
SDK Release Note
PPU SDK v1.5.3 release note
1. Main Features and Bug Fix Lists
详细功能:
支持 VLLM-V0.9.1;
支持 SGLang-V0.4.7;
支持 flashinfer 0.2.6.post1;
性能优化:
sailSHMEM:2 机 2 卡 ibgda path 在 put 与 atomic latency 场景有约 15% 提升;
重要 Bug Fix:
[acext]:修复了w8a8-int8 gemm接口传入bias导致的精度问题;
[acext]:fix int8_gemm python API crash when CUDA Graph Capture;
[acompute]:fix batchnorm2d return nan error;
[torch profiler]:修复了pytorch 2.6环境下torch profiler性能数据异常的问题;
[DeepEP]:修复了 internode kernel mode 0 上的多机 random hang 问题;
2. Known Issues
SGLang-V0.4.7 使用 generate 接口时候会出现推理回答不正确的问题,客户可以使用 openai 兼容接口来使用;
vLLM-V0.9.1 预估的可用 kv cache 空间相比 V0.8.5 少,导致受 kv cache 约束的场景并发数会因此下降,对性能产生影响(例如 DeepSeek-R1-bf16 真武810E 单机运行);
建议真武810E上跑A8W8量化模型以避免该性能下降;
SGLang-V0.4.7在运行DeepSeek-R1 \ DeepSeek-V3 A8W8-INT8模型时,默认会使用shared expert,SGLang-V0.4.6.post1则不会,这会导致SGLang-V0.4.7运行该模型时性能不如SGLang-V0.4.6.post1。SGLang-V0.4.7可通过
--disable-shared-experts-fusion禁用shared expert,此时SGLang-V0.4.7运行该模型时性能与SGLang-V0.4.6.post1相当;SGLang-V0.4.7在
--mem-fraction-static设置的较大导致单机显存容量不足时,会出现decode out of memory的问题,例如真武810E单机运行DeepSeek-R1。这是社区已知问题;
PPU SDK v1.5.2 release note
1. Main Features and Bug Fix Lists
详细功能:
发布 PPU SGLang 0.4.6 支持 Qwen3-235B-A22B、Deepseek V3/R1 A8W8(int8)推理;
DeepGemm:
支持 BF16/INT8 contiguous/masked 接口;
INT8 接口支持 channel-wise 量化(尚不支持 block-wise 量化)
内置基本的性能调优规则,支持python jit调优功能;
cutlass3 新增 a8w8 block-wise 量化功能支持示例代码;
互联通信库:
sailSHMEM:
真武810E 16卡平台下的自动最佳网卡识别,减少环境变量指定;
IBRC path 支持多 QPs 设置并新增 per QP 做数据传输与同步的 API;
优化单机 pt2pt perf 性能,其中 get_bw 约有 3 倍多提升;
优化代码结构以减少对 CUDA 头文件的版本依赖;
DeepEP:
去除对 affinity 网卡的 hardcode 指定;
优化 internode kernel (IBRC path) 下的性能, 2/4/8 机下性能与 mode 0 (IBGDA) 接近;
优化 ll kernel 单机时的性能,16 卡 真武810E 下约有 3 倍多提升;
16 卡 真武810E 平台的 generic 支持;
软件生态:
支持 xformers 0.0.30
支持 TransformerEngine 2.3
支持 NeMo v2.1.0
问题修复:
Fix v1.5.1 版本上 Megatron-LM 训练保存 torch_dist 格式权重会出现 hang 的问题;
Fix v1.5.1 版本上开启prefix-cache后模型推理出现乱回复的 bug;
Fix 非 PPU 环境编译 vllm 时出现 "Failed to create /dev/alixpu node" 错误日志的问题;
2. Known Issues
DeepEP:
internode kernel combine 性能尚不及 dispatch 性能,仍在优化中;
ll kernel 已支持 icn link 功能使用,但需在 buffer init 时显示设置 allow_nvlink_for_low_latency_mode 为 True;
多机 DeepEP internode kernel 走 mode 0 即 ibgda path 时,当 tokens 数超过 16K 时会有 random hang 问题,尚未定位;
同个 DeepEP buffer 同时处理 ll 与 internode 两种类型 workloads, 即 PD 不分离的场景未做过充分测试,建议仅用于 PD 分离的模型场景。
PPU SDK v1.5.1 release note
1. Main Features and Bug Fix Lists
DeepEP、sailSHMEM目前在PAI和ACS的容器镜像中尚不可用,仅SDK支持,预计在下一个镜像版本中更新并支持。
功能:
发布PPU版本DeepEP;
说明需搭配最新发布的v1.5.1 KMD驱动一起使用,在旧的KMD驱动版本上使用DeepEP存在已知的随机崩溃问题;
发布PPU版本sailSHMEM;
发布PPU版本DeepGemm(目前只支持 BF16);
说明当前对标DeepGemm APIs的功能实现在acext加速库中;
计算库:迭代发布libacext.so支持FusedMOE,该版本也开始支持Gemm、FusedMOE A8W8(int8) 计算,可以进一步提升LLM模型int8量化推理性能;
互联库PCCL:
优化多机小sizes下alltoall性能,多机真武810E + 商卡配置下32KB ~ 8MB区间平均性能比上个版本提升约60%+;
改进pccl hang monitor功能,控制对本地硬盘空间的使用;
软件生态:
VLLM:
发布PPU-VLLM v0.8.3
发布PPU-VLLM v0.8.5
说明PPU基于PPU-VLLM v0.8.3支持了Deepseek-V3/R1 W8A8、 同时也支持了Qwen3,欢迎用户使用。
PPU-VLLM通过新增acext MOE Backend提升了Deepseek-V3/R1、Qwen3的推理性能;
SGlang:
发布PPU-SGLang v0.4.4.post3
发布PPU-SGLang v0.4.6
说明PPU-SGLang通过新增acext MOE Backend提升了Deepseek-V3/R1、Qwen3的推理性能;
更新PPU MODEL ZOO v1.5.1
TransformerEngine:v2.1
DeepSpeed:v0.16.5
Megatron-Core:v0.11.0
新的算法模型:
Qwen2.5-Omni
LLama4
Qwen3 Dense、MOE系列(VLLM v0.8.5、SGLang v0.4.6均可运行)
说明VLLM v0.8.5、SGLang v0.4.6因最近刚发布,PPU上测试尚不充分。
Bug Fix:
PCCL:修复pccl ext-kernel plugin所含的oneShot与twoShot算法在部分场景因symbol查找错误无法使用的issue;
HGGC:修复tensorflow 2.15.1 + tfra 0.8.1跑demo出现illegal memory access的问题;
2. Known Issues
Qwen3-235B-A22B性能将在下一个迭代版本中进一步优化;
SGLang框架目前尚不支持A8W8-int8量化模型推理,因此在Qwen3.0上目前尚未有A8W8-int8量化模型推理性能数据,平头哥研发团队尚在开发中,预计很快将会支持;
VLLM v0.8.5、SGLang v0.4.6因最近刚发布,PPU上测试尚不充分;
如果不是通过发布的sglang v0.4.6.post1的docker,而是通过源码编译来使用sglang v0.4.6.post1,使用时请确保当前环境中
/usr/local/PPU_SDK/lib/th_op/路径下存在libth_op.so文件(sglang 0.4.6.post1接入了ppu deepep和ppu deepgemm)。如果不存在,可以从源码编译安装acext(参考: acext使用指南),编译完成后将<path-to-acext>/build/thop/libth_op.so文件拷贝到/usr/local/PPU_SDK/lib/th_op/路径下;其他Known issues参照V1.5版本描述;
PPU SDK v1.5 release note
1. 版本概述
1.1 软件栈介绍
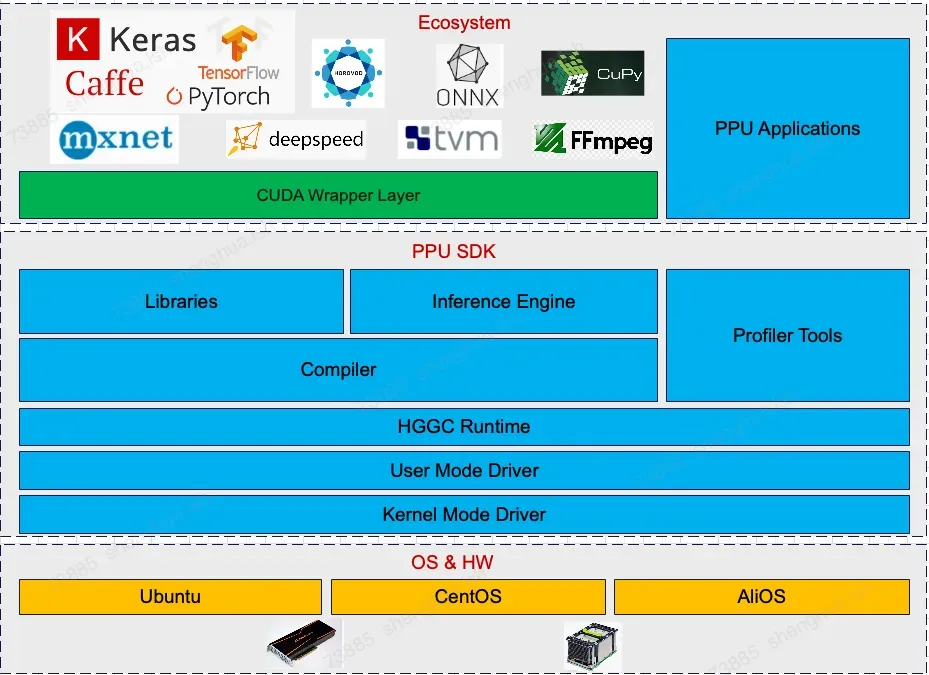
为 CUDA 应用开发者使用PPU软硬件降本增效。
三个层次交付物:兼容CUDA 生态的框架软件包与模型、CUDA SDK兼容软件包、T-Head SAIL SDK软件包。
1.2 核心组件
组件名称 | 概要说明 |
Firmware | PPU 固件 |
KMD | PPU 内核驱动 |
UMD / HGGC | PPU 用户态驱动和运行时 |
Compiler | PPU 编译器工具链 |
Acompute | PPU 计算加速库 |
Acext | PPU 量化加速库 |
PCCL | PPU 通信加速库 |
PPU SMI | PPU 设备管理工具 |
PPU DCGM | PPU 在线监控工具 |
Asight System | PPU 性能分析工具 |
Asight Compute | PPU 性能分析工具 |
PPU GDB | PPU 调试工具 |
PPU MemCheck | PPU Sanitizer工具 |
PPU hgobjdump | PPU Device Binary工具 |
CUDA SDK Wrapper | CUDA API 兼容库 |
1.3 主要功能
1.3.1 Firmware
支持二进制包安装(rpm或deb);
支持动态电源管理功能,缺省模式下PPU固件会根据实时的工作负载、温度和功耗等信息动态调节核心频率(200MHZ~最大工作频率)和工作电压;
支持PPU锁频功能,详情请参见设备管理工具PPU-SMI;
支持固件安全签名和固件双备份功能,确保固件内容的安全性和可靠性;
支持电源芯片固件升级功能;
支持BMC带外管理功能,包括设备状态监控和固件带外升级等;
1.3.2 内核驱动
支持二进制包安装(rpm或deb)和runfile包安装两种方式,用户可根据需要自由选择;
支持内核驱动和PPU SDK解耦,v1.0版本之后的内核驱动和PPU SDK可任意组合使用;
支持单机单卡、单机8卡/16卡(ICN互联)、多机多卡(ICN互联)和多机多卡(GDR)多种灵活的机器形态,使用GDR功能之前需确保系统已安装
alixpu-peermem内核模块(随PPU内核驱动一起发布);支持PPU故障上报和故障处理;
支持
auto-reset功能,驱动在检测到kill overtime或cp invalid cmd错误之后会自动进行PPU设备复位,无需用户手动复位即可恢复正常。该功能默认打开,用户可通过ppu-smi查询状态或关闭该功能;支持MPS(Multi Pipe Service)功能,用户可通过
ppudbg --config_submit_mode 1/0打开或关闭该功能;支持MPS模式下小模型和大模型任务的潮汐场景使用;
支持nvml GPM指标采集功能,包括:sm利用率、sm occupancy、tensor core利用率、显存带宽利用率、pcie读写速率、icn link读写速率;
支持MIG(Multi Instance GPU)多实例功能,PPU最多支持8个实例,需注意使用MIG功能时ICN互联功能不可使用;
支持整卡直通虚拟化功能,用户可以在宿主机上解绑PPU驱动直通进虚拟机内使用,此时需要注意不同VM之间的ICN隔离;
支持SRIOV虚拟化模式下宿主机驱动的热升级功能,即可以在虚拟机内业务运行的同时对宿主机PPU驱动进行更新;
支持SRIOV虚拟化模式下虚拟机任务的热迁移功能 (仅限单卡,ICN互联热迁移暂不支持);
新增单机16卡真武810E的正式支持并优化默认的PPU设备顺序(按照机尾排序);
新增L1/L2 cache命中率GPM指标采集,用户可通过DCGM工具查询获取;
调整16卡真武810E设备的逻辑编号规则以获取更好的互联性能;
新增MPS潮汐模式状态查询功能;
新增Xid错误信息查询功能;
新增GPM状态查询和GPM状态启停功能;
取消HBM parity Xid错误上报;
1.3.3 用户态驱动和运行时
兼容绝大多数cuda runtime api (cudaXXX) 和cuda driver api (cuXXX);
新增发生xid 896错误时输出更多错误日志方便定位问题;
优化2D/3D类型的cudaMemcpy/cudaMemset性能;
支持stream memory opertaion v2版本API;
支持graph management中edge data相关API;
支持graph management中batch memory op node相关API;
支持texture基本功能;
优化CUDA_DEVICE_MAX_CONNECTIONS=1时PPU性能;
支持cuCtxCreate_v3 api;
支持在发生异常之后正确输出device code printf的内容;
支持
HGGC_EXCLUSIVE_STREAMS环境变量指定stream group映射到不同的硬件队列;修复cuda graph不支持cooperative kernel node的问题;
1.3.4 编译器
基于clang/llvm的编译框架,实现面向PPU架构的、host/device混合编程风格的C/C++扩展语言编译器,完整兼容cuda c/c++的编程语言规范;
提供丰富的编译功能模块,方便开发者通过API的调用方式,灵活构建编译流程,方便集成JIT编译的能力;
丰富的开发和 debug 工具:hgobjdump、memcheck、ppu-gdb、sanitizer library、hgprune,可以让用户更加方便地开发;
支持system level reserved shared memory特性;
gcc host compiler的版本支持范围在[5.5 - 14.2],clang host compiler的支持范围在[clang 9 - clang 18];
支持triton 2.3.x、3.0.x、3.1.x、3.2.x;
部分兼容sparse mma ptx指令;
支持部分Texture相关API、Inline PTX 指令功能;
1.3.5 加速库
计算加速库
闭源计算库支持:acdnn、acblas、acfft、acsolver、acrand
acdnn支持算子
Conv
BatchNorm
Pooling
Softmax
Activation
CTCLoss
Dropout
LRN
LSTM
GRU
MultiHeadAttn
Tensor Ops
SpartialTransform
Backend fusion
acblas支持算子
Level1 系列 Op
Gemv
Gemm
Matmul + epilogue
MatrixTransform
trsm
getrfBatched
getrsBatched
geqrfBatched
gelsBatched
acfft支持:R2C/C2R/C2C/D2Z/Z2Z + FFT/iFFT 变换;
acsolver支持:矩阵LU分解/求解,cholesky分解/求解,QR分解,SVD分解,特征值分解;
acrand支持:
伪随机生成器XORWOW、MRG32K3A、PHILOX4_32_10;
数据分布:Default/Uniform/Normal/LogNormal;
acext量化库支持:
支持A16W8/A16W4以及PerChannel/GroupWise的各种Kernel变种;
支持A8W8以及PerChanel/PerToken的各种Kernel变种;
支持WeightonlyBatchedGemv对小batchsize的加速kernel;
支持以下类型 MoE:FP16/BF16,a8w8 PerChanel/PerToken;
关键更新:
acext:DeepSeek MoE 支持调优;
新增离线 RTC cache 机制支持,可以部分解决 rtc 编译造成的性能问题;
blasLt:matmul 新增 Atomics Synchronization 功能支持;
blas:更多大模型推理场景性能调优,算子最高提升 20%;
conv:新增 activation/weight 不同 format 组合支持;
conv:新增 Tensor/Vector Core 算法启发式选择逻辑;
conv:优化 group conv 性能,算子最高提升 33x;
conv:解决 Tensor > 4GB 时非 tensorflow 场景性能慢问题,最大提升;算子最高提升 230x;
solver:新增特征值分解接口支持:syevd, sytrd, ormtr, orgtr;
互联加速库
兼容支持绝大多数nccl api (ncclXXX) 和环境变量;
支持AllReduce、AllGather、ReduceScatter、Broadcast、Reduce、Send、Recv等典型互联算子;
支持单机内多卡通过ICN、PCIE、ShareMemory通信;
兼容支持绝大多数nccl api (ncclXXX) 和环境变量;
支持AllReduce、AllGather、ReduceScatter、Broadcast、Reduce、Send、Recv等典型互联算子;
支持单机内多卡通过ICN、PCIE、ShareMemory通信;
支持多机之间通过RDMA (GDR & non GDR) 、Socket、ICN通信;
性能优化:
优化了多机真武810E环境下alltoall的性能, 相比之前版本最佳throughput可提升20% ~ 60%,目前需配置参考环境变量才能达到性能优化效果;
优化了在输入或输出buffer非64B对齐时的算子性能, allgather在相应场景下可有约40%提升;
解决了模型中通信算子性能与单测算子benchmark性能不一致的部分问题,关键算子像allreduce等在部分场景可有约20%提升;
强oneShot与twoShot kernels对不同直连topo的感知及相应topo下的性能参数优化;
多机多卡debug功能增强:
增强了ppu device kernel执行状态监测功能;
消除了监测方案对kernel执行时间的额外消耗;
增加对kernel执行状态dump旧文件的自动清理功能;
增加pccl dump目录可配置的功能;
优化监控线程的出错信息显示以减少对主任务的干扰;
增加单机oneShot与twoShot kernel状态dump功能支持;
增加对真武810E多卡产品的icn speed及topo正确性检查功能支持;
增加对EIC网卡环境下的多机功能支持,可配合高网团队EIC SDK使用;
增加comm split场景下的splitShare功能支持;
增加p2p transport下使用DMA engine做多卡间传输的初步功能支持;
增加对ncclNet plugin v5与v6版本的支持;
增加对新的log subsys level 'NCCL_CALL' 的支持,可显示打印程序所调用的pccl API及参数;
增强pccl kernel的hgtx info内容以包含所在comm的transport type信息与kernel输入、输出buff信息;
修复多机多卡icn scaleout功能在多机非icn连接情况下的一些问题;
修复alltoallV在部分使用场景下会hang的问题;
修复
NCCL_MAX_P2P_NCHANNELS设置值比NCCL_MAX_NCHANNELS小时会造成结果错误的问题;修复debug log打印时所存在的内部buff潜在溢出问题;
pccl tools:
DeviceOrderSearch tool:
新增 'DeviceOrderSearch' 工具支持,用于Megatron框架模型训练任务上基于并行训练配置得到真武810E机器上的最佳 visible device order设置;
pccl perf:
支持AllReduce、AllGather、ReduceScatter、AlltoAll、Broadcast及Reduce;
支持基于hgpti callback机制进行pccl device kernel时间统计的新方式,具体可见:
去除对libmpicxx.so的依赖;
p2pBandwidthAndLatencyPerf工具增强:
支持真武810E产品在各种多卡互联topo server下的icn p2p互联带宽与延迟性能评估;
pccl check tools:
支持真武810E产品在多卡或多机多卡等场景下的功能readiness检查;
1.3.6 Video/Image codec硬件加速
兼容Nvidia Video Codec SDK,包括cuvid decode, nvenc和nvjpeg;兼容Nvidia 2D Image NPP接口。基于此,可以直接支持ffmpeg, OpenCV,DALI,PyAV(torchvideo, torchvision...),TorchCodec 等上层框架的Codec硬件加速能力,不需要额外修改代码去适配。
Video Decode
Support Nvidia cuvid decoder。
Codecs:
HEVC (H.265) - ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 Profile, Level 5.1, High Tier
Main Still Profile
VP9 - vp9-bitstream-specification-v0.6-20160331-draft
Profile 0, 8-bit
Profile 2, 10-bit
AVC (H.264) - ITU-T Rec. H.264 (03/2010) / ISO/IEC 14496-10
Main Profile, levels 1 - 5.2
High Profile, levels 1 - 5.2
High 10 Profile, levels 1 - 5.2
Baseline Profile, levels 1 - 5.2
AV1 Bitstream & Decoding Process Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
AVS2
Resolution Up to 8192x8192
Up to FHD 192 streams
Video Encode
Support nvenc
Codecs:
AVC(H.264):Spec Version 12:ISO/IEC 14496-10 / ITU-T Rec. H.264 (03/2010)
Baseline Profile, levels 1 – 5.2
Main Profile, levels 1 - 5.2
High Profile, levels 1 – 5.2
High 10 Profile, levels 1 - 5.2
HEVC(H265):ITU-T Rec. H.265 (04/2013), ISO/IEC 23008-2
Main Profile, Level 5.1, High Tier
Main10 profile, Level 5.1, High Tier
Main Still Profile
AV1 Bitstream Specification Version 1.0.0 with Errata 1
Main Profile, Level 5.1
Resolution up to 4K support
Support input RGB format (converted to YUV420 via inlinePP)
Support crop, scale, rotate with inlinePP
Up to FHD 32 streams
JPEG:
Support nvjpeg decoder & encoder
Resolution up to 32Kx32K
Support RGB format input and output with inlinePP
Support crop, scale, rotate with inlinePP
Up to UHD 960FPS
Image Process:
Support Nvidia 2D Image NPP
1.3.7 软件工具
为了满足云计算大规模集群监控需求,我们发布了如下PPU管理和监控工具和库文件,以便集成到客户集群运维监控系统中:
PPU设备管理工具ppu-smi类似Nvidia-smi。详细介绍请参考设备管理工具PPU-SMI;
ppu-smi v1.5新功能主要包含:
更新已知问题
增加查询SDK各组件版本信息的描述
数据中心管理和监控工具PPU DCG类似Nvidia DGCM,详情请参考管理监控工具DCGM;
DCGM v1.5新功能主要包含:
增加Docker环境使用DCGM的说明
hgml类似Nvidia nvml;
发布了PPU性能分析工具Asight Systems和Asight Compue(类似 Nvidia Nsight Systems/ Compute),可以支持用户进行单机、多机训练、推理等场景的性能分析;
Asight Systems 是一款低开销的系统级的性能分析工具,用来采集系统各种事件,CPU和PPU的活动,API执行时间以及相关调用栈,NVTX,CPU/PPU activity关联关系等,在Timeline View上统一的可视化呈现出来。 通过imeline View,开发人员可以方便分析CPU/PPU的负载和关联关系,找到性能瓶颈,确保CPU和PPU能够协调的工作,确保最大的并行度。详细介绍请参考程序性能分析套件Asight Systems;
Asight Systems v1.5新功能主要包含:
asys stats支持HGTX PPU projection summary统计功能
asys stats支持HGGC PPU memory跟踪数据量 / 耗时统计功能
asys stats子命令PPU kernel相关统计功能支持添加HGTX range前缀
asys stats子命令HGTX Range Summary支持按照进程过滤
asys stats子命令PPU跟踪相关统计功能支持指定统计的PPU device列表
asys stats子命令Device Memory Uasge Details / Summary支持2 / 4种查看模式
asys analyze子命令PPU时间利用率分析支持指定时间范围的选择模式
asys专家系统和统计系统description框说明文本简化,增加说明文档跳转链接
asys支持限制生成报告文件尺寸
asys支持通过--hggc-memory-usage选项使能采集device和pinned内存使用情况
支持采集CPU侧动态分配内存的使用情况,支持内存泄露分析 / 内存使用量统计 / 申请次数统计
支持采集MPS模式使能时HGGC context关联的计算资源信息
Memory View支持4种查看模式以及火焰图
Timeline View 优化PPU activity依赖关系的显示方式
Timeline View支持分组显示功能,允许将感兴趣的时间线行添加到Group View中并单独显示
Timeline View支持Device Memory Timeline,帮助用户分析各模块的内存的使用情况,支持三种模式:普通模式;分组模式;分组着色模式
Timeline View支持通信算子分层显示
Timeline View支持不同kernel以不同颜色显示
Timeline View支持CPU侧heap内存时间线显示
Time range tooltip中支持显示PPU active/idle时间占比
Timeline View 选择time range时按住Shift键支持吸附至最近的时间线起点/终点
Timeline View支持按shift/ctrl多选时间线行
Timeline View性能优化,解决了打开超大报告GUI卡顿的问题
HGGC API支持C调用栈和Python调用栈的混合显示
Asight Compute是一款kernel性能分析工具,通过采集PPU硬件perf counter,组合成为一系列性能指标,我们称为metrics。GUI通过各种维度,把这些metrics呈现出来, 帮助用户深入分析和优化kernel,详细介绍请参考Kernel分析器Asight Compute;
Asight Compute v1.5新功能主要包含:
Details Page中Memory Chart支持按transfer size/throughput显示
Details Page中Memory Chart连接链路tooltip中显示链路利用率
Details Page中的tooltip支持pin住,pin住后支持选择文本拷贝
Details Page中Launch Statistics中增加 Stack Size Per Thread
Details Page中Launch Statistics中增加 Driver SharedMemory Per Block
Baseline按钮布局更新,明确各按钮功能
Source Page支持点击分支指令跳转,支持高亮所有搜索结果
Source Page增强resolve源代码,支持自动resolve同目录结构其它文件
发布了PPU调试工具PPU-GDB,允许在同一个应用程序中同时调试GPU和CPU代码,最新更新:
在layout asm模式中优化kernel managed name的显示长度
支持blockIdx等internal variables的条件断点,支持register条件断点
支持gdb python extension特性(python版本范围在3.6-3.10)
支持device kernel断点的触发行为:一次触发和多次触发,默认为:一次触发
发布了PPU Memcheck,是一组用于功能性正确检查的工具套件。该套件中包含了一系列的检查工具,包括memcheck、initcheck、synccheck、racecheck;
发布了PPU Binary工具hgobjdump,用于提取binary中的device相关信息;
发布了PPU Prune 工具hgprune,用于提取binary中的device相关信息;
1.4 支持的操作系统
类别 | 操作系统 | 架构 | 内核版本 | GCC |
Ubuntu | Ubuntu 24.04 LTS | x86_64 | 6.8.0-53-generic | 13.3.0 |
Ubuntu 22.04 LTS | 6.2.0-39-generic | 11.4.0 | ||
Ubuntu 20.04 LTS | 5.4.0-131-generic (GA) | 9.5.0 | ||
5.4.0-92-generic | 9.5.0 | |||
Ubuntu 18.04 LTS | 4.15.0-112-generic (GA) | 7.5.0 | ||
4.18.0-15-generic | 7.5.0 | |||
CentOS | CentOS8.2 | 5.10.134-007.ali5000.al8.x86_64 | 8.5.0 | |
Alios | Alios7U2 | 5.10.112-005.ali5000.alios7.x86_64 | 10.2.1 | |
5.10.84-004.ali5000.alios7.x86_6 | 10.2.1 | |||
alippu-driver-4.19.91-014.kangaroo.alios7.x86_64 | 10.2.1 | |||
Afa3 | ALinux3 | 5.10.134-12.2.al8.x86_64 | 10.2.1 | |
5.10.134-13.al8.x86_64 | 10.2.1 |
1.5 SDK版本兼容性说明
1.5.1 KMD兼容性
V1.5 版本向前兼容 V1.3 与 V1.4 的 kmd/mcu_fw。
1.5.2 Firmware兼容性
真武810E需要使用 V1.2.1 以上的 mcu_fw 版本。
1.5.3 SDK兼容性
SDK v1.5从文件、编程接口和编译环境上存在有四类调整,会导致同之前SDK版本的组件或编译产生的组件共存情况下,存在不兼容性的情形。相关的调整内容如下:
将先前SDK中包含的libgomp.so、libomp.so文件移除,改为直接依赖相应OS环境以及host compiler(gcc/clang)所提供的libgomp.so、libomp.so库文件;
此改动可能导致旧版程序执行在v1.5 SDK环境中存在找不到相应so文件的报错;
在编译命令option层面,将“-alippu-xxx的option 选项值 修改为 “-ppu-xxx”的格式;
这些options主要包含在一些定制化编译的场景中,此改动可能导致在混合版本的源代码编译或JIT运行过程中出现编译报错;
在ptx扩展指令层面,有几类扩展ptx指令的调整:
将“alippu.mma.xxx”的ptx指令修改为“ppu.mma.xxx";
将“alippu.ldmatrix.xxx”的ptx指令修改为“ppu.ldmatrix.xxx";
将“cp.async.aiu.xxx”的ptx指令修改为“ppu.cp.async.aiu.xxx”;
SDK 头文件中自定义类型“__ali_bfloat16”修改为“__ppu_bfloat16”;
后面的三类改动会导致之前开源的部分PPU代码库存在编译问题(vllm/cutlass/flash-attn/flashinfer等),需要拉取适配v1.5改动的代码库。
总的来说,以上四类调整会导致在源代码不更新、运行组件局部升级情况下存在编译/运行的兼容性问题,这在内部SDK兼容测试中也得到了体现,建议大家基于完整的v1.5 SDK环境来做编译和运行环境的部署。
测试结论
本次测试随机选取6个客户常用whls,覆盖6个场景,包括Asys和Acu工具,所有测试结果FAlL as expected。
SDK 1.5镜像里大概率不兼容用低版本SDK编译出来的Whls,workaround方法是建议用户手动安装libomp的库后尝试继续使用,不保证UT通过率;
SDK 1.4镜像里大概率不兼容高版本SDK1.5编译出来的Whls,UT大概率不能通过;
对于JIT类型的库如triton等,确定交叉版本的SDK和库不兼容;
混合SDK版本进行编译和安装Whls大概率不兼容。比如SDK1.4镜像里不建议使用混合SDK编译出来的库,SDK1.5镜像里不建议编译低版本的库等;
SDK1.5镜像兼容SDK1.4版本的工具Asys和Acu报告;
1.5.4 asight文件兼容性
v1.5 版本中asys和acu的输出文件兼容v1.4的asys和acu client工具;
2. CUDA生态兼容
2.1 介绍
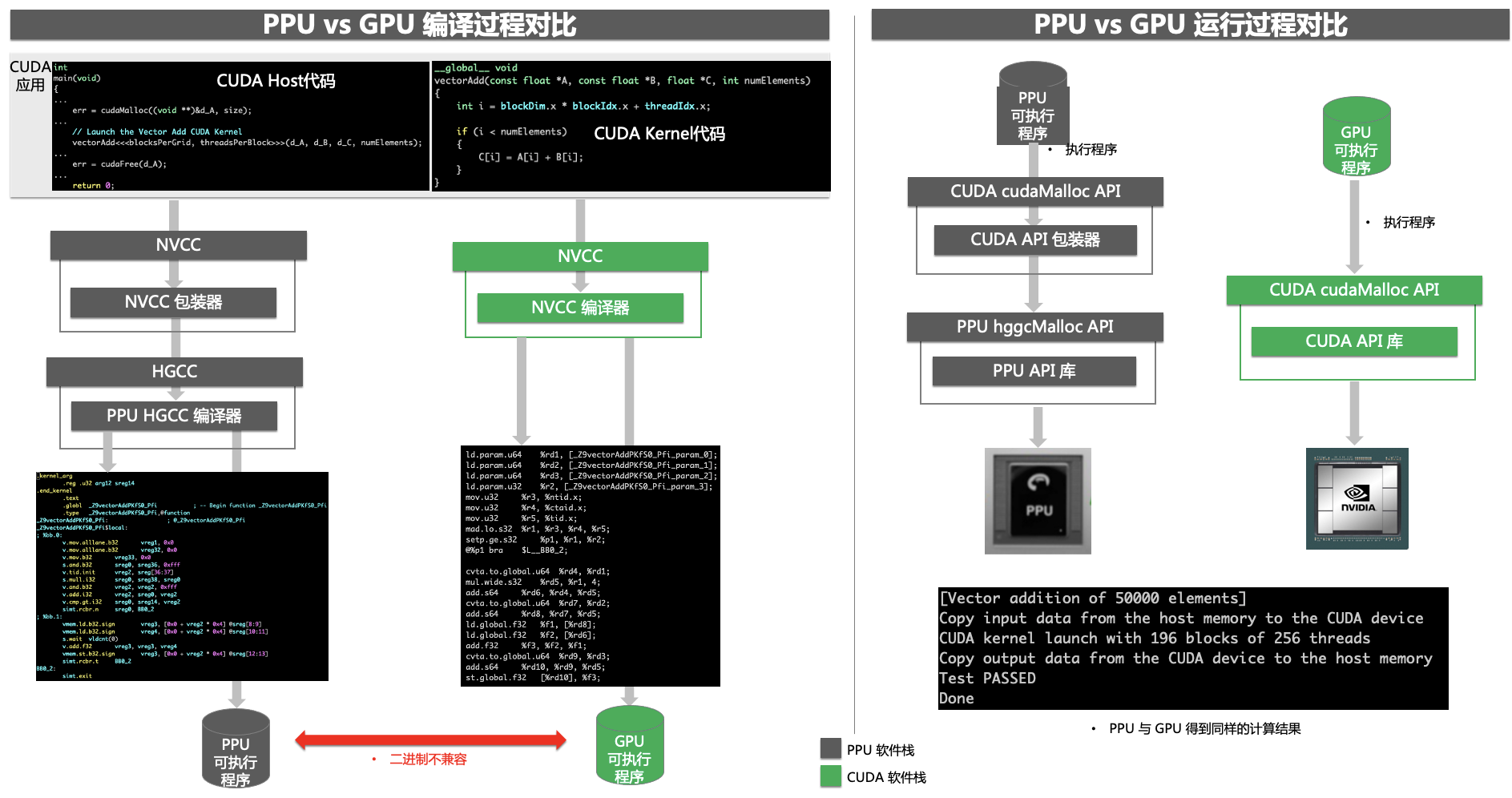
在PPU平台上开发应用程序,用户既可以基于PPU SDK API开发应用程序,也可以使用CUDA语言编写应用程序,经过PPU编译器重新编译后在PPU 上运行,下图展示了同样的CUDA应用程序分别在PPU和GPU上编译、运行的差异。
CUDA 生态兼容方法:通过代码自动生成技术生成CUDA SDK Wrapper来自动兼容CUDA不同版本的APIs,从而使得用户的CUDA程序经过PPU编译器重新编译后即可在PPU上运行。
通过CUDA生态系统的兼容方案,PPU与GPU在源代码级别上是编译兼容的,但PPU二进制与GPU二进制不兼容。
2.2 CUDA APIs兼容版本
截至PPU SDK V1.5版本,对CUDA APIs版本支持到12.8.0,但是限于硬件架构的区别,对CUDA APIs兼容主要在DeepLearning范畴,下表是目前支持的版本列表。更多CUDA兼容性内容请参见兼容性。
CUDA Version |
11.1 |
11.2 |
11.3 |
11.4 |
11.5 |
11.6 |
11.7 |
11.8 |
12.1 |
12.2 |
12.3 |
12.4 |
12.5 |
12.6 |
12.8 预览版 (通过cuda samples、pytorch 2.6 UT测试,但模型等端到端测试不充分) |
2.3 支持的开源框架/库
2.3.1 开源框架/库支持列表
开源框架/库 | 版本 |
apex | 24.4.1 |
auto_gptq | 0.7.1 |
bitsandbytes | 0.40.0 0.41.0 0.42.0 0.43.0 0.44.1 0.45.3 |
byte_flux | 1.0.4 1.1.1 |
cumm | 0.2.9 0.5.3 |
cupy | 13.1.0 13.3.0 13.4.1 |
faiss | 1.7.3 1.7.4 1.8.0 |
cutlass | 2.4 3.3 3.4.1 3.5 3.6 3.7 |
flash-attn | 1.0.5、2.0.9、2.4.2、2.5.6、2.5.7 2.4.2、2.4.3、2.5.0、2.5.1、2.5.2、2.5.3、2.5.4、2.5.5、2.5.6、2.5.7、2.5.8、2.5.9、2.6.0、2.6.1、2.6.2、2.6.3 2.7.0、2.7.1、2.7.2、2.7.3、2.7.4.post1 |
flashinfer | 0.1.0 0.1.1 0.1.2 0.1.6 0.2.0.post1 0.2.1.post1 0.2.2.post1 |
grouped_gemm | 1.1.4 |
jax_cuda12_pjrt | 0.4.34 |
jax_cuda12_plugin | 0.4.34 |
jaxlib | 0.4.34 |
lightllm | 1.0.0 |
lmdeploy | 0.4.2 0.5.3 0.6.3 0.6.4 0.7.0 0.7.1 |
mamba_ssm | 2.1.0 2.2.0 2.2.1 2.2.2 |
mlflow | 2.16.1 2.16.2 2.17.0 2.17.1 2.17.2 2.18.0 |
mmcv-full | 1.4.2 1.5.3 1.6.0 1.7.2 |
mmcv | 2.0.0 2.1.0 2.2.0 |
mmdet | 2.14.0 2.24.0 2.26.0 2.28.2 3.3.0 |
mmdet3d | 1.17.0 1.0.0rc4 1.0.0rc6 1.4.0 |
natten | 0.17.3 0.17.5 |
numba | 0.55.0 0.58.0 0.59.0 0.60.0 0.61.0rc2 0.62.0dev0 |
nvidia_dali_cuda120 | 1.20.0 1.44.0 |
onnxruntime_gpu | 1.20.0 1.20.1 |
onnxruntime_training | 1.18.0 1.19.0 1.19.2 |
open3d | 0.18.0 0.19.0 |
opencv-contrib-python | 4.10.0.84 |
paddlepaddle-gpu | 2.6.2 |
pytorch3d | 0.7.6 0.7.7 |
sgl_kernel | 0.0.2.post8 0.0.3 0.0.3.post6 0.0.5 |
sglang | 0.2.14 0.4.1 0.4.2 0.4.3 0.4.4.post1 0.4.4.post3 |
spconv-cu | 2.1.21 2.2.6 2.3.6 |
tensorflow | 2.14.1 2.17.0 2.6.3 |
torch | 1.10.0 1.10.1 1.8.0 1.9.0 1.9.1 2.0.1 2.1.0 2.1.2 2.2.0 2.2.1 2.3.0 2.3.1 2.4.0 2.5.1 2.6.0 |
torch_xla | 2.3.0 2.4.0 2.5.1 2.6.0 |
torchao | 0.2.0 0.3.0 0.4.0 0.7.0 |
torchaudio | 2.4.0 2.5.1 |
torchdata | 0.6.1 0.7.0 0.7.1 0.8.0 |
torchrec | 0.7.0 |
torchtext | 0.15.2 0.16.0 0.16.2 0.17.0 0.17.1 0.18.0 |
torchvision | 0.10.0 0.10.1 0.11.0 0.11.1 0.16.2 0.19.0 0.20.1 |
transformer_engine | 1.11 1.12 1.13 1.5 1.7 2.0 |
triton | 2.1.1 2.2.0 3.0.0 3.1.0 3.2.0 |
vllm-flash-attn | 2.6.2 |
vllm | 0.6.3.post1 0.6.4.post1 0.6.6.post1 0.7.1 0.7.2 0.7.3 |
xformers | 0.0.22 0.0.25 0.0.27 0.0.29.post1 |
sgboost | 1.6.2 |
OneFlow | 0.7.0 |
MXNet | 1.8.0 |
TorchACC | 1.12 |
HIE-ALLSPARK | 1.0.0 |
BladeDISC | 0.21 |
rtp-llm | 0.2.0 |
trition-inference-server | 2.21.0 |
Megatron-Core | 0.5.0 0.7.0 0.8.0 0.9.0 |
DeepSpeed-Megatron | 0.2.0 (d65921c) |
DeepSpeed | 0.8.0 0.10.0、0.12.3、0.13.1 0.14.4 |
Horovod | 0.24.2 |
ray | 2.6.1、2.8.0 |
Nemo | 1.13.0 |
NVTabular | 0.7.1 |
rmm | 23.2.0a0 |
torchmetrics(*) | 1.4.0 |
fbgemm | 0.7.0 |
nvidia_dali_cuda110(*) | 1.20.0 |
nvidia_dali_cuda120(*) | 1.20.0 |
wholegraph(*) | 24.12.00a |
说明:
Pytorch开源支持说明:
Pytorch 2.1及其之前的版本对标NGC
Pytorch 2.1.2及其之后的版本对标torch开源社区RELEASE版本
TensorFlow开源支持说明:
Tensorflow Google社区开源版本1.12仅支持CUDA 9、1.15仅支持CUDA 10 https://www.tensorflow.org/install/source?hl=zh-cn#gpu_support_3
发布Tensorflow 1.15采用NV官方NGC nv22.04的开源版本 https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html#unique_1997996242
Tensorflow 1.12采用PAI TF 1.12
Tensorflow 2.4NGC NV 21.02
Tensorflow 2.6 2.7 Google官方开源社区RELEASE版本
Tensorflow 2.8 NGC NV 22.04
Tensorflow 2.10及以上使用Google官方开源社区RELEASE版本
带(*)标志的,如FlashAttention(*) 与cutlass(*)等,完全对标社区开源版本,未做性能优化,仅功能支持。
其它开源框架/开源库 除个别对标NGC以外,大部分对标开源社区RELEASE版本,详情请参考各个使用指南。
对于开源框架/开源库,PPU SDK兼容编译、基本功能运行和UT测试,由于资源限制V1.5 RELEASE并没有解决所有测试中发现的问题,遗留问题请参考【已知问题】章节。
2.3.2 开源框架兼容性
框架 | 版本 | 测试类型 | 通过率 |
torch | 2.6 | Unit Test | 97.4% |
sglang | 0.4.3 | Unit Test | 85.44% |
flashinfer | 0.2.2 | Unit Test | 99.42% |
vllm | 0.7.3 | Unit Test | 90.61% |
Pytorch | 1.7 | Unit Test | 98.5% |
Pytorch | 1.8 | Unit Test | 97.6% |
Pytorch | 1.9 | Unit Test | 93.5% |
Pytorch | 1.10 | Unit Test | 94.7% |
Pytorch | 1.11 | Unit Test | 92.9% |
Pytorch | 1.12 | Unit Test | 95.2% |
Pytorch | 2.1 | Unit Test | 95.7% |
Pytorch | 2.3 | Unit Test | 96.9% |
Pytorch | 2.4 | Unit Test | 97.6% |
Pytorch | 2.5.1 | Unit Test | 98.7% |
Pytorch | 2.6 | Unit Test | 95.8% |
Tensorflow | 1.15 | Unit Test | 97.6% |
Tensorflow | 2.7 | Unit Test | 89% |
Tensorflow | 2.8 | Unit Test | 91.3% |
Tensorflow | 2.12 | Unit Test | 81.3% |
Tensorflow | 2.14 | Unit Test | 83.6% |
Tenorflow | 2.16 | Unit Test | 83.8% |
Tensorflow | 2.17 | Unit Test | 89.81% |
Megatron-Core | 0.8.0 | Unit Test | 99.7% |
Megatron-Core | 0.7.0 | Unit Test | 97.5% |
DeepSpeed | 0.15.2 | Unit Test | 93.1% |
DeepSpeed | 0.14.4 | Unit Test | 89% |
Horovod | 0.24.2 | E2E example | 100% |
VLLM | 0.4.1 | Unit Test | 99% |
VLLM | 0.4.2 | Unit Test | 99% |
VLLM | 0.4.3 | Unit Test | 99.98% |
VLLM | 0.5.0 | Unit Test | 100% |
VLLM | 0.5.1 | Unit Test | 99.9% |
VLLM | 0.5.2 | Unit Test | 99.9% |
VLLM | 0.5.3 | Unit Test | 100% |
VLLM | 0.6.0 | Unit Test | 99.3% |
VLLM | 0.7.2 | Unit Test | 80.66% |
VLLM | 0.7.3 | Unit Test | 90.61% |
sglang | 0.4.3 | Unit Test | 85.44%(A800: 85.25%) |
lmdeploy | 0.3.0 | E2E example | 100% |
lmdeploy | 0.4.0 | Unit Test | 99% |
lmdeploy | 0.4.1 | Unit Test | 98.5% |
lmdeploy | 0.4.2 | Unit Test | 97.7% |
lmdeploy | 0.5.0 | Unit Test | 99% |
lmdeploy | 0.5.1 | Unit Test | 100% |
lmdeploy | 0.5.2 | Unit Test | 97.9% |
lmdeploy | 0.5.3 | Unit Test | 98.5% |
ONNX Runtime | 1.19.2 | Unit Test | 94.9% |
ONNX Runtime | 1.18.0 | Unit Test | 90.0% |
TransformerEngine | 1.11 | Unit Test | 98.69% |
TransformerEngine | 1.5 | Unit Test | 93.7% |
TransformerEngine | 1.7 | Unit Test | 94.3% |
TransformerEngine | 1.8 | Unit Test | 95.2% |
TransformerEngine | 1.9 | Unit Test | 96.1% |
TransformerEngine | 2.0 | Unit Test | 98.69% |
rtp-llm | 0.2.0 | Unit Test | 100% |
torch xla | 2.3 | E2E example | 100% |
xformers | 0.0.27 | Unit Test | 99.9% |
xformers | 0.0.26 | Unit Test | 99.9% |
xformers | 0.0.26 | Unit Test | 99.9% |
xformers | 0.0.25 | Unit Test | 99.9% |
xformers | 0.0.24 | Unit Test | 99.9% |
xformers | 0.0.23 | Unit Test | 99.9% |
xformers | 0.0.22 | Unit Test | 99.8% |
xformers | 0.0.21 | Unit Test | 98% |
vllm-flashattention | 2.4.2 | Unit Test | 99% |
vllm-flashattention | 2.4.3 | Unit Test | 99% |
vllm-flashattention | 2.5.0 | Unit Test | 100% |
vllm-flashattention | 2.5.1 | Unit Test | 100% |
vllm-flashattention | 2.5.2 | Unit Test | 100% |
vllm-flashattention | 2.5.3 | Unit Test | 100% |
vllm-flashattention | 2.5.4 | Unit Test | 100% |
vllm-flashattention | 2.5.5 | Unit Test | 99.9% |
vllm-flashattention | 2.5.6 | Unit Test | 99.9% |
vllm-flashattention | 2.5.7 | Unit Test | 100% |
vllm-flashattention | 2.5.8 | Unit Test | 100% |
vllm-flashattention | 2.5.9 | Unit Test | 100% |
vllm-flashattention | 2.6.0 | Unit Test | 100% |
vllm-flashattention | 2.6.1 | Unit Test | 100% |
vllm-flashattention | 2.6.2 | Unit Test | 100% |
vllm-flashattention | 2.6.3 | Unit Test | 100% |
flashinfer | 0.1.0 | Unit Test | 97.9% |
flashinfer | 0.1.1 | Unit Test | 99% |
flashinfer | 0.1.2 | Unit Test | 99.9% |
flashinfer | 0.1.6 | Unit Test | 99.9% |
flashinfer | 0.2.2.post1 | Unit Test | 99.9% |
text embedding inference | 1.5.0 | Unit Test | 99% |
Apex | 24.04.01 | Unit Test | 91% |
auto_gptq | 0.7.1 | Unit Test | 94.3% |
bitsandbytes | 0.40.0 | Unit Test | 99.9% |
bitsandbytes | 0.41.0 | Unit Test | 99.9% |
bitsandbytes | 0.42.0 | Unit Test | 100% |
bitsandbytes | 0.43.0 | Unit Test | 100% |
bitsandbytes | 0.43.1 | Unit Test | 100% |
byte-flux | 1.0.2 | Unit Test | 92.1% |
byte-flux | 1.0.3 | Unit Test | 95.1% |
cupy | 13.1.0 | Unit Test | 95% |
faiss | 1.7.3 | Unit Test | 100% |
faiss | 1.7.4 | Unit Test | 100% |
faiss | 1.8.0 | Unit Test | 100% |
grouped_gemm | 1.1.4 | Unit Test | 92.5% |
mamba_ssm | 2.1.0 | Unit Test | 94.5% |
mamba_ssm | 2.2.0 | Unit Test | 93.9% |
mamba_ssm | 2.2.1 | Unit Test | 99% |
mamba_ssm | 2.2.2 | Unit Test | 100% |
mmcv | 2.2.0 | Unit Test | 99.9% |
nvidia_dali_cuda110 | 1.20.0 | Unit Test | 94.7% |
nvidia_dali_cuda120 | 1.20.0 | Unit Test | 94.7% |
onnxruntime_gpu | 1.15.1 | Unit Test | 92.1% |
onnxruntime_gpu | 1.16.3 | Unit Test | 97.4% |
onnxruntime_gpu | 1.17.1 | Unit Test | 91% |
onnxruntime_gpu | 1.17.3 | Unit Test | 93% |
onnxruntime_gpu | 1.18.0 | Unit Test | 92.4% |
onnxruntime_gpu | 1.18.1 | Unit Test | 95.7% |
onnxruntime_gpu | 1.19.0 | Unit Test | 96% |
pytorch3d | 0.7.6 | Unit Test | 91.2% |
pytorch3d | 07.7 | Unit Test | 93% |
torchao | 0.2.0 | Unit Test | 99.9% |
torchao | 0.3.0 | Unit Test | 99.9% |
torchao | 0.4.0 | Unit Test | 99.9% |
torchaudio | 2.0.2 | Unit Test | 91.2% |
torchaudio | 2.1.0 | Unit Test | 91.8% |
torchaudio | 2.1.2 | Unit Test | 92.7% |
torchaudio | 2.2.0 | Unit Test | 93% |
torchaudio | 2.2.1 | Unit Test | 99.9% |
torchaudio | 2.3.0 | Unit Test | 99.9% |
torchaudio | 2.3.1 | Unit Test | 99.9% |
torchaudio | 2.4.0 | Unit Test | 99.9% |
torchaudio | 2.0.2 | Unit Test | 99.9% |
torchdata | 0.6.1 | Unit Test | 100% |
torchdata | 0.7.0 | Unit Test | 100% |
torchdata | 0.7.1 | Unit Test | 100% |
torchdata | 0.8.0 | Unit Test | 100% |
torchmetrics | 1.4.0 | Unit Test | 95% |
torchrl | 0.5.0 | Unit Test | 93.9% |
torchtext | 0.15.2 | Unit Test | 96.9% |
torchtext | 0.16.0 | Unit Test | 97% |
torchtext | 0.16.2 | Unit Test | 97% |
torchtext | 0.17.0 | Unit Test | 96.8% |
torchtext | 0.17.1 | Unit Test | 98% |
torchtext | 0.18.0 | Unit Test | 98% |
torchvision | 0.15.2 | Unit Test | 99.9% |
torchvision | 0.16.0 | Unit Test | 99.9% |
torchvision | 0.16.2 | Unit Test | 97% |
torchvision | 0.17.0 | Unit Test | 100% |
torchvision | 0.17.1 | Unit Test | 100% |
torchvision | 0.18.0 | Unit Test | 98.9% |
torchvision | 0.18.1 | Unit Test | 99.9% |
torchvision | 0.19.0 | Unit Test | 99.9% |
transformer_engine_torch | 1.8 | Unit Test | 92.7% |
transformer_engine_torch | 1.9 | Unit Test | 93.4% |
transformers | 4.30.2 | Unit Test | 94% |
transformers | 4.31.0 | Unit Test | 92.1% |
transformers | 4.32.1 | Unit Test | 93.4% |
transformers | 4.33.2 | Unit Test | 93% |
transformers | 4.34.1 | Unit Test | 93% |
transformers | 4.35.2 | Unit Test | 92.7% |
transformers | 4.36.2 | Unit Test | 92.6% |
transformers | 4.37.2 | Unit Test | 94% |
transformers | 4.38.1 | Unit Test | 94% |
transformers | 4.38.2 | Unit Test | 94% |
transformers | 4.39.3 | Unit Test | 94% |
transformers | 4.40.2 | Unit Test | 95.2% |
transformers | 4.41.2 | Unit Test | 94.9% |
transformers | 4.42.4 | Unit Test | 96% |
transformers | 4.43.0 | Unit Test | 96.7% |
transformers | 4.43.3 | Unit Test | 98% |
3. 已知问题
3.1 驱动
不支持的CUDA API列表可参考CUDA兼容性。
3.2 编译器
不支持大部分的Texture和Surface相关的Cuda C++扩展 API、Inline PTX指令的功能,编译会报错;
不支持Dynamic Parallelism相关的Cuda C++扩展API、Inline PTX 指令的功能,编译会报错;
针对ptx 8.7之上的新增指令,会存在因硬件架构不支持的部分功能,不影响编译,但运行时会报错;
不支持Inline PTX中ld/st相关指令带有 {.level::eviction_priority} 和 {.level::prefetch_size} 的特性,忽略其定义但不影响编译和运行的过程;
不支持Inline PTX中cache eviction policy相关的指令和操作数,编译会报错;
Device文件编译流程包括Cuda Device C++ 代码 -> llvm(hgvm) IR -> Device Binary的过程, 但不包含输出 ptx 格式的文件过程; 针对其他平台的代码编译(或Codegen)环节,如带有 ptx 格式的编译环节,需要进行代码适配;
兼容CUDA mma及相关数据搬运的ptx指令中大部分,范围包括特定数据类型(.u8/.s8/.tf32/.bf16/.f16)下的dense/sparse mma指令,相比于使用ppu specific tensor core ptx指令实现,性能会存在损失。如果此类kernel的性能在整个端到端中占比重要,则建议对该kernel代码实现进行算法的重构(参考ppu tensor core ptx用户编程手册及算法重构指南);
3.3 加速库
性能:性能泛化能力有待加强。
aublas:
仅支持列表API,详见CUBLAS APIs支持状态,更多API持续按需支持中,更多API持续按需支持中。
不支持复数数据类型。
Gemm: 默认打开FP32 Tensor Core,由于计算顺序等原因导致精度不能和FP32 FMA完全配置,matrixMulCUBLAS实例会因此失败;
Gemv:仅支持host指针模式;
BlasLt:不支持algo/perf等指定属性;
audnn:
仅支持列表API,详见CUDNN APIs支持状态,更多API持续按需支持中。
Conv:不支持INT64/BOOLEAN数据类型,不支持输入FP16 + 输出FP32。
3DConv:有限调优,性能待加强;
depthwise:某些dgrad用例性能待加强;
BN:1)仅支持alpha==1和beta==0参数;2)不支持ACDNN_BATCHNORM_PER_ACTIVATION模式。
Pooling:不支持ACDNN_PROPAGATE_NAN。
RNN:仅支持acdnnRNNBiasMode_t DOUBLE;仅支持FP16/F32数据类型;仅支持ACDNN_RNN_ALGO_STANDARD;
Activation:不支持ACDNN_PROPAGATE_NAN;不支持SWISH Op。
Softmax:不支持SoftmaxAlgorithm_t FAST。
TensorOp:acdnnReduceTensor不支持MUL_NO_ZEROS。
MultiHeadAttn:仅支持前向op。
Backend:1)不支持前处理融合;2)仅支持最多4个pointwise后处理融合;3)仅支持fp16/fp32/bf16数据类型;4)融合的pointwise操作仅支持alpha1 = 1和alpha2 = 1。
ausolver:
仅支持列表API,详见CUSOLVER APIs支持状态,更多API持续按需支持中。
不支持复数数据类型。
aufft:
仅支持列表API,详见CUFFT APIs支持状态,更多API持续按需支持中。
不支持LTO优化;
aurand:
仅支持列表API,详见CURAND APIs支持状态 ,更多API持续按需支持中。
仅支持类型:XORWOW/MRG32K3A/PHILOX4_32_10;
仅支持Legacy order;
仅支持分布类型:default、uniform、uniform double、normal、normal double、lognormal、lognormal double;
3.4 互联库
Collective操作性能:16 x 真武810E服务器采用TP 2/4/8 mode时建议aware自己所用机器的icn topo配置情况以来选择最佳的devices placement;
仅支持 nccl netplugin v7的版本;
执行收发sizes不均衡的alltoallV类型操作会有概率性死锁问题,dmesg中能看到"ERR_FAB_REQ_TO"类型的exceptions,此时需做device reset以恢复为正常状态;
多个pccl communicators同时工作在相同PPU下面时,会有概率性死锁的问题, 需尽量规避多个pccl kernels同时launch在同一ppu device下的行为; 避免设置
NCCL_MIN_NCHANNELS为大于16的值可帮助规避此问题;
3.5 Video Codec/Image硬件加速
Video decode不支持raw nvdec模式;
Video decode不支持MPEG1,MPEG2,MPEG4,VC1,VP8等legacy格式;
JPEG不支持lossless,不支持JPEG2000;
NPP目前只支持Image Process接口,不支持Signal Process接口;
3.6 工具
PPU-SMI已知问题,请参考PPU-SMI已知问题;
Asight Systems已知问题,请参考Asight Systems已知问题;
Asight Compute已知问题,请参考Asight Compute已知问题;
管理监控工具DCGM已知问题,请参考DCGM已知问题;
3.7 框架与模型
开源框架已知问题说明
框架 | 版本 | 已知问题 |
Pytorch | 2.6 |
|
SGlang | 0.4.3 |
|
VLLM | 0.7.3 |
|
TransformerEngine | 2.0 |
|
flashinfer | 0.2.2.post1 |
|