
跨机通信:在PAI-PPU中使用跨机RDMA网络
PAI中的ml.gp7vf.16.40xlarge和ml.gp7vf.16.46xlarge机型使用了自研RDMA网卡,在使用过程中,请确保容器环境中已经声明如下环境变量,以确保跨机通信使用RDMA网络:
export NCCL_SOCKET_IFNAME=eth0
export NCCL_IB_HCA=
export NCCL_DEBUG=INFO
export NCCL_IB_DISABLE=1关键环境变量 | 环境变量说明 |
NCCL_SOCKET_IFNAME | 通信库选择建连的端口,不同的机型、多租和单租都有差异,不配置或者配置错误可能会导致通信库建连不起来 |
NCCL_DEBUG | 一般配置为INFO,如果不配置,可能导致没有足够的日志来定位问题 |
NCCL_IB_HCA | 指定RDMA通信的网卡,不同的机型下IBdev的数量和命名规则是不一样的,这里我们做了适配,所以配置时候只要为空就会匹配所有网卡 |
NCCL_IB_DISABLE | 默认是0,需要配置成1 |
上述环境变量在PAI-PPU官方镜像中已经内置,请勿随意更改。
机内通信:在PAI-PPU中使用最佳ICN-Link拓扑
PAI-PPU机型使用了独特的16卡ICN-Link机内互联(如下图所示)。为了能达到最优的性能,针对模型任务的不同并行策略,需要通过环境变量配置合理的CUDA设备顺序。
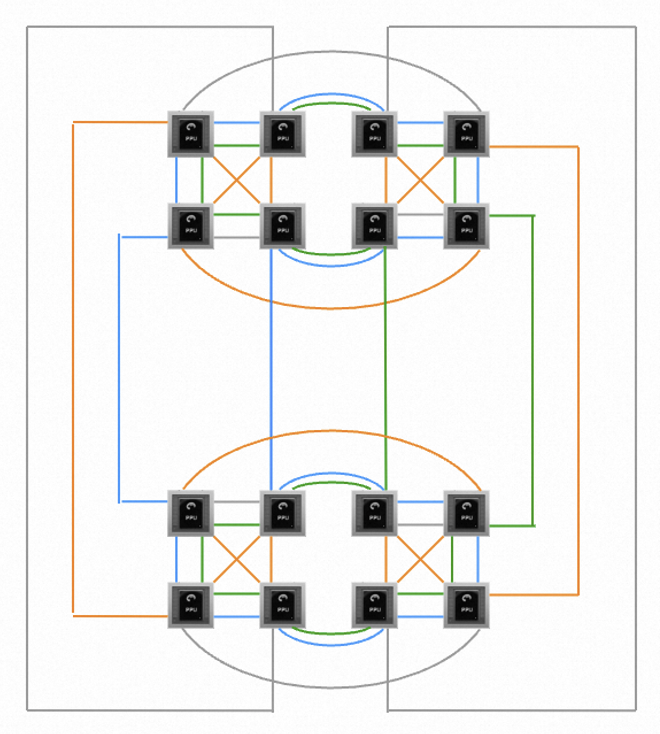
一般来说,TP(张量并行)对通信带宽更为敏感,只需考虑TP并行度,设置相应的CUDA设备顺序即可。
并行策略 | 环境变量设置 |
TP 2 | export CUDA_VISIBLE_DEVICES=4,7,5,6,1,2,0,3,12,15,13,14,9,10,8,11 |
TP 4 | export CUDA_VISIBLE_DEVICES=4,5,7,6,0,1,3,2,9,8,10,11,13,12,14,15 |
TP 8 | export CUDA_VISIBLE_DEVICES=4,5,7,6,2,3,1,0,13,12,14,15,11,10,8,9 |
TP1/TP 16 | 无需配置 |
当采取复杂的5D并行策略时,一般也只需考虑TP并行度(如无TP并行则视为TP=1)。如遇极端情况导致任务运行异常或性能受损,建议提交工单寻求技术支持。