
功能简介
长文档信息抽取是基于深度学习的信息抽取自学习模型任务,支持用户自定义抽取字段,通过平台可视化引导,完成数据标注和模型训练,实现对非结构化、多版式的文档的高精度抽取。
在图像质量较好情况下,通过100+训练样本标注,调优后模型识别准确率可超85%+。
功能优势
高精度,基于阿里云强大的预训练模型,经过调优训练的多版式模型识别准确率可达85%以上。
少样本,仅需标注少量数据即可完成模型优化迭代,且模型具有泛化性。
低门槛,无需代码开发,开箱即用,可自主配置规则,交互友好可控。
高效率,提供智能预标注能力,多人协同标注耗时短。
应用场景
高性能模型:适用于文档样式/格式较为简单的文档。例如仅包含标题、段落的文档;支持的文档格式包括PDF/图片。适用于证明、文书、文件、信件、公告等行业场景。
混合版面模型:适用于文档样式/格式较为丰富的文档。例如包括标题,段落,表格、表单等内容的文档;支持的文档格式包括PDF/图片。适用于合同、标书、保单、工程表单等行业场景。
模型有持续优化的需求,且有较多的数据样本(大于20条)可用于模型训练进行效果优化的长文档数据。
相关链接
OCR文档自学习:控制台入口
长文档信息抽取模型任务开发指南:在线调试,API 接口文档(异步调用API接口文档),SDK文档
操作指南
「长文档信息抽取接入视频」参考:
创建「长文档信息抽取」流程如下图,需要超过20张图片进行训练才可完成模型创建。
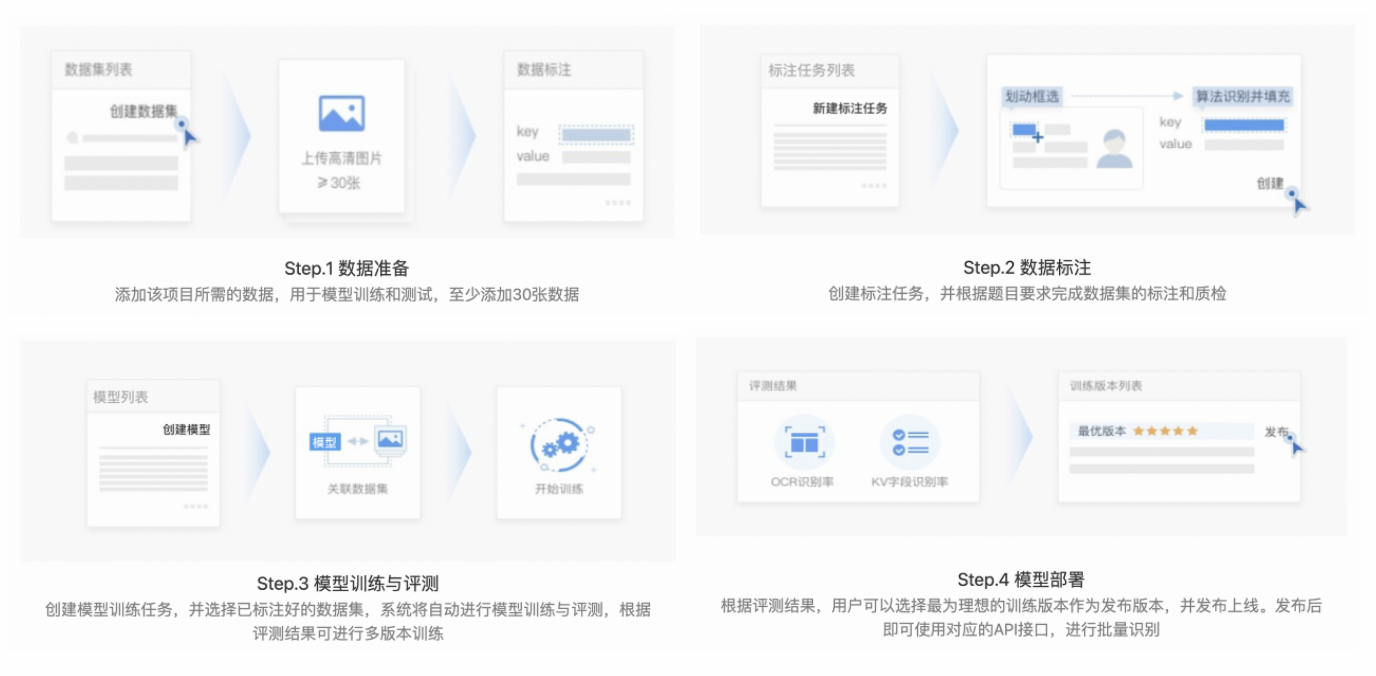
步骤一:数据准备
在「数据中心-数据集」中,用户可进行上传和管理模型任务所需数据。点击添加数据集进入上传界面,编辑数据集名称并上传相关业务数据。
长文档信息抽取自定义模型至少需要50张训练数据,才能获得相对较好的识别抽取效果。
步骤二: 数据标注
数据标注划分为标注创建环节、标注环节、质检环节三大步骤;
标注任务创建
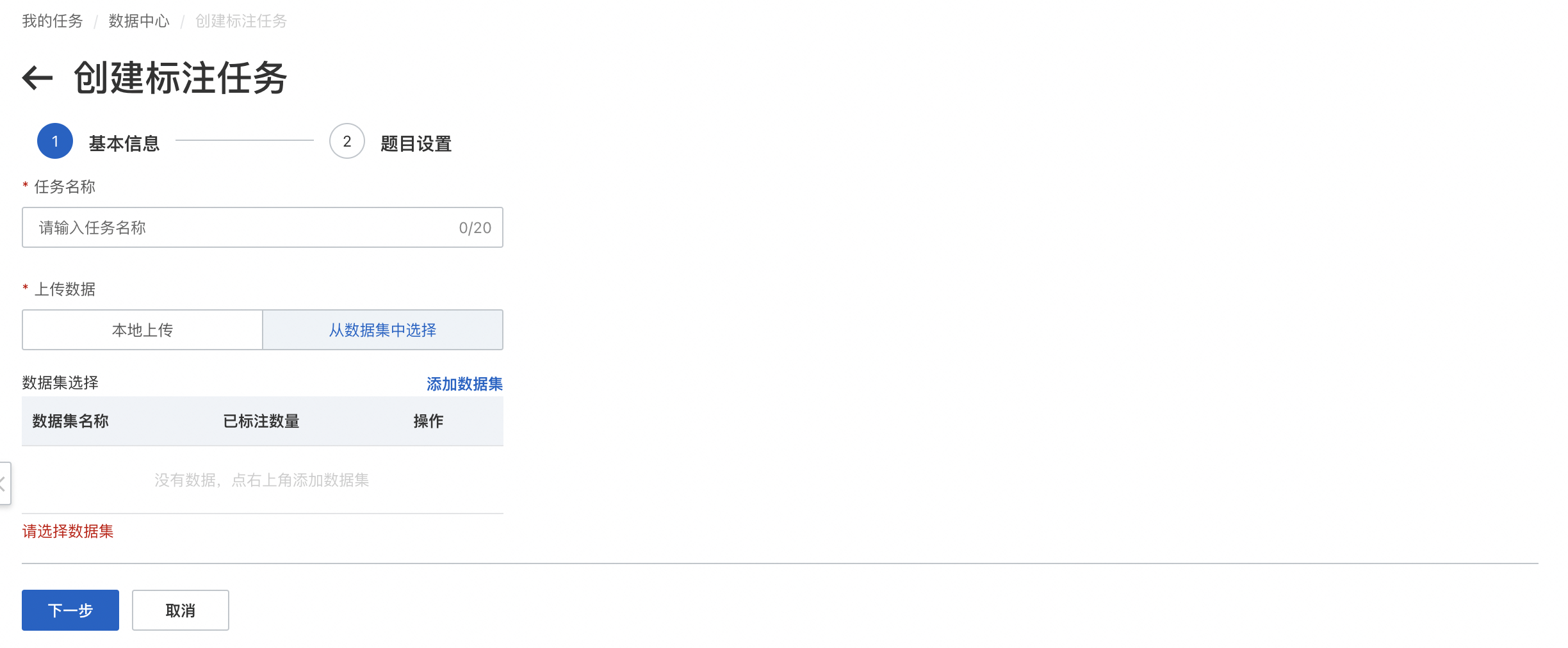
在「数据中心-标注任务」界面中,点击创建标注任务进入创建界面,编辑任务名称以及在上传数据中选择需要标注的数据集或直接本地上传,完成后进入题目设置。
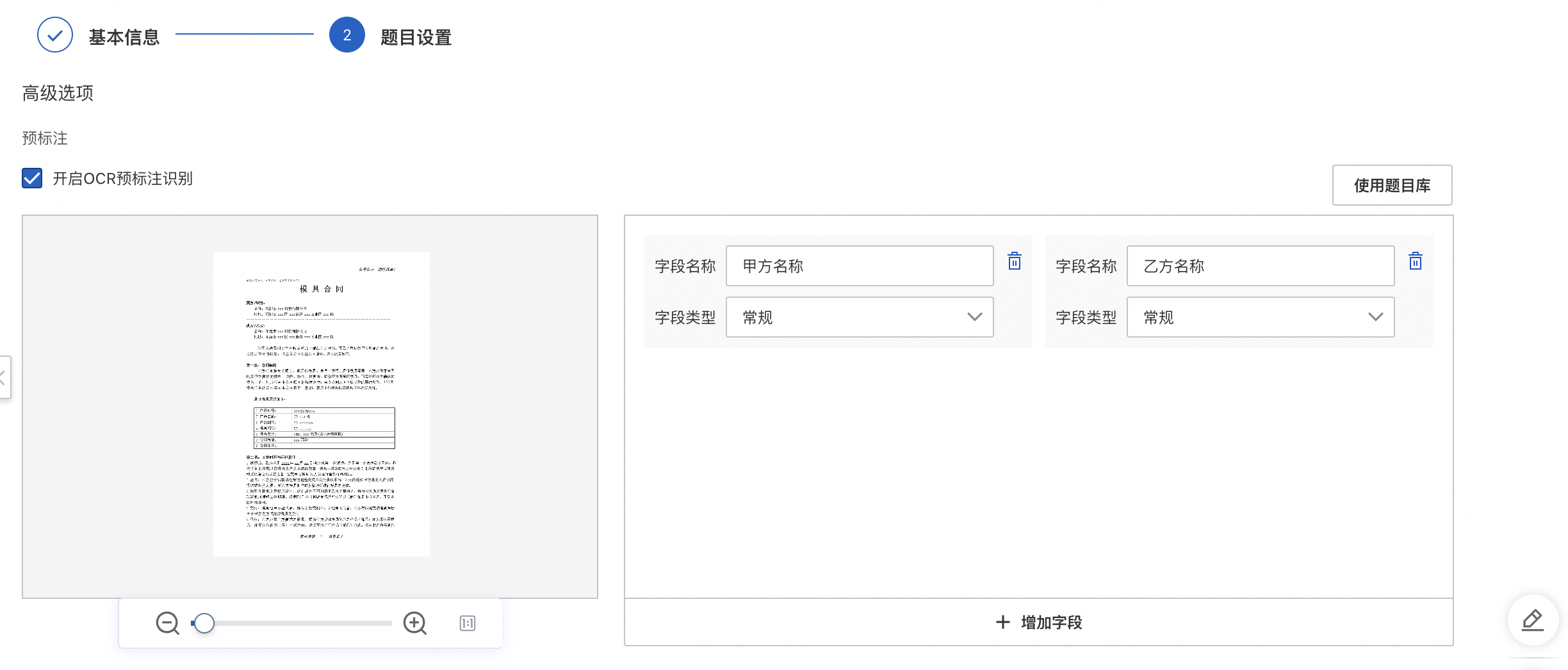
预标注:开启OCR预标注识别后,在标注时画框之后会自动识别出框内文字内容,提高标注效率。
题目库:本任务中,已存在的题目,用户可通过查看题目库选择合适的题目用于标注任务的制定。
字段名称:识别字段对外透出的名称,即API接口中对应的名称,且字段名需全局唯一。
字段类型:字段属性定义,选择合适的字段类型可提升字段识别端到端效果,支持选择通用字段或用户自行添加自定义字段。无需后处理选择常规字段类型即可。
标注
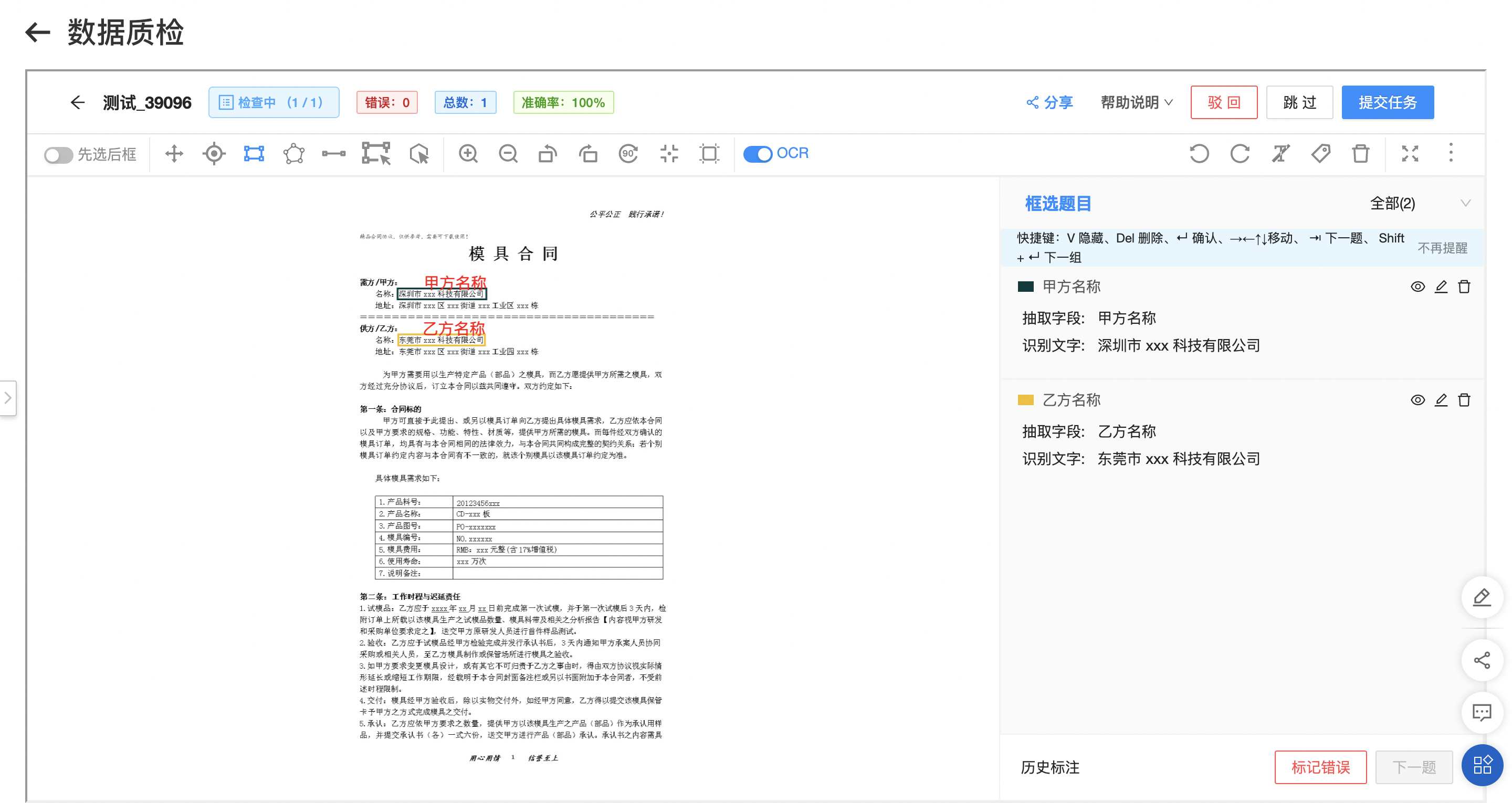
在「数据中心-标注任务」中,选择已创建的标注任务,点击去标注进入数据标注界面。在标注工具中,可通过框选按钮进行待识别字段的框选标注,选择对应的题目,并仔细检查核对自动识别的文字内容。待所有图片及其所有待识别字段都依次完成标注后,点击提交任务完成该部分标注。
标注数据的质量(文字及位置)将直接影响模型训练的效果与评测指标。
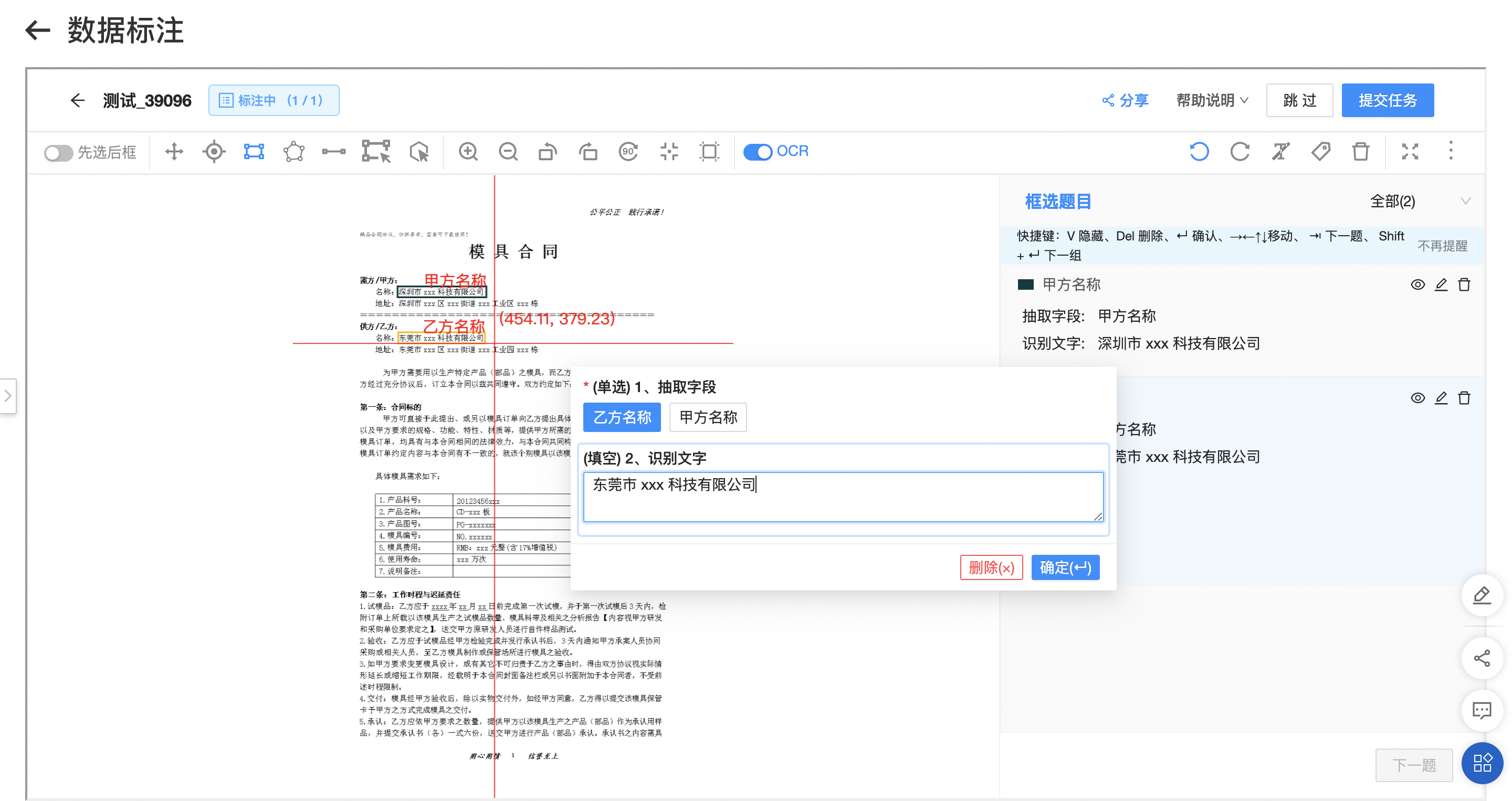
如遇见错误数据或不可标注数据,可选择跳过该张图片。
质检
进入「数据中心-标注任务」界面,选择已标注完成的任务进行质检。质检员可进行标注修改与驳回,完整当前所有标注任务后进行任务提交。注意核对所有字段是否均已完成标注。
步骤三: 模型训练与测评
进入「模型中心」,点击创建模型进入模型创建界面,进行训练集标注结果和测试集标注结果选择,同时完成和基本信息填写。创建模型成功后自动进入模型训练。
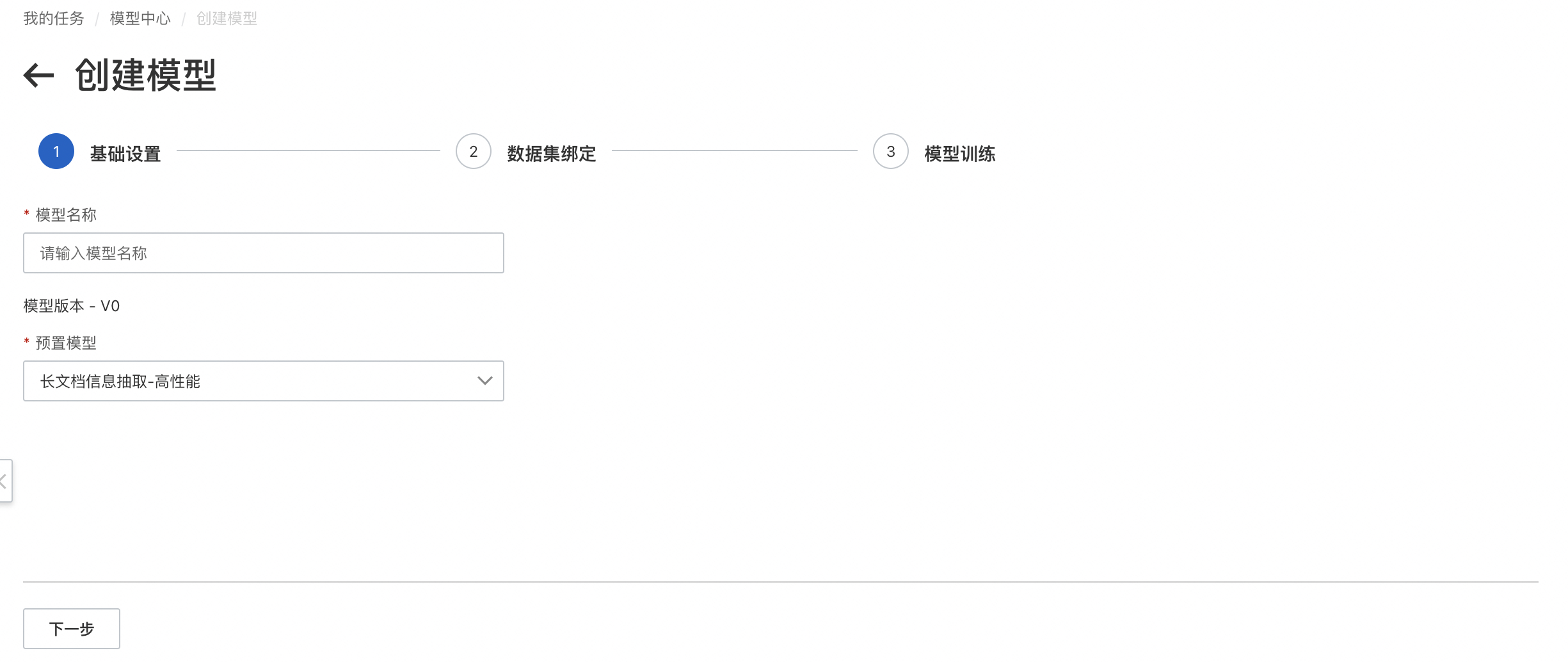
「预置模型」:长文档现支持「高性能」和「混合版面」两个版本。
「高性能模型」:适用于文档样式/格式较为简单的文档,例如仅包含标题、段落的文档,支持的文档格式包括PDF/图片。
「混合版面模型」:适用于文档样式/格式较为丰富的文档,例如包括标题,段落,表格、表单等内容的文档,支持的文档格式包括PDF/图片。
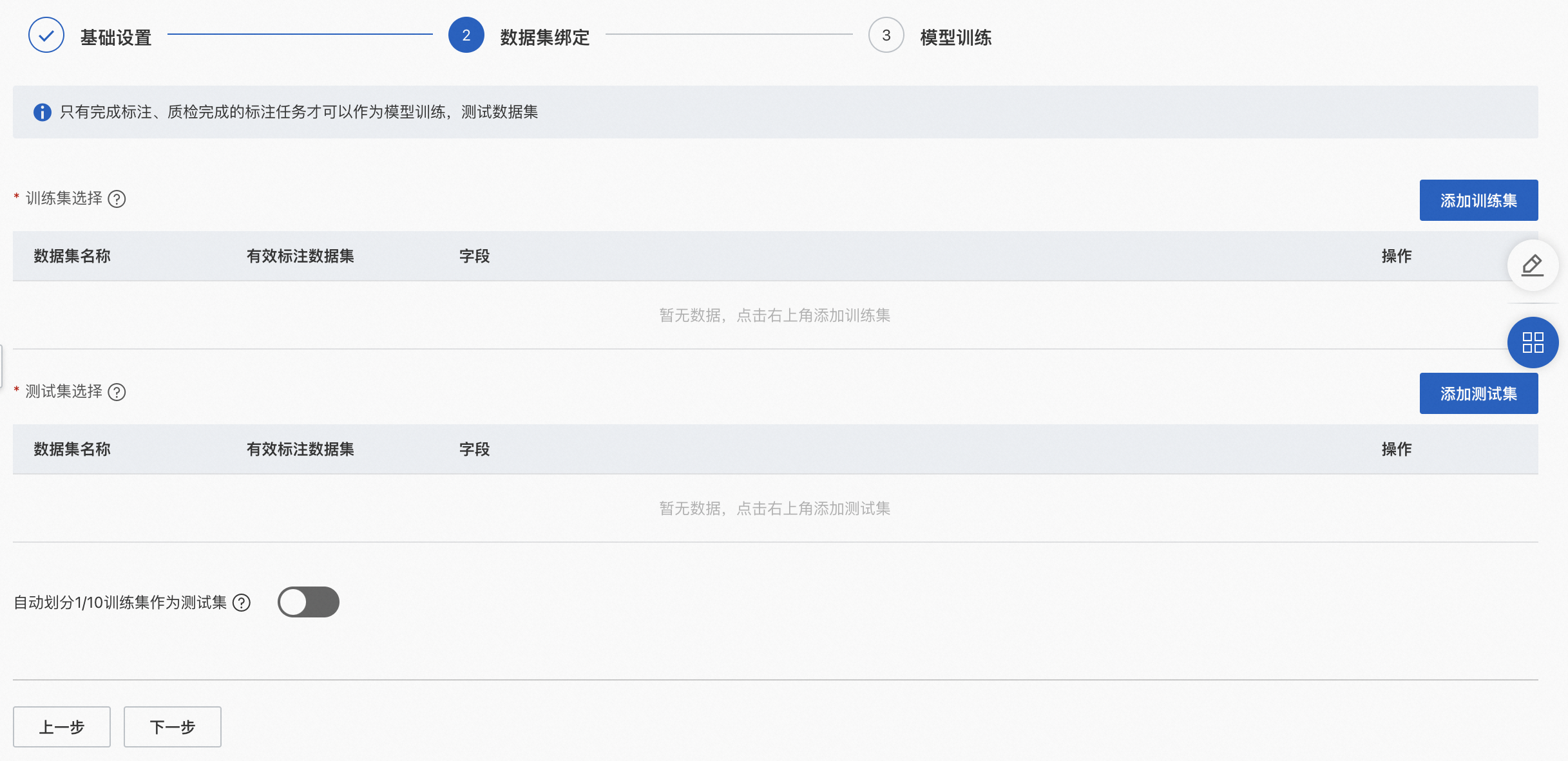
「训练集」:用于训练模型的数据源,只能选择标注且质检完成的数据集作为训练集,且已被选为测试集的数据集不可再次选择。建议选择20张以上有效数据进行模型训练。
「测试集」:用于测试模型的数据源,只能选择标注且质检完成的数据集作为测试集,且已被选为训练集的数据集不可再次选择。
「自动划分1/10训练集作为测试集」:若打开此按钮,则无需手动再次选择测试集,系统直接自动划分1/10训练集作为测试集。如打开自动划分功能前已存在完成上传测试集,打开开关后,系统将忽略此前手动上传的测试集数据。
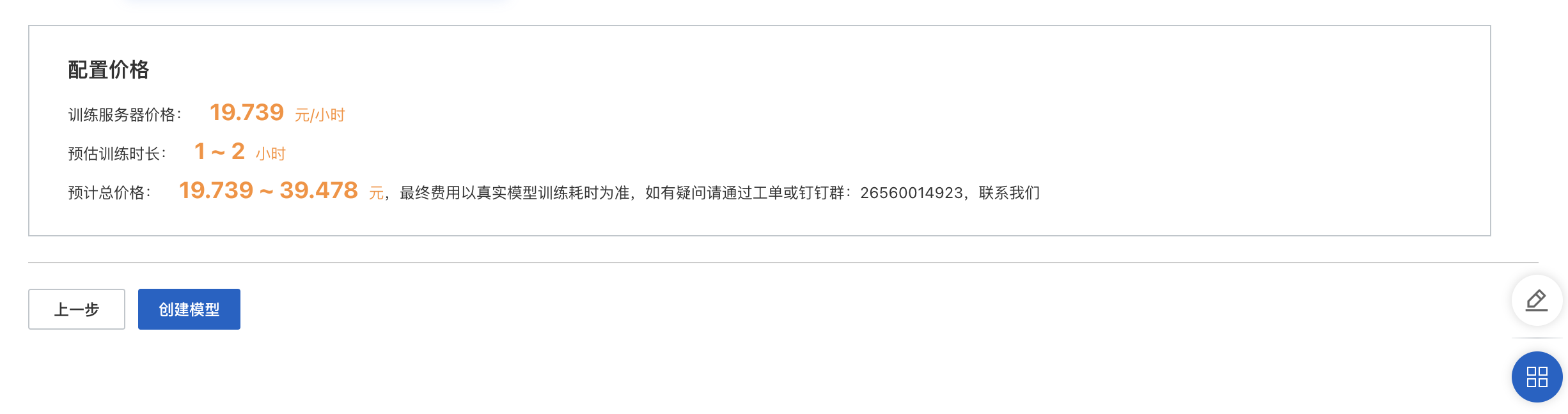
模型训练费用及预估时长。根据任务类型及数量变动,以界面显示数字为准。
「训练时长」:由数据量、标注情况、机器资源等多种因素共同决定。如采用V100机器,6万字数约需1分钟训练时长。
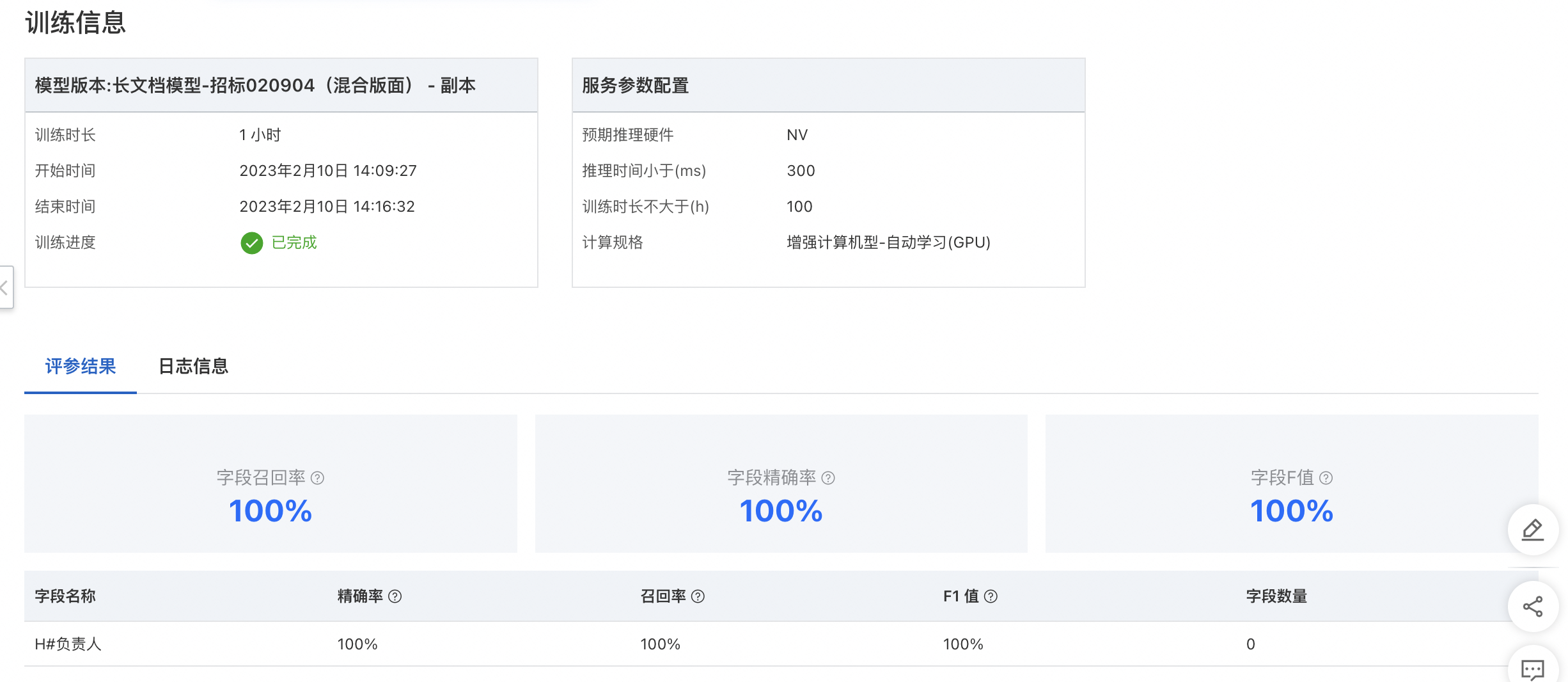
算法评估评价指标评:包括整体指标、字段指标两个维度。
整体指标 - 均值
精确率:算法模型精确率(Precision),未经规则后处理修正,为被识别为正类别的样本中,真实为正类别的比例,有正确预测的字段个数 / 所有预测的字段个数,即测试集中被识别出来的字段占该类字段标注框一致(内容+位置)比例。

召回率:算法模型召回率(Recall),未经规则后处理修正,为所有真实为正类别的样本中,被正确识别为正类别的比例,有正确预测的字段个数 / 所有真实正确的字段个数。
F值:综合评价指标(F1-Measure),为精确率和召回率的加权调和平均,常用于评价分类模型的好坏。
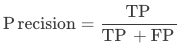
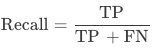
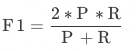
字段指标
精确率:算法模型精确率(Precision),未经规则后处理修正,测试集中该字段正确字段个数 / 该字段预测的总数。
召回率:算法模型召回率(Recall),未经规则后处理修正,测试集中该字段正确字段个数 / 该字段真实正确的总数。
F1值:综合评价指标(F1-Measure),未经规则后处理修正,测试集中为精确率和召回率的加权调和平均。
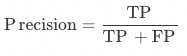
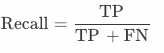
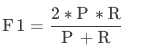
步骤四: 模型部署
模型训练完成后,进入「模型中心-模型详情」,点击页面底部「去部署」按钮,即可开始模型部署。模型部署需要一定时间,部署成功后即可通过在线体验可视化测试模型效果或直接使用API进行在线服务调用。
OCR文档自学习自2023年8月23日开启全面商业化,模型训练按时长计费,模型推理调用按调用量计费,详情可见OCR文档自学习计费。
小工具-题目库
题目库:应用于「题目设置」环节,预先创建标注任务字段,此题目支持多次引用;即多标注任务若所需标注字段相同,可通过题目库选择,减少多次编辑题目人力成本并降低题目编辑错误可能性。
若重新修改题目库,不会对已经发起的标注任务或模型产生影响。