用大模型对电影数据做观众偏好分析
本实验中,您将学会使用阿里云DataV-Note进行电影评价数据的分析探索,通过借助大模型的能力,在“零代码”模式下对复杂多维数据进行分析探索,通过数据洞察背后的复杂商业逻辑。
实验简介
本实验中,您将学会使用阿里云DataV-Note进行电影评价数据的分析探索,通过借助大模型的能力,在“零代码”模式下对复杂多维数据进行分析探索,通过数据洞察背后的复杂商业逻辑。
背景知识
DataV-Note(智能数据分析报告):是DataV系列下基于大模型面向数据分析的智能工具;它支持通过自然语言对话进行Python、SQL等数据分析,并提供丰富的数据可视化能力,支持面向PC、手机等多种使用场景的数据报告分享。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
所有实验操作将保留至您的账号,请谨慎操作。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
实验资源说明:本次实验使用DataV Note个人版包年(¥30.00),将使用300元专属权益优惠券进行费用抵扣(如已兑换过该资源包,且资源包在可使用时间范围内,无需重复兑换,可直接开启实验)
本实验产生的费用优先使用优惠券。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
实操结束后,如通过云工开物代金券购买的产品,无需进行注销;如注销产品,代金券不会返还。
领取专属权益及开通资源
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

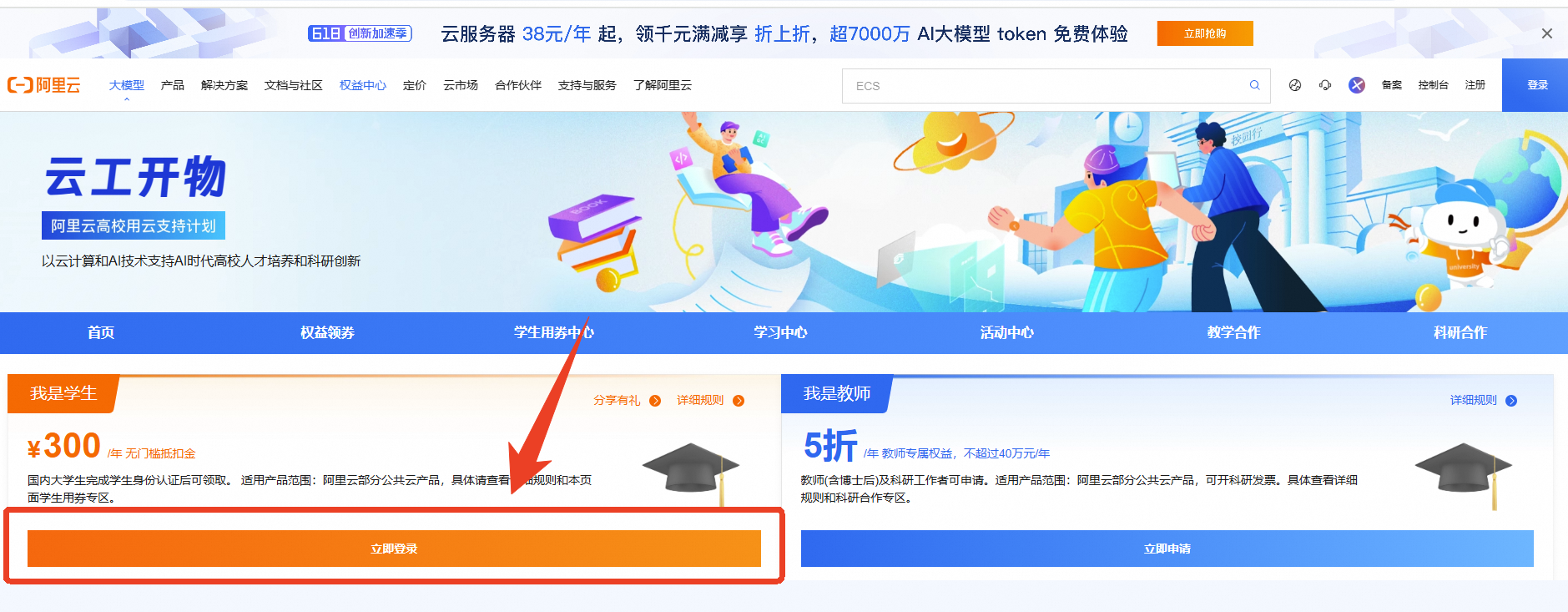
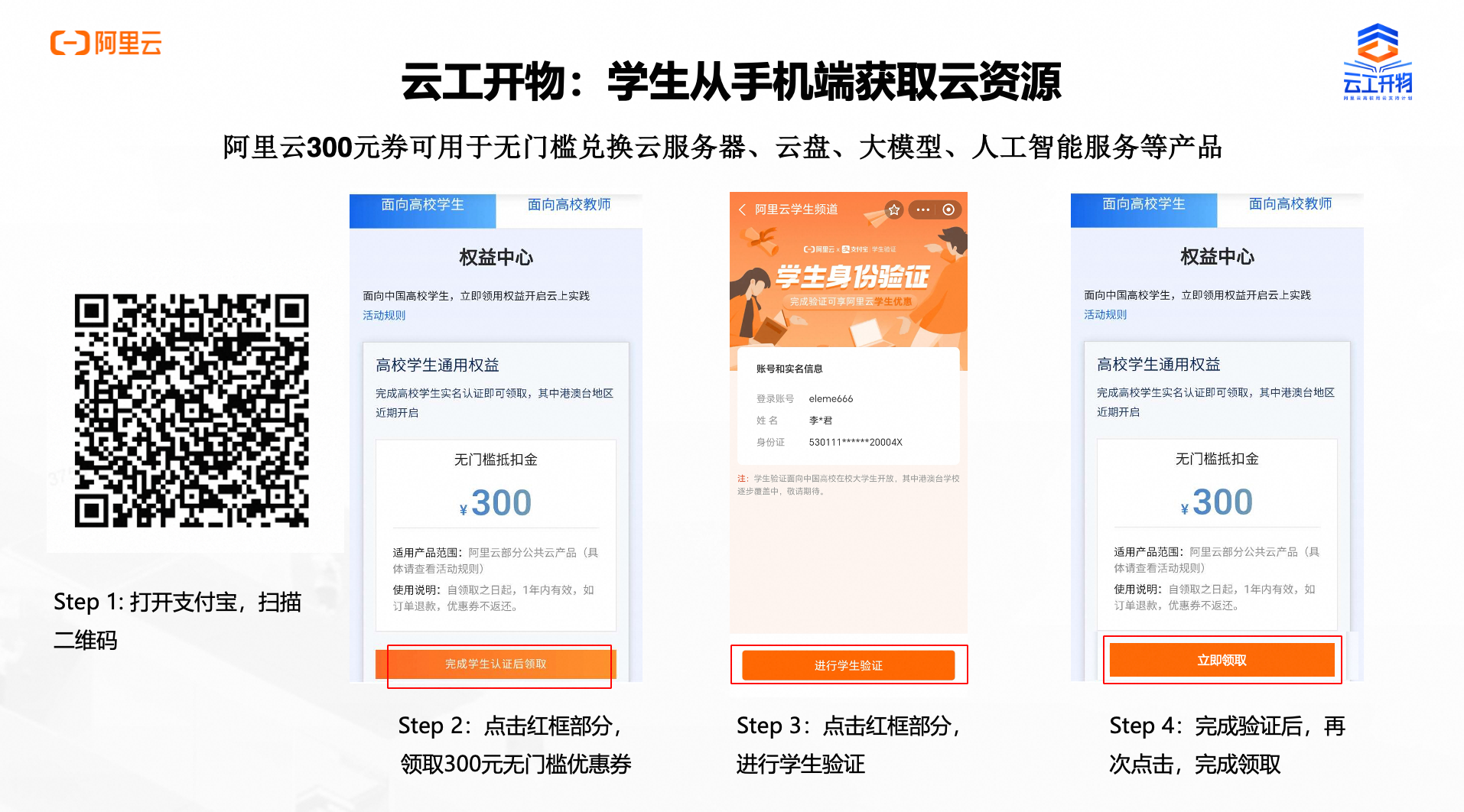
第一步:领取专属权益
本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
第二步:开通资源
领取学生专属300元优惠券后,使用代金券领取阿里云DataV产品
如已兑换过该资源包,且资源包在可使用时间范围内,无需重复兑换,可直接开启实验。
DataV-Note数据分析报告:DataV系列下基于大模型面向数据分析的智能工具;它支持通过自然语言对话进行Python、SQL等数据分析,并提供丰富的数据可视化能力
点击前往领取DataV Note智能分析报告产品:领取DataV Note学生版包月
选择-学生版-1个月,并使用云工开物代金券支付
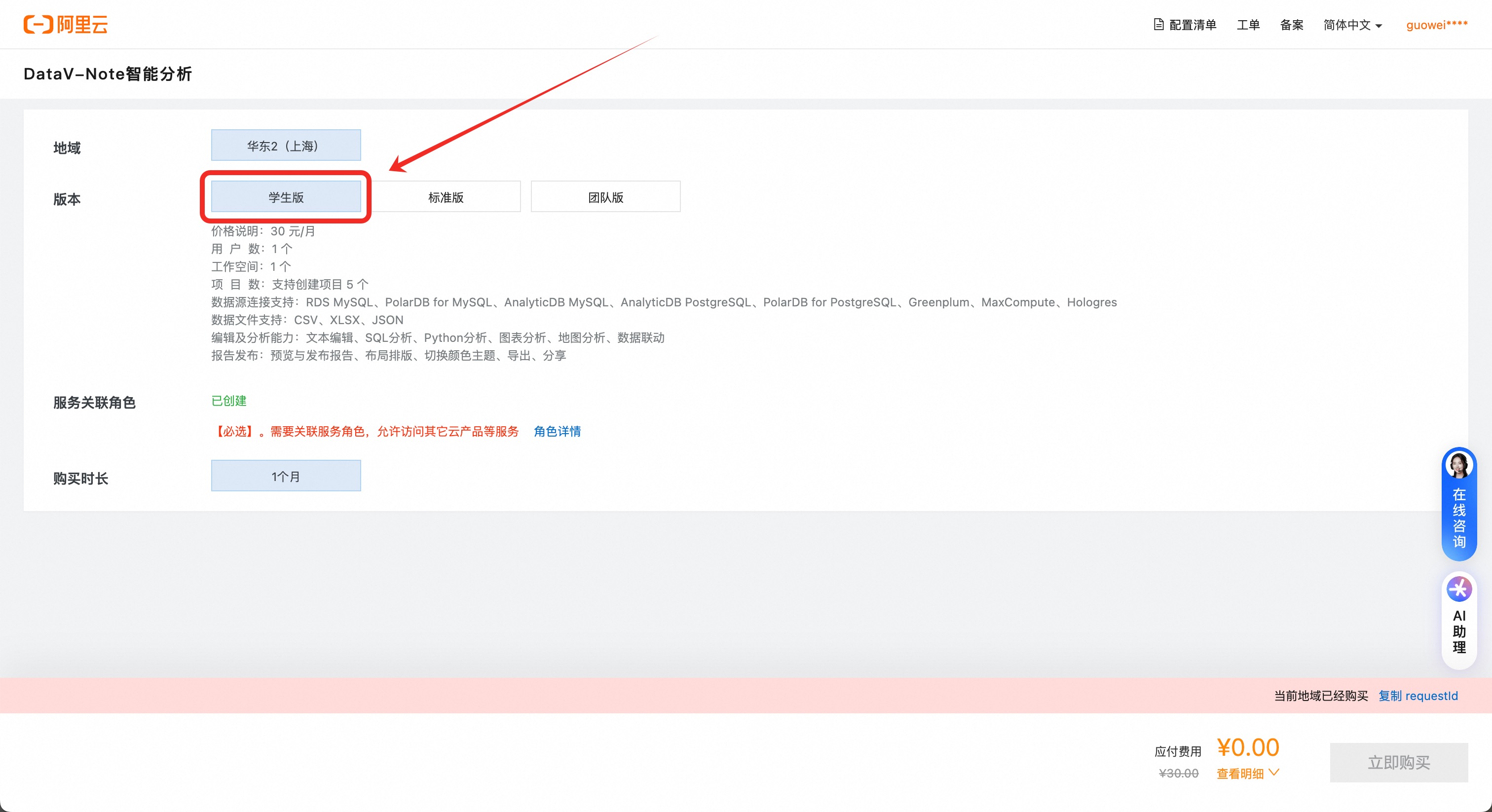
若立即购买按钮置灰,并提示需创建服务关联角色,请先点击【请先创建服务关联角色】

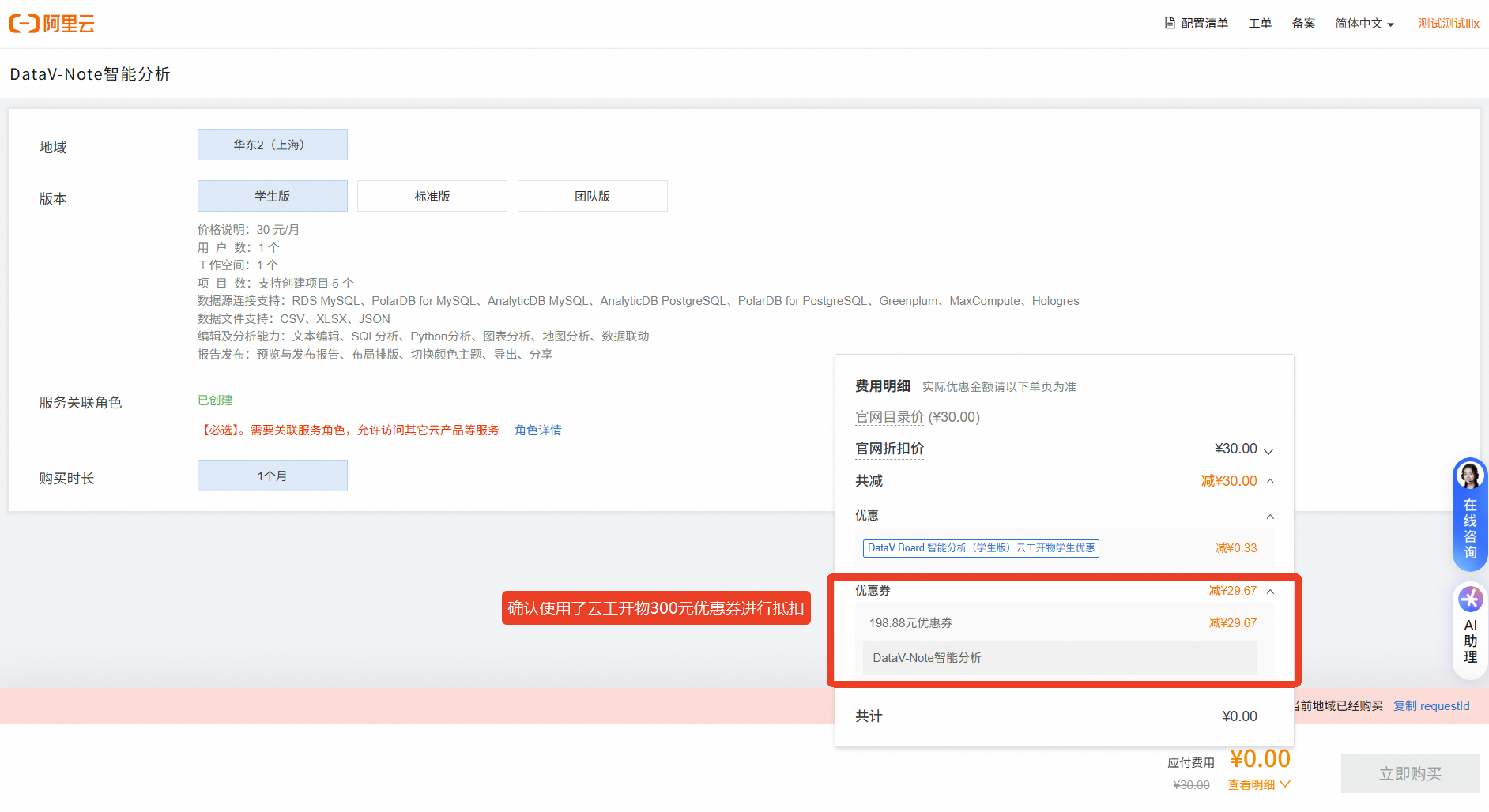
创建好服务关联角色后,请确认使用了云工开物代金券进行抵扣,点击【立即购买】

实验步骤
1、登录DataV Note工作台
点击前往DataV Note工作台
2、数据导入
下载3份电影评价相关数据(都需要下载),并保存到本地
数据来源
公开研究数据集,信息参考: F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4, Article 19 (December 2015), 19 pages. DOI=http://dx.doi.org/10.1145/2827872
数据说明
新建分析项目
登录产品后,点击左侧工具栏【新建项目】
项目命名
点击项目,进入编辑器
进入编辑器状态
导入数据
导入电影名称数据
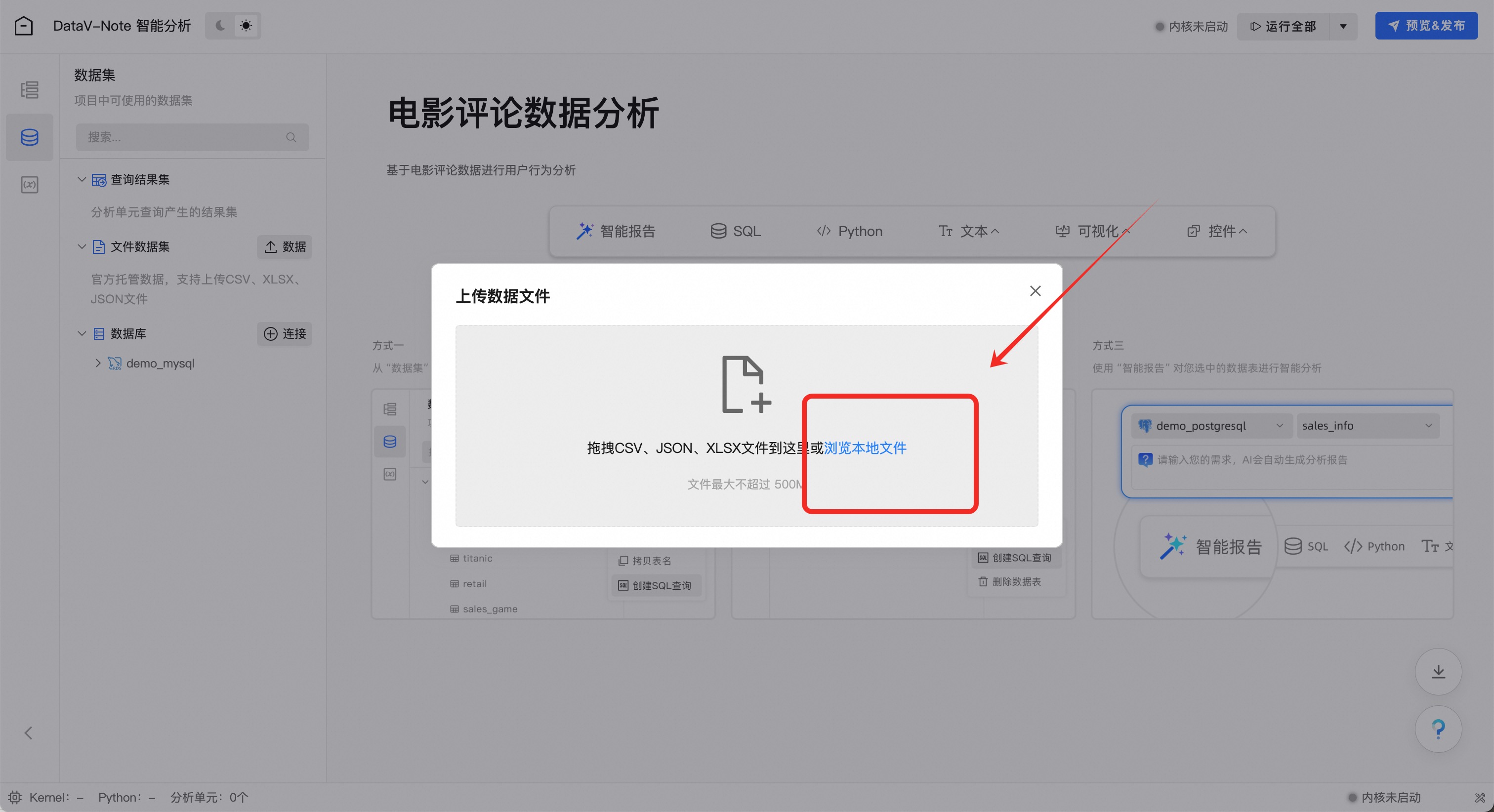
点击工具栏左侧——【文件数据集】——【数据】
点击【浏览本地文件】
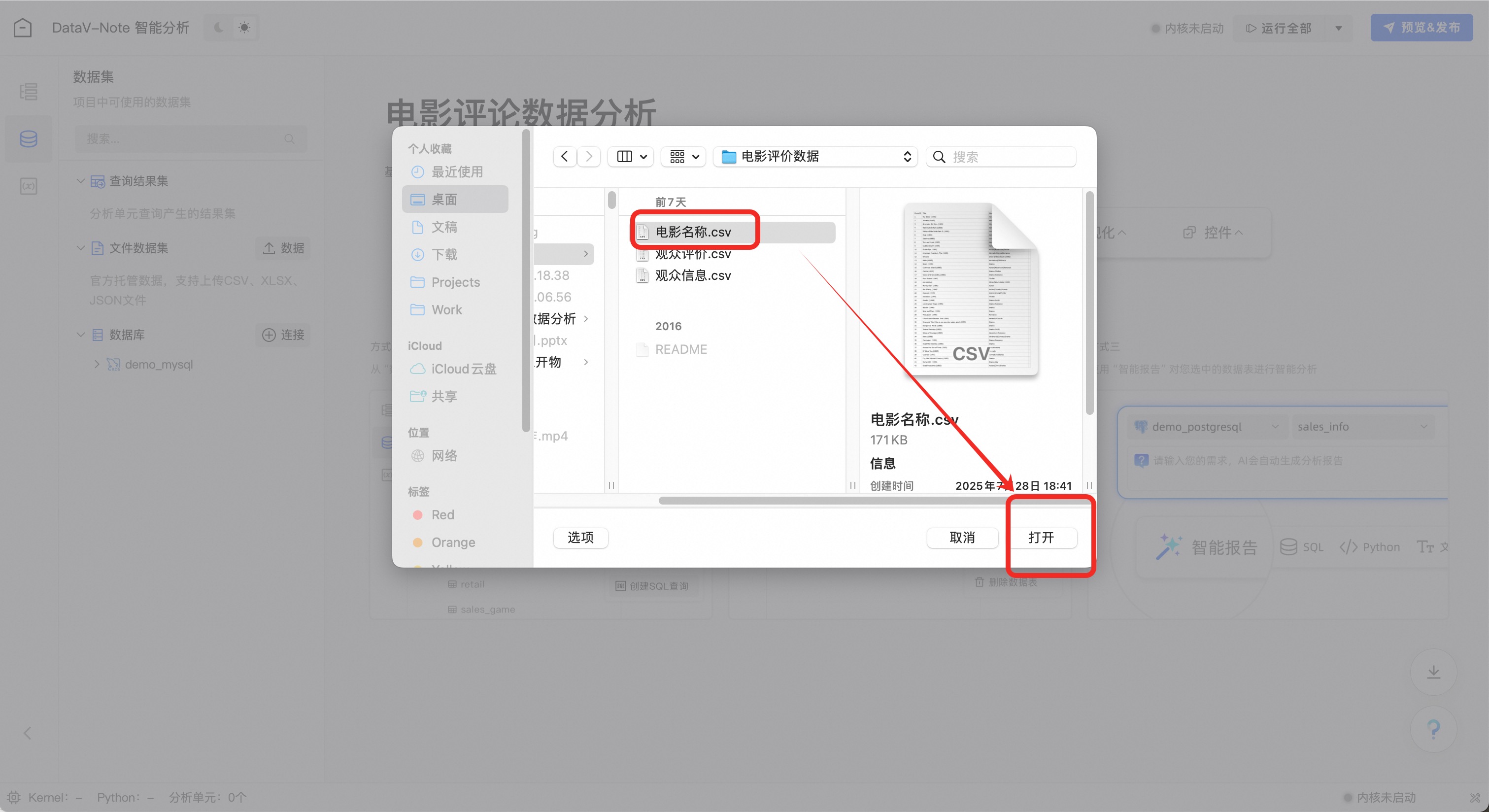
弹出对话框,选择下载的电影名称.csv
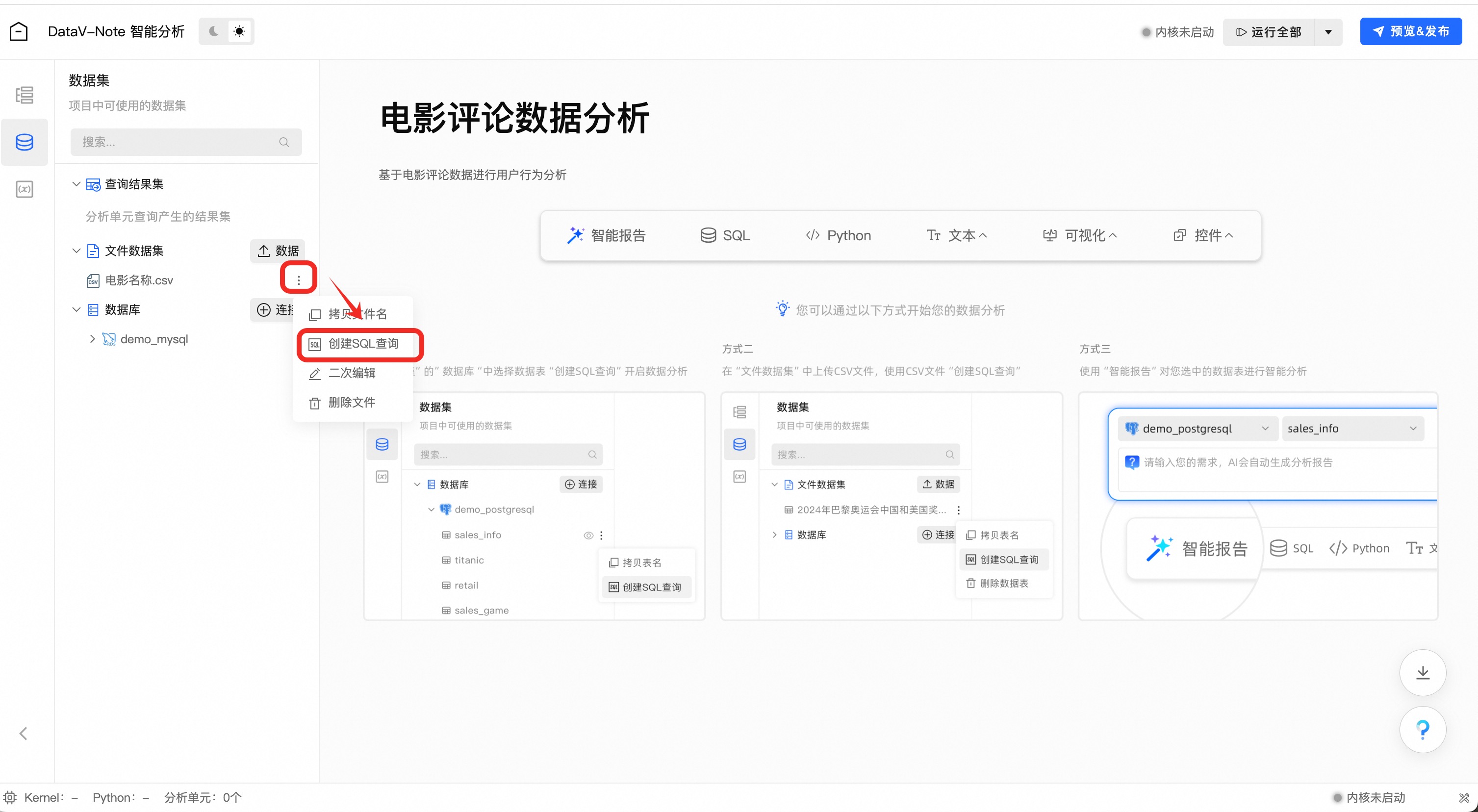
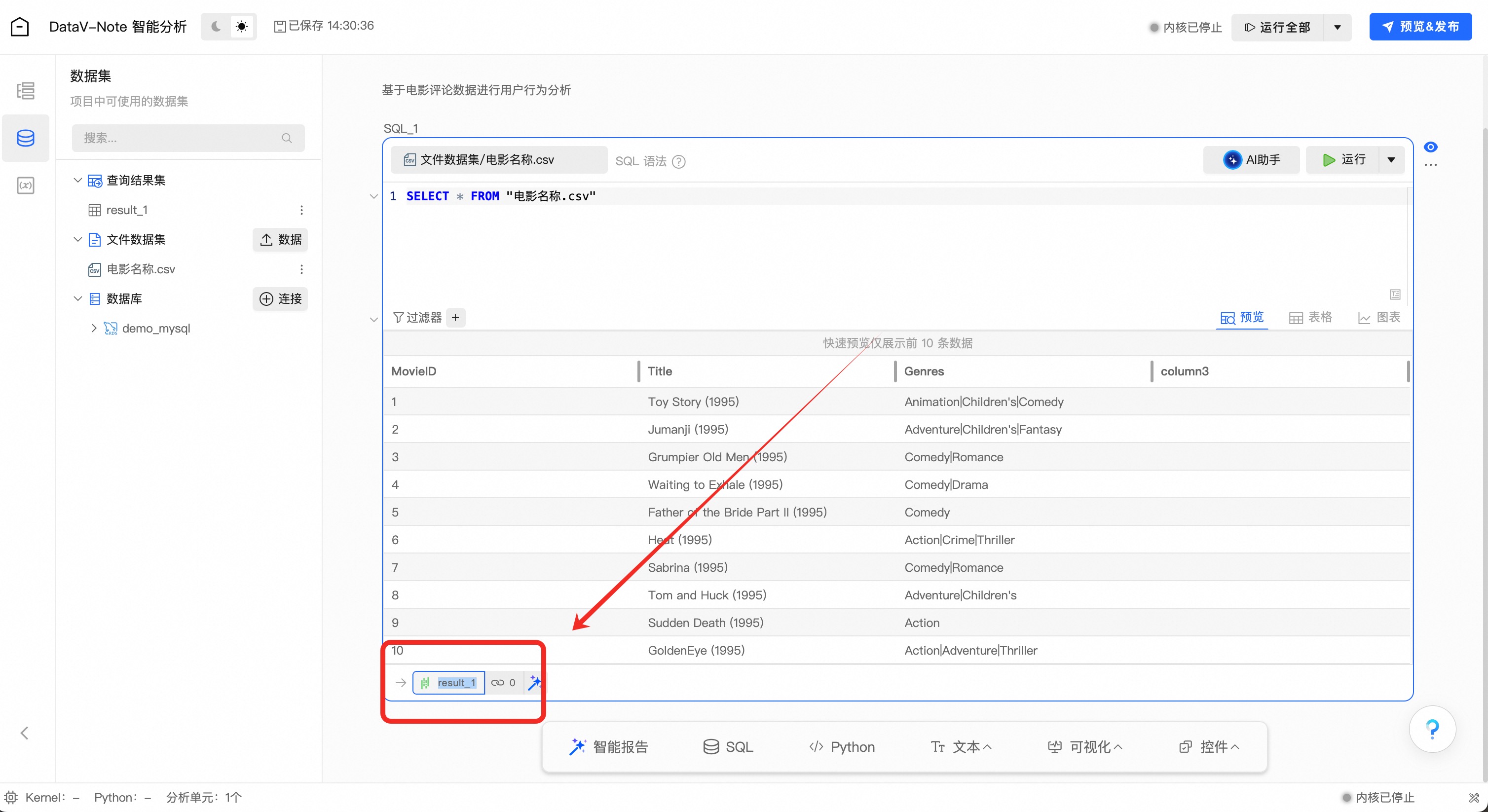
点击工具栏左侧——【文件数据集】——【电影名称.csv】数据旁边的三个小点菜单,在弹出的菜单中选择【创建SQL查询】选项
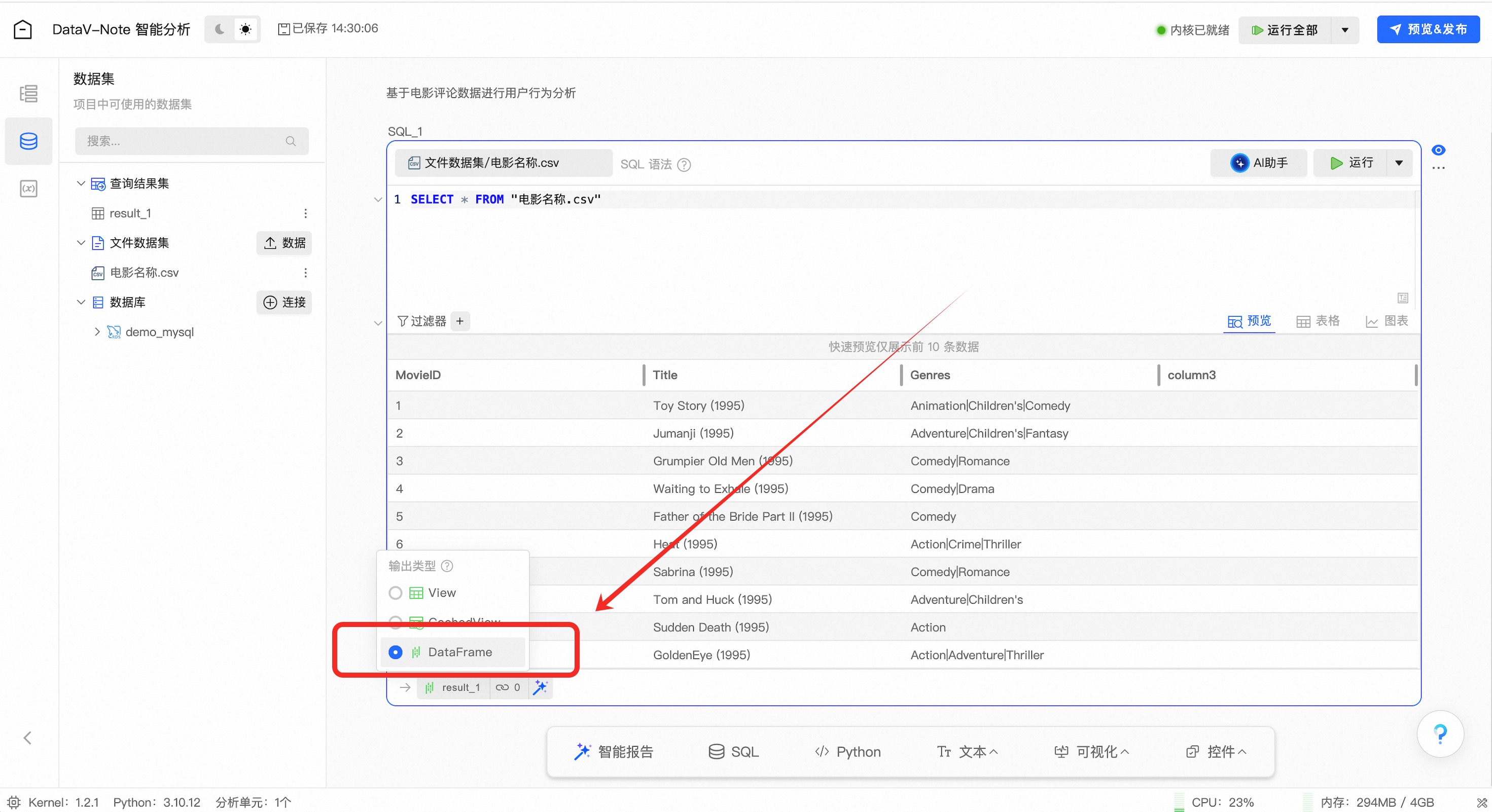
数据查询表格生成之后,鼠标移动到左下角数据表名【result_1】上,在弹出的窗口中将数据表格类型选择为【DataFrame】
(非常重要!DataFrame是python数据分析中重要的格式类型,后续以此开展分析)
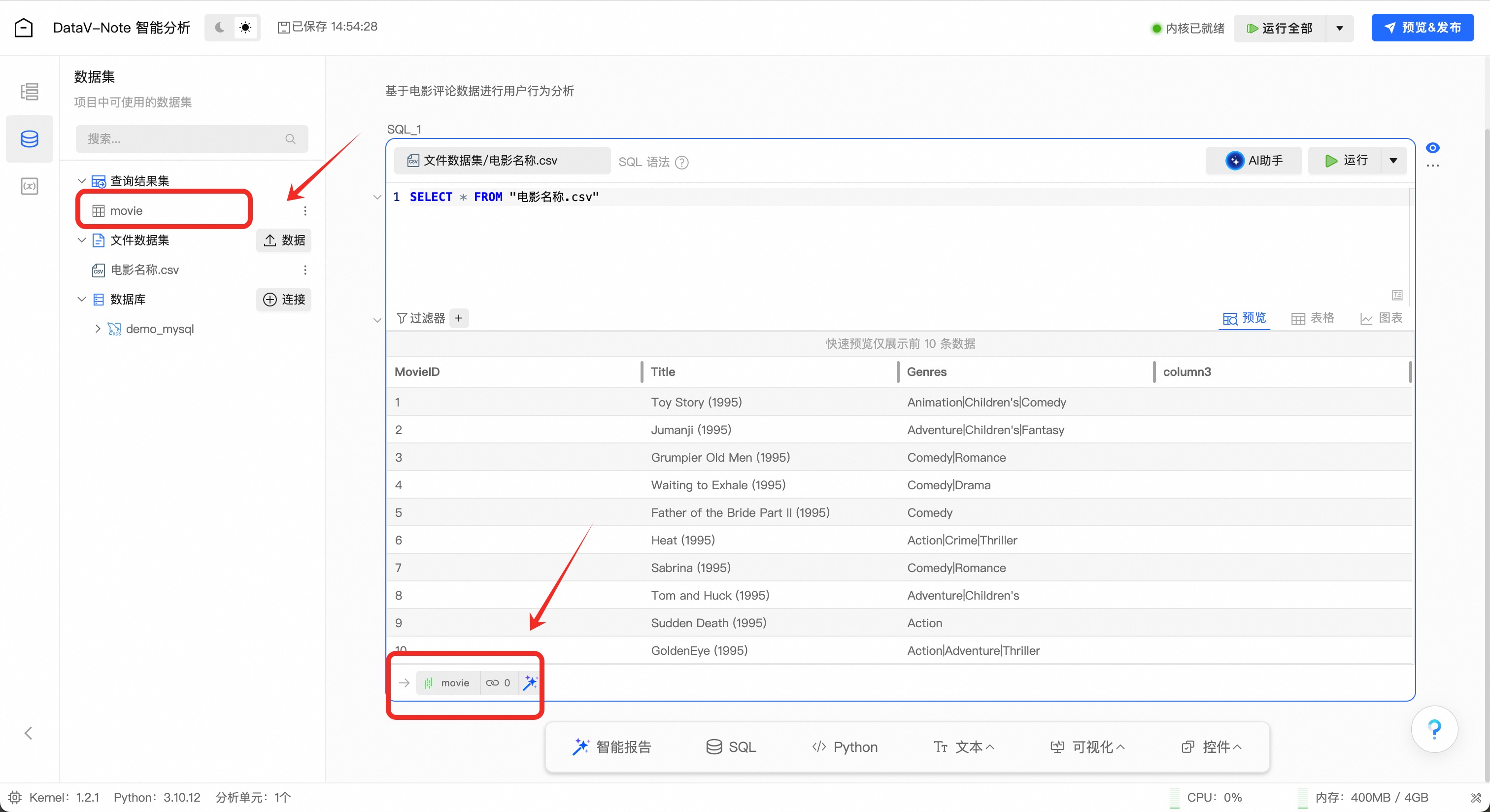
鼠标双击左下角数据表名【result_1】,将表名改为【movie】
(非常重要!表名【movie】是后续python数据分析中引用的变量名称,如不一致后续大模型提示词会出错)
检查电影名称数据是否正确命名为【movie】
导入观众评价数据
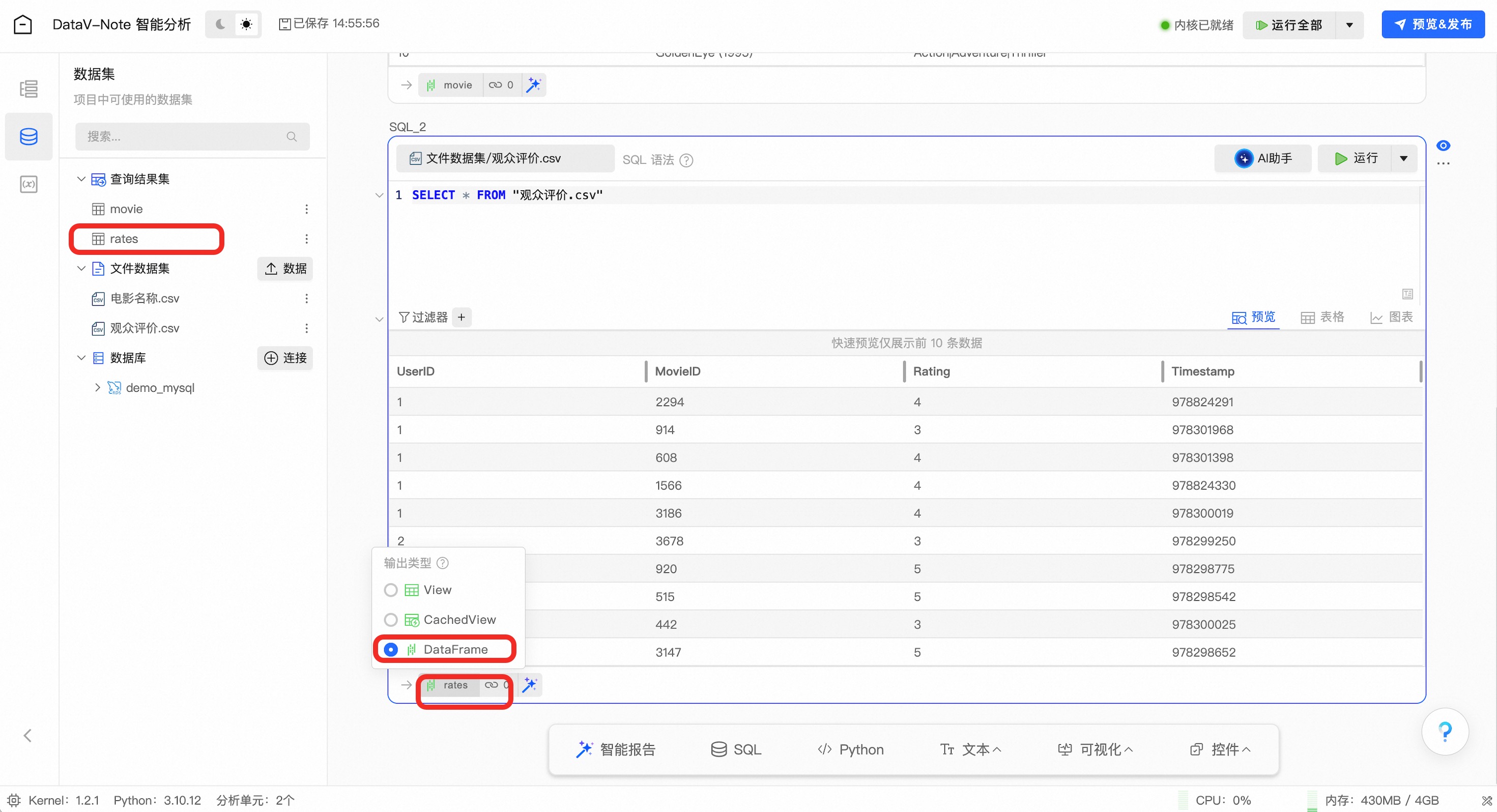
与上述操作类似,将【观众评价.csv】数据导入并执行SQL查询,并检查以下内容:
数据查询结果表是否命名为【rates】
(非常重要!如不一致后续大模型提示词会出错!)
数据查询结果表是否格式设置为【DataFrame】
(非常重要!如不一致后续大模型提示词会出错!)
导入观众信息数据
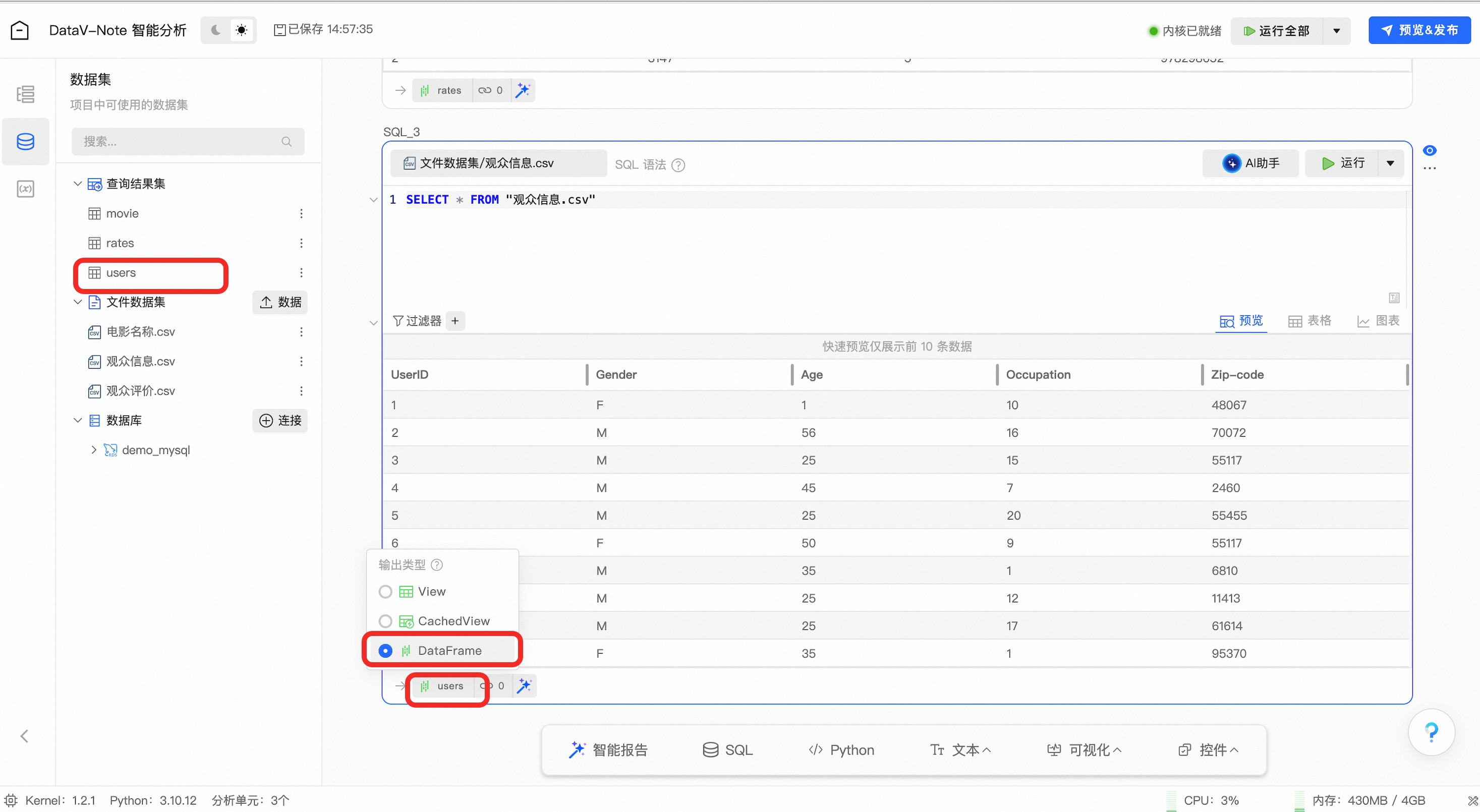
与上述操作类似,将【观众信息.csv】数据导入并执行SQL查询,并检查以下内容:
数据查询结果表是否命名为【users】
(非常重要!如不一致后续大模型提示词会出错!)
数据查询结果表是否格式设置为【DataFrame】
(非常重要!如不一致后续大模型提示词会出错!)
3、数据分析
背景知识:大模型提示词工程与python数据分析介绍
大模型通过自然语言到代码(如NL2Python)的转换技术,使用户无需编程即可高效完成Python数据分析;DataV Note通过对话式交互自动生成数据查询与可视化,显著降低技术门槛。
提示词工程(Prompt Engineering)是通过设计和优化提示词(Prompt)来引导大语言模型(LLM)生成符合预期输出的技术,是通过自然语言到代码进行python数据分析的核心技能之一,其核心在于将用户需求转化为大模型可理解的指令,从而提升python数据分析代码输出的准确性、相关性和可控性。
提示词工程(Prompt Engineering)关键要素及其重要性:
角色定义:为模型分配身份或视角(如“资深python数据分析师”),影响输出的语气、专业性和知识范围。例如,明确角色可使模型输出更贴合特定数据分析需求,减少歧义。
任务描述:明确指令的核心目标(如“对观众评论数量最多的十部电影进行排序输出”),确保模型聚焦于具体任务,避免偏离方向。清晰的任务描述能显著提升输出的针对性。
数据输入/输出:通过上下文、示例和输出指示控制输入信息和输出格式。例如,提供数据输入的变量名称,而输出指定数据变量名称,方便下一步做图表可视化操作。
约束条件:通过角色、任务、上下文等要素隐含或显式设定约束(如字禁止修改原始输入数据等),降低模型“胡说八道”的风险,增强输出的一致性。
分析最受女性欢迎的十大热门电影
参考大模型提示词:
### 角色 你是一位Python数据分析专家,擅长高效处理大规模时序数据。 ### 任务 根据电影评价数据,要求最受女性欢迎的10部电影: * 同一部电影,女性观众的评价数量越多则被认为越受欢迎; * 找出最受女性欢迎的10部电影,按降序排序 ### 输入数据 * 原始数据为rates(电影评分数据)、movie(电影名称数据)、users(用户数据) * 不允许修改原始数据,可以复制原始数据进行分析 ### 输出要求 * 输出最受女性欢迎的10部电影 * 输出结果包含电影名称、女性评分人数 * 输出结果存储在名为popular_female_df的dataframe ### 约束 * 禁止修改原始数据rates(电影评分数据)、movie(电影名称数据)、users(用户数据) * 输出结果存储在名为popular_female_df的dataframe点击下方工具栏【python】按钮
在新增的python代码框右上角,点击【AI助手】
将大模型提示词复制后粘贴到AI助手输入框中,并点击输入框右侧按钮
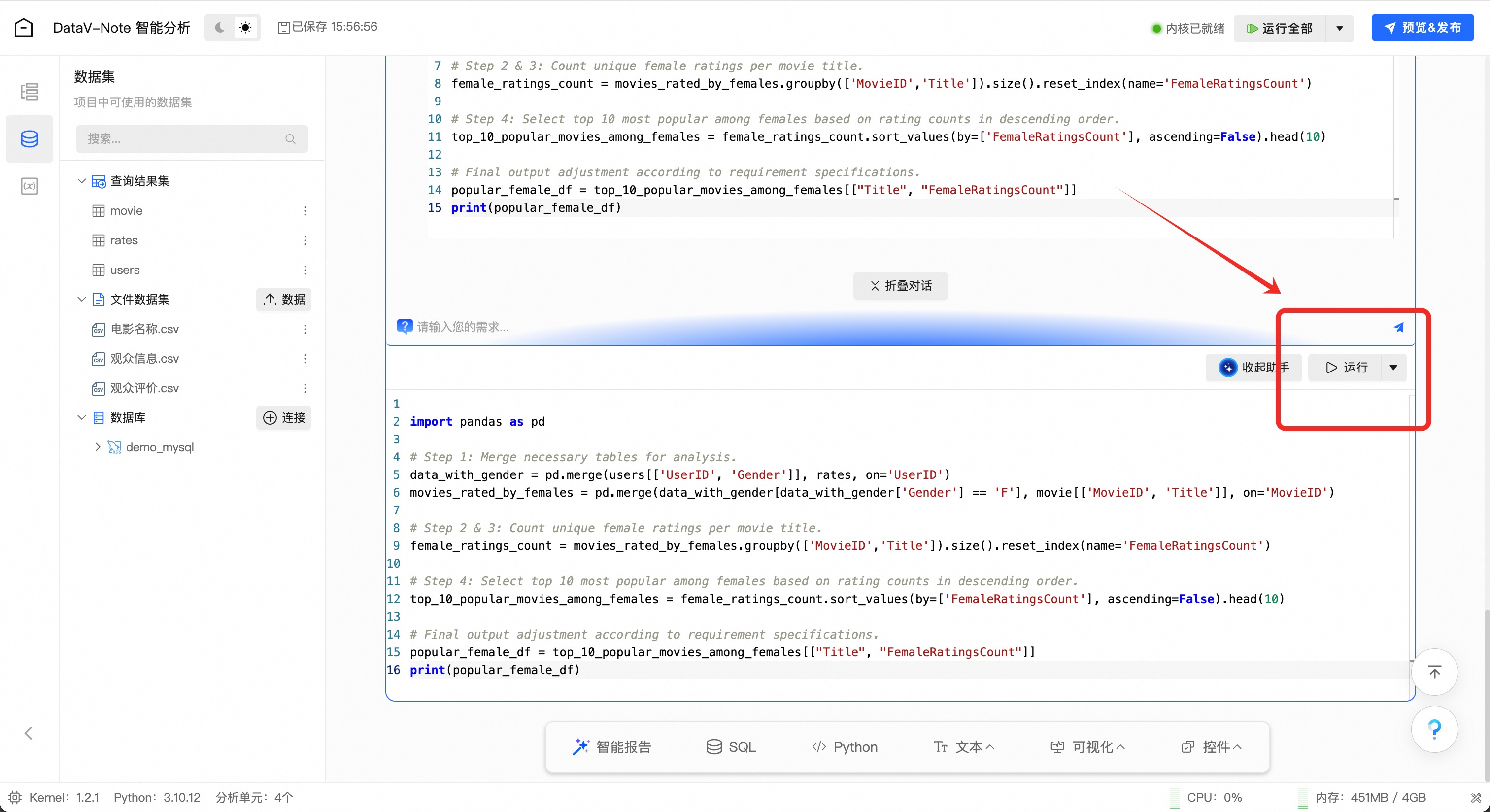
大模型生成python数据分析代码之后,点击代码框右上角【添加到当前单元】
添加代码到编辑框后,点击编辑框右上角的【运行】
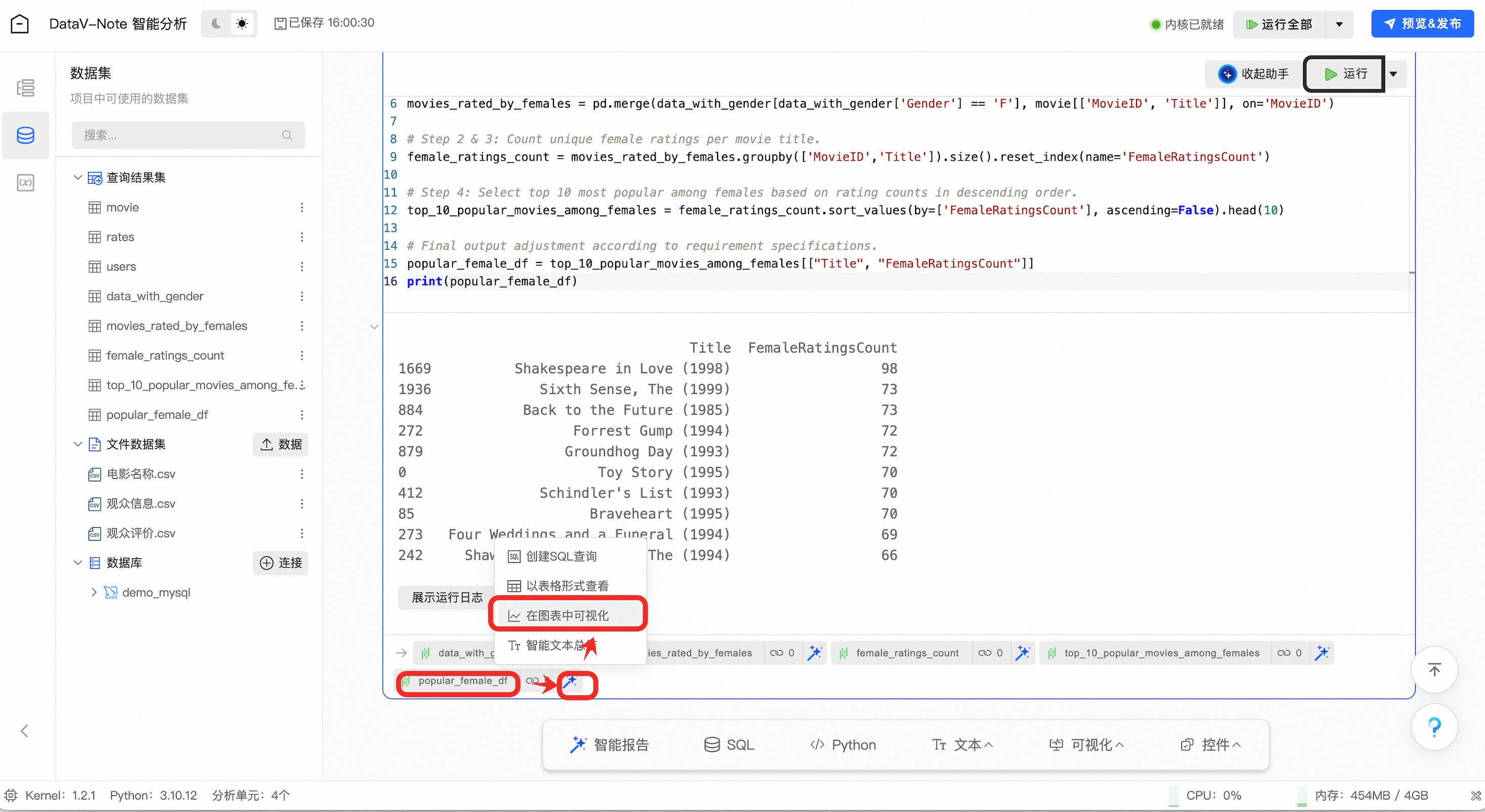
运行代码之后,可以看到分析结果已经出现
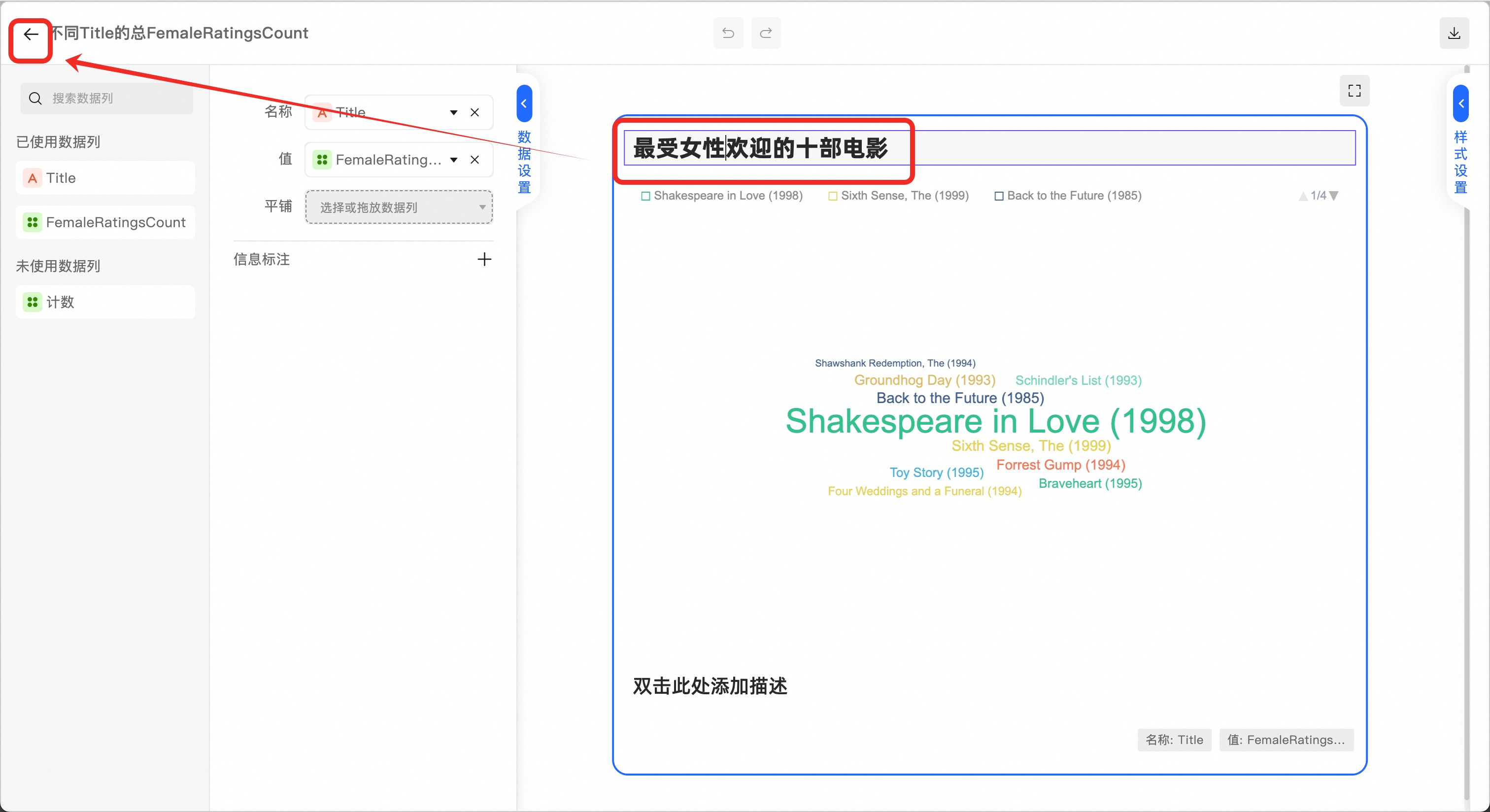
在输出的结果数据【popular_female_df】数据标签上点击右侧按钮,在弹出的菜单中选择【在图表中可视化】
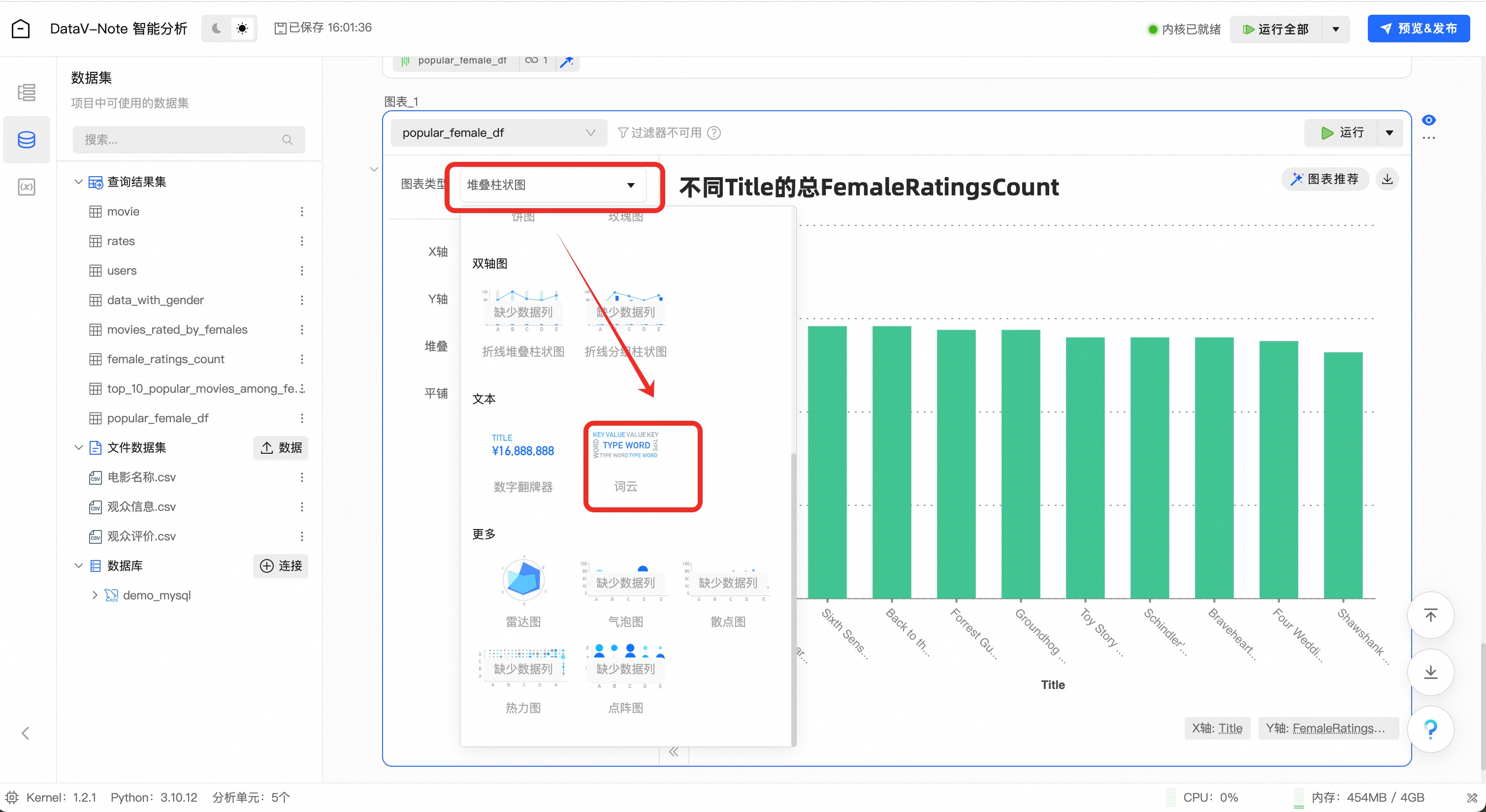
在图表类型中,选择适合的图表形式,例如【词云】
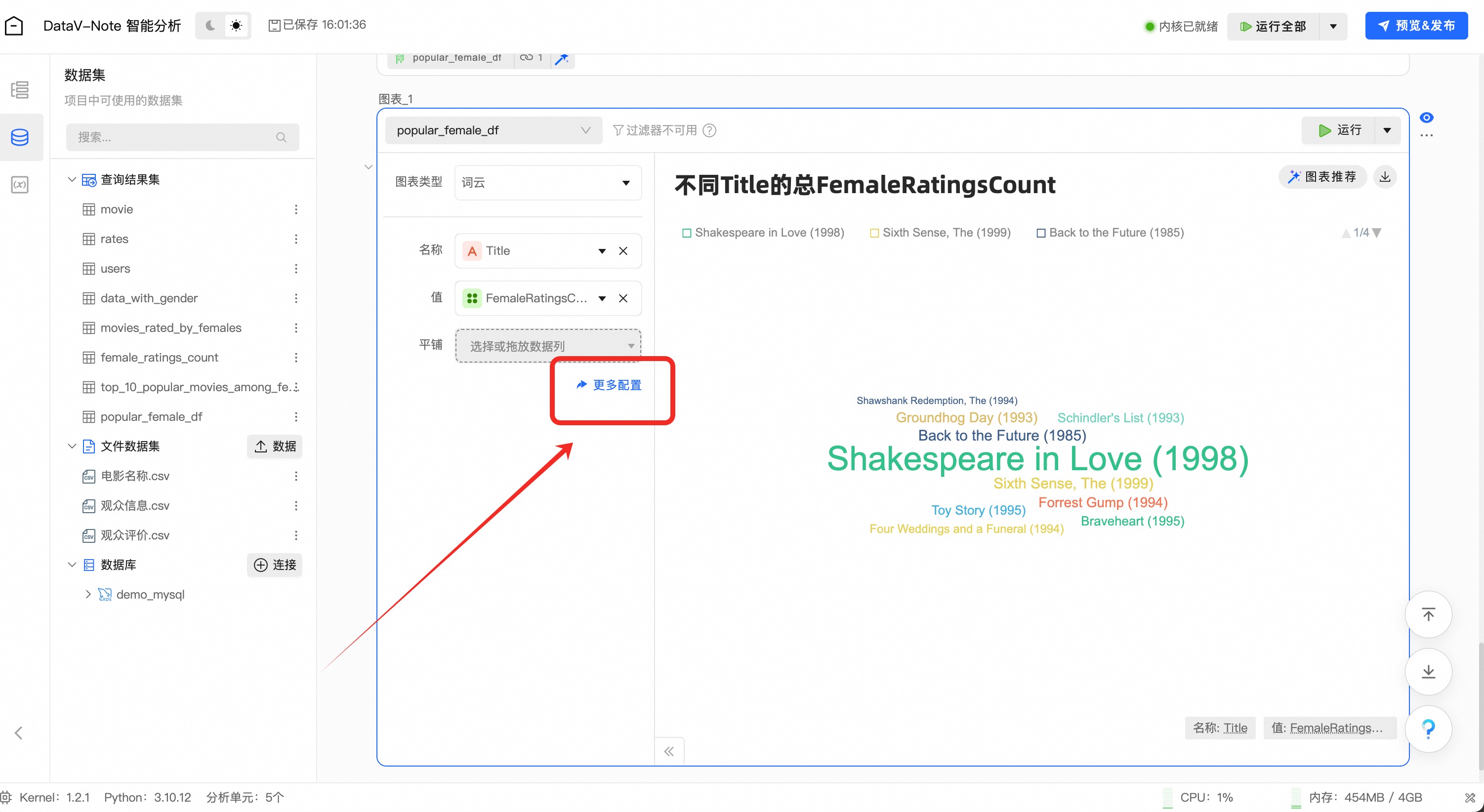
点击【更多配置】,修改标题等图表选项
修改完后,点击左上角返回数据分析界面
分析最受青少年欢迎的电影类型
参考大模型提示词:
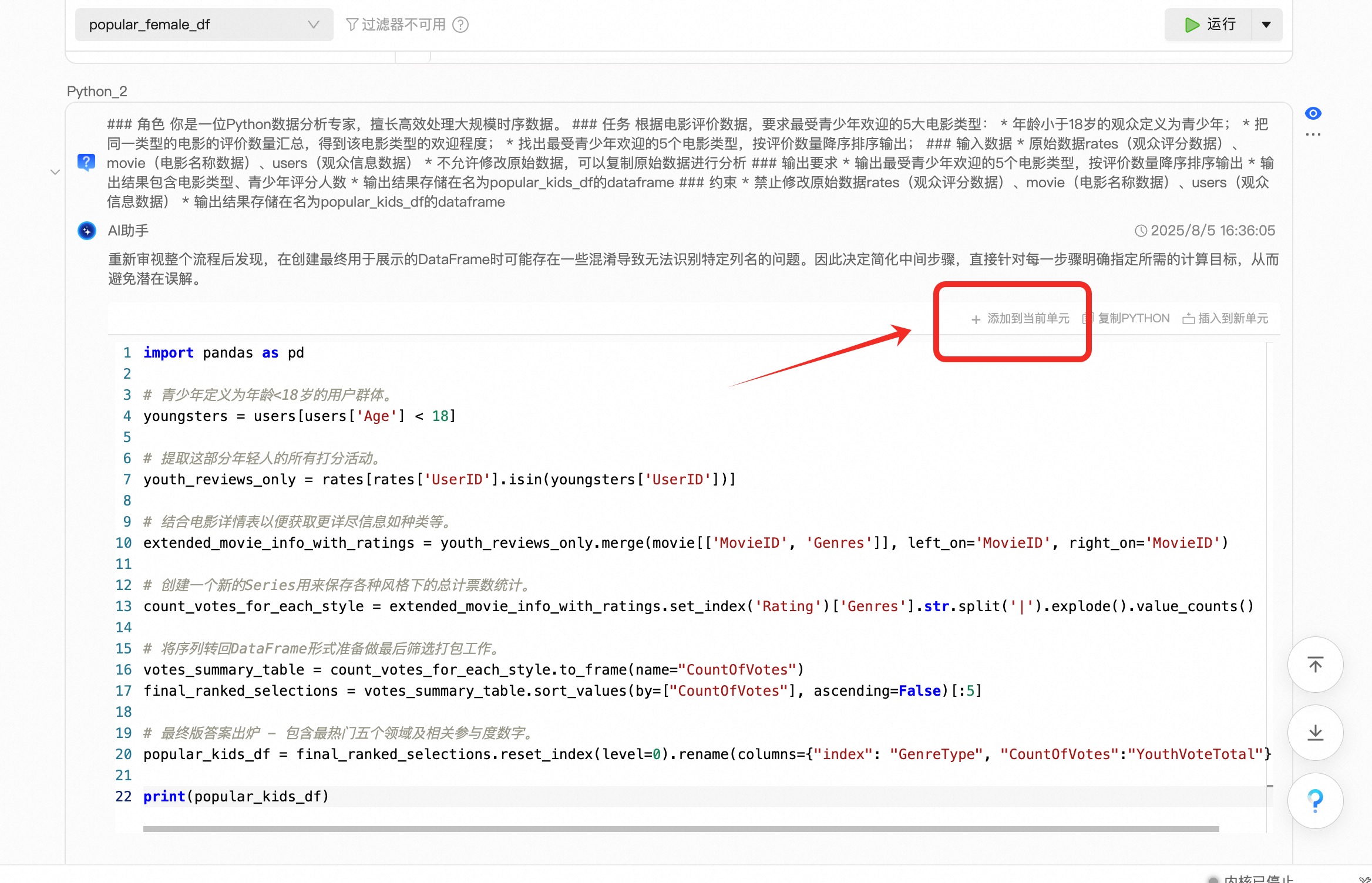
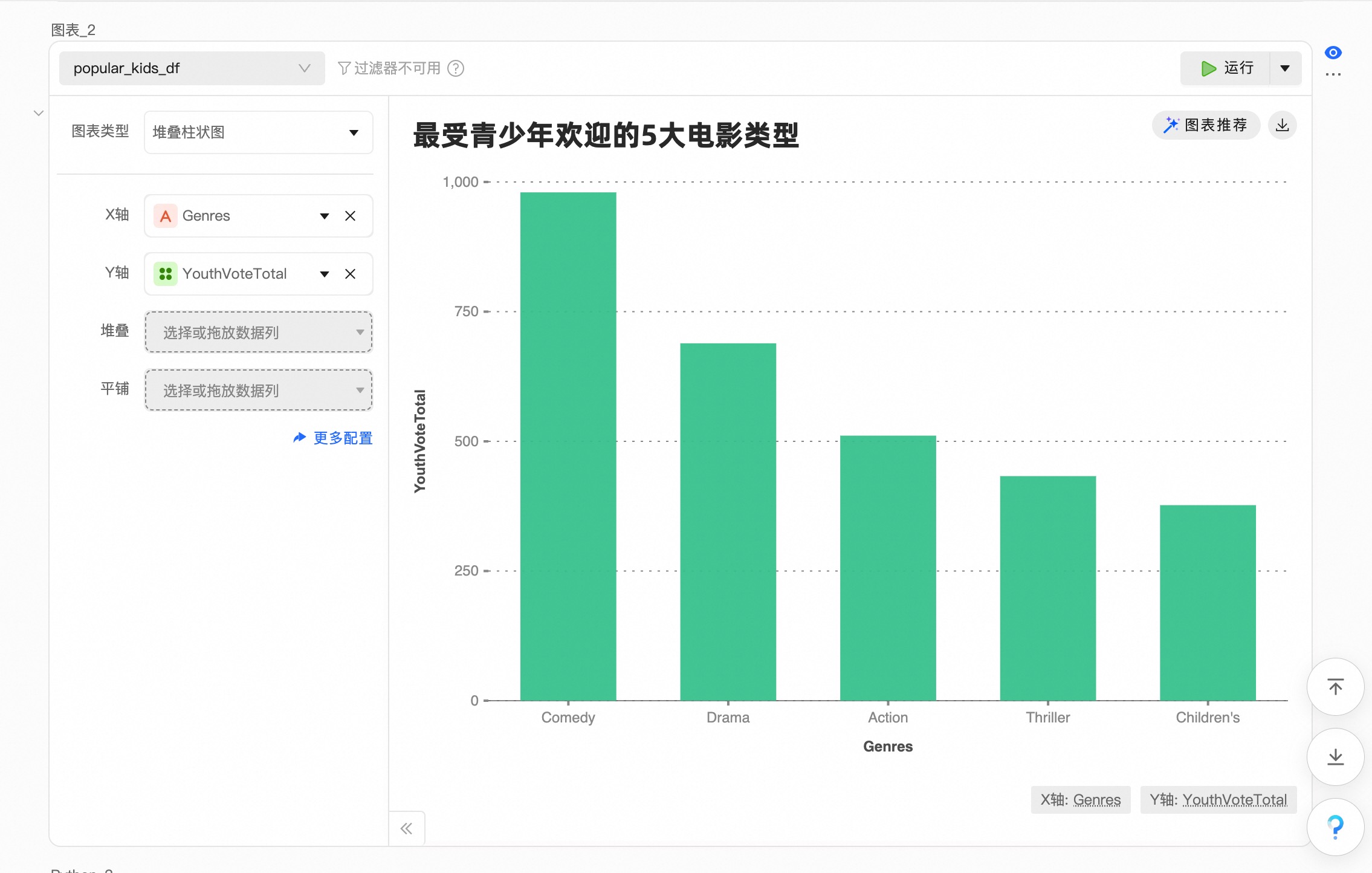
### 角色 你是一位Python数据分析专家,擅长高效处理大规模时序数据。 ### 任务 根据电影评价数据,要求最受青少年欢迎的5大电影类型: * 年龄小于18岁的观众定义为青少年; * 把同一类型的电影的评价数量汇总,得到该电影类型的欢迎程度; * 找出最受青少年欢迎的5个电影类型,按评价数量降序排序输出; ### 输入数据 * 原始数据rates(观众评分数据)、movie(电影名称数据)、users(观众信息数据) * 不允许修改原始数据,可以复制原始数据进行分析 ### 输出要求 * 输出最受青少年欢迎的5个电影类型,按评价数量降序排序输出 * 输出结果包含电影类型、青少年评分人数 * 输出结果存储在名为popular_kids_df的dataframe ### 约束 * 禁止修改原始数据rates(观众评分数据)、movie(电影名称数据)、users(观众信息数据) * 输出结果存储在名为popular_kids_df的dataframe按之前步骤类似,在下方工具栏新建一个python窗口
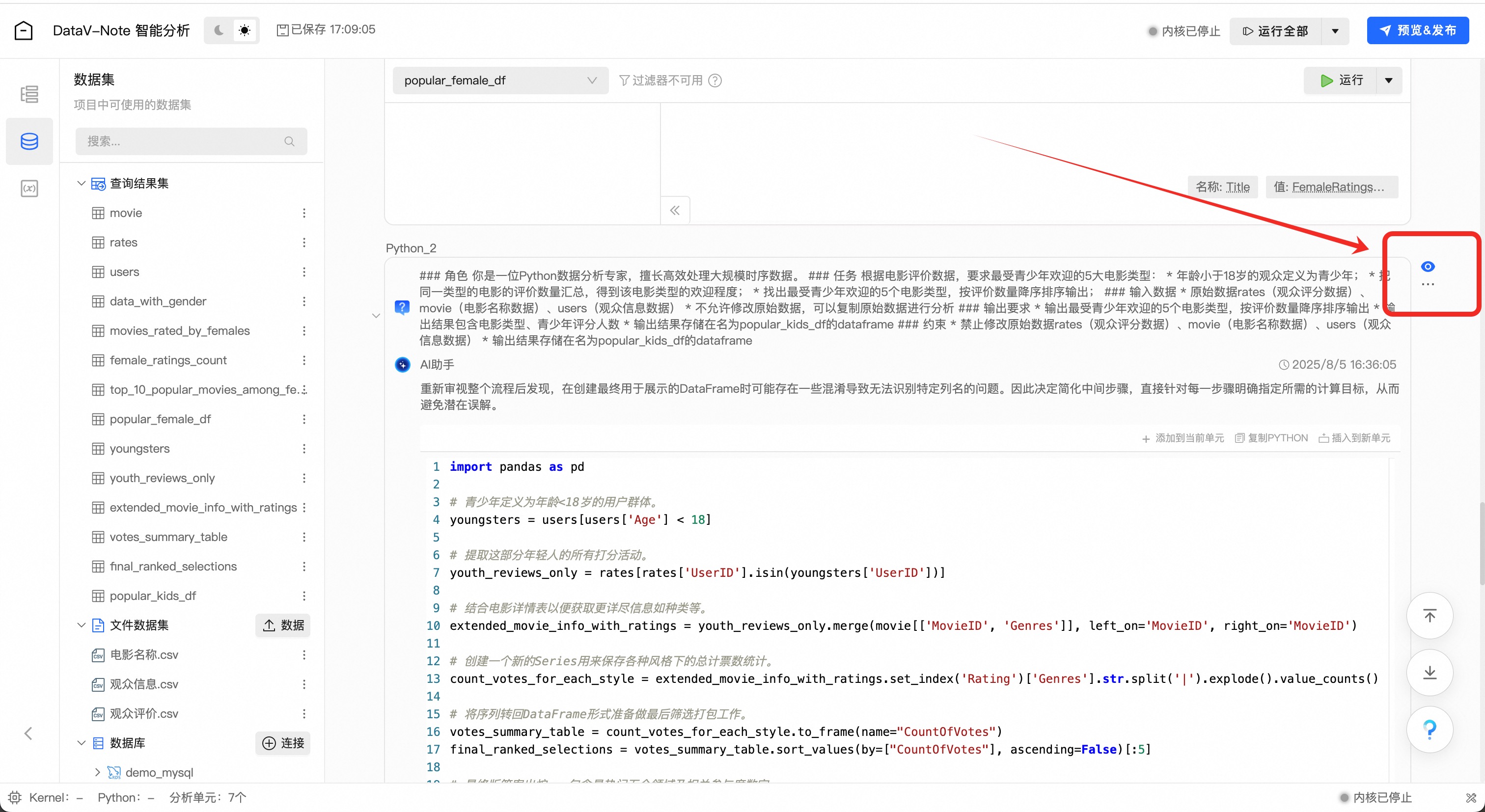
打开【AI助手】,将大模型提示词贴入对话框
大模型生成python数据分析代码之后,点击代码框右上角【添加到当前单元】
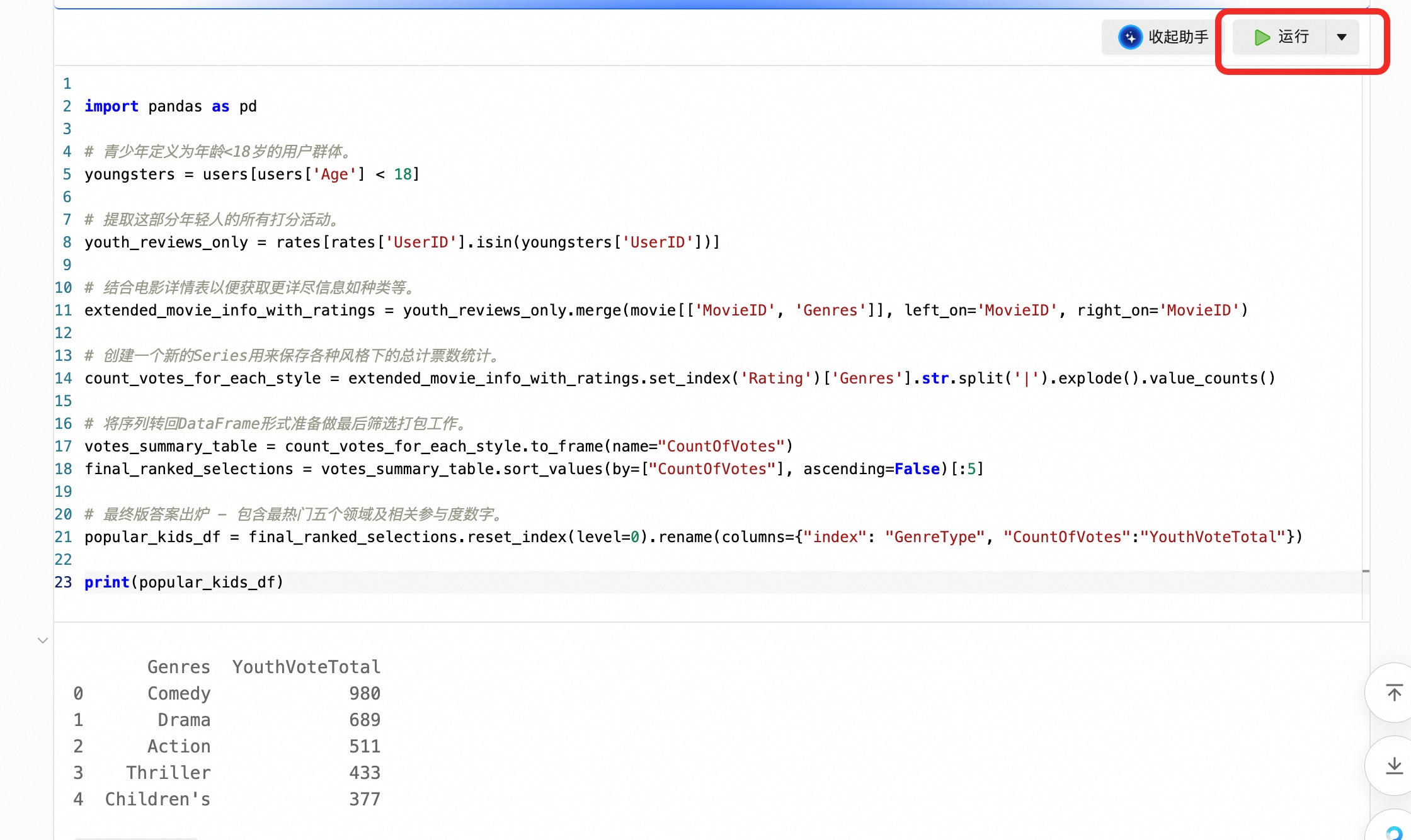
添加代码到编辑框后,点击编辑框右上角的【运行】
运行代码之后,可以看到分析结果已经出现
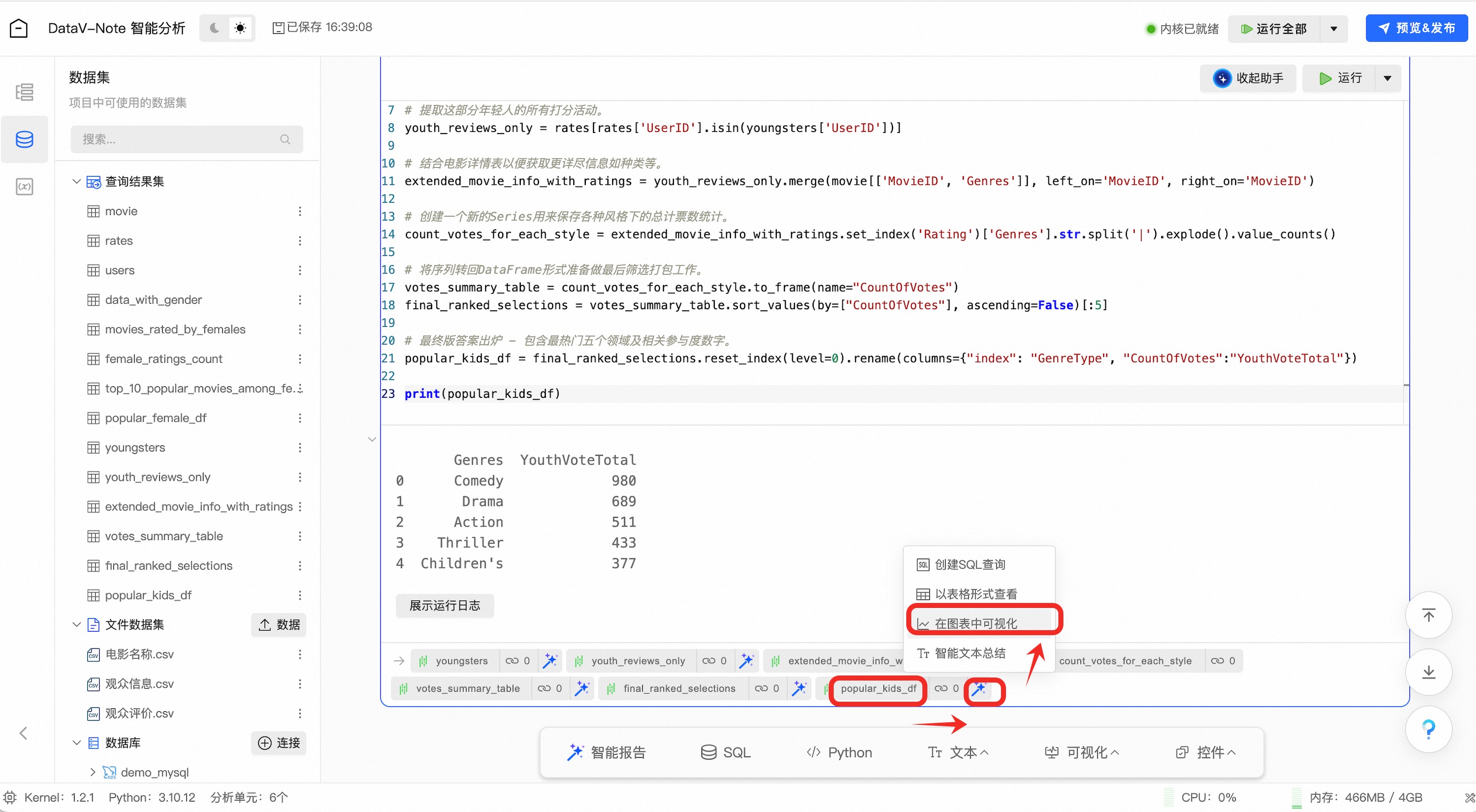
在输出的结果数据【popular_kids_df】数据标签上点击右侧按钮,在弹出的菜单中选择【在图表中可视化】
对图表进行设置,展示数据分析结果
更多数据分析,可以按上述步骤进行探索!
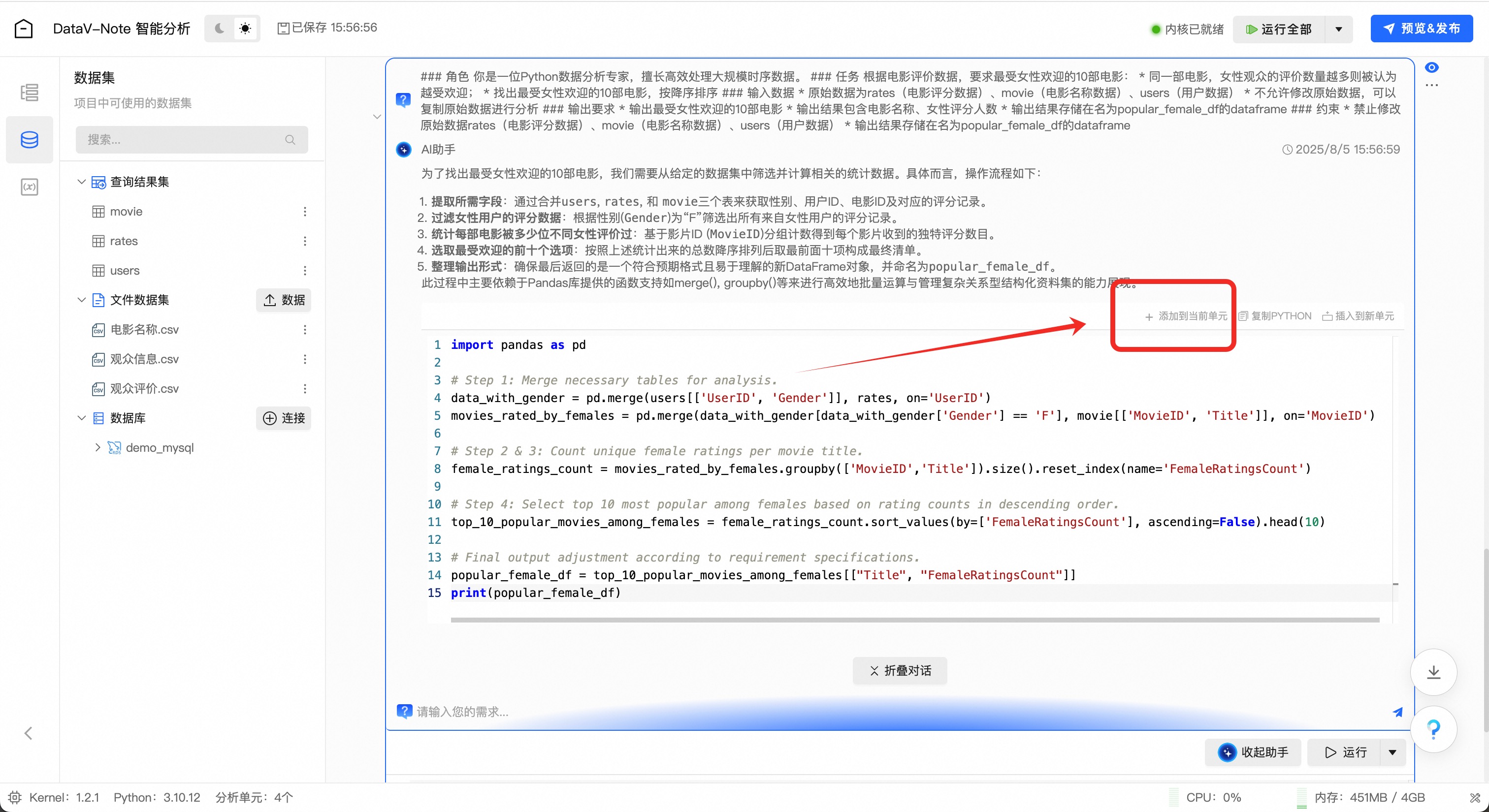


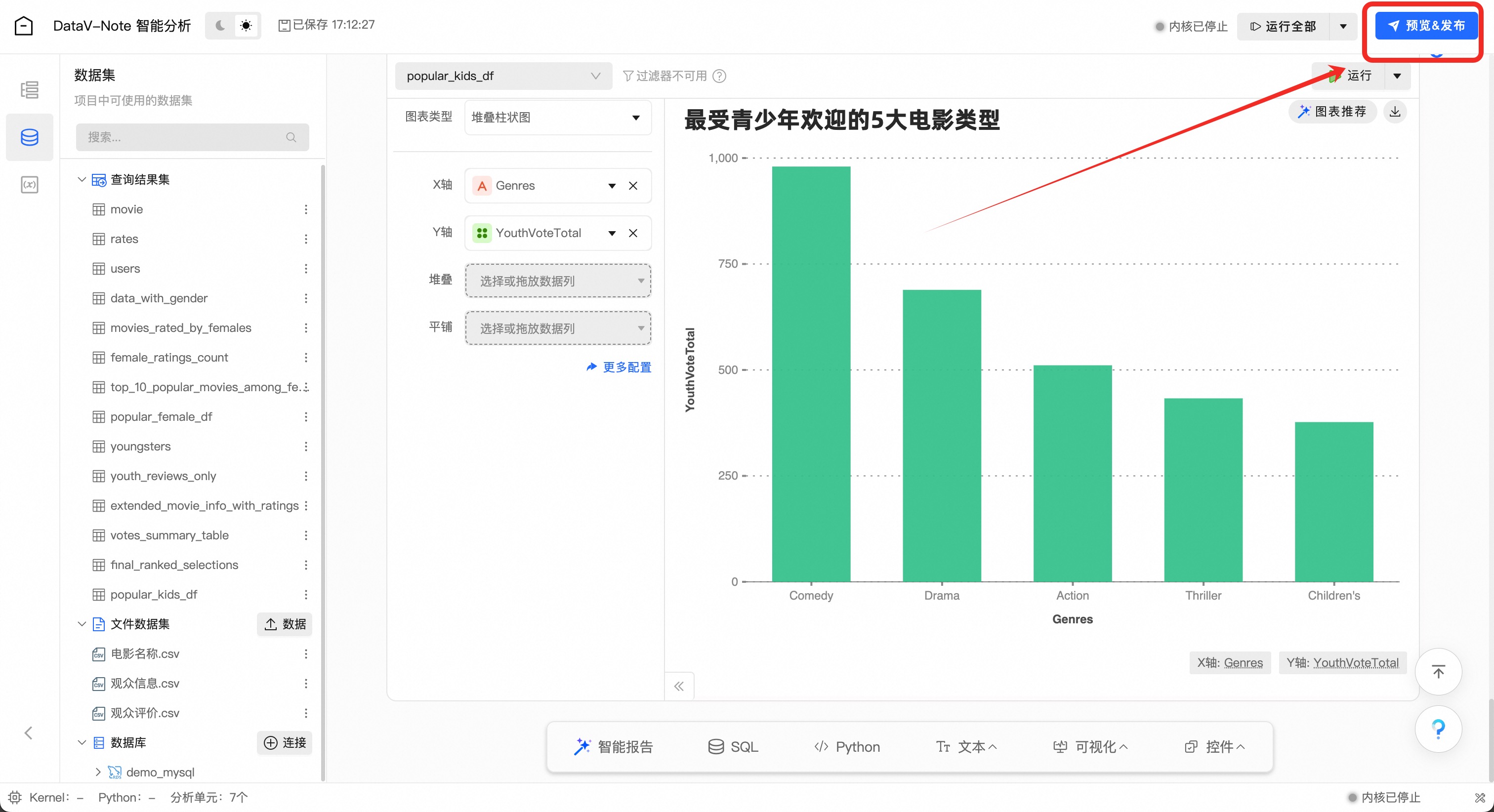
4、数据报告发布
将不需要在报告中展示的内容,点击单元右侧的【眼睛图标】进行隐藏
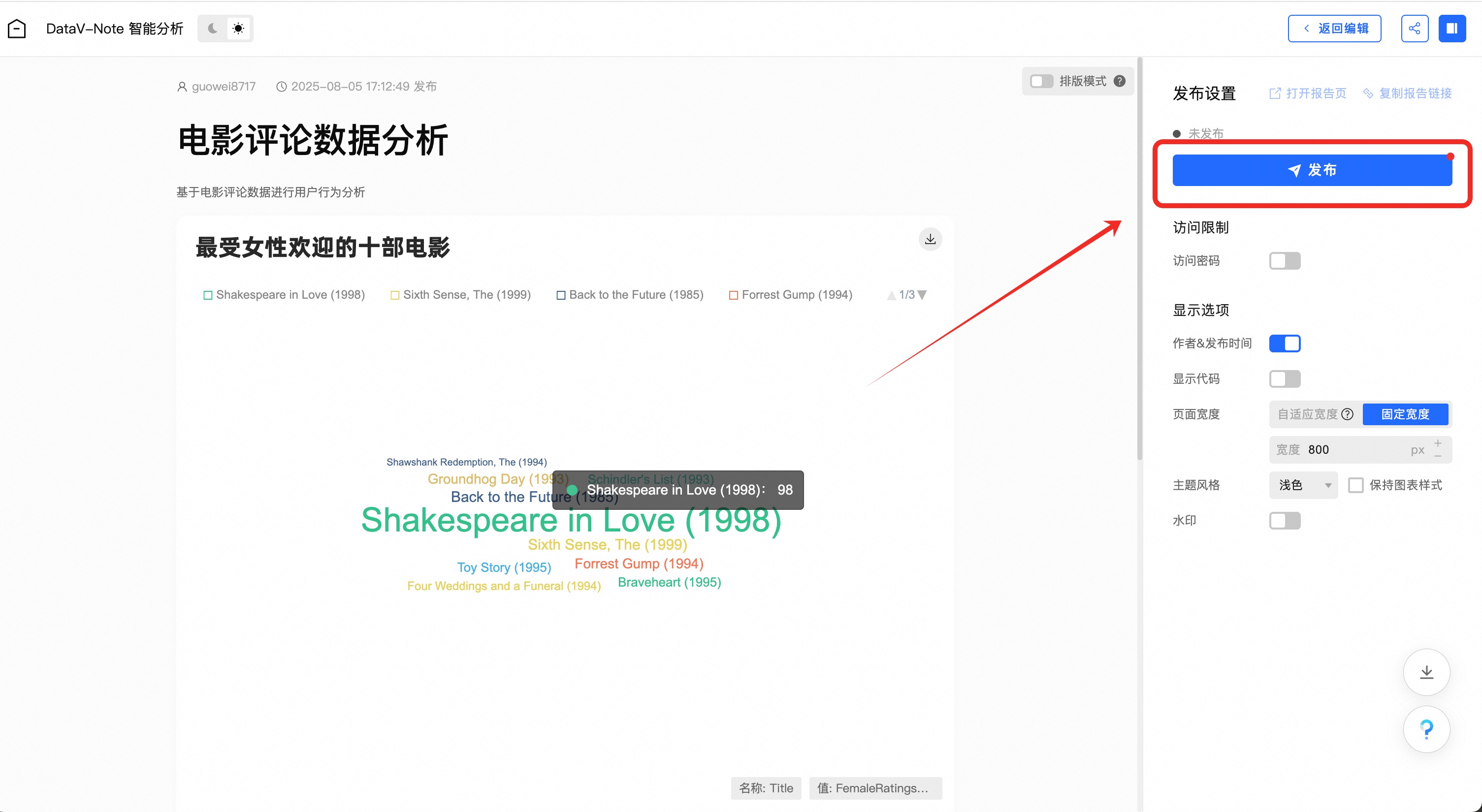
选取数据分析报告需要发布的内容之后,点击右上角的【预览&发布】
对版面、样式等进行设置,点击右侧【发布】即可发布报告并分享
如果需要导出图片或者Office格式,或者通过钉钉/微信分享,点击右上角【导出】,选择所需功能
至此数据分析实验结束!
实验资源释放
实验结束,如以云工开物代金券购买产品,无需退订/释放资源;
关闭实验
在完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 结束实验,关闭页面退出实验