
在PPU上快速部署DeepSeek-R1/V3推理服务
更新时间:
复制为 MD 格式
DeepSeek系列模型(如R1/V3)是由深度求索公司推出的高性能推理模型,PAI Model Gallery现已支持在PPU资源上快速部署DeepSeek系列模型的推理服务。
操作步骤
本文以DeepSeek-R1为例演示操作流程,该流程同样适用于在PPU上部署其他模型。
登录PAI控制台,左上角选择支持PPU资源的地域,本文以乌兰察布为例为您介绍操作步骤。
说明目前支持PPU资源的地域包括:乌兰察布、北京、上海、杭州。
在左侧菜单栏单击工作空间列表,选择进入目标工作空间。如果您有PPU的资源配额,可选择关联该配额的工作空间。
在左侧菜单栏单击Model Gallery,在模型列表中搜索并选择DeepSeek-R1模型卡片。
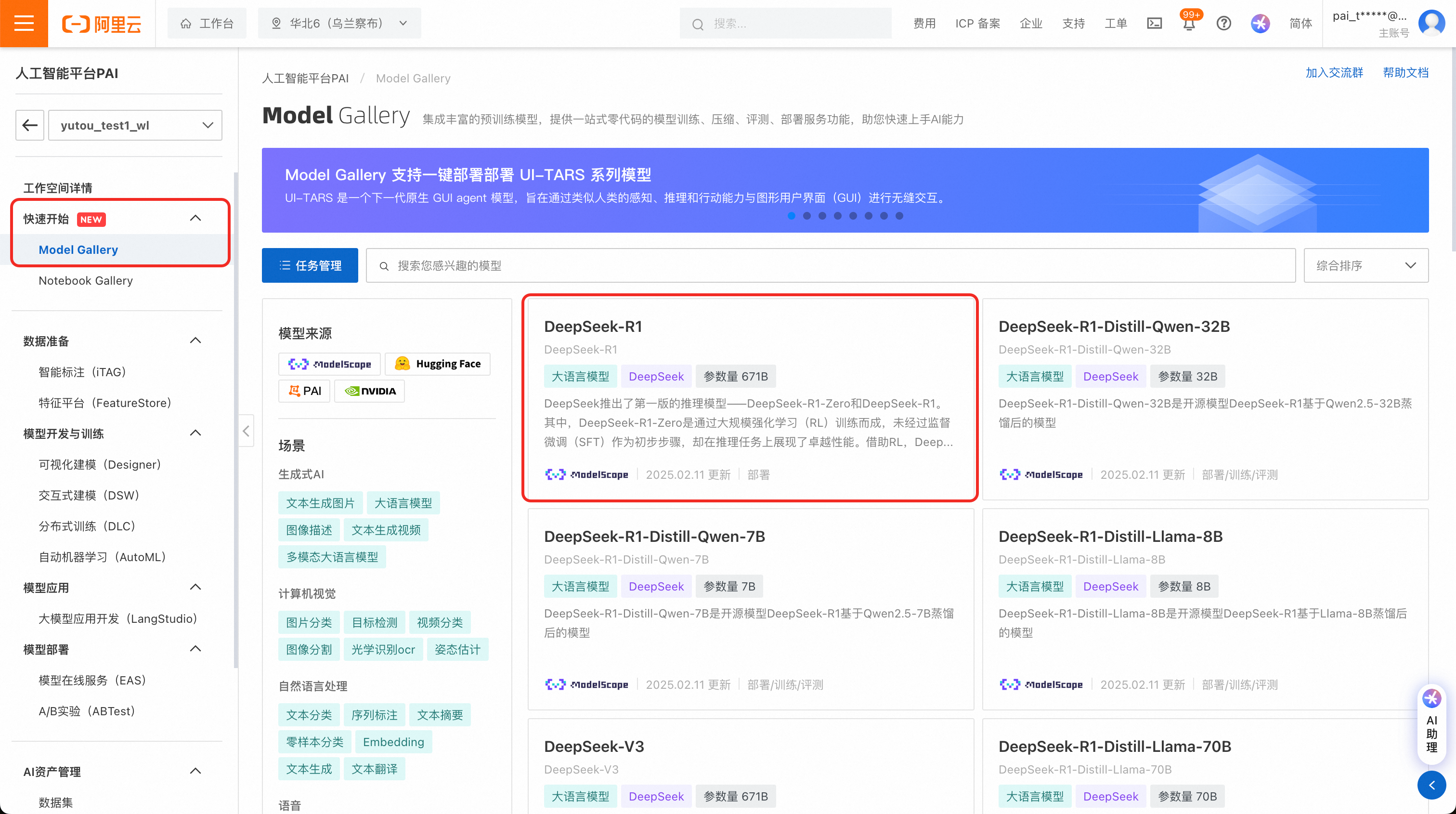
进入模型详情页面,然后单击右上角的部署。
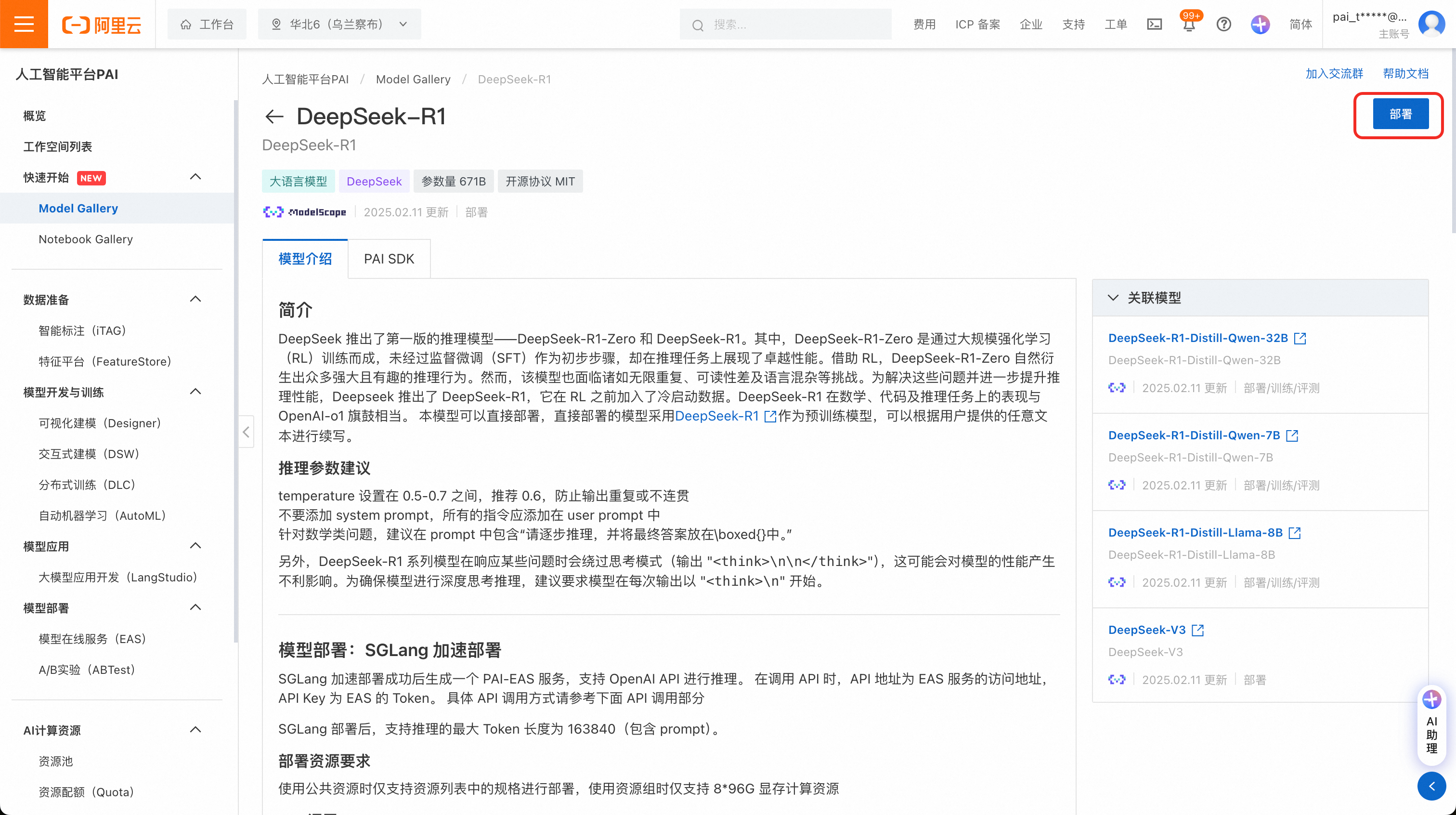
在部署页配置如下关键参数,其他参数默认即可。
推理引擎:选择vLLM。
部署模板:选择单机-GP7V机型。
资源类型:可选择公共资源,或者如果已有PPU资源配额,可选择资源配额。
公共资源:采用按量付费模式。资源规格请选择
ml.gp7vf.16.40xlarge或ml.gp7va.16.48xlarge。资源配额:资源配额选择PPU配额,部署资源可配置如下:

专有网络配置:如果选择使用公共资源,则必须配置专有网络VPC、交换机、安全组。

单击部署按钮,等待服务部署成功。
目前公共资源组的后付费PPU库存紧张,如使用公共资源组可能需要较长时间等待资源。您可以单击更多 > 更多信息查看部署状态信息。

调用模型服务。部署成功后即可调用模型推理服务,您可以直接参考模型详情页介绍的API调用模型,或查看文档通过网关进行公网或内网调用(默认)。

该文章对您有帮助吗?