
PCCL: NCCL APIs及环境变量支持情况(v1.7)
1. 概述
本文档主要总结PCCL 和 NCCL 2.22.3 在 APIs 与环境变量方面的差异,并注明相应的版本信息。另外也对模型训练、推理场景下最佳环境变量配置的推荐做法。
2. APIs 汇总
2.1 NCCL APIs 兼容支持列表
API 名称 | NCCL | PCCL | PCCL 支持版本 | 备注 |
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | Since PCCL 1.4.0 | ||
✅ | ✅ | Since PCCL 1.4.0 | ||
✅ | ✅ | Since PCCL 1.4.0 | Only support 'splitShare=0' & 'blocking' configs from pcclConfig_t on 1.4.0, Fully enabled and support on 1.5.0 | |
✅ | ✅ | Since PCCL 1.4.0 | API compatible only, doesn't take effect due to HW limitation | |
✅ | ✅ | Since PCCL 1.4.0 | API compatible only, doesn't take effect due to HW limitation | |
✅ | ✅ | Since PCCL 1.4.0 | Fallback to cudaMalloc() due to HW limitation | |
✅ | ✅ | Since PCCL 1.4.0 | Fallback to cudaFree() due to HW limitation | |
✅ | ✅ | since PCCL 1.7.0 | ||
✅ | ✅ | since PCCL 1.7.0 | ||
✅ | ✅ | since PCCL 1.7.0 | ||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
ncclResetDebugInit | ✅ | ❌ | Deprecated and will be removed in the future |
2.2 PCCL扩展API列表
N/A
3. 环境变量汇总
3.1 NCCL 环境变量兼容支持列表
Note: 统计内容来自于 NCCL 官方文档, NCCL 代码里面还有少数环境变量并没有在官方文档提及, 暂不列入统计.
环境变量名称 | NCCL | PCCL | PCCL 支持版本 | 备注 |
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
NCCL_IB_PKEY | ✅ | ✅ | ||
NCCL_IB_USE_INLINE | ✅ | ✅ | ||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
✅ | ✅ | |||
NCCL_MIN_P2P_NCHANNELS | ✅ | ✅ | ||
NCCL_MAX_P2P_NCHANNELS | ✅ | ✅ | ||
NCCL_TOPO_DUMP_FILE_RANK | ✅ | ✅ | ||
NCCL_GRAPH_DUMP_FILE_RANK | ✅ | ✅ | ||
NCCL_PROXY_DUMP_SIGNAL | ✅ | ✅ | ||
NCCL_GDRCOPY_SYNC_ENABLE | ✅ | ✅ | ||
NCCL_GDRCOPY_FLUSH_ENABLE | ✅ | ✅ | ||
NCCL_GDR_FLUSH_DISABLE | ✅ | ✅ | ||
NCCL_LL128_NTHREADS | ✅ | ✅ | ||
NCCL_P2P_READ_ENABLE | ✅ | ✅ | ||
✅ | ✅ | Since PCCL 1.4.0 | ||
✅ | ✅ | Since PCCL 1.4.0 | ||
✅ | ✅ | Since PCCL 1.4.0 | ||
✅ | ✅ | Since PCCL 1.4.0 | ||
NCCL_REPORT_CONNECT_PROGRESS | ✅ | ✅ | Since PCCL 1.4.0 | |
✅ | ✅ | Since PCCL 1.4.3 | ||
✅ | ✅ | Since PCCL 1.5.0 | ||
NCCL_U2MM_LOG_LEVEL | ❌ | ✅ | Since PCCL 1.5.0 | EIC 网卡平台的支持 |
NCCL_P2P_USE_CUDA_MEMCPY | ✅ | ✅ | Since PCCL 1.5.0 | |
NCCL_COMM_SPLIT_SHARE_RESOURCES | ✅ | ✅ | Since PCCL 1.5.0 | |
✅ | ✅ | Since PCCL 1.6.0 | ||
NCCL_GDRCOPY_ENABLE | ✅ | ✅ | Since PCCL 1.6.1 | |
NCCL_GDRCOPY_FIFO_ENABLE | ✅ | ✅ | Since PCCL 1.6.1 | |
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
NCCL_WIN_STRIDE | ✅ | ✅ | Since PCCL 1.7.0 | |
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
NCCL_CREATE_THREAD_CONTEXT | ✅ | ✅ | Since PCCL 1.7.0 | |
✅ | ✅ | Since PCCL 1.7.0 | ||
✅ | ✅ | Since PCCL 1.7.0 | ||
NCCL_SYM_CTAS | ✅ | ✅ | Since PCCL 1.7.0 | |
NCCL_SYM_KERNEL | ✅ | ✅ | Since PCCL 1.7.0 | |
✅ | ❌ | |||
NCCL_NVB_PRECONNECT | ✅ | ❌ | ||
NCCL_GRAPH_HELPER_DISABLE | ✅ | ❌ | ||
✅ | ❌ | |||
✅ | ❌ | |||
NCCL_IGNORE_DISABLED_P2P | ✅ | ❌ | ||
NCCL_NCHANNELS_PER_NET_PEER | ✅ | ❌ | ||
✅ | ❌ | |||
✅ | ❌ | |||
NCCL_SHM_USE_CUDA_MEMCPY | ✅ | ❌ | ||
NCCL_SHM_MEMCPY_MODE | ✅ | ❌ | ||
NCCL_SHM_LOCALITY | ✅ | ❌ | ||
✅ | ❌ | |||
NCCL_NET_DISABLE_INTRA | ✅ | ❌ | ||
✅ | ❌ | |||
✅ | ❌ | |||
NCCL_NET_FORCE_FLUSH | ✅ | ❌ | ||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
NCCL_P2P_PCI_CHUNKSIZE | ✅ | ❌ | ||
NCCL_P2P_NVL_CHUNKSIZE | ✅ | ❌ | ||
NCCL_PROXY_APPEND_BATCH_SIZE | ✅ | ❌ | ||
NCCL_PROGRESS_APPENDOP_FREQ | ✅ | ❌ | ||
NCCL_L1_SHARED_MEMORY_CARVEOUT | ✅ | ❌ | ||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
NCCL_NVLS_NCHANNELS | ✅ | ❌ | ||
NCCL_NET_OVERHEAD | ✅ | ❌ | ||
✅ | ❌ | since nccl 2.23 | ||
NCCL_IB_MERGE_VFS | ✅ | ❌ | ||
NCCL_CONNECT_ROUND_MAX_PEERS | ✅ | ❌ | ||
✅ | ❌ | since nccl 2.20 | ||
✅ | ❌ | since nccl 2.21 | ||
NCCL_NVLS_CHUNKSIZE | ✅ | ❌ | ||
NCCL_CHUNK_SIZE | ✅ | ❌ | ||
NCCL_NVLSTREE_MAX_CHUNKSIZE | ✅ | ❌ | ||
NCCL_UNPACK_DOUBLE_NCHANNELS | ✅ | ❌ | ||
NCCL_RUNTIME_CONNECT | ✅ | ❌ | since nccl 2.22 | |
NCCL_WORK_FIFO_BYTES | ✅ | ❌ | ||
NCCL_WORK_ARGS_BYTES | ✅ | ❌ | ||
NCCL_IB_ROUTABLE_FLID_GID_INDEX | ✅ | ❌ | ||
NCCL_IB_FIFO_TC | ✅ | ❌ | since nccl 2.22 | |
✅ | ❌ | since nccl 2.23 | ||
✅ | ❌ | since nccl 2.23 | ||
✅ | ❌ | since nccl 2.23 | ||
✅ | ❌ | since nccl 2.23 | ||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ | |||
✅ | ❌ |
3.2 PCCL扩展环境变量列表
PCCL特有的环境变量,我们采用PCCL_开头的名称定义以便于区分。
环境变量名称 | PCCL 支持版本 | 备注 |
PCCL_ICN_SCALE_OUT_DISABLE | ||
PCCL_NET_BYPASS | ||
PCCL_FORCE_ICN_SCALE_OUT | ||
PCCL_DISABLE_ADJUST_SYSTEM | ||
PCCL_DUMP_CONN_INFO | ||
PCCL_CU_MASK | ||
PCCL_BLOCKS_PER_FC_LINK | ||
PCCL_P2P_NCHANNELS_FACTOR_NPATHS | ||
PCCL_DISABLE_ABORT | ||
PCCL_CHANNEL_SHUFFLE | ||
PCCL_DUMP_WORK_ELEMS | Dump each active ncclWork's ncclWorkElem information within the channel | |
PCCL_REVERSE_RING_INTERLEAVE | ||
PCCL_ONEBATCH_PER_CE | ||
PCCL_IB_DISABLE_ACC_BONDING_PORT | ||
PCCL_BOOTSTRAP_DEBUG | ||
PCCL_USE_STATIC_LAUNCH_GRID | ||
PCCL_RING_DUMP_FILE | ||
PCCL_DISABLE_TORUS_GRAPH | ||
PCCL_CE_MASK | ||
PCCL_GRAPH_TREE_PATTERN | ||
PCCL_PROXY_DUMP_FILE | ||
PCCL_DISP_MODE | ||
PCCL_QUADRUPLE_CHANNELS | ||
PCCL_PER_COMM_HASH_DEBUG_FILE | ||
PCCL_COMM_DUMP_SIGNAL | ||
PCCL_GLOBAL_TOPO_FILE | ||
PCCL_PERFMODEL_SPEEDUP | ||
PCCL_IGNORE_TOPO_DETECTION | ||
PCCL_SINGLE_HOST_CROSS_NODE_TEST | ||
PCCL_BLOCKING_BOOTSTRAP | ||
PCCL_NO_MEMSET | ||
PCCL_GET_MIN_PATH_NUM_BY_DRIVER | ||
PCCL_MULTI_HOSTS_BULK_MODE | ||
PCCL_GROUP_HGGC_STREAM | ||
PCCL_DISABLE_FC_GRAPH | ||
PCCL_ADJUST_SYSTEM_MIN_NET_NUM | ||
PCCL_TB_PER_CU | ||
PCCL_TRAVERSE_Y | ||
PCCL_IGNORE_INTEL_P2P_OVERHEAD | ||
PCCL_GRAPH_SEARCH_START_INTER_TYPE | configure the cross node start inter type, like PXN to speed up graph search | |
PCCL_INJECTION64_PATH | ||
PCCL_DEBUG_DEV | ||
PCCL_ERROR_YIELD | ||
PCCL_GRAPH_SPEEDS | ||
PCCL_COMM_DUMP_FILE | ||
PCCL_ENABLE_ABORT_DUMP | ||
PCCL_ENABLE_EXT_KERNEL | Since PCCL 1.4.0 | |
PCCL_EXT_KERNEL_PLUGIN | Since PCCL 1.4.0 | |
PCCL_COMM_DUMP_LEVEL | Since PCCL 1.4.0 | |
PCCL_STATE_MONITOR_DISABLE | Since PCCL 1.4.0 | PCCL feature to monitor kernel execution state |
PCCL_STATE_MONITOR_TRIGGER_PIPE | Since PCCL 1.4.0 | |
PCCL_STATE_MONITOR_SLEEP_US | Since PCCL 1.4.0 | |
PCCL_STATE_MONITOR_QUIT_WHEN_EXCEPTION | Since PCCL 1.4.0 | |
PCCL_STATE_MONITOR_DUMP_WHEN_EXCEPTION_DISABLE | Since PCCL 1.4.0 | |
PCCL_STATE_SYNC_POLL_INTERVAL_MS | Since PCCL 1.4.0 | |
PCCL_STATE_MONITOR_LOG_EVERY_MS | Since PCCL 1.4.0 | |
PCCL_GDR_USE_DEV_MEM_FOR_RX_TAIL | Since PCCL 1.4.0 | Use device memory for tail pointer during GDR path communication |
PCCL_GDR_CPU_FLUSH | Since PCCL 1.4.0 | Use CPU memory PCI-e read for GDR flush operation |
PCCL_DEBUG_DUMP_DIR | Since PCCL 1.4.3 | Configure debug dump foler path |
PCCL_IB_NIC_SPEED_SCALING_FACTOR | Since PCCL 1.4.3 | Configure IB NIC bandwidth factor if missing the bonding information and cause real speed mismatch with sys information |
PCCL_NET_AFFINITY | Since PCCL 1.5.0 | Configure PPU affinity NET id, format: "hgml_dev_id:net_id,hgml_dev_id:net_id" |
PCCL_CHECK_ITEMS_ENABLE | Since PCCL 1.5.0 | Configure if enable internal check for potential topo or environment problems |
PCCL_DOUBLE_EIC_PCI_WIDTH_DISABLE | Since PCCL 1.5.0 | Configure to 0 if run on EIC platform, and default is 0 |
PCCL_STATE_MONITOR_LEVEL | Since PCCL 1.5.0 | Configure the monitor level |
PCCL_D2D_DISP_PING_PONG_EN | Since PCCL 1.6.0 | |
PCCL_JUMP_DIM | Since PCCL 1.6.0 | |
PCCL_LAST_ROUND_EN | Since PCCL 1.6.0 | |
PCCL_ONE_BATCH_PER_CE | Since PCCL 1.6.0 | |
PCCL_SKEW_EN | Since PCCL 1.6.0 | |
PCCL_TRAVERSE_Y_STEP | Since PCCL 1.6.0 | |
PCCL_FB_STALL_ST_TYPE | Since PCCL 1.6.0 | |
PCCL_TRAVERSE_X_STEP | Since PCCL 1.6.0 | |
PCCL_LAST_ROUND_TB_PER_CE | Since PCCL 1.6.0 | |
PCCL_TUNING_FALL_BACK | Since PCCL 1.6.0 | |
PCCL_FB_STALL_ST_EN | Since PCCL 1.6.0 | |
PCCL_FORCE_DEFAULT_DISP | Since PCCL 1.6.0 | |
PCCL_START_CE_ID | Since PCCL 1.6.0 | |
PCCL_LAST_ROUND_ONETB_PER_CE | Since PCCL 1.6.0 | |
PCCL_WAIT_EN | Since PCCL 1.6.0 | |
PCCL_LAST_ROUND_BEGIN_NUMBER | Since PCCL 1.6.0 | |
PCCL_PRE_ALLOC_EN | Since PCCL 1.6.0 | |
PCCL_BLOCK_AGE_EN | Since PCCL 1.6.0 | |
PCCL_NDIES | Since PCCL 1.6.0 | |
PCCL_START_CE_EN | Since PCCL 1.6.0 | |
PCCL_FORCE_DEFAULT_CE_MASK | Since PCCL 1.6.0 |
4. Net APIs汇总
4.1 Net APIs
NCCL 2.22.3 + Net V8 | PCCL 1.5 + Net V6 | 备注 |
const char* name | const char* name | Name of the network |
ncclResult_t (*init)(ncclDebugLogger_t logFunction); | pcclResult_t (*init)(pcclDebugLogger_t logFunction); | Initialize the network. |
ncclResult_t (*devices)(int* ndev); | pcclResult_t (*devices)(int* ndev); | Return the number of adapters. |
ncclResult_t (*getProperties)(int dev, ncclNetProperties_v8_t* props); | pcclResult_t (*getProperties)(int dev, pcclNetProperties_v6_t* props); | Get various device properties. |
ncclResult_t (*listen)(int dev, void* handle, void** listenComm); | pcclResult_t (*listen)(int dev, void* handle, void** listenComm); | Create a receiving object and provide a handle to connect to it. |
ncclResult_t (*connect)(int dev, void* handle, void** sendComm, ncclNetDeviceHandle_v8_t** sendDevComm); | pcclResult_t (*connect)(int dev, void* handle, void** sendComm); | Connect to a handle and return a sending comm object for that peer. |
ncclResult_t (*accept)(void* listenComm, void** recvComm, ncclNetDeviceHandle_v8_t** recvDevComm); | pcclResult_t (*accept)(void* listenComm, void** recvComm); | Finalize connection establishment after remote peer has called connect. |
ncclResult_t (*regMr)(void* comm, void* data, size_t size, int type, void** mhandle); | pcclResult_t (*regMr)(void* comm, void* data, int size, int type, void** mhandle); | Register/Deregister memory. |
ncclResult_t (*regMrDmaBuf)(void* comm, void* data, size_t size, int type, uint64_t offset, int fd, void** mhandle); | pcclResult_t (*regMrDmaBuf)(void* comm, void* data, size_t size, int type, uint64_t offset, int fd, void** mhandle); | DMA-BUF support |
ncclResult_t (*deregMr)(void* comm, void* mhandle); | pcclResult_t (*deregMr)(void* comm, void* mhandle); | Register/Deregister memory. |
ncclResult_t (*isend)(void* sendComm, void* data, int size, int tag, void* mhandle, void** request); | pcclResult_t (*isend)(void* sendComm, void* data, int size, int tag, void* mhandle, void** request); | Asynchronous send to a peer. |
ncclResult_t (*irecv)(void* recvComm, int n, void** data, int* sizes, int* tags, void** mhandles, void** request); | pcclResult_t (*irecv)(void* recvComm, int n, void** data, int* sizes, int* tags, void** mhandles, void** request); | Asynchronous recv from a peer. |
ncclResult_t (*iflush)(void* recvComm, int n, void** data, int* sizes, void** mhandles, void** request); | pcclResult_t (*iflush)(void* recvComm, int n, void** data, int* sizes, void** mhandles, void** request); | Perform a flush/fence to make sure all data received |
ncclResult_t (*test)(void* request, int* done, int* sizes); | pcclResult_t (*test)(void* request, int* done, int* size); | Test whether a request is complete. |
ncclResult_t (*closeSend)(void* sendComm); | pcclResult_t (*closeSend)(void* sendComm); | Close and free send/recv comm objects |
ncclResult_t (*closeRecv)(void* recvComm); | pcclResult_t (*closeRecv)(void* recvComm); | |
ncclResult_t (*closeListen)(void* listenComm); | pcclResult_t (*closeListen)(void* listenComm); | |
ncclResult_t (*getDeviceMr)(void* comm, void* mhandle, void** dptr_mhandle); | ❌ | Copy the given mhandle to a dptr |
ncclResult_t (*irecvConsumed)(void* recvComm, int n, void* request); | ❌ | Notify the plugin that a recv has completed by the device |
4.2 Coll Net APIs
NCCL 2.22.3 + Coll Net V8 | PCCL 1.5 + Coll Net V6 | 备注 |
const char* name | const char* name | Name of the network |
ncclResult_t (*init)(ncclDebugLogger_t logFunction); | pcclResult_t (*init)(pcclDebugLogger_t logFunction); | Initialize the network. |
ncclResult_t (*devices)(int* ndev); | pcclResult_t (*devices)(int* ndev); | Return the number of adapters. |
ncclResult_t (*getProperties)(int dev, ncclNetProperties_v8_t* props); | pcclResult_t (*getProperties)(int dev, pcclNetProperties_v4_t* props); | Get various device properties. |
ncclResult_t (*listen)(int dev, void* handle, void** listenComm); | pcclResult_t (*listen)(int dev, void* handle, void** listenComm); | Create a receiving object and provide a handle to connect to it. |
ncclResult_t (*connect)(void* handles[], int nranks, int rank, void* listenComm, void** collComm); | pcclResult_t (*connect)(void* handles[], int nranks, int rank, void* listenComm, void** collComm); | Create a group for collective operations. |
ncclResult_t (*reduceSupport)(ncclDataType_t dataType, ncclRedOp_t redOp, int* supported); | pcclResult_t (*reduceSupport)(pcclDataType_t dataType, pcclRedOp_t redOp, int* supported); | Returns whether a reduction operation on a data type is supported. |
ncclResult_t (*regMr)(void* collComm, void* data, size_t size, int type, void** mhandle); | pcclResult_t (*regMr)(void* collComm, void* data, int size, int type, void** mhandle); | Register/Deregister memory. |
ncclResult_t (*regMrDmaBuf)(void* collComm, void* data, size_t size, int type, uint64_t offset, int fd, void** mhandle); | pcclResult_t (*regMrDmaBuf)(void* collComm, void* data, size_t size, int type, uint64_t offset, int fd, void** mhandle); | DMA-BUF support |
ncclResult_t (*deregMr)(void* collComm, void* mhandle); | pcclResult_t (*deregMr)(void* collComm, void* mhandle); | Register/Deregister memory. |
ncclResult_t (*iallreduce)(void* collComm, void* sendData, void* recvData, int count, ncclDataType_t dataType, ncclRedOp_t redOp, void* sendMhandle, void* recvMhandle, void** request); | pcclResult_t (*iallreduce)(void* collComm, void* sendData, void* recvData, int count, pcclDataType_t dataType, pcclRedOp_t redOp, void* sendMhandle, void* recvMhandle, void** request); | Performs an asynchronous allreduce operation on the collective group. |
ncclResult_t (*iallgather)(void* collComm, void* sendData, int nRecvParts, ncclNetSGE_v8_t* recvParts, size_t bytesPerRank, size_t windowOffset, size_t windowBytes, void* sendMhandle, void** request); | ❌ | Performs an asynchronous allgather operation on the collective group. |
ncclResult_t (*ireducescatter)(void* collComm, int nSendParts, ncclNetSGE_v8_t* sendParts, void* recvData, size_t bytesPerRank, size_t windowOffset, size_t windowBytes, ncclDataType_t dataType, ncclRedOp_t redOp, void* recvMhandle, void** request); | ❌ | Performs an asynchronous reduce_scatter operation on the collective group. |
ncclResult_t (*iflush)(void* collComm, void* data, int size, void* mhandle, void** request); | pcclResult_t (*iflush)(void* collComm, void* data, int size, void* mhandle, void** request); | Perform a flush/fence to make sure all data received |
ncclResult_t (*test)(void* request, int* done, int* size); | pcclResult_t (*test)(void* request, int* done, int* size); | Test whether a request is complete. |
ncclResult_t (*closeColl)(void* collComm); | pcclResult_t (*closeColl)(void* collComm); | Close and free collective comm objects |
ncclResult_t (*closeListen)(void* listenComm); | pcclResult_t (*closeListen)(void* listenComm); |
5. 模型训练或推理时环境变量配置建议
经过一段时间对模型训练的性能问题的分析和积累,PCCL 有下面几个相关的环境变量设置可以在日常模型训练中,提升模型训练性能。
5.1 CUDA_VISIBLE_DEVICES
基于 Megatron core 的多种并行训练配置,可以参考下面的文件,进行提前扫描,并根据实际扫描出来的配置进行设置,扫描脚本会根据提供的并行参数搜索最佳 CUDA_VISIBLE_DEVICES 配置,相比默认会大幅提升通信效率,进一步提高模型训练性能。
5.2 真武810E 多机训练时的配置 (v1.5.2 及之后版本不再需要)
Note: 该配置在 PCCL 版本 1.5.2 之后不需要额外设置,PCCL 内部会自动检测 affinity 网卡并使用。
如果模型训练涉及多机通信,可以配置下述的环境变量列表,为 真武810E 配置最佳的网卡,确保走性能最佳的 GDR 通路,同时去掉机头网卡的参与,提高端到端训练性能。尤其是多机 allToAll 的性能目前依赖下面环境变量的设置才能达到最佳性能。
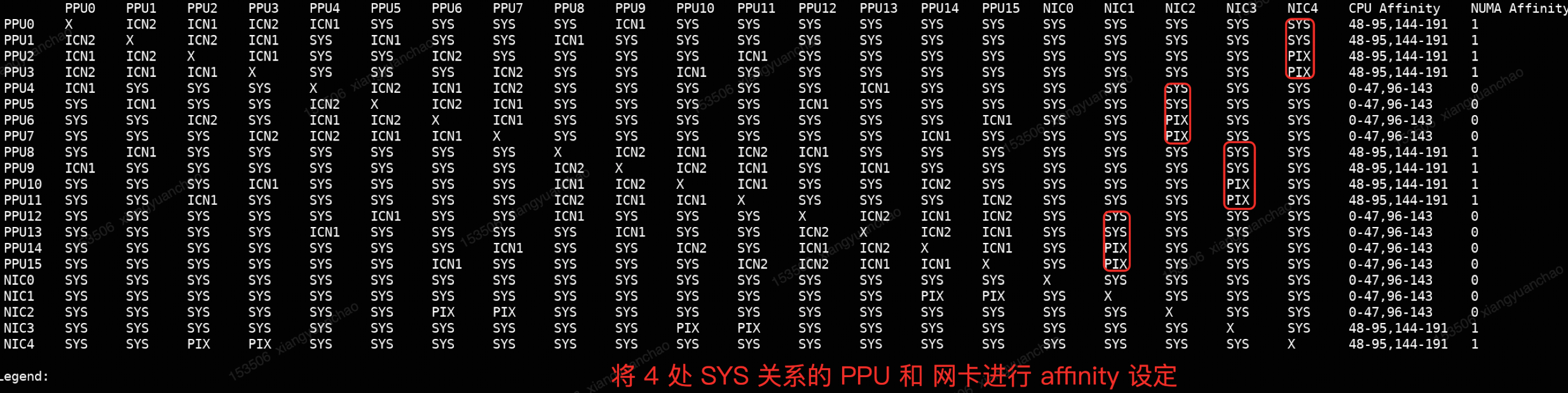
// PCCL_NET_AFFINITY format: "hgml_dev_id:net_id,hgml_dev_id:net_id"
// 通常会通过 NCCL_IB_HCA 过滤掉机头的网卡,所以 NET id 会有一个 -1 的 偏移
export PCCL_NET_AFFINITY=0:3,1:3,4:1,5:1,8:2,9:2,12:0,13:0
export NCCL_NET_GDR_LEVEL=PHBH
export NCCL_IB_HCA=mlx5_bond_1,mlx5_bond_2,mlx5_bond_3,mlx5_bond_45.3 PPU资源控制
如果模型训练中,存在计算和通信 overlap 场景,可以尝试下面的环境变量,调整减少通信库对计算资源占用来提高端到端训练性能。(实验性功能,具体有效与否取决于 workload 实际情况)。
export PCCL_CU_MASK=8
export NCCL_NTHREADS=256
export NCCL_LL128_NTHREADS=320export PCCL_CU_MASK=12
export NCCL_NTHREADS=256
export NCCL_LL128_NTHREADS=320