api.cn-hangzhou.aliyuncs.com"
config := openClient.Config{AccessKeyId: accessKeyId, AccessKeySecret: accessKeySecret, Endpoint: &endpoint}
// 初始化client
cli, err := client.NewClient(&config)
if err != nil {
panic(err)
}
id := "docmind-20220925-76b1****"
// 调用查询接口
request := client.QueryDocParserStatusRequest{Id: &id}
response, err := cli.QueryDocParserStatus(&request)
if err != nil {
panic(err)
}
// 打印查询结果
fmt.Println(response.Body.String())
}using Newtonsoft.Json;
using System;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
using Tea;
using Tea.Utils;
public static void GetResult()
{
// 使用默认凭证初始化Credentials Client。
var akCredential = new Aliyun.Credentials.Client(null);
AlibabaCloud.OpenApiClient.Models.Config config = new AlibabaCloud.OpenApiClient.Models.Config
{
// 通过credentials获取配置中的AccessKey Secret
AccessKeyId = akCredential.GetAccessKeyId(),
// 通过credentials获取配置中的AccessKey Secret
AccessKeySecret = akCredential.GetAccessKeySecret(),
};
// 访问的域名
config.Endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
AlibabaCloud.SDK.Docmind_api20220711.Client client = new AlibabaCloud.SDK.Docmind_api20220711.Client(config);
AlibabaCloud.SDK.Docmind_api20220711.Models.QueryDocParserStatusRequest request = new AlibabaCloud.SDK.Docmind_api20220711.Models.QueryDocParserStatusRequest
{
Id = "docmind-20240902-824b****"
};
AlibabaCloud.TeaUtil.Models.RuntimeOptions runtime = new AlibabaCloud.TeaUtil.Models.RuntimeOptions();
try
{
// 复制代码运行请自行打印 API 的返回值
client.QueryDocParserStatus(request);
}
catch (TeaException error)
{
// 如有需要,请打印 error
AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message);
}
catch (Exception _error)
{
TeaException error = new TeaException(new Dictionary<string, object>
{
{ "message", _error.Message }
});
// 如有需要,请打印 error
AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message);
}
}use AlibabaCloud\SDK\Docmindapi\V20220711\Docmindapi;
use AlibabaCloud\SDK\Docmindapi\V20220711\Models\GetDocStructureResultRequest;
use Darabonba\OpenApi\Models\Config;
use AlibabaCloud\Tea\Utils\Utils\RuntimeOptions;
use AlibabaCloud\Tea\Exception\TeaUnableRetryError;
use AlibabaCloud\Credentials\Credential;
// 使用默认凭证初始化Credentials Client。
$bearerToken = new Credential();
$config = new Config();
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
$config->endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
// 通过credentials获取配置中的AccessKey ID
$config->accessKeyId = $bearerToken->getCredential()->getAccessKeyId();
// 通过credentials获取配置中的AccessKey Secret
$config->accessKeySecret = $bearerToken->getCredential()->getAccessKeySecret();
$config->type = "access_key";
$config->regionId = "cn-hangzhou";
$client = new Docmindapi($config);
$request = new QueryDocParserStatusRequest();
$request->id = "docmind-20220902-824b****";
$runtime = new RuntimeOptions();
$runtime->maxIdleConns = 3;
$runtime->connectTimeout = 10000;
$runtime->readTimeout = 10000;
try {
$response = $client->queryDocParserStatus($request, $runtime);
var_dump($response->toMap());
} catch (TeaUnableRetryError $e) {
var_dump($e->getMessage());
var_dump($e->getErrorInfo());
var_dump($e->getLastException());
var_dump($e->getLastRequest());
}返回示例:
{
"RequestId": "43A29C77-405E-4DC0-BC55-EE694AD0****",
"Data": {
"Status": "success",
"NumberOfSuccessfulParsing": 93,
"ImageCount": 0,
"PageCountEstimate": 8,
"ParagraphCount": 91,
"TableCount": 2,
"Tokens": 4429
}
}处理失败的返回示例:
{
"code": "FileUrlLegal",
"message": "File url is not legal.",
"requestId": "E26AC4F5-F633-5468-8F6F-708D2B3FXXXX"
}步骤三:调用文档解析(大模型版)结果获取服务GetDocParserResult接口
请求参数
|
名称 |
类型 |
必填 |
描述 |
示例值 |
|
Id |
string |
是 |
需要查询的业务订单号,订单号从提交接口的返回结果中获取。 |
docmind-20220712-b15f**** |
|
LayoutStepSize |
integer |
是 |
|
100 |
|
LayoutNum |
integer |
是 |
|
0 |
|
ExcludeFields |
List<String> |
否 |
去除结果中不需要返回的属性(目前仅支持一级属性的过滤,可去除属性请参考文件格式处理成功的返回结果中的 layout下的一级信息)。 |
"text","firstLinesChars" |
-
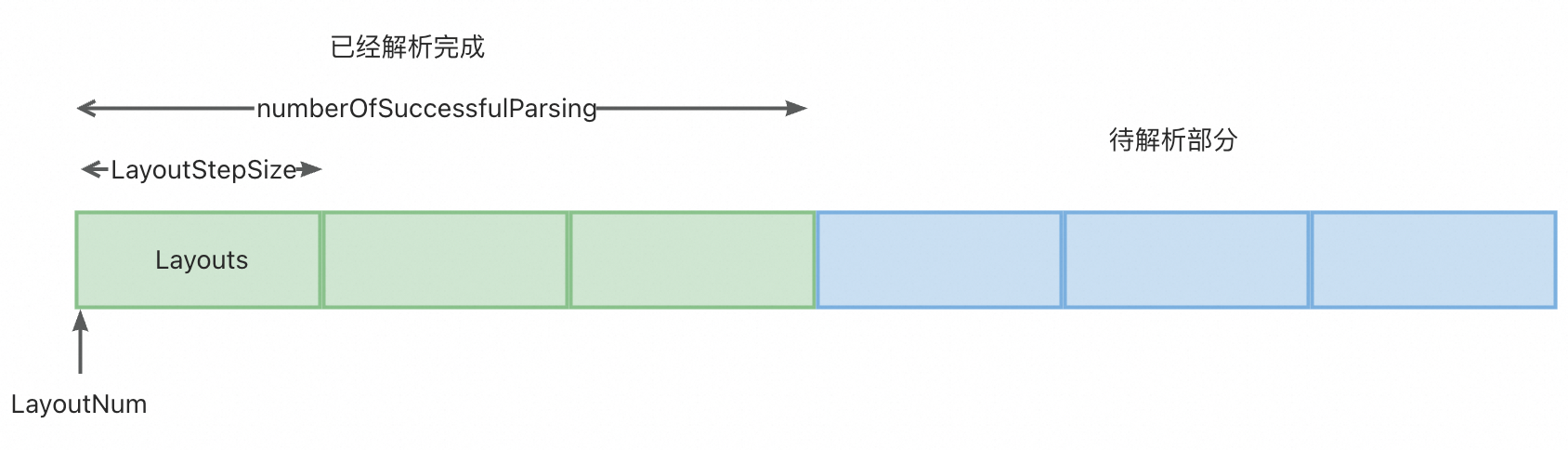
使用GetDocParserResult接口,意味着需要进行多次结果的查询(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),同时能在长文档解析时,能提前获取已解析完内容。
-
LayoutStepSize过长会出现报错,可以适当调小
GetDocParserResult接口中,可通过LayoutNum标记值和LayoutStepSize步长,获取layouts,即当文档处理中时,即可获得已经解析完成的内容;
返回参数
|
名称 |
类型 |
描述 |
示例值 |
|
RequestId |
string |
请求唯一ID。 |
43A29C77-405E-4CC0-BC55-EE694AD0**** |
|
Data |
string |
返回数据,文档解析(大模型版)的解析结果。 |
- |
|
Code |
string |
状态码。 |
200 |
|
Message |
string |
详细信息。 |
Message |
使用示例
以Java SDK为例,调用文档解析接口的结果查询类API示例代码如下。
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;
public static void main(String[] args) throws Exception {
submit();
}
public static void submit() throws Exception {
// 使用默认凭证初始化Credentials Client。
com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();
Config config = new Config()
// 通过credentials获取配置中的AccessKey ID
.setAccessKeyId(credentialClient.getAccessKeyId())
// 通过credentials获取配置中的AccessKey Secret
.setAccessKeySecret(credentialClient.getAccessKeySecret());
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
Client client = new Client(config);
GetDocParserResultRequest resultRequest = new GetDocParserResultRequest();
// 业务订单号,异步提交服务SubmitDocParserJob接口返回的id
resultRequest.id = "docmind-20220902-824b****";
/**
* 使用GetDocParserResult接口,意味着需要进行多次结果的查询
*(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),
* 同时能在长文档解析时,能提前获取已解析完内容。
*/
// LayoutStepSize:期望查询的Layout的Size大小(步长值)。最小值:1;最大值:3000
resultRequest.layoutStepSize = 10;
// LayoutNum:查询起始块位置。最小值:0
resultRequest.layoutNum = 0;
GetDocParserResultResponse response = client.getDocParserResult(resultRequest);
System.out.println(com.alibaba.fastjson.JSON.toJSON(response.getBody()));
}const Client = require('@alicloud/docmind-api20220711');
const Credential = require('@alicloud/credentials');
const getResult = async () => {
// 使用默认凭证初始化Credentials Client
const cred = new Credential.default();
const client = new Client.default({
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
endpoint: 'docmind-api.cn-hangzhou.aliyuncs.com',
// 通过credentials获取配置中的AccessKey ID
accessKeyId: cred.credential.accessKeyId,
// 通过credentials获取配置中的AccessKey Secret
accessKeySecret: cred.credential.accessKeySecret,
type: 'access_key',
regionId: 'cn-hangzhou'
});
const resultRequest = new Client.GetDocParserResultRequest();
resultRequest.id = "docmind-20220902-824b****";
/**
* 使用GetDocParserResult接口,意味着需要进行多次结果的查询
*(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),
* 同时能在长文档解析时,能提前获取已解析完内容。
*/
// LayoutStepSize:期望查询的Layout的Size大小(步长值)。最小值:1;最大值:3000
resultRequest.layoutStepSize = 10;
// LayoutNum:查询起始块位置。最小值:0
resultRequest.layoutNum = 0;
const response = await client.getDocParserResult(resultRequest);
return response.body;
}from typing import List
from alibabacloud_docmind_api20220711.client import Client as docmind_api20220711Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_docmind_api20220711 import models as docmind_api20220711_models
from alibabacloud_tea_util.client import Client as UtilClient
from alibabacloud_credentials.client import Client as CredClient
if __name__ == '__main__':
# 使用默认凭证初始化Credentials Client。
cred = CredClient()
config = open_api_models.Config(
# 通过credentials获取配置中的AccessKey ID
access_key_id=cred.get_credential().get_access_key_id(),
# 通过credentials获取配置中的AccessKey Secret
access_key_secret=cred.get_credential().get_access_key_secret()
)
# 访问的域名
config.endpoint = f'docmind-api.cn-hangzhou.aliyuncs.com'
client = docmind_api20220711Client(config)
request = docmind_api20220711_models.GetDocParserResultRequest(
# id : 任务提交接口返回的id
id='docmind-20220902-824b****',
'''
使用GetDocParserResult接口,意味着需要进行多次结果的查询
(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0-100,100-200块内容),
同时能在长文档解析时,能提前获取已解析完内容.
'''
# LayoutStepSize: 期望查询的Layout的Size大小(步长值).最小值:1;最大值:3000
layout_step_size=10,
# LayoutNum:查询起始块位置。最小值:0
layout_num=0
)
try:
# 复制代码运行请自行打印 API 的返回值
response = client.get_doc_parser_result(request)
# API返回值格式层级为 body -> data -> 具体属性。可根据业务需要打印相应的结果。获取属性值均以小写开头
# 获取返回结果。建议先把response.body.data转成json,然后再从json里面取具体需要的值。
print(response.body)
except Exception as error:
# 如有需要,请打印 error
UtilClient.assert_as_string(error.message)
import (
"fmt"
openClient "github.com/alibabacloud-go/darabonba-openapi/v2/client"
"github.com/alibabacloud-go/docmind-api-20220711/client"
"github.com/aliyun/credentials-go/credentials"
)
func submit(){
// 使用默认凭证初始化Credentials Client。
credential, err := credentials.NewCredential(nil)
// 通过credentials获取配置中的AccessKey ID
accessKeyId, err := credential.GetAccessKeyId()
// 通过credentials获取配置中的AccessKey Secret
accessKeySecret, err := credential.GetAccessKeySecret()
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
var endpoint string = "docmind-api.cn-hangzhou.aliyuncs.com"
config := openClient.Config{AccessKeyId: accessKeyId, AccessKeySecret: accessKeySecret, Endpoint: &endpoint}
// 初始化client
cli, err := client.NewClient(&config)
if err != nil {
panic(err)
}
id := "docmind-20220925-76b1****"
/**
* 使用GetDocParserResult接口,意味着需要进行多次结果的查询
*(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),
* 同时能在长文档解析时,能提前获取已解析完内容。
*/
// LayoutStepSize:期望查询的Layout的Size大小(步长值)。最小值:1;最大值:3000
layoutStepSize := 10
// LayoutNum:查询起始块位置。最小值:0
layoutNum := 0
// 调用查询接口
request := client.GetDocParserResultRequest{Id: &id}
response, err := cli.GetDocParserResult(&request)
if err != nil {
panic(err)
}
// 打印查询结果
fmt.Println(response.Body.String())
}using Newtonsoft.Json;
using System;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using System.Threading.Tasks;
using Tea;
using Tea.Utils;
public static void GetResult()
{
// 使用默认凭证初始化Credentials Client。
var akCredential = new Aliyun.Credentials.Client(null);
AlibabaCloud.OpenApiClient.Models.Config config = new AlibabaCloud.OpenApiClient.Models.Config
{
// 通过credentials获取配置中的AccessKey Secret
AccessKeyId = akCredential.GetAccessKeyId(),
// 通过credentials获取配置中的AccessKey Secret
AccessKeySecret = akCredential.GetAccessKeySecret(),
};
// 访问的域名
config.Endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
AlibabaCloud.SDK.Docmind_api20220711.Client client = new AlibabaCloud.SDK.Docmind_api20220711.Client(config);
AlibabaCloud.SDK.Docmind_api20220711.Models.GetDocParserResultRequest request = new AlibabaCloud.SDK.Docmind_api20220711.Models.GetDocParserResultRequest
{
/**
* 使用GetDocParserResult接口,意味着需要进行多次结果的查询
*(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),
* 同时能在长文档解析时,能提前获取已解析完内容。
*/
// LayoutStepSize:期望查询的Layout的Size大小(步长值)。最小值:1;最大值:3000
Id = "docmind-20240902-824b****",
LayoutStepSize = 10,
// LayoutNum:查询起始块位置。最小值:0
LayoutNum = 0
};
AlibabaCloud.TeaUtil.Models.RuntimeOptions runtime = new AlibabaCloud.TeaUtil.Models.RuntimeOptions();
try
{
// 复制代码运行请自行打印 API 的返回值
client.GetDocParserResult(request);
}
catch (TeaException error)
{
// 如有需要,请打印 error
AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message);
}
catch (Exception _error)
{
TeaException error = new TeaException(new Dictionary<string, object>
{
{ "message", _error.Message }
});
// 如有需要,请打印 error
AlibabaCloud.TeaUtil.Common.AssertAsString(error.Message);
}
}use AlibabaCloud\SDK\Docmindapi\V20220711\Docmindapi;
use AlibabaCloud\SDK\Docmindapi\V20220711\Models\GetDocStructureResultRequest;
use Darabonba\OpenApi\Models\Config;
use AlibabaCloud\Tea\Utils\Utils\RuntimeOptions;
use AlibabaCloud\Tea\Exception\TeaUnableRetryError;
use AlibabaCloud\Credentials\Credential;
// 使用默认凭证初始化Credentials Client。
$bearerToken = new Credential();
$config = new Config();
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
$config->endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
// 通过credentials获取配置中的AccessKey ID
$config->accessKeyId = $bearerToken->getCredential()->getAccessKeyId();
// 通过credentials获取配置中的AccessKey Secret
$config->accessKeySecret = $bearerToken->getCredential()->getAccessKeySecret();
$config->type = "access_key";
$config->regionId = "cn-hangzhou";
$client = new Docmindapi($config);
$request = new GetDocParserResultRequest();
$request->id = "docmind-20220902-824b****";
/**
* 使用GetDocParserResult接口,意味着需要进行多次结果的查询
*(例如 [LayoutNum,LayoutNum+LayoutStepSize] 获取 0~100,100~200块内容),
* 同时能在长文档解析时,能提前获取已解析完内容。
*/
// LayoutStepSize:期望查询的Layout的Size大小(步长值)。最小值:1;最大值:3000
$request->layoutStepSize = 10;
// LayoutNum:查询起始块位置。最小值:0
$request->layoutNum = 0;
$runtime = new RuntimeOptions();
$runtime->maxIdleConns = 3;
$runtime->connectTimeout = 10000;
$runtime->readTimeout = 10000;
try {
$response = $client->getDocParserResult($request, $runtime);
var_dump($response->toMap());
} catch (TeaUnableRetryError $e) {
var_dump($e->getMessage());
var_dump($e->getErrorInfo());
var_dump($e->getLastException());
var_dump($e->getLastRequest());
}返回示例:
处理失败的返回结果
{
"RequestId": "A8EF3A36-1380-1116-A39E-B377BE27****",
"Code": "UrlNotLegal",
"Message": "Failed to process the document. The document url you provided is not legal.",
"HostId": "docmind-api.cn-hangzhou.aliyuncs.com",
"Recommend": "https://next.api.aliyun.com/troubleshoot?q=IDP.UrlNotLegal&product=docmind-api"
}如果请求处理失败,会返回失败Code和详细原因Message。详细介绍,请参见错误码。
文件格式处理成功的返回结果
{
"Data": {
"layouts": [
{
"firstLinesChars": 0,
"level": 0,
"blocks": [
{
"text": "PRACTITIONERS’ SECTION"
}
],
"markdownContent": "# PRACTITIONERS’ SECTION \n\n",
"index": 2,
"subType": "doc_title",
"lineHeight": 0,
"text": "PRACTITIONERS’ SECTION",
"alignment": "center",
"type": "title",
"pageNum": 0,
"uniqueId": "3d8ded229371f879eac478dee2574a82"
},
{
"firstLinesChars": 0,
"level": 0,
"blocks": [
{
"text": "RAGGING: A PUBLIC HEALTH PROBLEM IN INDIA"
}
],
"markdownContent": "# RAGGING: A PUBLIC HEALTH PROBLEM IN INDIA \n\n",
"index": 3,
"subType": "doc_subtitle",
"lineHeight": 0,
"text": "RAGGING: A PUBLIC HEALTH PROBLEM IN INDIA",
"alignment": "center",
"type": "title",
"pageNum": 0,
"uniqueId": "44256f2d41419956ff30c6590683217b"
},
{
"firstLinesChars": 0,
"level": 1,
"blocks": [
{
"text": "RAJESH GARG"
}
],
"markdownContent": "RAJESH GARG \n\n",
"index": 4,
"subType": "para",
"lineHeight": 0,
"text": "RAJESH GARG",
"alignment": "center",
"type": "text",
"pageNum": 0,
"uniqueId": "d0d64505df8cb4d73f80e0f63007bf60"
}
]
},
"RequestId": "7B8CC68D-D498-5EDA-8352-FAF41591D97A"
}参数说明:
|
Data |
object |
解析结果 |
|
layouts |
array |
版面信息列表。 |
|
text |
string |
文本内容。 |
|
markdownContent |
string |
Markdown文本内容。 |
|
index |
int |
版面阅读顺序。 |
|
uniqueId |
string |
版面信息唯一Id。 |
|
alignment |
string |
间距枚举。 |
|
pageNum |
int |
版面所在页。 |
|
level |
int |
版面层级(最小层级为0,表示根节点)。 |
|
type |
string |
版面类型(详见备注版面类型)。 |
|
subType |
string |
版面子类型(详见备注版面类型)。 |
|
llmResult |
string |
大模型返回的结果(详见llmResult结果示例)。
|
|
layoutConf |
float |
解析的置信度。取值范围:[0, 1]。 |
|
pos |
array |
坐标。 |
|
x |
int |
顶点横坐标。 |
|
y |
int |
顶点纵坐标。 |
音视频格式处理成功的返回结果
{
"Data": {
"segments": [
{
"audio_frames": [
{
"ASR_info": "哪咤就是中国网民的自嗨,只有中国有票房,其他地方根本没人看的。",
"end_time": 5019.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/audio/request_1111_1.mp3?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645100&Signature=ioyj0ogA2pXSod1gPlM4KMCXLr4%3D",
"start_time": 0.0
}
],
"end_time": 5019.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/video/request_1111_0.mp4?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645176&Signature=RoMsrYsA%2B4jkuJTQA6Pjpv2knBY%3D",
"index": 0,
"start_time": 0.0,
"video_frames": [
{
"end_time": 4960.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/frame/request_1111-Scene-001-01.jpg?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645151&Signature=E8IsZesWrW%2B3i8VLs7ZXLqMFZYg%3D",
"start_time": 0.0,
"text_info": "一个戴眼镜的男子在圆形画面中手持手机,背景是书架,右侧显示一条评论:“哪吒就是中国网民的自嗨,只有中国有票房,其他地方根本没人看的”,下方有点赞、点踩、分享和评论图标,底部字幕为“只有中国有票房”"
},
{
"end_time": 10600.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/frame/request_1111-Scene-002-01.jpg?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645151&Signature=ZDOgHjs0iKmYCPcmsxTPk6fhg64%3D",
"start_time": 4960.0,
"text_info": "一个戴眼镜的男子站在书架前,书架上摆放着书籍和两个小黄人玩偶,他穿着棕色衬衫,正在说话,底部字幕为“反而为什么会有人这么说”"
}
]
},
{
"audio_frames": [
{
"ASR_info": "因为这个说法背后隐藏着非常深的歧视链条,我们来思考几个问题,第一,哪咤外国票房少是因为外国观众不喜欢还是看不到?",
"end_time": 19900.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/audio/request_1111_3.mp3?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645101&Signature=7QwfDASrWywOA%2FmlZ64r%2FMcu0b4%3D",
"start_time": 10577.0
}
],
"end_time": 19900.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/video/request_1111_2.mp4?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645181&Signature=m03c5oHyqY88mmtPLdSgMpi8Ul4%3D",
"index": 2,
"start_time": 10577.0,
"video_frames": [
{
"end_time": 14080.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/frame/request_1111-Scene-003-01.jpg?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645151&Signature=NCAM%2Bt1KLTNDt4jIFXOH%2B0m13Vs%3D",
"start_time": 10600.0,
"text_info": "一个戴眼镜的男子站在书架前,书架上摆放着书籍和两个小黄人玩偶,他穿着棕色衬衫,表情认真,底部字幕为“隐藏着非常深的歧视链条”"
},
{
"end_time": 15600.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/frame/request_1111-Scene-004-01.jpg?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645151&Signature=%2FhmtuSNvtjwHI2Ho88tIv9keM3k%3D",
"start_time": 14080.0,
"text_info": "一个戴眼镜的男子站在书架前,书架上摆放着书籍和两个小黄人玩偶,他穿着深色衬衫,正在说话,屏幕下方显示文字“我们来思考几个问题”"
},
{
"end_time": 52920.0,
"file_url": "http://doc-mind-video.oss-cn-hangzhou.aliyuncs.com/multimodal_data/20251125/frame/request_1111-Scene-005-01.jpg?OSSAccessKeyId=LTAI5tPtEwpyT4JR9XXXXX&Expires=1764645151&Signature=vfYhFendANuuzihVIlQAmq0YAuQ%3D",
"start_time": 15600.0,
"text_info": "一个黑色背景的画面,中央有一个白色方框,里面写着数字“3”,下方是白色文字“《美国队长4》算不算‘自嗨’?”,底部有字幕“但是在美国排片如此之高”"
}
]
}
],
"synopsis_result": "### 0秒 - 5秒\n**帧解析结果**:一个戴眼镜的男子站在书架前,书架上摆放着书籍和两个小黄人玩偶,他穿着棕色衬衫,正在说话,底部字幕为“反而为什么会有人这么说”
},
"RequestId": "7B8CC68D-D498-5EDA-8352-FAF41591D97A"
}参数说明:
|
Data |
object |
解析结果 |
|
segments |
array |
分段解析结果数组。 |
|
start_time |
float |
segment 开始时间(单位:ms)。 |
|
end_time |
float |
segment 结束时间(单位:ms)。 |
|
index |
int |
segment 序号,0~(n-1)。 |
|
file_url |
string |
segment 文件。 |
|
audio_frames |
array |
segment 音频解析信息。 |
|
video_frames |
array |
segment 视频帧解析信息。 |
|
synopsis_result |
string |
剧情解析内容(option=advance时返回该字段)。 |
文档解析(大模型版)返回结果中,段落音频(audio_frames)信息如下:
|
filed(字段名) |
类型描述 |
字段类型 |
|
start_time |
音频开始时间(单位:ms) |
float |
|
end_time |
音频结束时间(单位:ms) |
float |
|
file_url |
音频文件url |
string |
|
ASR_info |
音频 asr 结果 |
string |
文档解析(大模型版)返回结果中,段落视频帧(video_frames)信息如下:
|
filed(字段名) |
类型描述 |
字段类型 |
|
start_time |
视频开始时间(单位:ms) |
float |
|
end_time |
视频结束时间(单位:ms) |
float |
|
file_url |
视频文件url |
string |
|
text_info |
视频帧大模型解析结果 |
string |
文档解析(大模型版)返回结果中,llmResult结果示例如下:
-
对于PPT类型文档。
{
"llmResult": "```markdown\n# Welcome to Capital Markets Day London 2015\n\n## HEXAGON\n### Shaping Smart Change\n```",
"layoutConf": 0.6
}-
对于文件中的图表。
{
"llmResult": "<|类别|>\n估值图\n<|数值|>\n| Protocol Followed | Time Required (Minutes) |\n|-------------------|-------------------------|\n| Standard | 80 |\n| Halifax | 80 |\n| Halifaster | 40 |",
"layoutConf": 0.4
}版面类型
文档解析大模型版返回结果中,版面的类型type及子类型subType列表如下:
|
type(类型) |
类型描述 |
subType(子类型) |
子类型描述 |
|
title |
标题 |
doc_name |
文档名称 |
|
doc_title |
文档标题 |
||
|
doc_subtitle |
文档副标题 |
||
|
para_title |
段落标题 |
||
|
contents_title |
目录标题 |
cate_title |
目录标题 |
|
contents |
目录主体 |
cate |
目录主体 |
|
text |
普通文字 |
para |
段落 |
|
figure |
图表 |
picture |
图片 |
|
logo |
logo |
||
|
figure_name |
图名 |
pic_title |
图片标题 |
|
figure_note |
图注 |
pic_caption |
图注 |
|
foot |
页脚 |
page_footer |
页脚 |
|
head |
页眉 |
page_header |
页眉 |
|
head_pagenum |
页眉页码 |
page |
页码 |
|
foot_pagenum |
页脚页码 |
page |
页码 |
|
corner_note |
脚注 |
footer_note |
脚注 |
|
end_note |
尾注 |
endnode |
尾注 |
|
side |
侧栏 |
sidebar |
侧栏 |
相同子类型的 type 如下
|
type(类型) |
类型描述 |
|
table_name |
表格名称 |
|
table_note |
表注 |
|
formula |
公式 |
无子类型的 type
|
type(类型) |
类型描述 |
|
multicolumn |
多栏文字 |
|
table |
表格 |
|
foot_image |
页脚图片 |
|
head_image |
页眉图片 |
outputFormatResult的属性
|
type(类型) |
类型描述 |
|
outputType |
返回结果格式输出类型 |
|
outputFileUrl |
返回结果格式的文件地址 |
|
pages |
返回页内图片信息 |
outputType的属性
|
type(类型) |
类型描述 |
|
markdown |
markdown类型格式 |
|
pageImage |
页内图片类型格式 |
pages的属性
|
type(类型) |
类型描述 |
|
imageUrl |
图片链接 |
|
imageWidth |
图片长度 |
|
imageHeight |
图片高度 |
|
pageIdCurDoc |
文档当前页码 |
参考示例(Python)
解析输出markdown参考(本地文件上传示例)
是否启用VLM增强,enhancement=False 关闭
使用方法:
python3 docmind_example_parser.py input_file output_file.md
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import time
import json
from alibabacloud_docmind_api20220711.client import Client as docmind_api20220711Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_docmind_api20220711 import models as docmind_api20220711_models
from alibabacloud_tea_util.client import Client as UtilClient
from alibabacloud_tea_util import models as util_models
from alibabacloud_credentials.client import Client as CredClient
class DocParser:
def __init__(self, endpoint="docmind-api.cn-hangzhou.aliyuncs.com"):
"""
初始化文档解析器
Args:
endpoint (str): API端点地址
"""
self.endpoint = endpoint
self.client = self._init_client()
def _init_client(self):
"""
初始化API客户端
Returns:
docmind_api20220711Client: API客户端实例
"""
# 使用默认凭证初始化Credentials Client
cred = CredClient()
config = open_api_models.Config(
# 通过credentials获取配置中的AccessKey ID
access_key_id=cred.get_credential().get_access_key_id(),
# 通过credentials获取配置中的AccessKey Secret
access_key_secret=cred.get_credential().get_access_key_secret()
)
# 设置访问的域名
config.endpoint = self.endpoint
return docmind_api20220711Client(config)
def submit_job(self, file_path, file_name=None):
"""
提交文档解析任务
Args:
file_path (str): 本地文件路径
file_name (str, optional): 文件名
Returns:
str: 任务ID,如果失败则返回None
"""
try:
# 如果未指定文件名,则从文件路径中提取
if not file_name:
file_name = file_path.split('/')[-1]
# 构造请求对象
# 是否启用VLM增强,enhancement=False 关闭
request = docmind_api20220711_models.SubmitDocParserJobAdvanceRequest(
file_url_object=open(file_path, "rb"),
file_name=file_name,
file_name_extension=file_name.split('.')[-1] if '.' in file_name else None,
llm_enhancement=True,
enhancement_mode="VLM",
)
runtime = util_models.RuntimeOptions()
# 提交任务
response = self.client.submit_doc_parser_job_advance(request, runtime)
task_id = response.body.data.id
print(f"任务已提交,任务ID: {task_id}")
return task_id
except Exception as error:
print(f"提交任务时出错: {error}")
return None
def query_status(self, task_id):
"""
查询任务状态
Args:
task_id (str): 任务ID
Returns:
dict: 任务状态信息,如果失败则返回None
"""
try:
request = docmind_api20220711_models.QueryDocParserStatusRequest(id=task_id)
response = self.client.query_doc_parser_status(request)
return response.body.data.to_map() if response.body.data else None
except Exception as error:
print(f"查询任务状态时出错: {error}")
return None
def get_result(self, task_id, layout_num=0, layout_step_size=10):
"""
获取文档解析结果(支持增量获取)
Args:
task_id (str): 任务ID
layout_num (int): 起始布局编号
layout_step_size (int): 步长
Returns:
dict: 解析结果,如果失败则返回None
"""
try:
request = docmind_api20220711_models.GetDocParserResultRequest(
id=task_id,
layout_step_size=layout_step_size,
layout_num=layout_num
)
response = self.client.get_doc_parser_result(request)
return response.body.data if response.body.data else None
except Exception as error:
print(f"获取解析结果时出错: {error}")
return None
def wait_for_completion(self, task_id, poll_interval=5):
"""
等待任务完成
Args:
task_id (str): 任务ID
poll_interval (int): 轮询间隔(秒)
Returns:
bool: 任务是否成功完成
"""
print("开始轮询任务状态...")
while True:
status_data = self.query_status(task_id)
if not status_data:
return False
print(status_data)
status = status_data.get('Status', '').lower()
# 检查任务是否完成
if status == 'success':
print("任务已成功完成")
return True
elif status == 'failed':
print("任务执行失败")
return False
else:
# 任务仍在处理中
print(".")
time.sleep(poll_interval)
def collect_results_incrementally(self, task_id, layout_step_size=10):
"""
增量收集解析结果
Args:
task_id (str): 任务ID
layout_step_size (int): 步长
Yields:
list: 每次获取到的布局块列表
"""
layout_num = 0
while True:
result_data = self.get_result(task_id, layout_num, layout_step_size)
if not result_data:
break
layouts = result_data.get('layouts', [])
if not layouts:
break
yield layouts
# 更新下次获取的起始位置
layout_num += len(layouts)
# 如果获取到的数量小于步长,说明已经获取完所有内容
if len(layouts) < layout_step_size:
break
def table_to_html(self, table_layout):
"""
将表格布局转换为HTML格式
Args:
table_layout (dict): 表格布局数据
Returns:
str: HTML格式的表格
"""
cells = table_layout.get('cells', [])
if not cells:
return ""
# 创建HTML表格
html_parts = ['<table border="1" cellspacing="0" cellpadding="2">']
# 用于跟踪哪些单元格已被处理(处理跨行跨列的情况)
processed_cells = set()
# 按行分组单元格
rows = {}
for cell in cells:
row_start = cell.get('ysc', 0)
if row_start not in rows:
rows[row_start] = []
rows[row_start].append(cell)
# 按行顺序处理
for row_idx in sorted(rows.keys()):
html_parts.append('<tr>')
# 按列顺序排序
row_cells = sorted(rows[row_idx], key=lambda x: x.get('xsc', 0))
for cell in row_cells:
cell_key = (cell.get('ysc', 0), cell.get('xsc', 0))
if cell_key in processed_cells:
continue
# 计算跨行跨列
rowspan = cell.get('yec', 0) - cell.get('ysc', 0) + 1
colspan = cell.get('xec', 0) - cell.get('xsc', 0) + 1
# 标记已处理的单元格
for i in range(rowspan):
for j in range(colspan):
processed_cells.add((cell.get('ysc', 0) + i, cell.get('xsc', 0) + j))
# 获取单元格文本内容
cell_text = ""
cell_layouts = cell.get('layouts', [])
for layout in cell_layouts:
if 'text' in layout:
cell_text += layout['text']
# 清理文本内容
cell_text = cell_text.strip().replace('\n', '<br>')
# 添加单元格HTML
cell_attrs = []
if rowspan > 1:
cell_attrs.append(f'rowspan="{rowspan}"')
if colspan > 1:
cell_attrs.append(f'colspan="{colspan}"')
html_parts.append(f'<td {" ".join(cell_attrs)}>{cell_text}</td>')
html_parts.append('</tr>')
html_parts.append('</table>')
return ''.join(html_parts)
def generate_markdown(self, layouts):
"""
将布局块转换为Markdown内容
Args:
layouts (list): 布局块列表
Returns:
str: Markdown内容
"""
markdown_content = ""
for layout in layouts:
# 直接使用返回的markdownContent字段
if layout.get('type')=="table":
# 对于表格类型,转换为HTML格式
table_html = self.table_to_html(layout)
markdown_content += table_html + "\n\n"
else:
markdown_content += layout.get('markdownContent', '') + "\n"
return markdown_content
def process_document(self, file_path, output_path, layout_step_size=10, poll_interval=5):
"""
处理整个文档:提交、轮询、增量获取结果并生成Markdown文件
Args:
file_path (str): 本地文件路径
output_path (str): 输出Markdown文件路径
layout_step_size (int): 增量获取步长
poll_interval (int): 轮询间隔(秒)
Returns:
bool: 是否成功处理
"""
# 1. 提交任务
print("正在提交文档解析任务...")
task_id = self.submit_job(file_path)
if not task_id:
print("提交任务失败")
return False
# 2. 等待任务完成
if not self.wait_for_completion(task_id, poll_interval):
print("任务未成功完成")
return False
# 3. 增量获取结果并写入文件
print("任务已完成,开始获取解析结果...")
with open(output_path, 'w', encoding='utf-8') as f:
# 增量获取并写入内容
for layouts in self.collect_results_incrementally(task_id, layout_step_size):
markdown_content = self.generate_markdown(layouts)
f.write(markdown_content)
f.flush() # 立即刷新到文件
print(f"文档解析完成,结果已保存至: {output_path}")
return True
def main():
import argparse
parser = argparse.ArgumentParser(description='文档解析工具')
parser.add_argument('input_file', help='输入的文档文件路径')
parser.add_argument('output_file', help='输出的Markdown文件路径')
parser.add_argument('--step-size', type=int, default=10, help='增量获取步长,默认为10')
parser.add_argument('--poll-interval', type=int, default=5, help='轮询间隔(秒),默认为5秒')
args = parser.parse_args()
# 创建文档解析器实例
parser = DocParser()
# 处理文档
success = parser.process_document(
args.input_file,
args.output_file,
layout_step_size=args.step_size,
poll_interval=args.poll_interval
)
if success:
print("文档处理成功完成!")
else:
print("文档处理失败!")
exit(1)
if __name__ == "__main__":
main()