
inference-xpu-pytorch 25.06
本文介绍inference-xpu-pytorch 25.06版本发布记录。
Main Features and Bug Fix Lists
Main Features
基础镜像PPU SDK升级至v1.5.2。
SGLang 0.4.6.post1支持 Qwen3-235B-A22B、Deepseek V3/R1 A8W8(int8)推理。
优化 Qwen3/LLaMa4 访存瓶颈 gemm 问题,性能最高提升50%。
优化 Qwen3-235B-A22B MOE 性能。
Bug Fix
修复v1.5.1版本上开启prefix-cache后模型推理出现乱回复的 bug。
Contents
inference-xpu-pytorch | inference-xpu-pytorch | |
镜像Tag | 25.06-v1.5.2-vllm0.8.5-torch2.6-cu126-20250610 | 25.06-v1.5.2-sglang0.4.6.post1-torch2.6-cu126-20250610 |
应用场景 | 大模型推理 | 大模型推理 |
框架 | pytorch | pytorch |
Requirements | PPU SDK V1.5.2 | PPU SDK V1.5.2 |
系统组件 |
|
|
镜像Asset
建议您使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间。
公网镜像
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.06-v1.5.2-vllm0.8.5-torch2.6-cu126-20250610
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.06-v1.5.2-sglang0.4.6.post1-torch2.6-cu126-20250610
VPC镜像
acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}
{region-id}为您使用的ACS产品所在的开服地域,比如:cn-beijing、cn-wulanchabu等。{image:tag}为实际镜像的名称和Tag。
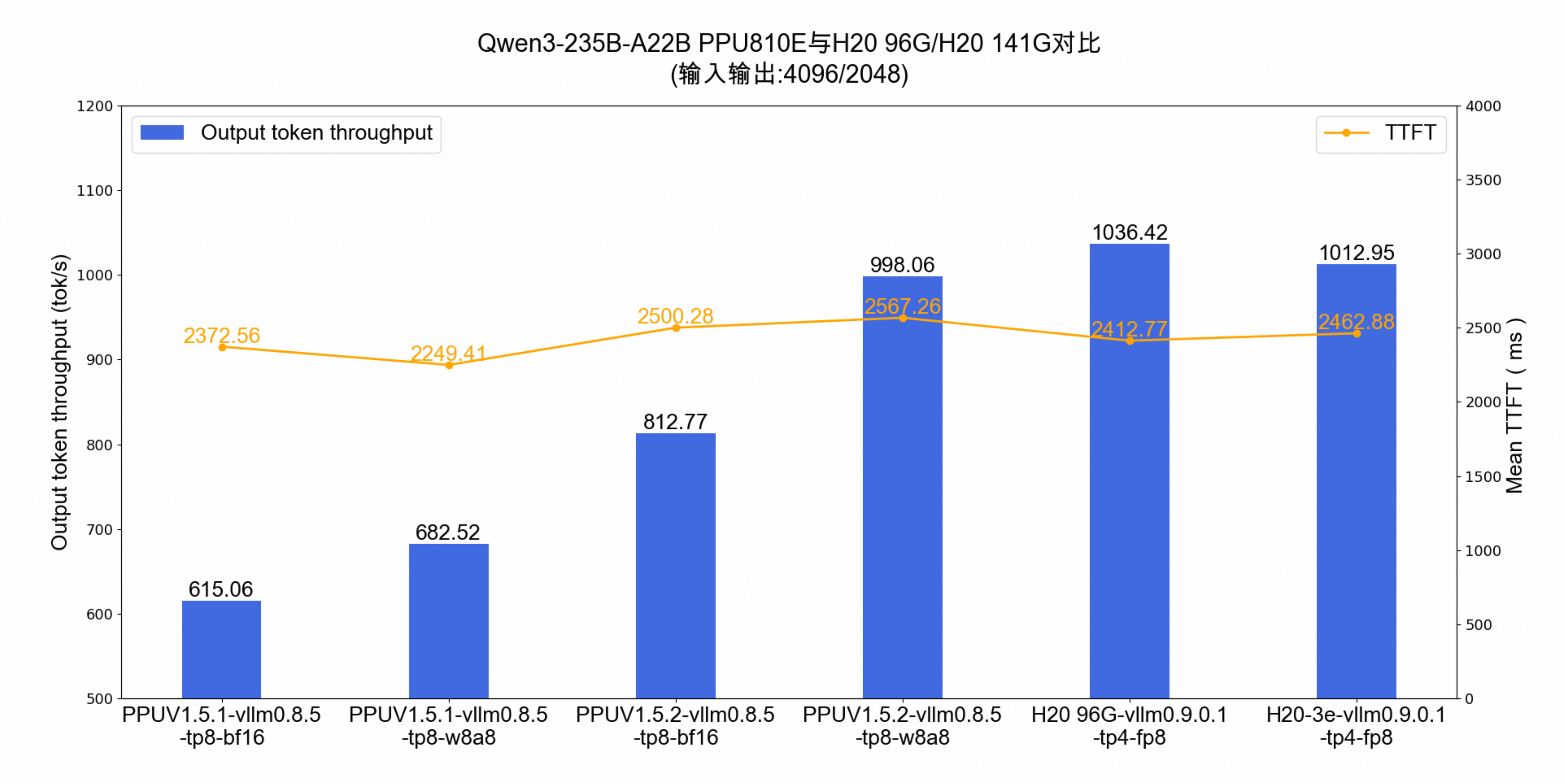
E2E性能评估
vLLM在线推理模式下,控制TTFT<3s 并且 TPOT< 100ms ,测试满足条件的最大并发量,对比吞吐。
vllm0.8.5:
Qwen3-235B-A22B(bf16)模型单机 Output Token Throughput 性能是 V1.5.1版本镜像的 132%。
Qwen3-235B-A22B-INT8 模型单机 Output Token Throughput 性能是bf16模型的 122%。
Quick Start
以下示例内容仅通过Docker方式拉取inference-xpu-pytorch镜像,并使用Qwen2.5-7B-Instruct模型测试推理服务。
在ACS中使用inference-xpu-pytorch镜像需要通过控制台创建工作负载界面的制品中心页面选取,或者通过YAML文件指定镜像引用。
在ACS环境下使用xpu大模型推理镜像的使用指导,请参见ACS集群形态的LLM大模型推理镜像使用指导。
在ACS环境下部署DeepSeek推理服务的使用指导,请参见在ACS中使用PPU快速部署DeepSeek V3/R1推理服务。
拉取推理容器镜像。
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:[tag]从modelscope下载模型文件。
pip install modelscope cd /mnt modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir ./Qwen2.5-7B-Instruct创建推理服务容器。
docker run -d -t --network=host --privileged --init --ipc=host \ --ulimit memlock=-1 --ulimit stack=67108864 \ -v /mnt/:/mnt/ \ egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:[tag]执行推理测试,测试vLLM推理对话功能。
启动Server服务。
python3 -m vllm.entrypoints.openai.api_server \ --model /mnt/Qwen2.5-7B-Instruct \ --trust-remote-code --disable-custom-all-reduce \ --tensor-parallel-size 1在Client端进行测试。
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/Qwen2.5-7B-Instruct", "messages": [ {"role": "system", "content": "你是个友善的AI助手。"}, {"role": "user", "content": "介绍一下深度学习。"} ]}'更多关于vLLM的使用方法请参见vLLM。
使用建议
使用本镜像运行DeepSeek R1(671B)、Qwen3量化模型,支持的量化方法如下:
DeepSeek R1(671B):
VLLM 0.8.5:支持AWQ(w4a16)、GPTQ (w4a16、w8a16)、per-token/per-channel a8w8(int8)量化方案。
SGLang 0.4.6post1:不支持AWQ(w4a16)和GPTQ (w4a16、w8a16)量化方案(存在社区已知问题),支持per-token/per-channel A8W8(int8)量化方案(运行 A8W8(int8)量化模型需要加
--quantization w8a8_int8选项)。
Qwen3:
VLLM 0.8.5:支持AWQ(w4a16)、GPTQ (w4a16、w8a16)、per-token/per-channel a8w8(int8)量化方案。
SGLang 0.4.6post1:支持AWQ(w4a16)、GPTQ (w4a16、w8a16)、per-token/per-channel A8W8(int8)量化方案 。(SGlang0.4.6post1 上通过AWQ和GPTQ运行量化模型需要加
--quantization moe_wna16选项; 运行 A8W8(int8)量化模型需要加--quantization w8a8_int8选项)。
暂时不支持PPU SDK 1.5.1和1.5.2 Release Note中提到的DeepEP和sailSHMEM功能,支持时间待定。
建议配合1.5.1及以上版本驱动使用本镜像获得最佳性能,设置方法请参考为ACS GPU Pod指定GPU型号和驱动版本和GPU驱动版本说明。
本镜像内置环境变量
NCCL_SOCKET_IFNAME需要根据使用场景动态调整:当单Pod只申请了1/2/4/8卡进行推理任务时:需要设置
NCCL_SOCKET_IFNAME=eth0(本推理镜像内默认配置)。当单Pod申请了整机的16卡(此时您可以使用HPN高网)进行推理任务时:需要设置
NCCL_SOCKET_IFNAME=hpn0。
Known Issues
Qwen3模型:
Qwen3-235B-A22B存在推理精度问题,建议增加环境变量
ACEXT_ENABLE_MOE_GEMV=0规避,后续版本会修复。
Qwen2.5模型:
vLLM镜像运行Qwen2.5-omni模型时会出现“
ModuleNotFoundError: No module named 'vllm.vllm_flash_attn.layers'”,此问题由vLLM 0.8.5社区已知问题触发,待vLLM版本更新后修复。
DeepSeek R1模型:
测试DeepSeek R1模型
--max-model-len设置需要小于80k,否则可能会在运行中出现 OOM。
稳定性问题:
性能问题:
MOE类大模型使用Autotune工具可以提升性能 ,VLLM支持通过硬件相关的fused_moe kernel配置文件启动kernel以提升性能的优化功能。