
SDK Release Note
PPU SDK v1.4.3-hotfix release note
1. Main Features and Bug Fix Lists
新增VLLM 0.7.3、SGLang 0.4.3的支持,提升Deepseek-V3/R1推理性能;
初步优化Deepseek-V3/R1 MLA kernel的性能(单机VLLM与v1.4.2相比)
throughput平均提升为27.69%
ttft平均提升为8.14%
tpot平均提升为29.99%
Enable多机跨节点CUDA Graph功能;
修复torch.nn.functional.conv2d报错:GET was unable to find an engine to execute this computation;
修复pccl send/recv调用导致的内存泄漏,相应泄漏问题可能在有send/recv op使用的场景如MoE模型或含Pipeline Parallel的大模型并行训练、推理等场景中存在;
2. Known Issues
计算库:算子库Gemm计算中用到FP32 tensor core时,可能有coner case存在计算错误,预计在下个版本修复。
PPU SDK v1.4.2 release note
1. Main Features and Bug Fix Lists
新增对Ubuntu 24.04 的支持;
新增VLLM 0.7.2、SGLang 0.4.2的支持,以便更好地支持Deepseek-V3、Deepseek-R1、Qwen2.5-Max;
修复vllm加载LoRA且开启TP并行时custom allreduce kernel会出现hang的问题;
修复容器有
SYS_ADMIN权限时无法正常使用PPU问题;
2. Known Issues
计算库:算子库Gemm计算中用到FP32 tensor core时,可能有coner case存在计算错误,预计在下个版本修复。
跨节点CUDA Graph功能在当前版本支持上还存在问题,预计下个版本会修复。
PPU SDK v1.4.1 release note
1. Main Features and Bug Fix Lists
用户态驱动/运行时
支持texture基本功能;
修复
HGGC_AUTO_DISPATCH_BARRIER环境变量打开时hang的问题;修复v1.4版本SDK搭配v1.4版本之前的老版本KMD驱动时
ppu-smi无法显示0号卡进程列表的问题;
计算库
acsolver新增接口支持:Xgetrf、Xgetrs、Spotrf、Dpotrf、Spotrs、Dpotrs;
修复gemm m超大尺寸导致
grid.y > 65536时计算正确性问题;
通信库
优化单机小size延迟敏感场景下的allreduce性能,默认打开了
ext-kernel plugin支持;优化多机真武810E上
topo graph search逻辑, 修复关键算子因device id变动而出现的性能下降issue;增强 'PcclStateMonitor' 功能以在用户手动关掉它的时候消除其对算子性能的影响;
修复
send/recv preconnect阶段memory初始化操作与kernel执行间的潜在冲突issue;pccl perf tools:
完成
scatter/gather/sendrecv/hypercube等新算子支持;添加
-a参数以支持用户可选设置AVG/MIN/MAX三种不同的算子时间统计方式;添加
NCCL_TESTS_SPLIT_MASK功能支持;
图像预处理
支持 DALI 1.20(CUDA 11.6及以下版本)
支持 DALI 1.44(CUDA 11.8及以上版本)
2. Known Issues
计算库:算子库Gemm计算中用到FP32 tensor core时,可能有coner case存在计算错误,预计在下个小版本会修复。
PPU SDK v1.4 release note
1. 版本概述
1.1 软件栈介绍
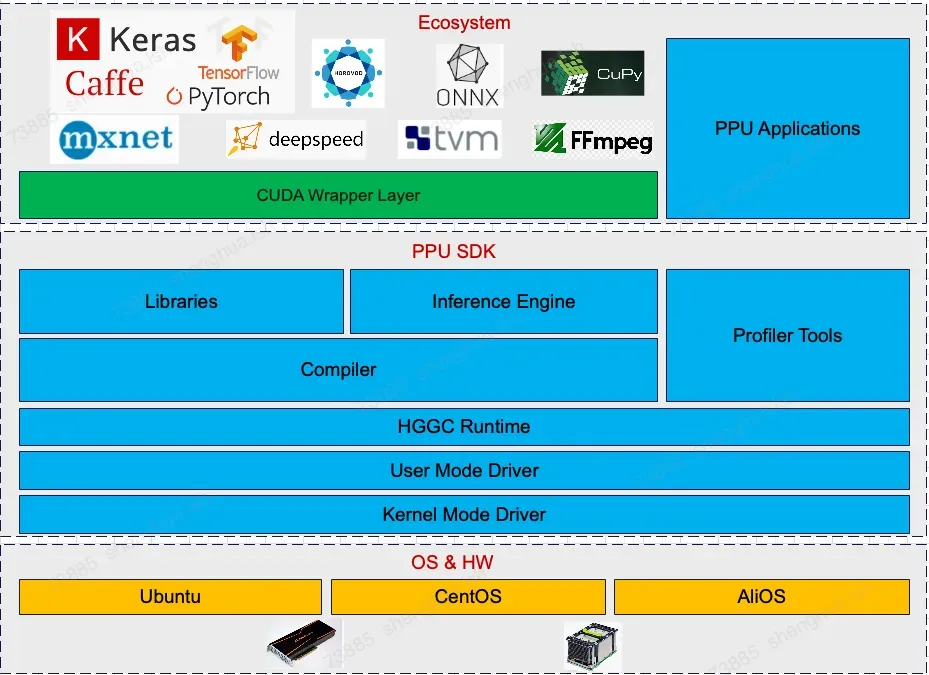
1.2 核心组件
组件名称 | 概要说明 |
Firmware | PPU固件 |
KMD | PPU内核驱动 |
UMD / HGGC | PPU用户态驱动和运行时 |
Compiler | PPU编译器工具链 |
Acompute | PPU计算加速库 |
Acext | PPU量化加速库 |
PCCL | PPU通信加速库 |
PPU SMI | PPU设备管理工具 |
PPU DCGM | PPU在线监控工具 |
Asight System | PPU性能分析工具 |
Asight Compute | PPU性能分析工具 |
PPU GDB | PPU调试工具 |
PPU MemCheck | PPU Sanitizer工具 |
PPU hgobjdump | PPU Device Binary工具 |
CUDA SDK Wrapper | CUDA API 兼容库 |
1.3 主要功能
1.3.1 Firmware
支持二进制包安装(rpm或deb);
支持动态电源管理功能,缺省模式下PPU固件会根据实时的工作负载、温度和功耗等信息动态调节核心频率(200MHZ~最大工作频率)和工作电压;
支持PPU锁频功能,详情请参见设备管理工具PPU-SMI;
支持固件安全签名和固件双备份功能,确保固件内容的安全性和可靠性;
支持电源芯片固件升级功能;
支持BMC带外管理功能,包括设备状态监控和固件带外升级等;
1.3.2 内核驱动
支持二进制包安装(rpm或deb)和runfile包安装两种方式,用户可根据需要自由选择;
支持内核驱动和PPU SDK解耦,v1.0版本之后的内核驱动和PPU SDK可任意组合使用;
支持单机单卡、单机8卡/16卡(ICN互联)、多机多卡(ICN互联)和多机多卡(GDR)多种灵活的机器形态,使用GDR功能之前需确保系统已安装
alixpu-peermem内核模块(随PPU内核驱动一起发布);支持PPU故障上报和故障处理;
支持
auto-reset功能,驱动在检测到kill overtime或cp invalid cmd错误之后会自动进行PPU设备复位,无需用户手动复位即可恢复正常。该功能默认打开,用户可通过ppu-smi查询状态或关闭该功能;支持MPS(Multi Pipe Service)功能,用户可通过
ppudbg --config_submit_mode 1/0打开或关闭该功能;支持MPS模式下小模型和大模型任务的潮汐场景使用;
支持nvml GPM指标采集功能,包括:sm利用率、sm occupancy、tensor core利用率、显存带宽利用率、pcie读写速率、icn link读写速率;
支持MIG(Multi Instance GPU)多实例功能,PPU最多支持8个实例,需注意使用MIG功能时ICN互联功能不可使用;
支持整卡直通虚拟化功能,用户可以在宿主机上解绑PPU驱动直通进虚拟机内使用,此时需要注意不同VM之间的ICN隔离;
支持SRIOV虚拟化功能,PPU最多支持8个VF (Virtual Function),需注意SRIOV和ICN互联同时开启时,只允许一个VF拥有ICN互联能力;
支持SRIOV虚拟化模式下宿主机驱动的热升级功能,即可以在虚拟机内业务运行的同时对宿主机PPU驱动进行更新;
支持SRIOV虚拟化模式下虚拟机任务的热迁移功能 (仅限单卡,ICN互联热迁移暂不支持);
新增单机16卡真武810E的正式支持并优化默认的PPU设备顺序(按照机尾排序);
新增L1/L2 cache命中率GPM指标采集,用户可通过DCGM工具查询获取;
修复使用v1.2/v1.2.1驱动采集ppu利用率指标时CPU占用率过高问题;
修复MPS潮汐模式切换时新建cuda context可能导致程序hang的问题;
修复PPU设备复位和GPM指标监控程序同时发生时引发的系统宕机问题;
修复rund场景频繁绑定/解绑PPU设备可能出现的mcu超时/掉卡问题;
调整16卡真武810E设备的逻辑编号规则以获取更好的互联性能;
优化驱动加载时间和驱动内存占用;
新增MPS潮汐模式状态查询功能;
新增Xid错误信息查询功能;
新增GPM状态查询和GPM状态启停功能;
修复ppu-smi工具的进程利用率数据和整卡利用率数据不对齐的问题;
修复ppu-smi工具的进程显存使用量和整卡显存使用量不对齐的问题;
修复使用unified memory (cudaMallocManaged)时概率性的系统hang的问题;
修复DCGM压测ECC page retirement pending flag未清除问题;
取消HBM parity Xid错误上报;
1.3.3 用户态驱动和运行时
兼容绝大多数cuda runtime api (cudaXXX) 和cuda driver api (cuXXX);
新增发生xid 896错误时输出更多错误日志方便定位问题;
优化2D/3D类型的cudaMemcpy/cudaMemset性能;
修复
asys profiling时偶发的hgpti activity record cycle invalid错误;支持环形print buffer,增强cuda device code中printf打印功能;
支持stream memory opertaion v2版本API;
支持graph management中edge data相关API;
支持graph management中batch memory op node相关API;
修复真武810E平台上qwen2-72b大模型在
vllm cuda graph enable情况下出现推理乱码的问题;修复fcn模型训练过程显存未释放的问题;
修复真武810E平台上DCGM压力测试概率性失败的问题;
修复程序中发生cuda launch error之后因为llvm符号冲突发生core的问题;
修复使用multiprocessing多进程方式执行模型推理报错的问题;
1.3.4 编译器
基于clang/llvm的编译框架,实现面向PPU架构的、host/device混合编程风格的C/C++扩展语言编译器,完整兼容cuda c/c++的编程语言规范;
提供丰富的编译功能模块,方便开发者通过API的调用方式,灵活组合编译流程,方便集成JIT编译的能力;
丰富的开发和debug 工具:hgobjdump、memcheck、ppu-gdb、sanitizer library,可以让用户更加方便地调试算法实现;
支持system level reserved shared memory特性;
支持triton 2.3.x、3.0.x;
gcc host compiler的版本支持范围在[5.5 - 12.3];
ppu-gdb:
在layout asm模式中优化kernel managed name的显示长度;
支持blockIdx等internal variables的条件断点,支持register条件断点;
支持gdb python extension特性(python版本范围在3.6-3.10);
支持device kernel断点的触发行为:一次触发和多次触发,默认为:一次触发;
1.3.5 加速库
计算加速库
闭源计算库支持:acdnn、acblas、acfft、acsolver、acrand
acdnn支持算子
Conv
BatchNorm
Pooling
Softmax
Activation
CTCLoss
Dropout
LRN
LSTM
GRU
MultiHeadAttn
Tensor Ops
SpartialTransform
Backend fusion
acblas支持算子
Level1 系列 Op
Gemv
Gemm
Matmul + epilogue
MatrixTransform
trsm
getrfBatched
getrsBatched
geqrfBatched
gelsBatched
acfft支持:R2C/C2R/C2C/D2Z/Z2Z + FFT/iFFT 变换;
acsolver支持:矩阵LU分解/求解,cholesky分解/求解,QR分解,SVD分解Jaccobi方法;
acrand支持:
伪随机生成器XORWOW、MRG32K3A、PHILOX4_32_10;
数据分布:Default/Uniform/Normal/LogNormal;
acext量化库支持:
支持A16W8/A16W4以及PerChannel/GroupWise的各种Kernel变种;
支持A8W8以及PerChanel/PerToken的各种Kernel变种;
支持WeightonlyBatchedGemv对小batchsize的加速kernel;
关键更新:
cutlass3:新增group gemm persisent策略支持;
进一步提升FA在真武810E上的性能,最高提升85%;
acext:新增a16w8 sub-channel量化支持;
MoE:新增a16w4量化支持和调优;
xformers:修复attn mask场景inf问题;
RTC:新增对group conv、gemv的RTC功能支持;
进一步增加预编译实例,减少RTC几率;
blas:新增rank=1/2 Level2 API支持;
blas:修复k=0时gemm行为不正确问题;
blas INT8 gemm:新增INT8输支持;新增NN/TN/TT支持;
blas:新增cublasSgetriBatched支持;
conv:优化wgrad > 4GB输入场景性能超100倍;
conv:修复1D SpatialTF exception问题;
acFFT:新增功能支持C2C/D2Z/Z2Z,新增多个辅助API支持;
solver:新增支持cholesky分解/求解,QR分解,SVD分解Jaccobi方法;
互联加速库
兼容支持绝大多数 nccl api (ncclXXX) 和环境变量
支持AllReduce、AllGather、ReduceScatter、Broadcast、Reduce、Send、Recv等典型互联算子;
支持单机内多卡通过ICN、PCIE、ShareMemory通信;
支持多机之间通过RDMA (GDR & non GDR) 、Socket通信;
支持多机上的610卡间进行icn scale out方式通信;
多机多卡debug功能增强,支持自动监测ppu device kernel执行hang的功能,支持分层次的comm状态dump功能并支持通过配置文件显示trigger dump;
优化多机场景下网卡通信与ppu device之间的同步开销,支持
NCCL_GDR_COPY_SYNC与PCCL_GDR_USE_DEV_MEM_FOR_RX_TAIL的功能;增加 nccl 高版本 API 、环境变量及配置支持:
新增 API 功能支持:ncclCommInitRankConfig、ncclCommFinalize、ncclCommSplit、ncclCommRegister、ncclCommDeregister、ncclMemAlloc、ncclMemFree、ncclCommGetAsyncError;
新增环境变量功能支持:NCCL_P2P_DIRECT_DISABLE、NCCL_NET_PLUGIN、NCCL_COMM_BLOCKING、NCCL_LOCAL_REGISTER、NCCL_REPORT_CONNECT_PROGRESS;
支持新的debug log subsys字段:NCCL_PROFILE & NCCL_ALLOC & NCCL_DUMP;
添加ncclRemoteError错误字段支持;
其它重要功能与问题修复:
优化多机多卡下的graph search逻辑以修复search阶段与connect阶段的proxyRank不一致的问题;
优化单机多卡场景下device memory的使用;
优化group mode下运行时host memory分配与释放;
修复单机四卡非icn全互联场景下FC algo使用时会crash的问题;
修复多机场景下机器间path type不一致时未能选择最佳path type的问题;
pccl tools:
pccl perf:
支持AllReduce、AllGather、ReduceScatter、AlltoAll、Broadcast及Reduce;
优化event based device kernel时间统计方式;
p2pBandwidthAndLatencyPerf工具增强:
支持真武810E等产品在各种多卡互联topo server下的icn p2p互联带宽与延迟性能评估;
支持类似nv p2p perf bench可以batch输出所有读写mode下带宽与延迟数据的功能;
支持显示p2p bandwidth perf ratio矩阵的功能;
支持可指定devices subset以进行p2p perf bench的功能;
修复双向CE mode读数据perf异常的问题;
pccl check tools:
支持真武810E等产品在多卡或多机多卡等场景下的功能 readiness 检查;
增加16 x 真武810E互联topo正确性的检查功能;
增加对icn link speed正确性的检查功能;
增加对acsCtrl配置正确性的检查功能;
1.3.6 Video/Image codec硬件加速
兼容Nvidia Video Codec SDK,包括cuvid decode、nvenc和nvjpeg;兼容Nvidia 2D Image NPP接口。基于此,可以直接支持ffmpeg、opencv、DALI、pytorch等上层框架的Codec硬件加速能力,不需要额外修改代码去适配。
Video Decode
Support Nvidia cuvid decoder。
Codecs:
HEVC (H.265) - ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 Profile, Level 5.1, High Tier
Main Still Profile
VP9 - vp9-bitstream-specification-v0.6-20160331-draft
Profile 0, 8-bit
Profile 2, 10-bit
AVC (H.264) - ITU-T Rec. H.264 (03/2010) / ISO/IEC 14496-10
Main Profile, levels 1 - 5.2
High Profile, levels 1 - 5.2
High 10 Profile, levels 1 - 5.2
Baseline Profile, levels 1 - 5.2
AV1 Bitstream & Decoding Process Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
AVS2
Resolution Up to 8192x8192
Up to FHD 192 streams
Video Encode
Support nvenc
Codecs:
AVC(H.264):Spec Version 12:ISO/IEC 14496-10 / ITU-T Rec. H.264 (03/2010)
Baseline Profile, levels 1 – 5.2
Main Profile, levels 1 - 5.2
High Profile, levels 1 – 5.2
High 10 Profile, levels 1 - 5.2
HEVC(H265):ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 profile, Level 5.1, High Tier
Main Still Profile
AV1 Bitstream Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
Resolution up to 4K support
Support input RGB format (converted to YUV420 via inlinePP)
Support crop, scale, rotate with inlinePP
Up to FHD 32 streams
Jpeg:
Support nvjpeg decoder & encoder
Resolution up to 32Kx32K
Support RGB format input and output with inlinePP
Support crop, scale, rotate with inlinePP
Up to UHD 960FPS
Image Process:
Support Nvidia 2D Image NPP
1.3.7 软件工具
为了满足云计算大规模集群监控需求,我们发布了如下PPU管理和监控工具和库文件,以便集成到客户集群运维监控系统中:
PPU设备管理工具ppu-smi类似Nvidia-smi。详细介绍请参考设备管理工具PPU-SMI;
ppu-smi v1.4新功能主要包含:
增加查询XID错误码的描述
增加查询performance counter状态的描述
增加gpm子命令查询和设置GPM的描述
增加查询潮汐模式的描述
增加查询产品架构和Minor number的描述
增加设置和查询MPS模式的描述
数据中心管理和监控工具PPU DCG类似Nvidia DGCM;
DCGM v1.4新功能主要包含:
支持ICN每链路收发速率相关field ID
更新field ID支持情况列表
hgml类似Nvidia nvml;
发布了PPU性能分析工具Asight Systems和Asight Compue(类似 Nvidia Nsight Systems/ Compute),可以支持用户进行单机、多机训练、推理等场景的性能分析。
Asight Systems 是一款低开销的系统级的性能分析工具,用来采集系统各种事件,CPU和PPU的活动,API执行时间以及相关调用栈,NVTX,CPU/PPU activity关联关系等,在Timeline View上统一的可视化呈现出来。 通过imeline View,开发人员可以方便分析CPU/PPU的负载和关联关系,找到性能瓶颈,确保CPU和PPU能够协调的工作,确保最大的并行度。详细介绍请参考程序性能分析套件Asight Systems。
Asight Systems v1.4新功能主要包含:
UI样式美化与布局调整,更多tab 样式用于切换
asys支持指定CPU和Python Profiling调用栈深度
asys支持指定采集应用程序部分进程的跟踪数据
asys支持采集PPU频率和温度等基本信息
asys支持采集CPU调用栈信息更短的采样周期
asys stats支持HGGC kernel grid block统计和跟踪导出
asys支持HGGC Python backtrace调用栈采集
asys支持memory python backtrace调用栈采集
asys python functions trace支持采集python进程下的所有线程
Timeline View支持显示HGTX自定义颜色
Timeline View支持filter后PPU节点时间占比更新
Timeline View支持显示RDMA网卡metrics指标信息
Timeline View支持显示PPU Activity依赖关系
Timeline View支持独立显示HGGC Graph信息
Timeline View支持标记时间线
Timeline View支持以不同的颜色显示不同类型的Video时间线
Timeline View中HGGC Launch API支持以kernel名显示
支持在报告打开过程中关闭报告标签页
Events View增加了平铺模式,增强搜索记录的自动填充
Function View增加了火焰图和冰川图
HGTX range汇总支持指定进程和线程列表
Asight Compute是一款kernel性能分析工具,通过采集PPU硬件perf counter,组合成为一系列性能指标,我们称为metrics。GUI通过各种维度,把这些metrics呈现出来, 帮助用户深入分析和优化kernel。详细介绍请参考Kernel分析器Asight Compute。
Asight Compute v1.4新功能主要包含:
新增真武810E 16卡、8卡拓扑图显示
Source Page支持显示Source Marker,支持采集和显示Kernel的汇编指令的执行信息,包括Instructions Executed和Thread Instructions Executed
metrics修正和稳定性增强
发布了PPU调试工具PPU-GDB,允许在同一个应用程序中同时调试GPU和CPU代码。
发布了PPU Memcheck,是一组用于功能性正确检查的工具套件。该套件中包含了一系列的检查工具,包括memcheck、initcheck、synccheck、racecheck。
发布了PPU Binary工具hgobjdump,用于提取binary中的device相关信息。
1.4 支持的操作系统
类别 | 操作系统 | 架构 | 内核版本 | GCC |
Ubuntu | Ubuntu 20.04 LTS | x86_64 | 5.4.0-131-generic (GA) | 9.5.0 |
5.4.0-92-generic | 9.5.0 | |||
Ubuntu 18.04 LTS | 4.15.0-112-generic (GA) | 7.5.0 | ||
4.18.0-15-generic | 7.5.0 | |||
CentOS | CentOS8.2 | 5.10.134-007.ali5000.al8.x86_64 | 8.5.0 | |
Alios | Alios7U2 | 5.10.112-005.ali5000.alios7.x86_64 | 10.2.1 | |
5.10.84-004.ali5000.alios7.x86_6 | 10.2.1 | |||
alippu-driver-4.19.91-014.kangaroo.alios7.x86_64 | 10.2.1 | |||
Afa3 | ALinux3 | 5.10.134-12.2.al8.x86_64 | 10.2.1 | |
5.10.134-13.al8.x86_64 | 10.2.1 |
1.5 SDK版本兼容性说明
V1.4版本向前兼容 V1.2 与 V1.3 的 kmd/mcu_fw。
真武810E需要使用V1.2.1以上的mcu_fw版本。
2. CUDA生态兼容
2.1 介绍
在PPU平台上开发应用程序,用户既可以基于PPU SDK API开发应用程序,也可以使用CUDA语言编写应用程序,经过PPU编译器重新编译后在PPU 上运行,下图展示了同样的CUDA应用程序分别在PPU和GPU上编译、运行的差异。
CUDA 生态兼容方法:通过代码自动生成技术生成CUDA SDK Wrapper来自动兼容CUDA不同版本的APIs,从而使得用户的CUDA程序经过PPU编译器重新编译后即可在PPU上运行。
通过CUDA生态系统的兼容方案,PPU与GPU在源代码级别上是编译兼容的,但PPU二进制与GPU二进制不兼容。
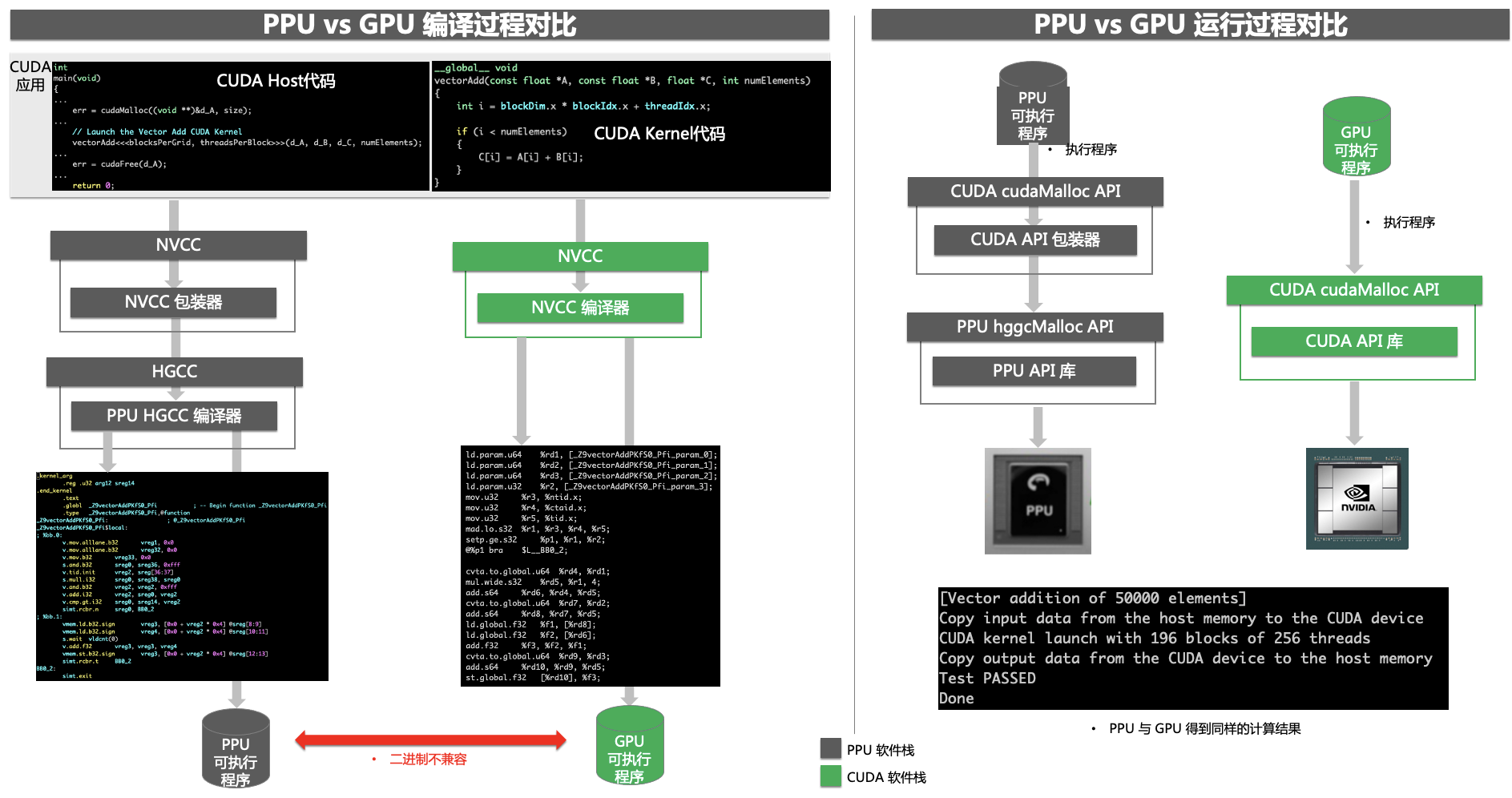
2.2 CUDA APIs兼容版本
截至PPU SDK V1.4版本,对CUDA APIs版本支持到12.6.0,但是限于硬件架构的区别,对CUDA APIs兼容主要在DeepLearning范畴,下表是目前支持的版本列表。更多CUDA兼容性内容请参见CUDA兼容性。
CUDA Version |
11.1 |
11.2 |
11.3 |
11.4 |
11.5 |
11.6 |
11.7 |
11.8 |
12.1 |
12.2 |
12.3 |
12.4 |
12.5 |
12.6 |
2.3 支持的开源框架/库
2.3.1 开源框架/库支持列表
开源框架/库 | 版本 | Status | Release |
Pytorch | 2.4 | ✅ | v1.4 Release |
Pytorch | 2.3 | ✅ | v1.3 Release |
Pytorch | 2.0、2.1、2.1.2、2.2 | ✅ | v1.2 Release |
Pytorch | 1.7、1.8、1.9、1.10、1.11、1.12、1.13 | ✅ | v1.0 Release |
Tensorflow | 2.16.1、2.17.0、2.6.3、2.7.0、2.8.0 | ✅ | v1.4 Release |
Tensorflow | 2.12、2.13.1、2.14.1 | ✅ | v1.2 Release |
Tensorflow | 1.15、2.4、2.6、2.7、2.8、2.10、2.11 | ✅ | v1.0 Release |
tensorrt | 0.1.0.8.0 | ✅ | v1.4 Release |
tensorrt_llm | 0.1.0.8.0 | ✅ | v1.4 Release |
tensorflow_gpu | 1.15.5 | ✅ | v1.4 Release |
PaddlePaddle | 2.3.2 | ✅ | v1.0 Release |
OneFlow | 0.7.0 | ✅ | v1.0 Release |
MXNet | 1.8.0 | ✅ | v1.0 Release |
TorchACC | 1.12 | ✅ | v1.0 Release |
HIE-ALLSPARK | 1.0.0 | ✅ | v1.0 Release |
BladeDISC | 0.21 | ✅ | v1.0 Release |
rtp-llm | 0.2.0 | ✅ | v1.4 Release |
trition-inference-server | 2.21.0 | ✅ | v1.0 Release |
Megatron-Core | 0.8.0 | ✅ | v1.4 Release |
Megatron-Core | 0.7.0 | ✅ | v1.3 Release |
Megatron-Core | 0.5.0 | ✅ | v1.2 Release |
DeepSpeed-Megatron | 0.2.0 (d65921c) | ✅ | v1.2 Release |
DeepSpeed | 0.15.2 | ✅ | v1.4 Release |
DeepSpeed | 0.14.4 | ✅ | v1.3 Release |
DeepSpeed | 0.10.0、0.12.3、0.13.1 | ✅ | v1.2 Release |
DeepSpeed | 0.8.0 | ✅ | v1.0 Release |
Horovod | 0.24.2 | ✅ | v1.0 Release |
VLLM | 0.5.2、0.6.x | ✅ | v1.4 Release |
VLLM | 0.4.2 | ✅ | v1.3 Release |
VLLM | 0.3.0、0.3.1、0.3.2、0.3.3 | ✅ | v1.2 Release |
VLLM | 0.2.6、0.2.7 | ✅ | v1.1.1 Release |
vllm(*) | 0.4.1、0.4.2、0.4.3、0.5.0、0.5.1、0.5.2、0.5.3 | ✅ | v1.4 Release |
lmdeploy | 0.5.3、0.6.3 | ✅ | v1.4 Release |
lmdeploy | 0.3.0、0.4.2 | ✅ | v1.3 Release |
lmdeploy(*) | 0.3.0、0.4.0、0.4.1、0.4.2、0.5.0、0.5.1、0.5.2、0.5.3 | ✅ | v1.4 Release |
ONNX Runtime | 1.19.2 | ✅ | v1.4 Release |
ONNX Runtime | 1.17.1、1.18.0 | ✅ | v1.3 Release |
ONNX Runtime | 1.15.1 | ✅ | v1.2 Release |
FasterTransformer | 5.3 | ✅ | v1.1 Release |
TransformerEngine | 1.11 | ✅ | v1.4 Release |
TransformerEngine | 1.4 | ✅ | v1.2 Release |
TransformerEngine | 1.5 | ✅ | v1.2.1 Release |
transformer_engine(*) | 1.7、1.8、1.9 | ✅ | v1.4 Release |
transformer_engine_torch(*) | 1.8、1.9 | ✅ | v1.4 Release |
pytorch3d(*) | 0.7.6、0.7.7 | ✅ | v1.4 Release |
triton | 2.0、2.1.1、2.2.0、3.0.0 | ✅ | v1.4 Release |
Nemo | 1.13.0 | ✅ | v1.2 Release |
TVM | 0.8.0 | ✅ | v1.0 Release |
hugectr | 3.1 | ✅ | v1.0 Release |
pytorch-quantization | 2.1.2 | ✅ | v1.0 Release |
DALI | 1.20.0 | ✅ | v1.0 Release |
cupy | 12.0 | ✅ | v1.2 Release |
pytorch3d | 0.7.6 | ✅ | v1.2.1 Release |
pytorch3d(*) | 0.7.6、0.7.7 | ✅ | v1.4 Release |
NVTabular | 0.7.1 | ✅ | v1.0 Release |
rmm | 23.2.0a0 | ✅ | v1.0 Release |
cudf | 23.2.0a0 | ✅ | v1.0 Release |
torch_xla | 2.2 | ✅ | v1.2 Release |
torch_xla | 2.3 | ✅ | v1.3 Release |
torch | 1.13.1、2.0.1、2.1.0、2.1.2、2.2.0、2.2.1、2.3.0、2.3.1、2.4.0 | ✅ | v1.4 Release |
torchao(*) | 0.2.0、0.3.0、0.4.0 | ✅ | v1.4 Release |
torchmetrics | 1.0.1 | ✅ | v1.0 Release |
torchmetrics(*) | 1.4.0 | ✅ | v1.4 Release |
torchrl(*) | 0.5.0 | ✅ | v1.4 Release |
torchaudio | 2.2.1 | ✅ | v1.3 Release |
torchaudio(*) | 2.0.2、2.1.0、2.1.2、2.2.0、2.2.1、2.3.0、2.3.1、2.4.0 | ✅ | v1.4 Release |
torchvison torchvison | 0.17.1 | ✅ | v1.3 Release |
0.13.0 | ✅ | v1.0 Release | |
torchvision(*) | 0.15.2、0.16.0、0.16.2、0.17.0、0.17.1、0.18.0、0.18.1、0.19.0 | ✅ | v1.4 Release |
torchdata | 0.6.1 | ✅ | v1.3 Release |
torchdata(*) | 0.6.1、0.7.0、0.7.1、0.8.0 | ✅ | v1.4 Release |
torchtext | 0.17.1 | ✅ | v1.3 Release |
torchtext(*) | 0.15.2、0.16.0、0.16.2、0.17.0、0.17.1、0.18.0 | ✅ | v1.4 Release |
mmcv | 1.5 | ✅ | v1.0 Release |
mmcv(*) | 2.2.0 | ✅ | v1.4 Release |
ray | 2.6.1、2.8.0 | ✅ | v1.2 Release |
xformers(*) | 0.0.21、0.0.22、0.0.23、0.0.24、0.0.25、0.0.26、0.0.27、 | ✅ | v1.4 Release |
xformers | 0.0.21、0.0.22、0.0.25、0.0.27 | ✅ | v1.4 Release |
cutlass | 2.4、3.3 | ✅ | v1.2 Release |
cutlass(*) | 3.4.1、3.5 | ✅ | v1.4 Release |
FlashAttention | 1.0.5、2.0.9、2.4.2、2.5.6、2.5.7 | ✅ | v1.4 Release |
FlashAttention(*) | 2.4.2、2.4.3、2.5.0、2.5.1、2.5.2、2.5.3、2.5.4、2.5.5、2.5.6、2.5.7、2.5.8、2.5.9、2.6.0、2.6.1、2.6.2、2.6.3 | ✅ | v1.4 Release |
vllm-flashattention | 2.6.2 | ✅ | v1.4 Release |
flashinfer | 0.1.6 | ✅ | v1.4 Release |
flashinfer(*) | 0.1.0、0.1.1、0.1.2 | ✅ | v1.4 Release |
text embedding inference | 1.5.0 | ✅ | v1.4 Release |
Apex | 23.08 | ✅ | v1.2 Release |
Apex | 24.04.01 | ✅ | v1.3 Release |
Apex(*) | 24.04 | ✅ | v1.4 Release |
auto_gptq(*) | 0.7.1 | ✅ | v1.4 Release |
peft | 0.3.0 | ✅ | v1.0 Release |
bitsandbytes | 0.43 | ✅ | v1.2 Release |
bitsandbytes | 0.43.1 | ✅ | v1.3 Release |
bitsandbytes(*) | 0.40.0、0.41.0、0.42.0、0.43.0、0.43.1 | ✅ | v1.4 Release |
byte_flux(*) | 1.0.2、1.0.3 | ✅ | v1.4 Release |
cupy(*) | 13.1.0 | ✅ | v1.4 Release |
faiss(*) | 1.7.3、1.7.4、1.8.0 | ✅ | v1.4 Release |
grouped_gemm(*) | 1.1.4 | ✅ | v1.4 Release |
mamba_ssm(*) | 2.1.0、2.2.0、2.2.1、2.2.2 | ✅ | v1.4 Release |
nvidia_dali_cuda110(*) | 1.20.0 | ✅ | v1.4 Release |
nvidia_dali_cuda120(*) | 1.20.0 | ✅ | v1.4 Release |
onnxruntime_gpu(*) | 1.15.1、1.16.3、1.17.1、1.17.3、1.18.0、1.18.1、1.19.0 | ✅ | v1.4 Release |
fbgemm | 0.7.0 | ✅ | v1.4 Release |
onnxruntime_training | 1.15.1、1.17.1、1.18.0、1.19.0、1.19.2 | ✅ | v1.4 Release |
transformers(*) | 4.30.2、4.31.0、4.32.1、4.33.2、4.34.1、4.35.2、4.36.2、4.37.2、4.38.1、4.38.2、4.39.3、4.40.2、4.41.2、4.42.4、4.43.0、4.43.3 | ✅ | v1.4 Release |
说明:
Pytorch开源支持说明:
Pytorch 2.1及其之前的版本对标NGC
Pytorch 2.1.2及其之后的版本对标torch开源社区RELEASE版本
TensorFlow开源支持说明:
Tensorflow Google社区开源版本1.12仅支持CUDA 9、1.15仅支持CUDA 10 https://www.tensorflow.org/install/source?hl=zh-cn#gpu_support_3
发布Tensorflow 1.15采用NV官方NGC nv22.04的开源版本 https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html#unique_1997996242
Tensorflow 1.12采用PAI TF 1.12
Tensorflow 2.4NGC NV 21.02
Tensorflow 2.6 2.7 Google官方开源社区RELEASE版本
Tensorflow 2.8 NGC NV 22.04
Tensorflow 2.10及以上使用Google官方开源社区RELEASE版本
带(*)标志的,如FlashAttention(*) 与cutlass(*)等,完全对标社区开源版本,未做性能优化,仅功能支持。
其它开源框架/开源库 除个别对标NGC以外,大部分对标开源社区RELEASE版本,详情请参考各个使用指南。
对于开源框架/开源库,PPU SDK兼容编译、基本功能运行和UT测试,由于资源限制V1.4 RELEASE并没有解决所有测试中发现的问题,遗留问题请参考【已知问题】章节。
2.3.2 开源框架兼容性
框架 | 版本 | 测试类型 | 通过率 |
Pytorch | 1.7 | Unit Test | 98.5% |
Pytorch | 1.8 | Unit Test | 97.6% |
Pytorch | 1.9 | Unit Test | 93.5% |
Pytorch | 1.10 | Unit Test | 94.7% |
Pytorch | 1.11 | Unit Test | 92.9% |
Pytorch | 1.12 | Unit Test | 95.2% |
Pytorch | 2.1 | Unit Test | 95.7% |
Pytorch | 2.3 | Unit Test | 96.9% |
Pytorch | 2.4 | Unit Test | 97.6% |
Tensorflow | 1.15 | Unit Test | 97.6% |
Tensorflow | 2.7 | Unit Test | 89% |
Tensorflow | 2.8 | Unit Test | 91.3% |
Tensorflow | 2.12 | Unit Test | 81.3% |
Tensorflow | 2.14 | Unit Test | 83.6% |
Tenorflow | 2.16 | Unit Test | 83.8% |
Megatron-Core | 0.8.0 | Unit Test | 99.7% |
Megatron-Core | 0.7.0 | Unit Test | 97.5% |
DeepSpeed | 0.15.2 | Unit Test | 93.1% |
DeepSpeed | 0.14.4 | Unit Test | 89% |
Horovod | 0.24.2 | E2E example | 100% |
VLLM | 0.4.1 | Unit Test | 99% |
VLLM | 0.4.2 | Unit Test | 99% |
VLLM | 0.4.3 | Unit Test | 99.98% |
VLLM | 0.5.0 | Unit Test | 100% |
VLLM | 0.5.1 | Unit Test | 99.9% |
VLLM | 0.5.2 | Unit Test | 99.9% |
VLLM | 0.5.3 | Unit Test | 100% |
VLLM | 0.6.0 | Unit Test | 99.3% |
lmdeploy | 0.3.0 | E2E example | 100% |
lmdeploy | 0.4.0 | Unit Test | 99% |
lmdeploy | 0.4.1 | Unit Test | 98.5% |
lmdeploy | 0.4.2 | Unit Test | 97.7% |
lmdeploy | 0.5.0 | Unit Test | 99% |
lmdeploy | 0.5.1 | Unit Test | 100% |
lmdeploy | 0.5.2 | Unit Test | 97.9% |
lmdeploy | 0.5.3 | Unit Test | 98.5% |
ONNX Runtime | 1.19.2 | Unit Test | 94.9% |
ONNX Runtime | 1.18.0 | Unit Test | 90.0% |
TransformerEngine | 1.11 | Unit Test | 98.69% |
TransformerEngine | 1.5 | Unit Test | 93.7% |
TransformerEngine | 1.7 | Unit Test | 94.3% |
TransformerEngine | 1.8 | Unit Test | 95.2% |
TransformerEngine | 1.9 | Unit Test | 96.1% |
rtp-llm | 0.2.0 | Unit Test | 100% |
torch xla | 2.3 | E2E example | 100% |
xformers | 0.0.27 | Unit Test | 99.9% |
xformers | 0.0.26 | Unit Test | 99.9% |
xformers | 0.0.26 | Unit Test | 99.9% |
xformers | 0.0.25 | Unit Test | 99.9% |
xformers | 0.0.24 | Unit Test | 99.9% |
xformers | 0.0.23 | Unit Test | 99.9% |
xformers | 0.0.22 | Unit Test | 99.8% |
xformers | 0.0.21 | Unit Test | 98% |
vllm-flashattention | 2.4.2 | Unit Test | 99% |
vllm-flashattention | 2.4.3 | Unit Test | 99% |
vllm-flashattention | 2.5.0 | Unit Test | 100% |
vllm-flashattention | 2.5.1 | Unit Test | 100% |
vllm-flashattention | 2.5.2 | Unit Test | 100% |
vllm-flashattention | 2.5.3 | Unit Test | 100% |
vllm-flashattention | 2.5.4 | Unit Test | 100% |
vllm-flashattention | 2.5.5 | Unit Test | 99.9% |
vllm-flashattention | 2.5.6 | Unit Test | 99.9% |
vllm-flashattention | 2.5.7 | Unit Test | 100% |
vllm-flashattention | 2.5.8 | Unit Test | 100% |
vllm-flashattention | 2.5.9 | Unit Test | 100% |
vllm-flashattention | 2.6.0 | Unit Test | 100% |
vllm-flashattention | 2.6.1 | Unit Test | 100% |
vllm-flashattention | 2.6.2 | Unit Test | 100% |
vllm-flashattention | 2.6.3 | Unit Test | 100% |
flashinfer | 0.1.0 | Unit Test | 97.9% |
flashinfer | 0.1.1 | Unit Test | 99% |
flashinfer | 0.1.2 | Unit Test | 99.9% |
flashinfer | 0.1.6 | Unit Test | 99.9% |
text embedding inference | 1.5.0 | Unit Test | 99% |
Apex | 24.04.01 | Unit Test | 91% |
auto_gptq | 0.7.1 | Unit Test | 94.3% |
bitsandbytes | 0.40.0 | Unit Test | 99.9% |
bitsandbytes | 0.41.0 | Unit Test | 99.9% |
bitsandbytes | 0.42.0 | Unit Test | 100% |
bitsandbytes | 0.43.0 | Unit Test | 100% |
bitsandbytes | 0.43.1 | Unit Test | 100% |
byte-flux | 1.0.2 | Unit Test | 92.1% |
byte-flux | 1.0.3 | Unit Test | 95.1% |
cupy | 13.1.0 | Unit Test | 95% |
faiss | 1.7.3 | Unit Test | 100% |
faiss | 1.7.4 | Unit Test | 100% |
faiss | 1.8.0 | Unit Test | 100% |
grouped_gemm | 1.1.4 | Unit Test | 92.5% |
mamba_ssm | 2.1.0 | Unit Test | 94.5% |
mamba_ssm | 2.2.0 | Unit Test | 93.9% |
mamba_ssm | 2.2.1 | Unit Test | 99% |
mamba_ssm | 2.2.2 | Unit Test | 100% |
mmcv | 2.2.0 | Unit Test | 99.9% |
nvidia_dali_cuda110 | 1.20.0 | Unit Test | 94.7% |
nvidia_dali_cuda120 | 1.20.0 | Unit Test | 94.7% |
onnxruntime_gpu | 1.15.1 | Unit Test | 92.1% |
onnxruntime_gpu | 1.16.3 | Unit Test | 97.4% |
onnxruntime_gpu | 1.17.1 | Unit Test | 91% |
onnxruntime_gpu | 1.17.3 | Unit Test | 93% |
onnxruntime_gpu | 1.18.0 | Unit Test | 92.4% |
onnxruntime_gpu | 1.18.1 | Unit Test | 95.7% |
onnxruntime_gpu | 1.19.0 | Unit Test | 96% |
pytorch3d | 0.7.6 | Unit Test | 91.2% |
pytorch3d | 07.7 | Unit Test | 93% |
torchao | 0.2.0 | Unit Test | 99.9% |
torchao | 0.3.0 | Unit Test | 99.9% |
torchao | 0.4.0 | Unit Test | 99.9% |
torchaudio | 2.0.2 | Unit Test | 91.2% |
torchaudio | 2.1.0 | Unit Test | 91.8% |
torchaudio | 2.1.2 | Unit Test | 92.7% |
torchaudio | 2.2.0 | Unit Test | 93% |
torchaudio | 2.2.1 | Unit Test | 99.9% |
torchaudio | 2.3.0 | Unit Test | 99.9% |
torchaudio | 2.3.1 | Unit Test | 99.9% |
torchaudio | 2.4.0 | Unit Test | 99.9% |
torchaudio | 2.0.2 | Unit Test | 99.9% |
torchdata | 0.6.1 | Unit Test | 100% |
torchdata | 0.7.0 | Unit Test | 100% |
torchdata | 0.7.1 | Unit Test | 100% |
torchdata | 0.8.0 | Unit Test | 100% |
torchmetrics | 1.4.0 | Unit Test | 95% |
torchrl | 0.5.0 | Unit Test | 93.9% |
torchtext | 0.15.2 | Unit Test | 96.9% |
torchtext | 0.16.0 | Unit Test | 97% |
torchtext | 0.16.2 | Unit Test | 97% |
torchtext | 0.17.0 | Unit Test | 96.8% |
torchtext | 0.17.1 | Unit Test | 98% |
torchtext | 0.18.0 | Unit Test | 98% |
torchvision | 0.15.2 | Unit Test | 99.9% |
torchvision | 0.16.0 | Unit Test | 99.9% |
torchvision | 0.16.2 | Unit Test | 97% |
torchvision | 0.17.0 | Unit Test | 100% |
torchvision | 0.17.1 | Unit Test | 100% |
torchvision | 0.18.0 | Unit Test | 98.9% |
torchvision | 0.18.1 | Unit Test | 99.9% |
torchvision | 0.19.0 | Unit Test | 99.9% |
transformer_engine_torch | 1.8 | Unit Test | 92.7% |
transformer_engine_torch | 1.9 | Unit Test | 93.4% |
transformers | 4.30.2 | Unit Test | 94% |
transformers | 4.31.0 | Unit Test | 92.1% |
transformers | 4.32.1 | Unit Test | 93.4% |
transformers | 4.33.2 | Unit Test | 93% |
transformers | 4.34.1 | Unit Test | 93% |
transformers | 4.35.2 | Unit Test | 92.7% |
transformers | 4.36.2 | Unit Test | 92.6% |
transformers | 4.37.2 | Unit Test | 94% |
transformers | 4.38.1 | Unit Test | 94% |
transformers | 4.38.2 | Unit Test | 94% |
transformers | 4.39.3 | Unit Test | 94% |
transformers | 4.40.2 | Unit Test | 95.2% |
transformers | 4.41.2 | Unit Test | 94.9% |
transformers | 4.42.4 | Unit Test | 96% |
transformers | 4.43.0 | Unit Test | 96.7% |
transformers | 4.43.3 | Unit Test | 98% |
3. 已知问题
3.1 驱动
不支持的CUDA API列表可参考CUDA兼容性。
SRIOV虚拟化single VF模式下多进程运行video应用时有概率发生掉卡问题,预计下个版本修复;
不支持ICN互联 + SRIOV虚拟化 + 热迁移功能同时使用;
3.2 编译器
不支持Texture和Surface相关的Cuda C++扩展 API、Inline PTX指令的功能,编译会报错;
不支持Dynamic Parallelism相关的Cuda C++扩展 API、Inline PTX指令的功能,编译会报错;
针对ptx 7.6之上的新增指令,会存在因硬件架构不支持的部分功能,不影响编译,但运行时会报错;
不支持Inline PTX中ld/st相关指令带有
{.level::eviction_priority}和{.level::prefetch_size}的特性,忽略其定义但不影响编译和运行的过程;不支持Inline PTX中cache eviction policy相关的指令和操作数,编译会报错;
Device文件编译流程包括Cuda Device C++代码 -> llvm(hgvm) IR -> Device Binary的过程, 但不包含输出ptx格式的文件过程; 针对其他平台的代码编译(或Codegen)环节,如带有ptx格式的编译环节,需要进行代码适配;
兼容CUDA mma及相关数据搬运的ptx指令中大部分,范围包括特定数据类型(.u8/.s8/.tf32/.bf16/.f16)下的dense mma指令,相比于使用ppu specific tensor core ptx指令实现,性能会存在损失。如果此类kernel的性能在整个端到端中占比重要,则建议对该kernel代码实现进行算法的重构(参考ppu tensor core ptx用户编程手册及算法重构指南);
3.3 加速库
性能:性能泛化能力有待加强。
acblas:
仅支持列表API,详见CUDA cuBLAS支持情况,更多API持续按需支持中。
不支持复数数据类型。
Gemm: 默认打开FP32 Tensor Core,由于计算顺序等原因导致精度不能和FP32 FMA完全配置,matrixMulCUBLAS实例会因此失败;
Gemv:仅支持host指针模式;
BlasLt:不支持algo/perf等指定属性;
acdnn:
仅支持列表API,详见CUDA cuDNN支持情况,更多API持续按需支持中。
Conv:不支持INT64/BOOLEAN数据类型,不支持输入FP16 + 输出FP32。
3DConv:有限调优,性能待加强。
depthwise:某些dgrad用例性能待加强。
BN:1)仅支持alpha==1和beta==0参数;2)不支持ACDNN_BATCHNORM_PER_ACTIVATION模式。
Pooling:不支持ACDNN_PROPAGATE_NAN。
RNN:仅支持acdnnRNNBiasMode_t DOUBLE;仅支持FP16/F32数据类型;仅支持ACDNN_RNN_ALGO_STANDARD;
Activation:不支持ACDNN_PROPAGATE_NAN;不支持SWISH Op。
Softmax:不支持SoftmaxAlgorithm_t FAST。
TensorOp:acdnnReduceTensor不支持MUL_NO_ZEROS。
MultiHeadAttn:仅支持前向op。
Backend:1)不支持前处理融合;2)仅支持最多4个pointwise后处理融合;3)仅支持fp16/fp32/bf16数据类型;4)融合的pointwise操作仅支持alpha1 = 1和alpha2 = 1。
3.4 互联库
Collective操作性能:16 x 真武810E服务器采用TP 2/4/8 mode时建议aware自己所用机器的icn topo配置情况以来选择最佳的devices placement;
仅支持 nccl netplugin v4 的版本;
尚不支持多机 cudaGraph;
尚不支持同个 comm 上使用不同的 params streams;
多个pccl communicators同时工作在相同PPU下面时,会有概率性死锁的问题, 需尽量规避多个pccl kernels同时launch在同一ppu device下的行为; 避免设置
NCCL_MIN_NCHANNELS为大于16的值可帮助规避此问题;
3.5 推理引擎
数据类型有限支持int8;
支持部分onnx模型;
Python binding仅支持部分API,参看使用指南;
对于dynamic shape提供部分支持,当前主要通过桶的方式支持传统模型产品化能力;
3.6 Video Codec/Image硬件加速
Video decode不支持raw nvdec模式;
Video decode不支持MPEG1,MPEG2,MPEG4,VC1,VP8等legacy格式;
JPEG不支持lossless,不支持JPEG2000;
NPP目前只支持Image Process接口,不支持Signal Process接口;
3.7 工具
PPU-SMI已知问题请参考PPU-SMI已知问题;
Asight Systems已知问题请参考Asight Systems已知问题;
Asight Compute已知问题请参考Asight Compute已知问题;
3.8 框架与模型
开源框架已知问题说明
框架 | 版本 | 已知问题 |
Pytorch | 2.4 |
|
Tensorflow | 2.16 |
|
Megatron-Core | 0.8.0 |
|
DeepSpeed | 0.15.2 |
|
VLLM | 0.6.3 |
|
lmdeploy | 0.5.3 |
|
ONNX Runtime | 1.19.2 |
|
TransformerEngine | 1.11 |
|
xformers | 0.0.27 |
|
vllm-flashattention | 2.6.2 |
|
flashinfer | 0.1.6 |
|
text embedding inference | 1.5.0 |
|