
本文介绍如何在ACS中使用GU8TF和PPU快速搭建QwQ-32B推理服务。
背景信息
阿里云最新发布的QwQ-32B模型,通过强化学习大幅度提升了模型推理能力。
QwQ-32B是Density模型,可在GU8TF/PPU上单卡完成推理服务部署。
ACS可以提供单卡GU8TF/PPU的算力部署能力,您只需要为单卡付费。
准备工作
已完成首次使用容器计算服务,需要开通容器计算服务ACS,并为其授权相应云资源的访问权限。
创建ACS集群
本步骤介绍如何通过配置主要参数快速创建一个ACS集群。
关于创建ACS集群的详细配置参数说明,请参见创建ACS集群。
-
登录容器计算服务控制台,在左侧导航栏选择集群列表。
-
在集群列表页面,单击页面左上角的创建集群。
在创建集群页面,进行如下配置。其余配置项使用默认设置即可。
配置项
说明
示例值
集群名称
填写集群的名称。
ACS-PPU-Inference地域
选择集群所在的地域。
华北6(乌兰察布)单击确认配置,在满足所有依赖检查后,单击创建集群。
集群的创建时间需要约5-10分钟。
准备存储卷和模型文件
大语言模型因其庞大的参数量,需要占用大量的磁盘空间来存储模型文件,建议参见使用ACS快速构建大语言模型数据存储卷来持久化存储模型文件。本示例以使用OSS为例,默认创建了OSS bucket、PV(
oss-pv)、PVC(oss-pvc)和下载模型文件的临时Pod。通过终端进入临时Pod中,依次执行如下命令,下载相应模型文件至OSS挂载的本地路径,本示例中为
/data目录。pip install modelscope modelscope download --model Qwen/QwQ-32B --local_dir /data/QwQ-32B
部署GPU算力
以下步骤在阿里云ACS控制台操作,创建一个Deployment来部署大模型推理任务。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 自定义资源。
单击YAML创建资源,填入如下YAML,点击创建。
本示例中使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间,请按实际情况替换为同地域的VPC镜像地址。
PPU示例
apiVersion: apps/v1 kind: Deployment metadata: labels: app: llm-test name: llm-test namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: llm-test template: metadata: labels: alibabacloud.com/compute-class: gpu alibabacloud.com/gpu-model-series: PPU810E alibabacloud.com/compute-qos: default app: llm-test spec: containers: - command: - sh - -c - python3 -m vllm.entrypoints.openai.api_server --model /mnt/QwQ-32B --tensor-parallel-size 1 --trust-remote-code --max-model-len 64000 --gpu-memory-utilization 0.95 # /mnt/QwQ-32B 为模型在pod中的路径 image: acs-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.02-v1.4.2-vllm0.7.2-torch2.5-cuda12.6-20250304 imagePullPolicy: IfNotPresent name: llm-test resources: limits: cpu: 10 memory: 80G alibabacloud.com/ppu: 1 ephemeral-storage: 200Gi requests: cpu: 10 memory: 80G alibabacloud.com/ppu: 1 ephemeral-storage: 200Gi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /mnt #OSS挂载路径 name: data - mountPath: /ppu-data name: ephemeral dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: data persistentVolumeClaim: claimName: oss-pvc #oss-pvc为通过OSS创建的存储声明 - name: ephemeral emptyDir: sizeLimit: 200G --- apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "internet" service.beta.kubernetes.io/alibaba-cloud-loadbalancer-ip-version: ipv4 labels: app: llm-test name: svc-llm namespace: default spec: externalTrafficPolicy: Local ports: - name: serving port: 8000 protocol: TCP targetPort: 8000 selector: app: llm-test type: LoadBalancerGU8TF示例
apiVersion: apps/v1 kind: Deployment metadata: labels: app: llm-test name: llm-test namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: llm-test template: metadata: labels: alibabacloud.com/compute-class: gpu alibabacloud.com/gpu-model-series: GU8TF alibabacloud.com/compute-qos: default app: llm-test spec: containers: - command: - sh - -c - python3 -m vllm.entrypoints.openai.api_server --model /mnt/QwQ-32B --tensor-parallel-size 1 --trust-remote-code --max-model-len 64000 --gpu-memory-utilization 0.95 # /mnt/QwQ-32B 为模型在pod中的路径 image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-nv-pytorch:25.02-vllm0.7.2-sglang0.4.3.post2-pytorch2.5-cuda12.4-erdma-20250224 imagePullPolicy: IfNotPresent name: llm-test resources: limits: cpu: 10 memory: 80G nvidia.com/gpu: 1 ephemeral-storage: 200Gi requests: cpu: 10 memory: 80G nvidia.com/gpu: 1 ephemeral-storage: 200Gi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /mnt #OSS挂载路径 name: data - mountPath: /gu8tf-data name: ephemeral dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: data persistentVolumeClaim: claimName: oss-pvc #oss-pvc为通过OSS创建的存储声明 - name: ephemeral emptyDir: sizeLimit: 200G --- apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/alibaba-cloud-loadbalancer-address-type: "internet" service.beta.kubernetes.io/alibaba-cloud-loadbalancer-ip-version: ipv4 labels: app: llm-test name: svc-llm namespace: default spec: externalTrafficPolicy: Local ports: - name: serving port: 8000 protocol: TCP targetPort: 8000 selector: app: llm-test type: LoadBalancer说明GPU相关Annotation,请参见ACS Pod实例概述。
PPU规格,请参见PPU Pod规格表。
GU8TF规格,请参见GPU Pod规格表。
第一次创建需要拉取镜像,大约需要20分钟左右,您可以在目标集群工作负载 > 容器组 > 事件下查看Pod的运行状态。
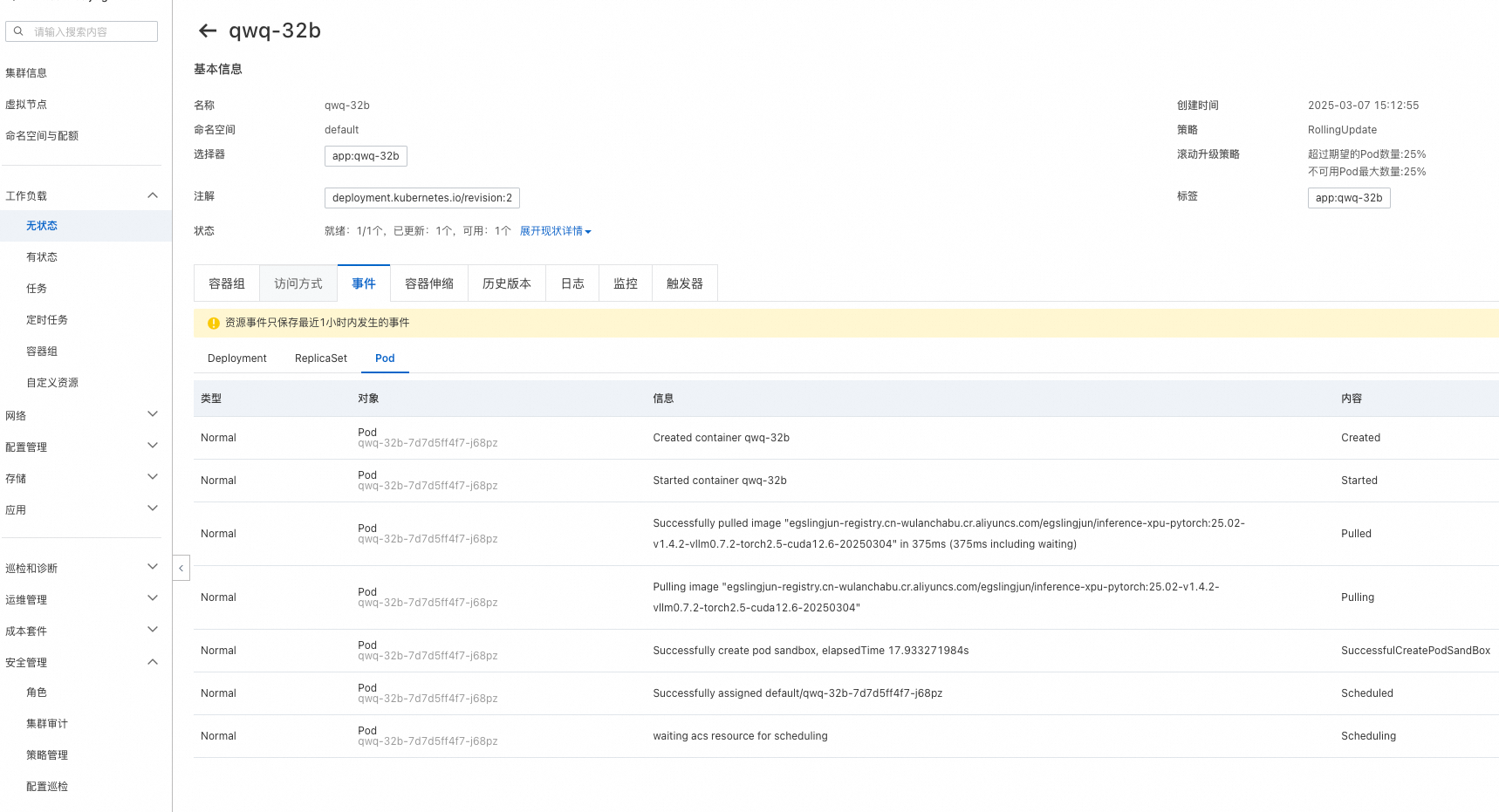
Pod为Running状态即为创建成功,Pod拉起后会自动拉起vLLM serving服务,您可以在目标集群工作负载 > 容器组 > 日志下查看log,有如下输出则说明服务启动成功。QwQ-32B模型加载需要约30分钟。
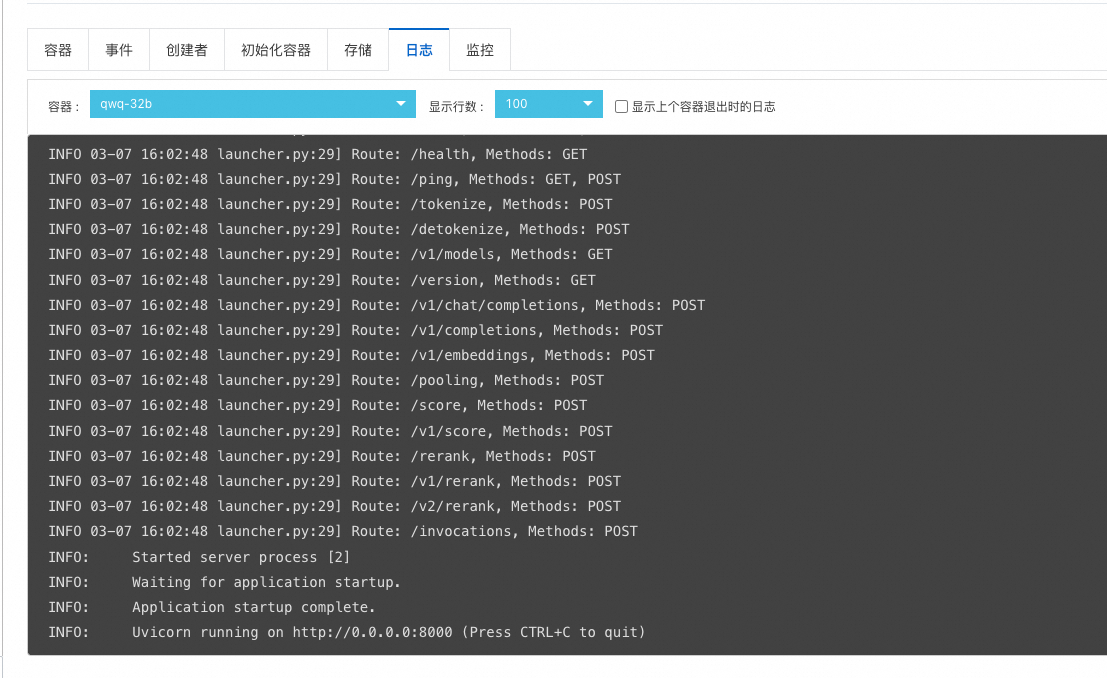
启动推理服务
在容器计算服务控制台中网络 > 服务,可以看到之前创建的svc-llm服务,该服务的外部IP地址(External IP)即为推理服务的公网IP。
在客户端测试vLLM推理对话功能的操作如下。
# 将<IP>改为上一步中创建的服务的外部IP地址 # model为模型在pod中的路径 curl http://<IP>:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/QwQ-32B", "messages": [ { "role": "user", "content": "给闺女写一份来自未来2035的信,同时告诉她要好好学习科技,做科技的主人,推动科技,经济发展;她现在是3年级" } ], "max_tokens": 1024, "temperature": 0.7, "top_p": 0.9, "seed": 10 }'预期输出:
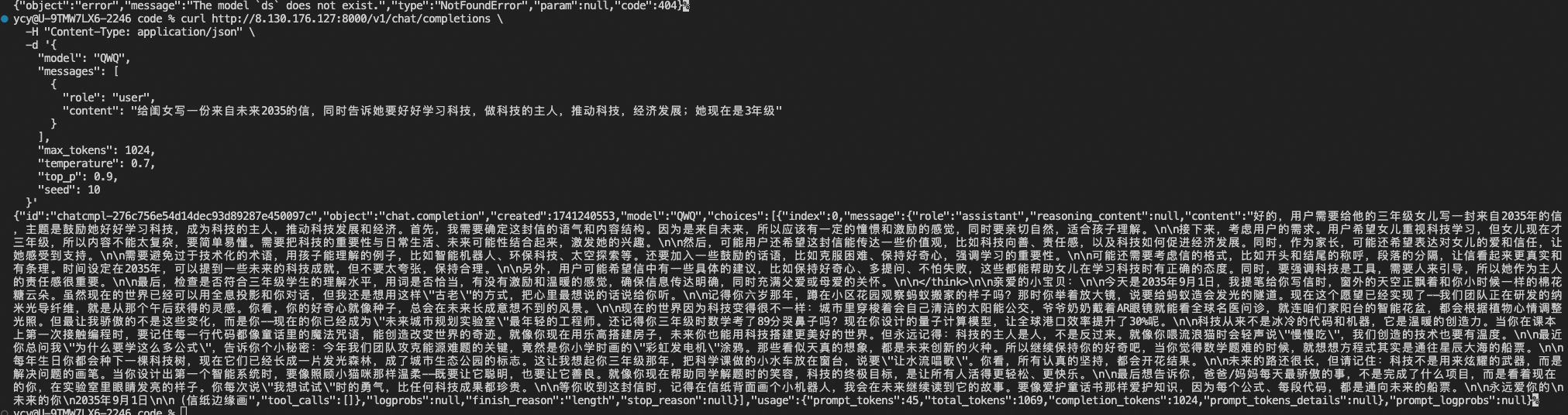
至此,使用ACS快速部署运行在PPU上的QwQ-32B推理服务完成。
附录
PPU Pod规格表
PPU | vCPU | Memory(GiB) | Memory支持步长(GiB) | 临时存储(GiB) |
1 | 2 | 2-16 | 1 | 30G ~ 384G |
4 | 4-32 | 1 | ||
6 | 6-48 | 1 | ||
8 | 8-64 | 1 | ||
10 | 10-80 | 1 | ||
2 | 4 | 4-32 | 1 | 30G ~ 768G |
6 | 6-48 | 1 | ||
8 | 8-64 | 1 | ||
16 | 16-128 | 1 | ||
22 | 32,64,128,225 | N/A | ||
4 | 8 | 8-64 | 1 | 30G ~ 1.5T |
16 | 16-128 | 1 | ||
32 | 32,64,128,256 | N/A | ||
44 | 64,128,256,450 | N/A | ||
8 | 16 | 16-128 | 1 | 30G ~ 3T |
32 | 32,64,128,256 | N/A | ||
64 | 64,128,256,512 | N/A | ||
88 | 128,256,512,900 | N/A | ||
16 | 32 | 32,64,128,256 | N/A | 30G~6T |
64 | 64,128,256,512 | N/A | ||
128 | 128,256,512,1024 | N/A | ||
176 | 256,512,1024,1800 | N/A |