创意的智能引擎 —— AIGC多模态内容创作
探索AI如何助力Q版角色形象设计,让创意无限飞翔 !
实验任务: 部署一个动漫角色形象生成模型并用于Q版角色创意生成
一、实验目标
在云端完成一个“Q版角色创意生成”系统的可用原型,支持从文本生成Q版形象、将角色写真转线稿再上色、对指定部位进行局部重绘与表情/姿态变体;
形成可沉淀的提示配置模板与参数预设,确保输出风格一致、质量可控、来源合规,并能导出适合品牌应用的角色九宫格与小样集。
完成本实验后,学生应能够:
利用阿里云PAI ArtLab 平台的 Stable Diffusion WebUI产出Q版IP动漫角色形象、Q版角色转线稿、线稿上色等知识内容。
通过提示配置模板与 ControlNet 实现可控变体与结构稳定。
确保内容原创合规后,产出可用于品牌化应用的角色九宫格与小样集。
二、实验介绍
动漫IP的角色设计与量产往往需要稳定的风格与高效的变体输出,传统纯手工流程在迭代速度与一致性上存在瓶颈。通过在 PAI ArtLab 平台使用 Stable Diffusion WebUI,将“文生图—图生图—局部重绘—线稿上色—风格约束”串成一条可复用流水线,用可控的提示配置与参数管理角色外观要素(发型、服装、配色、表情、道具),并通过ControlNet/局部蒙版等工具保证结构与姿态的稳定,显著提升创意产出效率。同时,训练与素材必须遵循版权与授权要求,避免对现有受保护IP风格的直接复刻。在本实验中,将利用阿里云PAI ArtLab 平台的Stable Diffusion WebUI构建动漫角色形象生成系统,支持Q版IP动漫角色形象、Q版角色转线稿、线稿上色等功能。
三、相关知识点
Q版动漫角色生成系统通过流程化与参数控制实现高效创意产出,核心知识点包括:
生成流水线编排:在 Stable Diffusion WebUI 中串联“文生图—图生图—局部重绘—线稿提取—上色”等步骤,形成可复用的自动化工作流。
角色要素控制:通过结构化提示配置与固定参数(如种子、LoRA、CFG值)精准管理发型、服装、表情等外观特征,保障风格一致性。
结构与版权约束:利用 ControlNet 或局部蒙版稳定姿态与构图,同时遵循素材授权规范,确保生成内容原创合规、适合品牌应用。
四、实验环境配置
平台与工具:PAI ArtLab平台
硬件要求:联网计算机
软件环境:Web浏览器(建议Chrome)
账户设置:注册阿里云账号并完成高校师生认证;开通PAI ArtLab平台
模型选择:IPDesign3D、AWPainting
五、实验内容与步骤
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
所有实验操作将保留至您的账号,请谨慎操作。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物300元代金券领取。
已通过实名认证且账户余额≥0元。
本实验,预计产生费用:约0.012元(以仅用SDWebUI(共享版)生成一张512*512最简单的图(393kb,1.66sec)为例估算)
本实验产生的费用优先使用优惠券。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
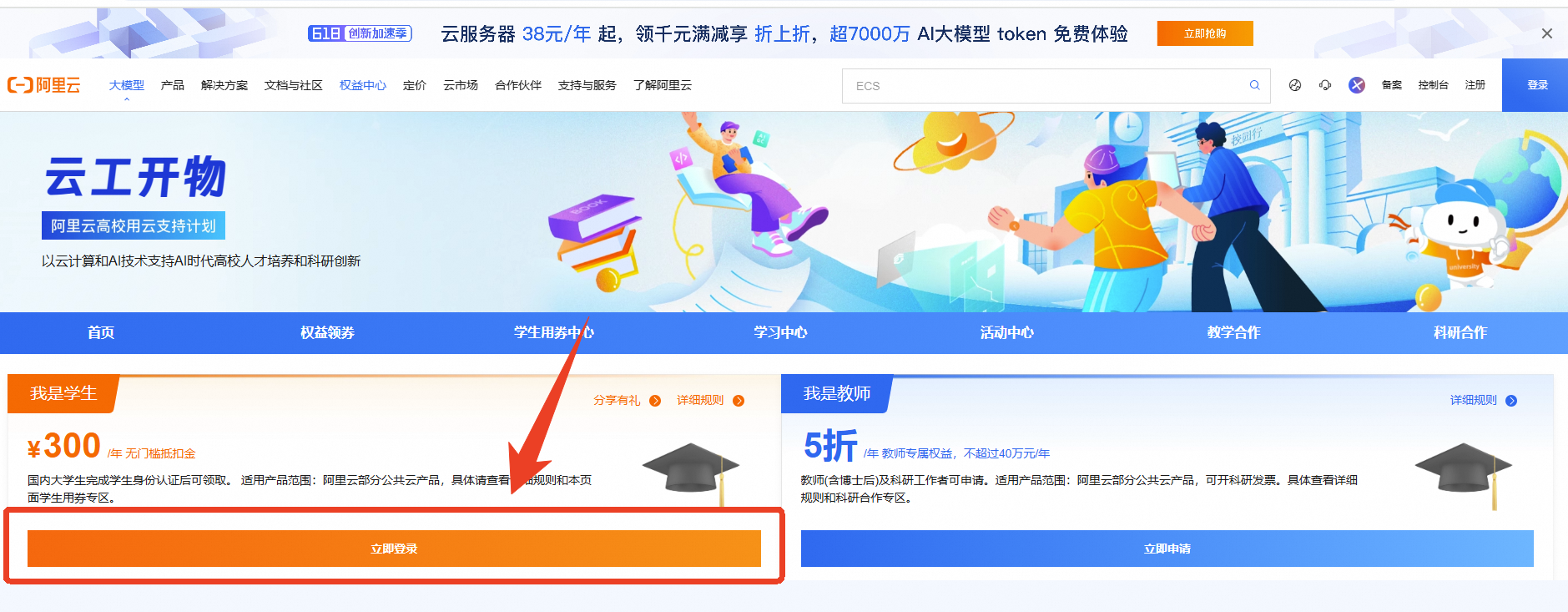
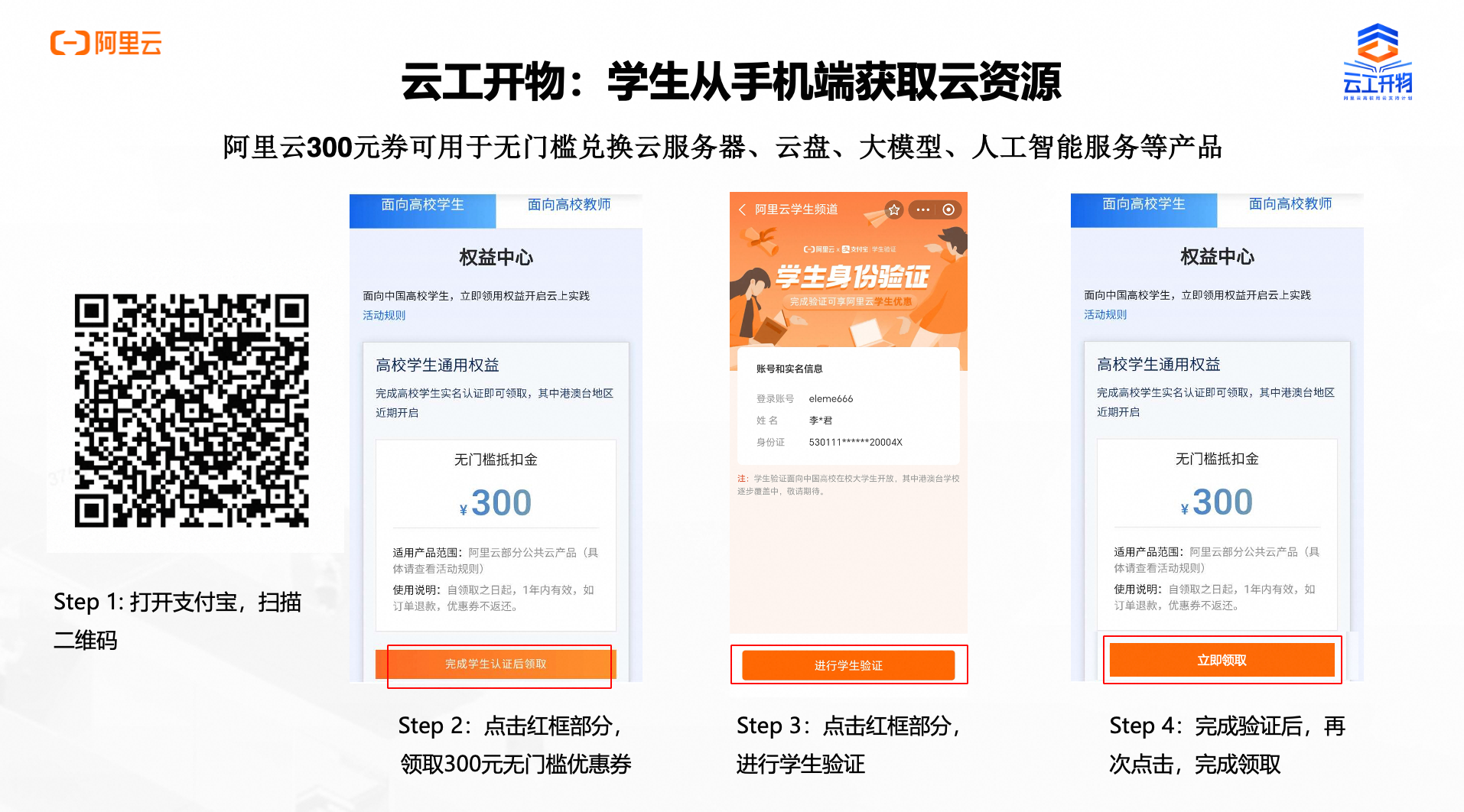
领取专属权益
第一步:点击“进入实操”
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作

第二步:领取300元优惠券
本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
 重要
重要实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。
进入并开通PAI ArtLab并授权
点击访问PAI ArtLab平台
初次进入平台,依次点击两步,完成PAI ArtLab平台开通与授权

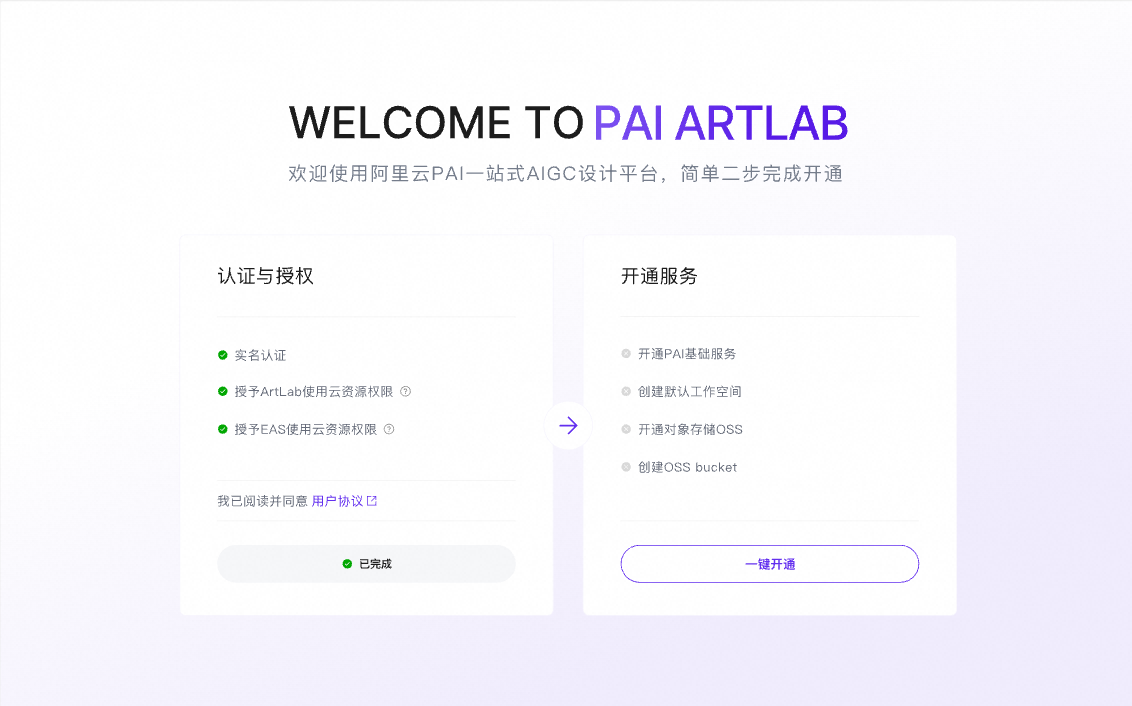
完成PAI ArtLab平台开通与授权,进入到首页

【实验一:Q版形象生成】
一、拉起SD共享版服务
在工具箱页面,选择SD共享版工具(初次拉起需要一些时间请耐心等待)
二、选择图生图模式
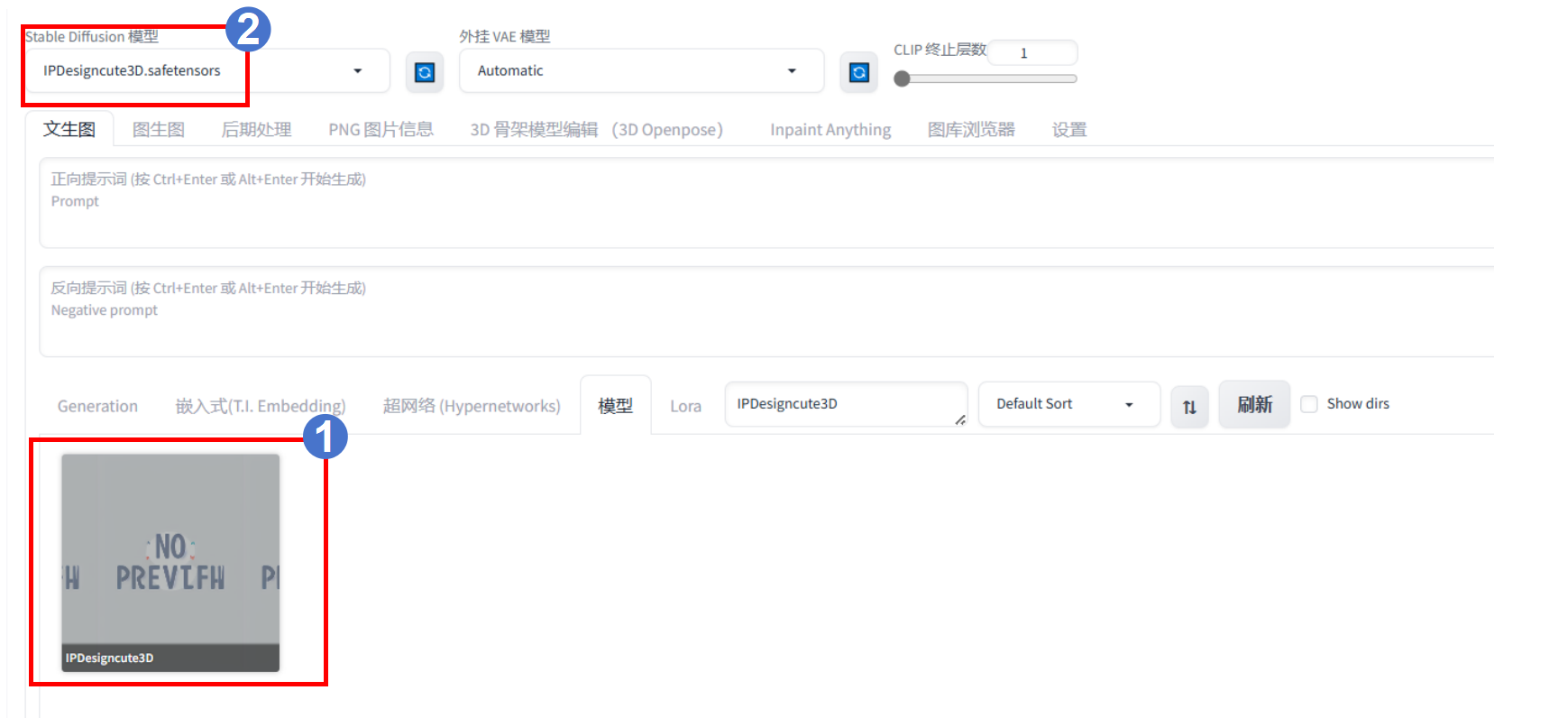
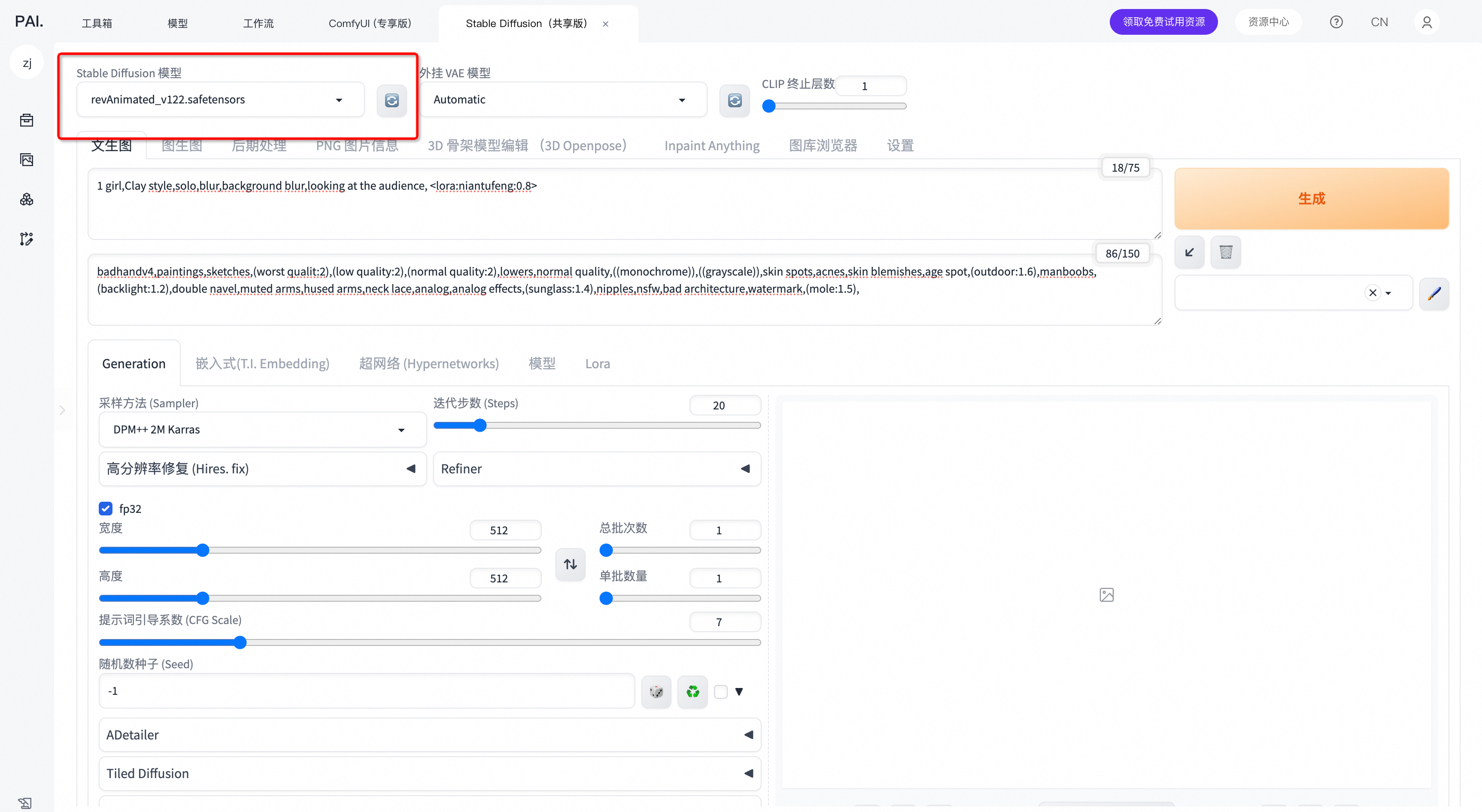
先选择一个Stable Diffusion模型,可在下方模型选项中选择,也可在上方Stable Diffusion模型中选择。
本次实验模型推荐:IPDesign3D | ,再选择文生图
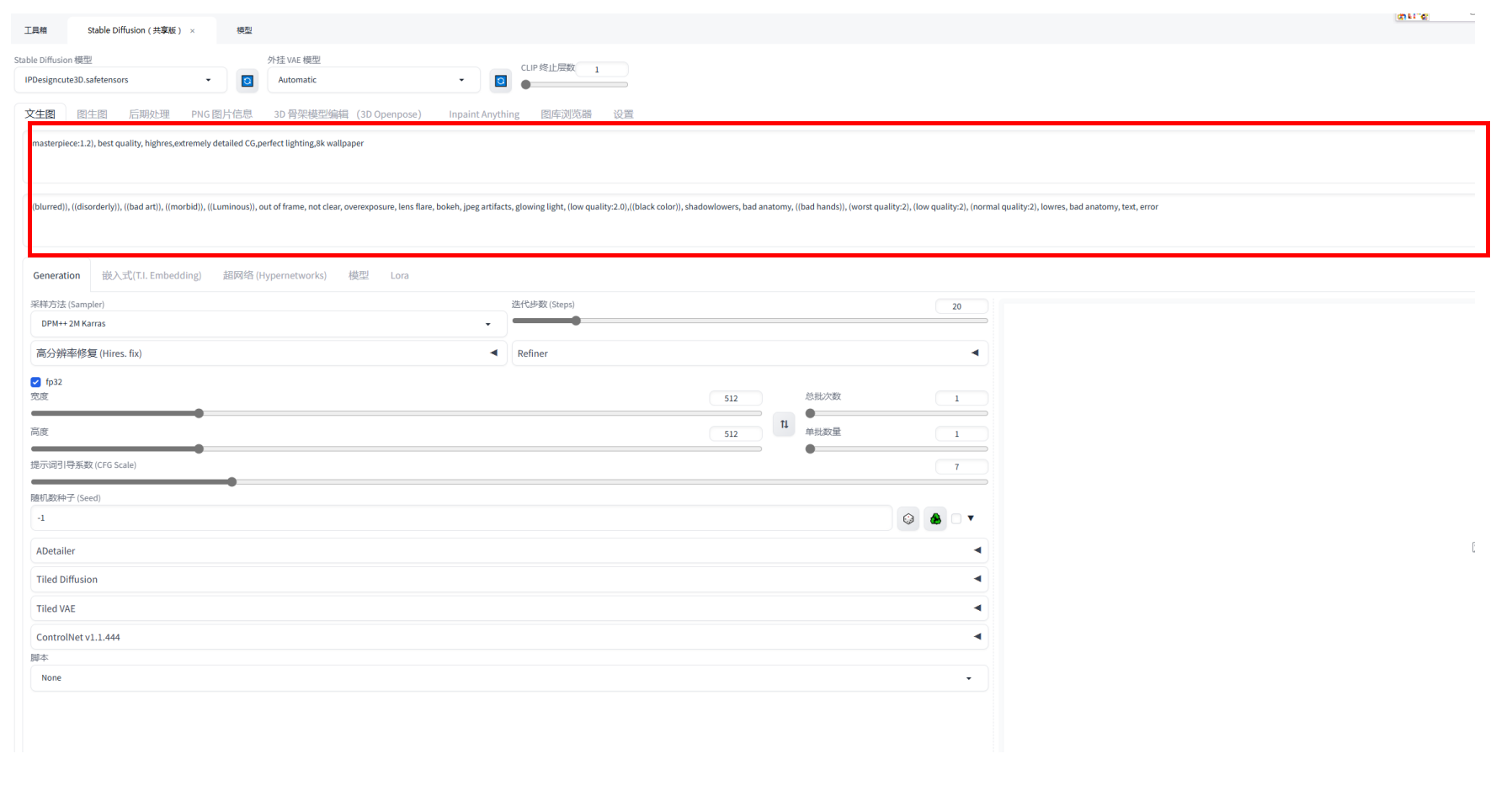
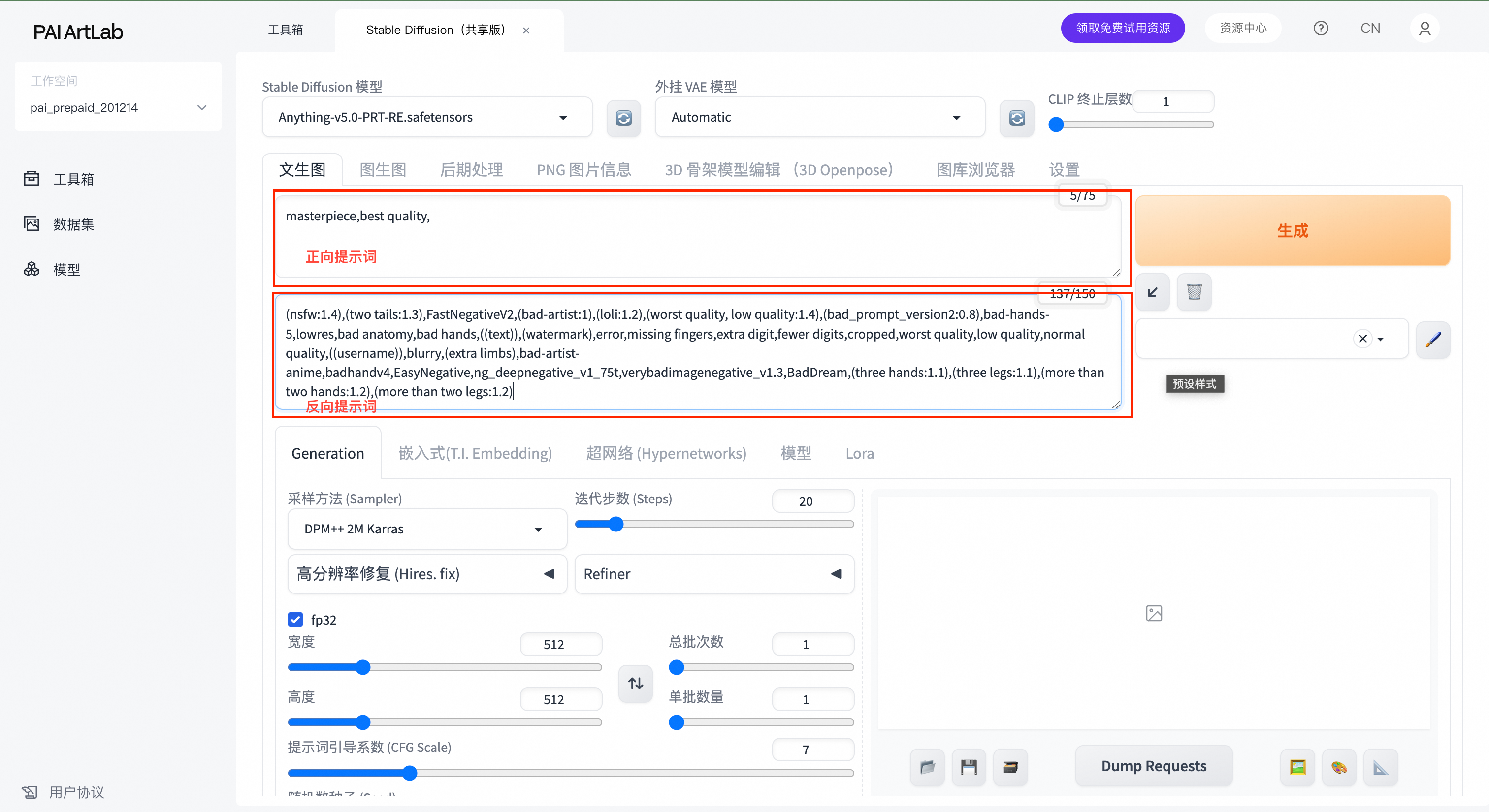
三、在图上标注位置输入提示词
正向提示词(ip形象描述):
可直接复制:cute,child,full body, white background,(masterpiece:1.2), best quality, highres,extremely detailed CG,perfect lighting,8k wallpaper,
反向提示词:
可直接复制:((blurred)), ((disorderly)), ((bad art)), ((morbid)), ((Luminous)), out of frame, not clear, overexposure, lens flare, bokeh, jpeg artifacts, glowing light, (low quality:2.0),((black color)), shadowlowers, bad anatomy, ((bad hands)), (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, text, error
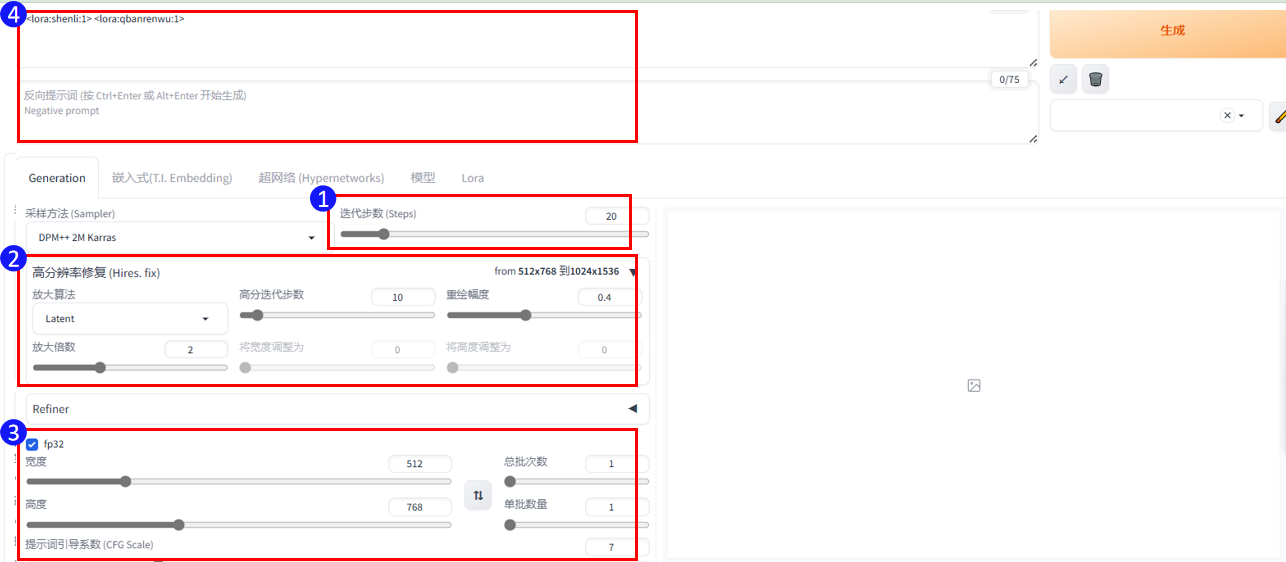
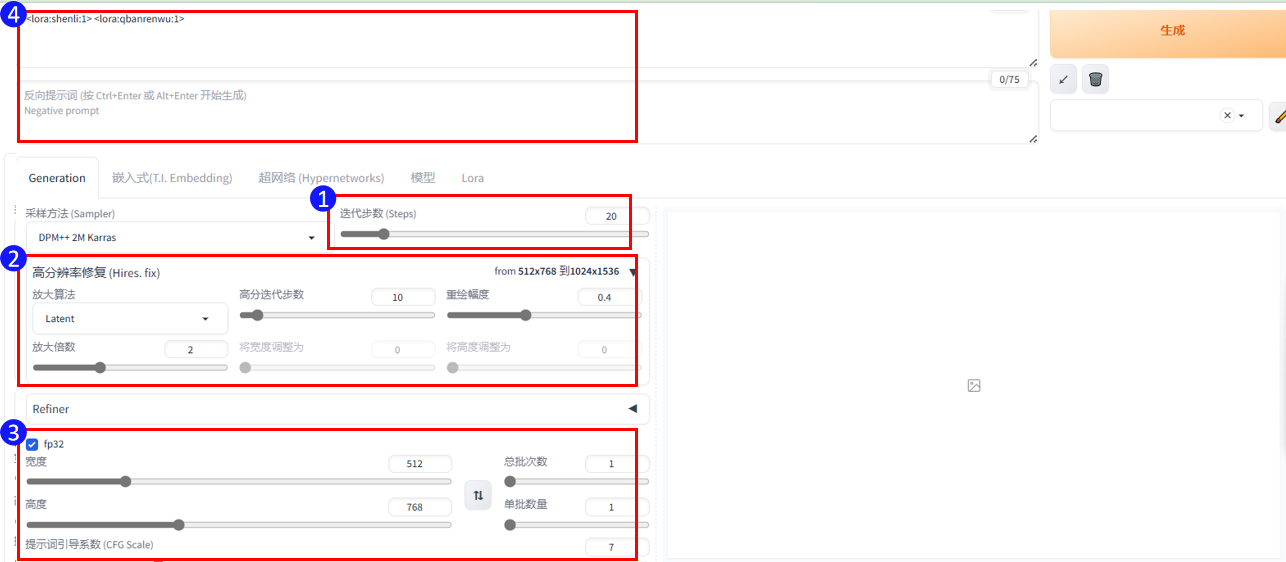
四、选择迭代步数和图片尺寸
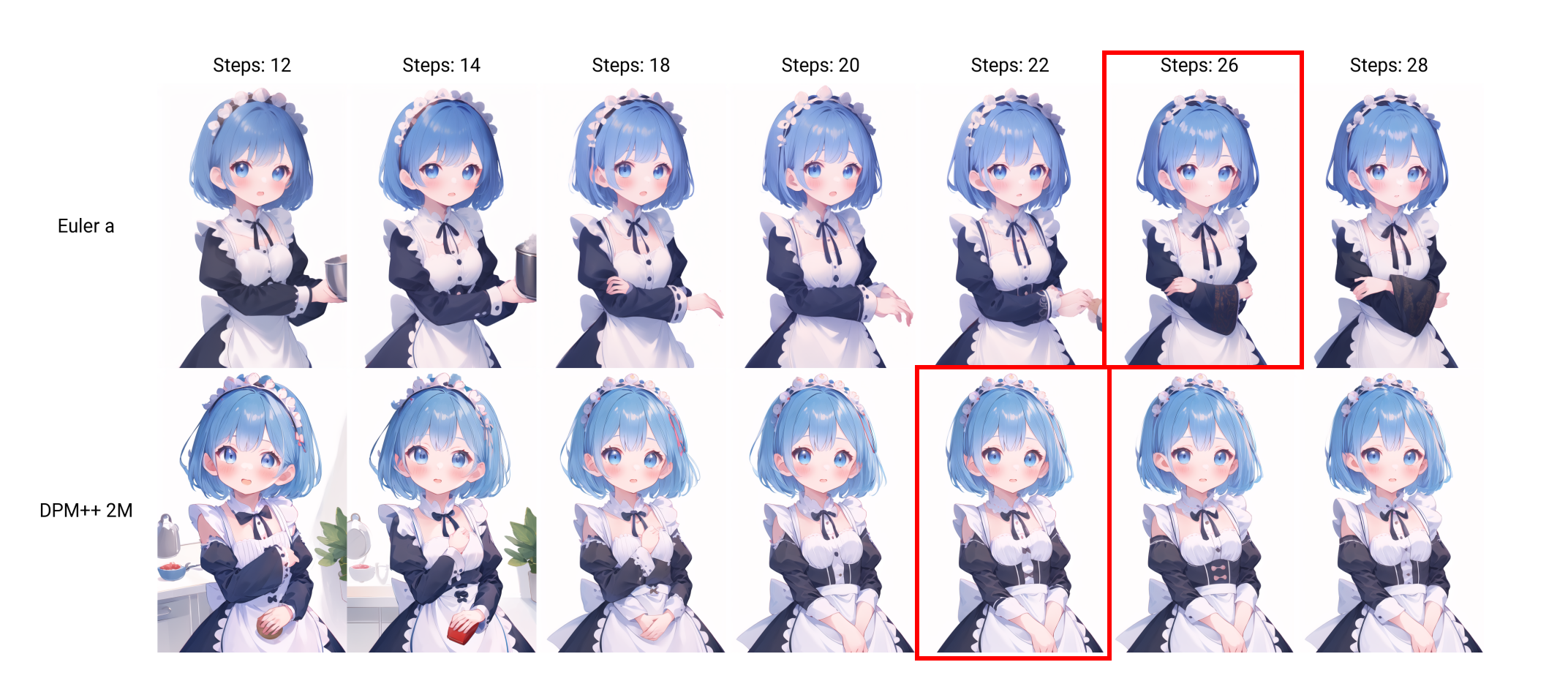
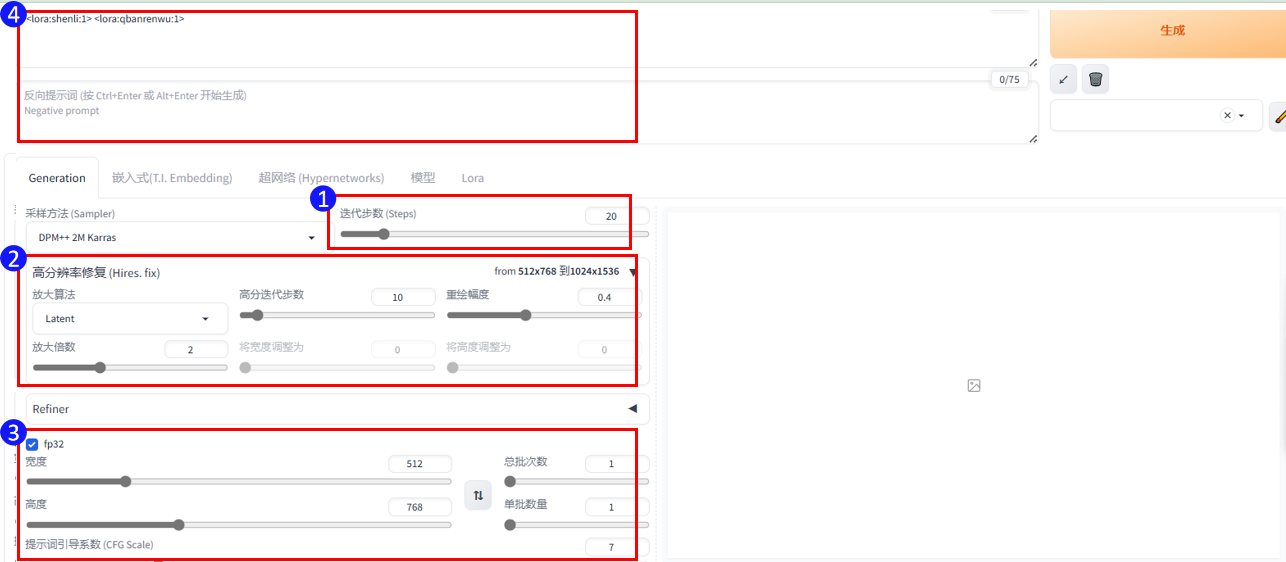
迭代部署:根据选择的大模型而定,下图为通过xyz测试得出的该模型合适的步数为22,采样方法DPM++ 2M或者Euler a(后续实验以Euler a为例展开)有着不同的风格,如果选择其他的模型请根据模型简介提示或者使用xyz测试进行步数测试
图片尺寸:采用512*768,生图后可通过高清修复进行尺寸扩展。
打开高清修复,放大算法选择Latent,高分迭代步数11(是迭代步数的一半最佳),重绘幅度0.4
填写准备好的白底黑边线稿的图片尺寸,尺寸如果大于1024,需要等比缩小填写
填写提示词引导系数(见第三步的提示词内容)
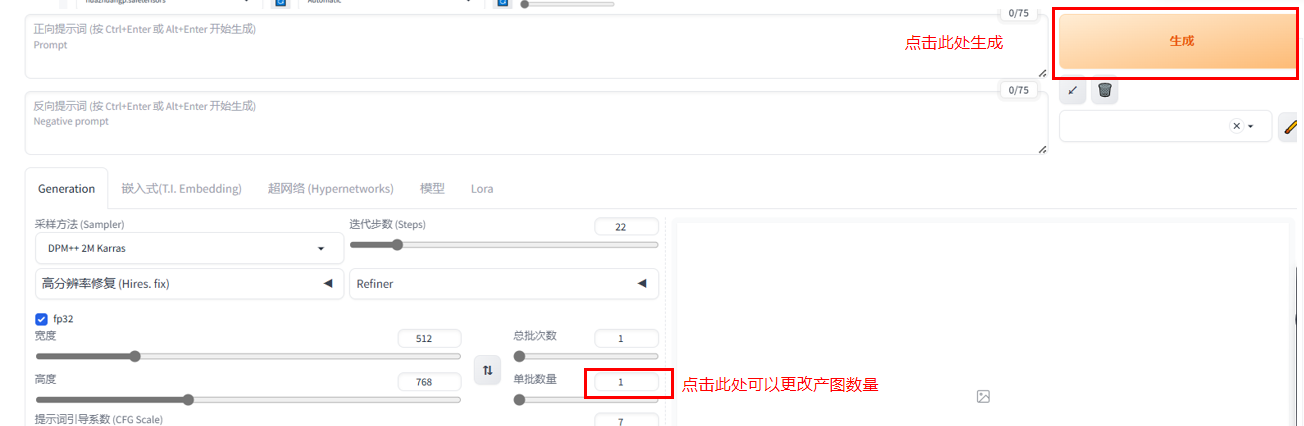
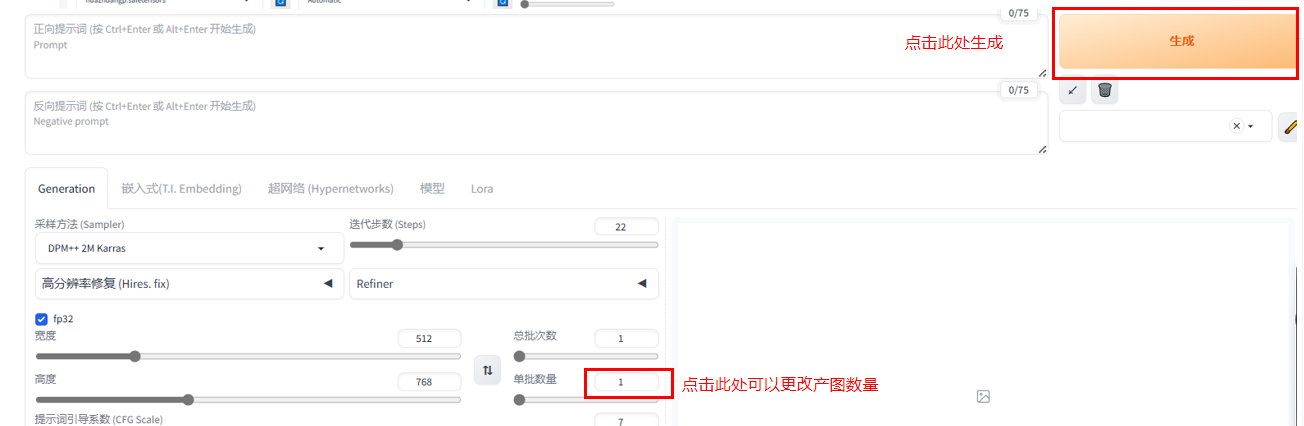
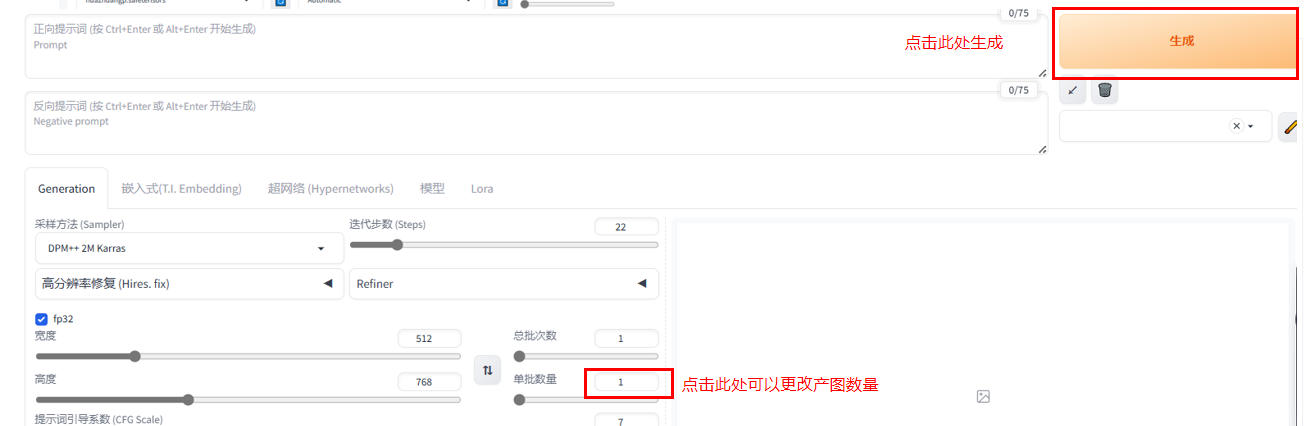
五、图片生成
在确认完上述内容后,可通过改变单次数量增加生图的数量。
点击生成
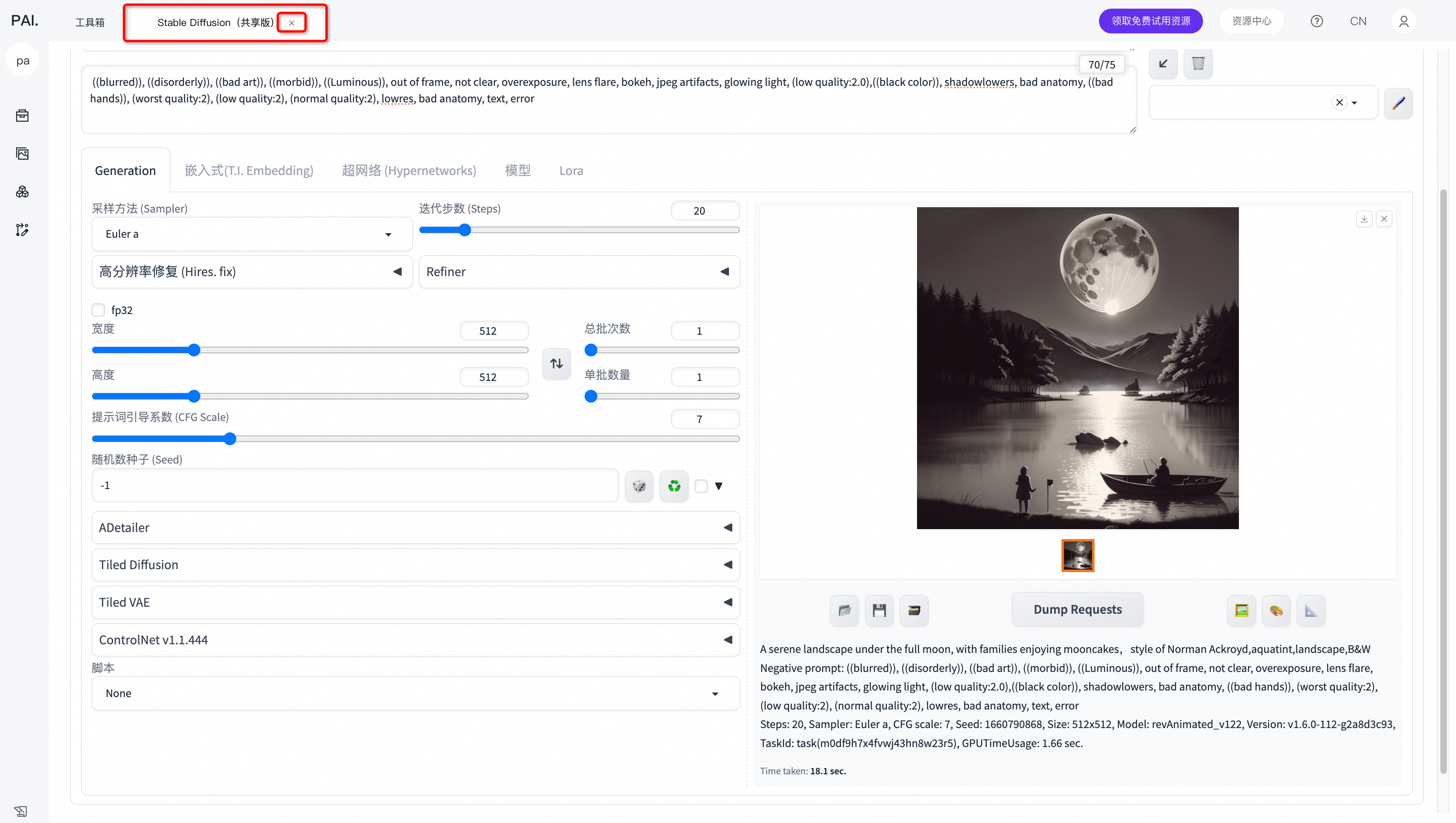
六、效果展示
提示词:
形象描述(动物+女孩ip):rabbit, ((child)),long hair, solo, dress, star hair ornament, star \(symbol\), bangs, gradient hair, artist name, gradient, smile, closed mouth, 加上固定关键词,详情见第三步的提示词内容
形象描述(动漫ip):cute,child,Pixar style,MG IP,1 girl,long hair,solo,Hatsune Miku,twintails,smile,ahoge,looking at viewer,very long aqua hair,aqua eyes,black jacket,sleeveless,加上固定关键词,详情见第三步的提示词内容(头两张加上关键词:hand on face,squatting,)
形象描述(可爱动物ip):Enhance art style,Peacock,Illustration cartoon cute art style,cute pet,cute,HD,No logo icon text,Gentle art style,((masterpiece)),original,rich details,extremely exquisite,加上固定关键词以及描述词,下图分别加上关键词dog,Peacock,详情见第三步的提示词内容(去掉第三步的提示词内容中的第二个关键词child)
【实验二:特定动漫/二次元角色形象生成】
一、拉起SD共享版服务
在工具箱页面,选择SD共享版工具(初次拉起需要一些时间请耐心等待)
二、选择图生图模式
先选择一个Stable Diffusion模型,模型推荐:AWPainting|,再选择文生图
三、模型说明
Q版动漫形象是在关键词描述正确的基础上加入Lora模型使得其更符合原作本身。
本次实验大模型:万象熔炉|Anything V5/Ink(大模型)、Lora模型:Rem (Re:Zero)
- 说明
该lora模型仅仅适用于这一个动漫角色生成,如需定向生成其他动漫角色,请于网络自行搜索
如果需要生成该动漫角色,需要复制以下触发词:
正向关键词:
((cute little people)),((lovely girl)),moe,highres,((Dress conservatively)),sharp focus,sleeve-off,((intricate details)),[highly detailed],1girl,blue hair,short hair,maid uniform,maid headdress,upper_body,
反向关键词:
duplicated, disfugured, deformed, poorly drawn, low quality eyes, border, comic, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, (worst quality, low quality:1.4), interlocked fingers, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, pixels, nsfw, sexy,
四、在图上标注位置输入提示词
正向提示词(动漫形象描述):
可直接复制:(masterpiece:1.2), best quality, highres,extremely detailed CG,perfect lighting,8k wallpaper
反向提示词:
可直接复制:((blurred)), ((disorderly)), ((bad art)), ((morbid)), ((Luminous)), out of frame, not clear, overexposure, lens flare, bokeh, jpeg artifacts, glowing light, (low quality:2.0),((black color)), shadowlowers, bad anatomy, ((bad hands)), (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, text, error
五、返回Stable Diffusion,选择Lora模型
点击Lora
选择Lora模型:Rem (Re:Zero) ,和角色定向模型:CJ_儿童绘本卡通插画
在正向提示中会出现相对应的lora模型关键词以及权重,及 <lora:Rem_RE Zero:1>、<lora:CJ儿童绘本卡通插画 :1>
输入触发模型关键词:chibi
六、参数选择
迭代部署:根据选择的大模型和Lora模型而定,下图为通过xyz测试得出的该模型Euler a为简约q版形象、DPM++2M采样下内容更详细。其采样迭代步数推荐分别为:26、22
打开高清修复,放大算法选择4x-UltraSharp,高分迭代步数11-13(是迭代步数的一半),重绘幅度0.4
填写准备好的白底黑边线稿的图片尺寸,尺寸如果大于1024,需要等比缩小填写
填写提示词引导系数(见第四步的提示词内容)
七、图片生成
在确认完上述内容后,可通过改变单次数量增加生图的数量。
点击生成
八、效果展示
以下效果均用上述模型配合其他模型使用产出
【实验三:线稿上色】
一、准备线稿
准备线稿图片,以下线稿为AI生成
二、拉起SD共享版服务
在工具箱页面,选择SD共享版工具(初次拉起需要一些时间请耐心等待)
三、选择图生图模式
先选择一个Stable Diffusion模型
模型推荐:AWPainting 在线稿生成当中大模型和Lora模型没有限定,根据自身需求去选择,生成的图片会根据模型选择风格而定,再选择图生图
四、在图上标注位置输入提示词
正向提示词(风格上色描述):
可直接复制:(masterpiece:1.2), best quality, highres,extremely detailed CG,perfect lighting,8k wallpaper
反向提示词:
可直接复制:((blurred)), ((disorderly)), ((bad art)), ((morbid)), ((Luminous)), out of frame, not clear, overexposure, lens flare, bokeh, jpeg artifacts, glowing light, (low quality:2.0),((black color)), shadowlowers, bad anatomy, ((bad hands)), (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, text, error
五、返回Stable Diffusion,选择Lora模型
点击Lora
选择Lora模型:Rem (Re:Zero) ,和角色定向模型
在正向提示中会出现相对应的lora模型关键词以及权重,及 <lora模型:1>
六、参数选择
迭代部署:20,根据选择的大模型和Lora模型而定,如果选择其他的模型请根据模型简介提示或者使用xyz测试进行步数测试
打开高清修复,放大算法选择4x-UltraSharp,高分迭代步数10(是迭代步数的一半),重绘幅度0.4
填写准备好的白底黑边线稿的图片尺寸,尺寸如果大于1024,需要等比缩小填写
填写提示词引导系数(见第四步的提示词内容)
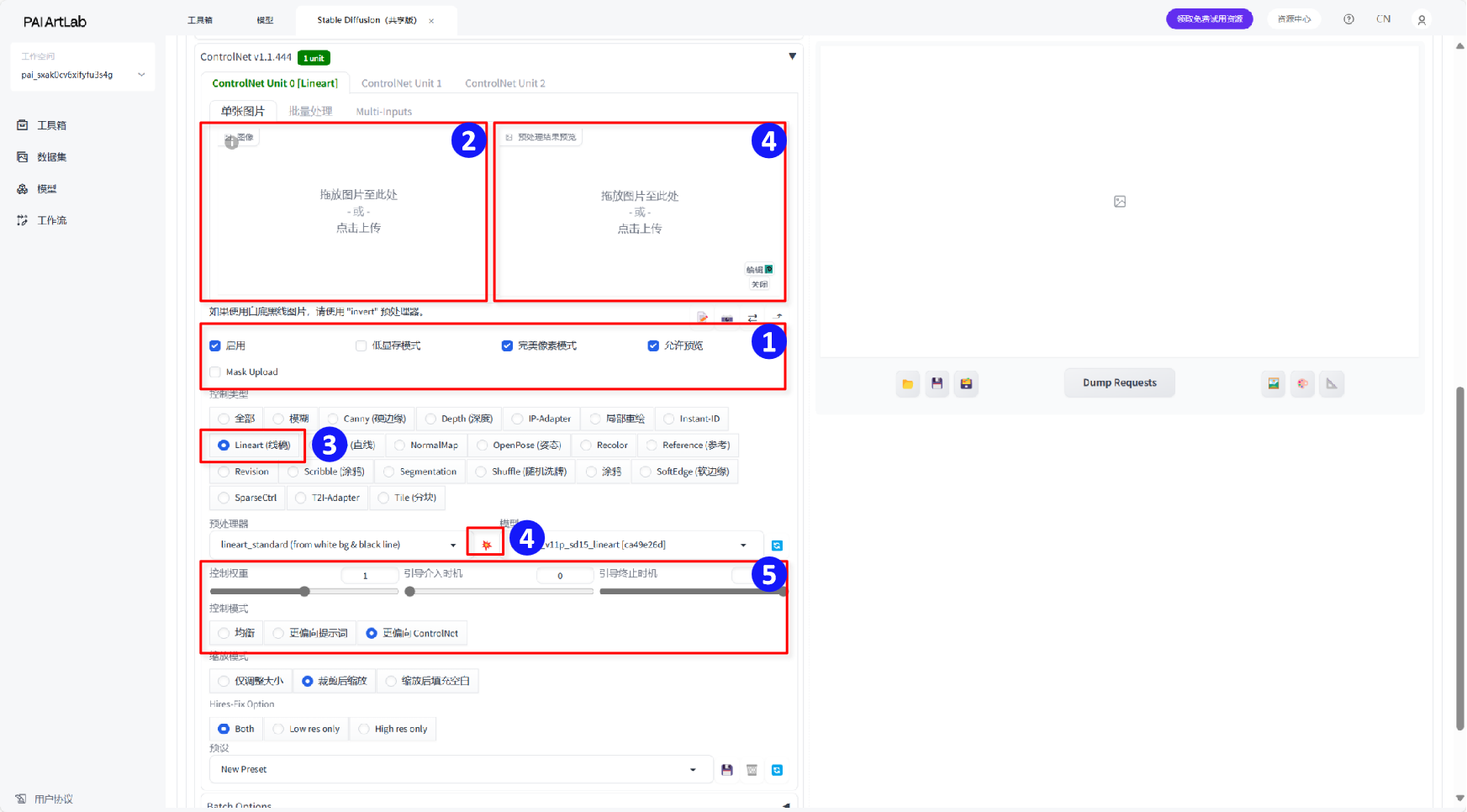
七、打开启用ControlNet
勾选启用、完美像素模式、允许预览
上传准备好的白底黑边线稿
控制类型选择Lineart(线稿)
点击爆炸图标即可预览线稿处理效果
八、图片生成
在确认完上述内容后,可通过改变单次数量增加生图的数量。
点击生成
九、生成效果
清理资源
如果无需继续使用工具,您可以按照以下操作步骤停止或删除工具。
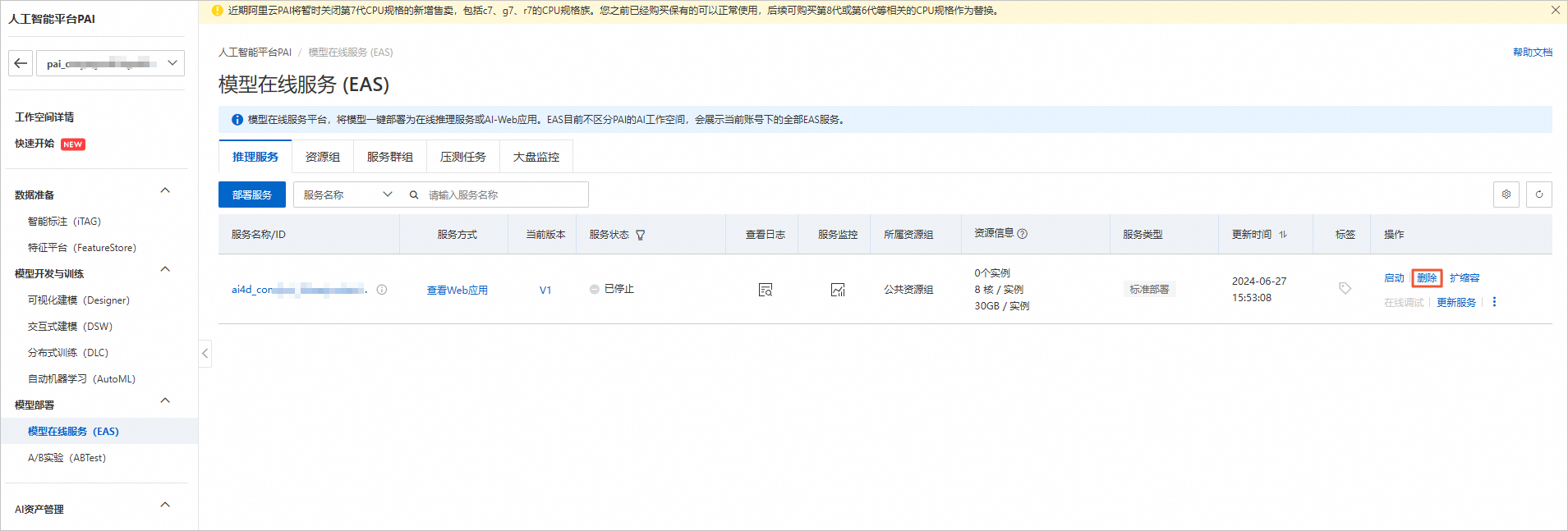
在PAI ArtLab控制台中,关闭Stable Diffusion(共享版)页签,EAS模型服务将会停止,不会继续收费。
在页面左上方,选择模型所在地域,本实验EAS实例所在地域为华东2(上海)
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击默认工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏中单击模型在线服务(EAS)。在模型在线服务(EAS)页面,找到目标服务。单击其右侧操作列下的删除
如果需要继续使用Stable Diffusion(共享版),请随时关注账号扣费情况,避免模型会因欠费而被自动停止。


















六、结果与验证
预期输出:生成风格一致的Q版角色图、线稿及上色结果,并记录提示配置与参数。
验证方法:抽检图像结构稳定性、风格一致性与提示配置响应准确性。
此外,需人工审核原创性与关键特征表达,规避版权风险,确保流程可控可复用。
七、拓展与思考
如何组合多工具提升角色生成效率与多样性?
此架构能否应用于更广泛的动漫内容创作领域或跨媒体项目?
如何应对提示模糊、风格漂移与版权合规风险?
八、常见问题
多智能体协作系统实验的常见问题与解决方案表:
常见问题 | 解决方案 |
风格不一致 | 使用相同的模型和提示配置,确保风格统一。 |
线稿失真 | 优化ControlNet参数,必要时手动修正。 |
上色错误 | 应用蒙版控制上色区域,利用参考图调整颜色。 |
版权问题 | 严格使用授权资料,避免受保护IP的直接复制。 |
九、实验报告要求
基于实验学生应提交完整的实验报告,要求包含以下内容:
实验目的与任务描述;
实验环境配置截图;
尝试不同模型与提示配置,进行生成结果对比;
对“七、拓展与思考”问题的回答;
实验总结与个人反思。
十、关闭实验
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验