图书智能分类助手
本实验将以“图书智能分类助手”为例,通过使用阿里云百炼搭建工作流,了解利用AI辅助图书赋分类号的方法,从而掌握阿里云百炼搭建工作流的过程和技巧。
实验简介
本实验将以“图书智能分类助手”为例,通过使用阿里云百炼搭建工作流,了解利用AI辅助图书赋分类号的方法,从而掌握阿里云百炼搭建工作流的过程和技巧。
背景知识
阿里云百炼是一站式的大模型开发及应用构建平台。不论是开发者还是业务人员,都能深入参与大模型应用的设计和构建。您可以通过简单的界面操作,在5分钟内开发出一款大模型应用,或在几小时内训练出一个专属模型,从而将更多精力专注于应用创新。点击查看产品简介。
中国图书分类法(简称中图法)是我国图书馆最广泛使用的综合性图书分类体系,将图书按学科内容分为五大部类和22个基本大类。依据图书内容和主题进行层级分类。图书智能分类助手搭建分类的完整工作流,进行基本大类的分类,使用者可以在此基础上对工作流和提示词进行细化,以探索图书分类自动化的过程。
实验室资源方式简介
进入实操前,请确保阿里云账号满足以下条件:
个人账号资源
使用您个人的云资源进行操作,资源归属于个人。
平台仅提供手册参考,不会对资源做任何操作。
确保已完成云工开物 300 元代金券领取。
已通过实名认证且账户余额 ≥0 元。
本实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
实操结束后,无需对阿里云百炼进行注销。您可以选择继续付费保留资源,但这将导致持续产生费用,否则请根据实验手册释放资源。
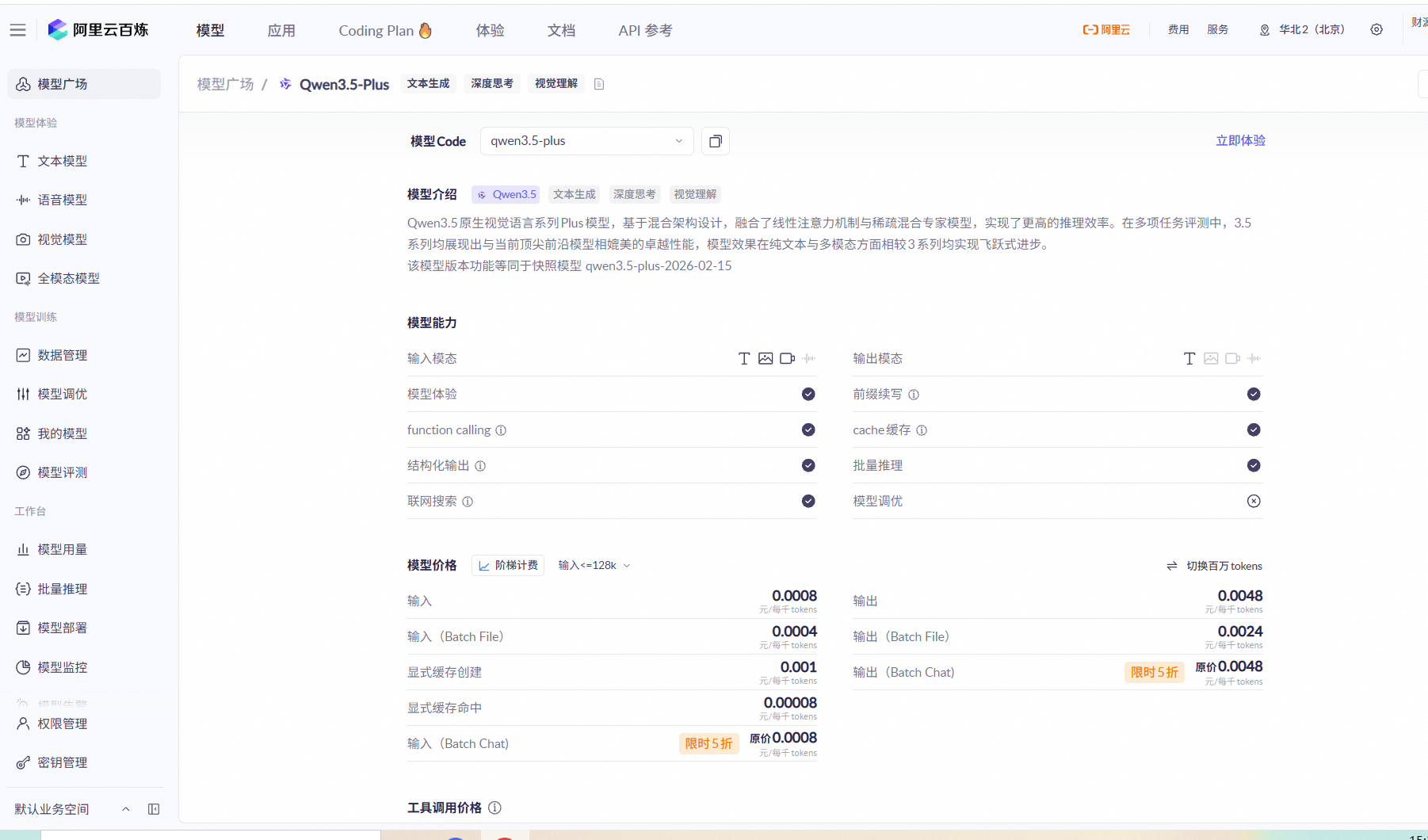
新注册阿里云百炼的用户,千问系列模型提供模型的免费额度,不同模型的免费额度不同,请在使用前,先阅读产品文档确认模型的免费额度,或在使用前,登录阿里云百炼-模型广场-模型卡片详情,查看具体模型的免费额度。注意在使用过程中的token消耗。模型列表 只有开通阿里云百炼服务后才能体验模型的免费额度。
资源消耗说明
本场景主要涉及以下云产品和服务:阿里云百炼大模型服务平台Qwen-Flash模型和Deepseek-V3模型
本实验费用以实际使用的token量为准,以Qwen-Flash和Deepseek-V3为例,Qwen-Flash为阶梯计费,输入<128k时,输入 0.00015元/千tokens,输出0.0015元/千tokens;Deepseek-V3,输入0.002元/千tokens,输出0.008元/千tokens。
本实验预计产生资源消耗:约0.03元(以3次工作流内部大模型节点测试及2次工作流测试为例估算),如果您调整了资源规格、使用时长,或执行了本方案以外的操作,可能导致费用发生变化,请以控制台显示的实际价格和最终账单为准。
输入token:约11.7k(Deepseek-V3 2.5k;Qwen-Flash 9.2k)
输出token:约8.5k(Deepseek-V3 2k;Qwen-Flash 6.5k)
领取专属权益及创建实验资源
在开始实验之前,请先点击右侧屏幕的“进入实操”再进行后续操作
本次实验需要您通过领取阿里云云工开物学生专属300元抵扣券兑换本次实操的云资源,如未领取请先点击领取。(若已领取请跳过)
实验产生的费用优先使用优惠券,优惠券使用完毕后需您自行承担。

实验步骤
说明:本实验根据《中图法》进行图书基本大类的分类的工作流搭建实验,旨在帮助大家了解如何构建工作流,并借助工作流完成图书分类工作,您可以在本实验的基础上,对Prompt和工作流节点进行优化和调整,实现更多能力。
登录阿里云百炼
在阿里云官网搜索阿里云百炼进入控制台,或点击进入阿里云百炼控制台
点击【登录】
若之前未登录开通过阿里云百炼请按以下步骤操作,若已开通过百炼服务请跳过此步
点击【立即开通】

阅读服务协议并点击【同意】
创建工作流应用
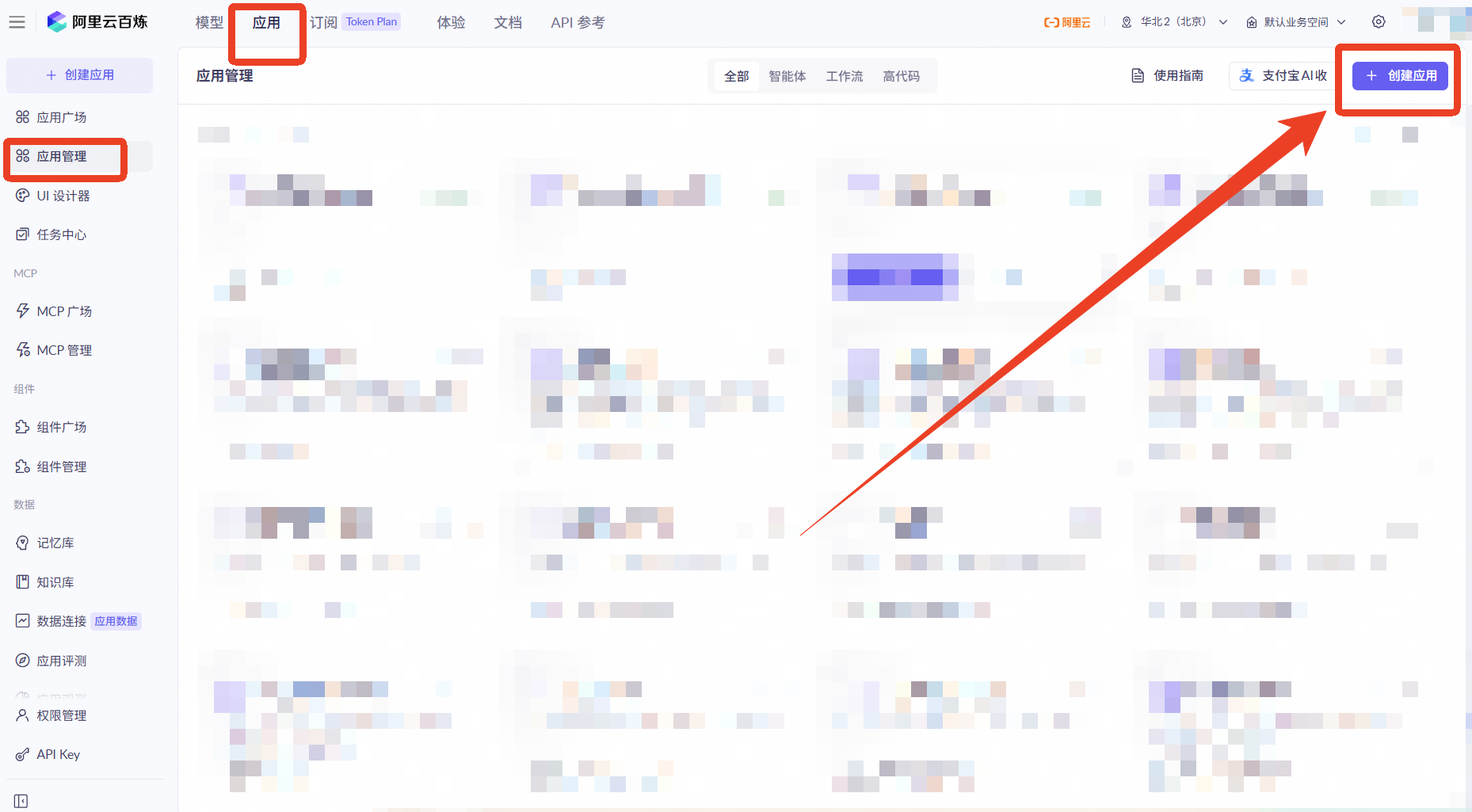
点击【应用】——【应用管理】——【创建应用】
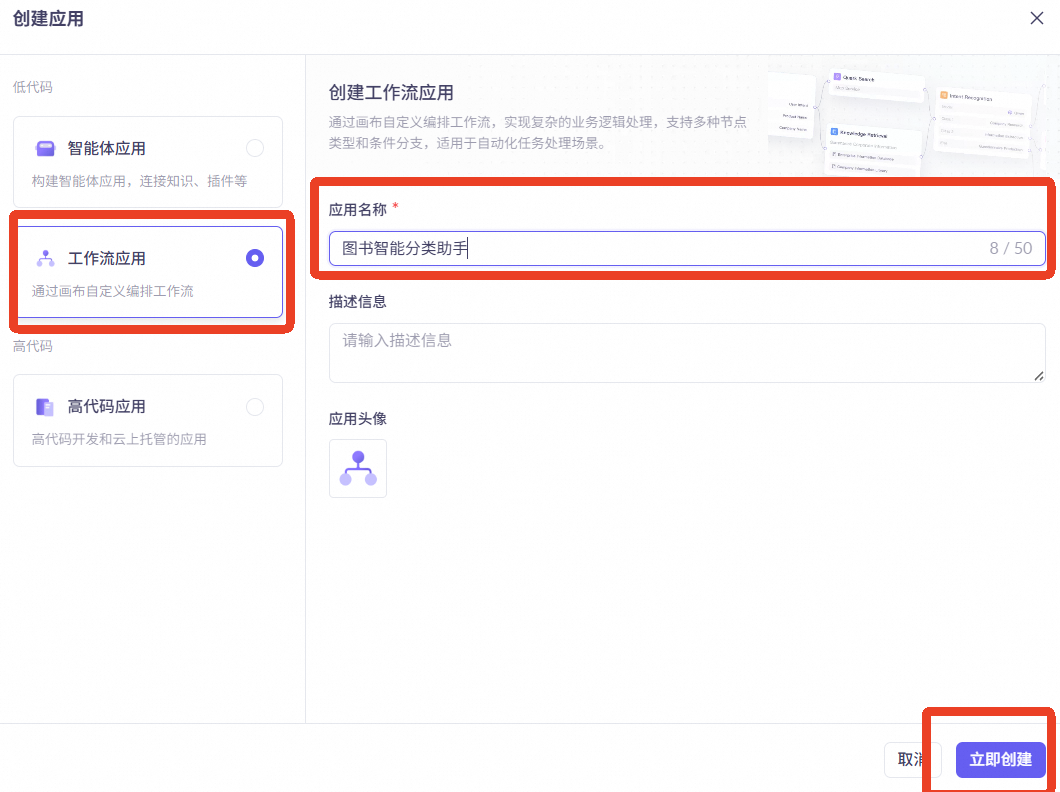
选择【工作流应用】,输入应用名称,点击【立即创建】
创建成功
工作流设计介绍
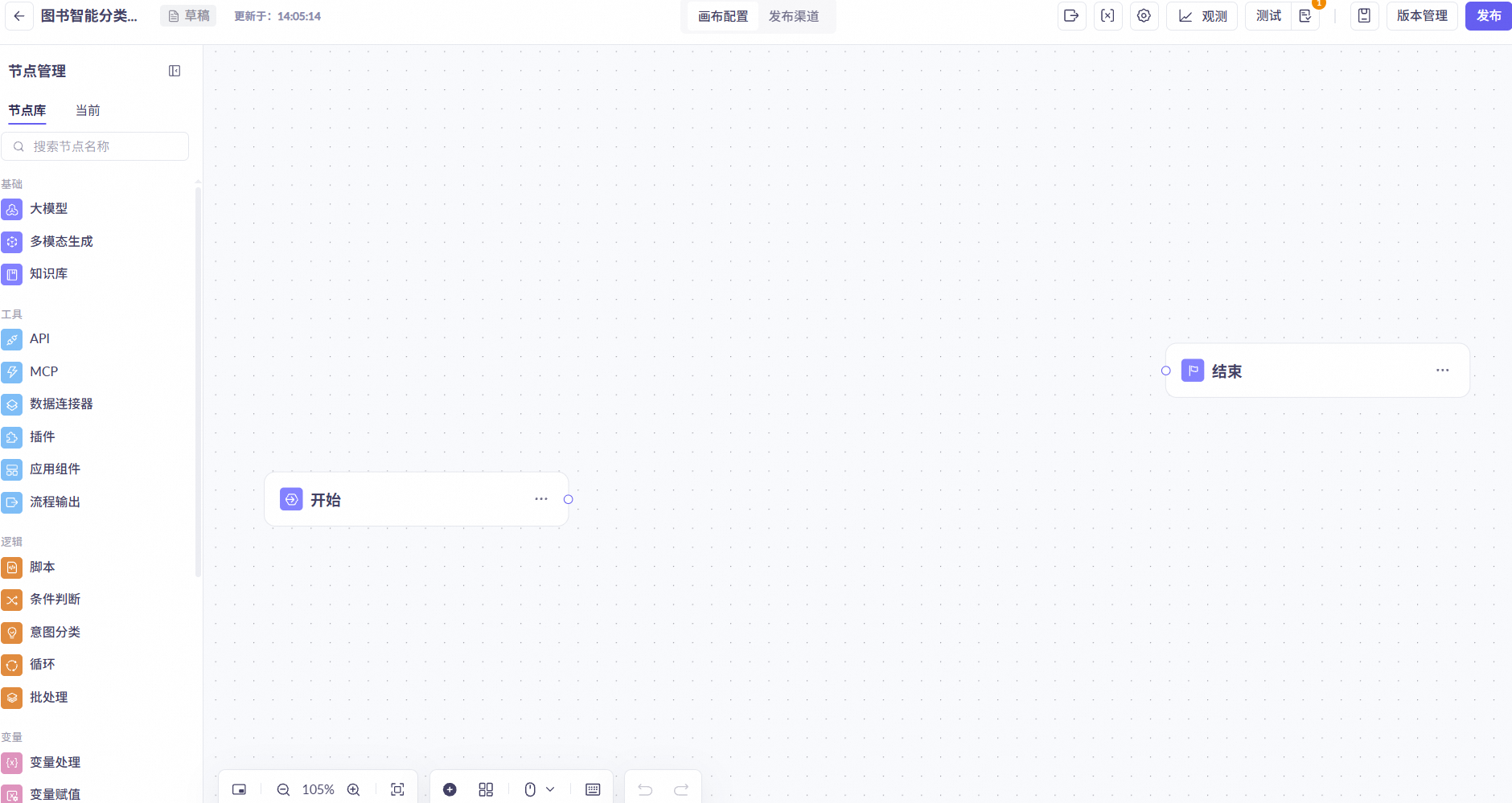
与智能体不同,工作流中的功能更加多样,可以引入不同的节点(基础、工具、逻辑、变量、数据、智能体等)。节点库位于界面左边栏。引入节点时将节点拖入画布即可。更详细的工作流应用及相关节点的说明可参考大模型服务平台百炼控制台。本实验建议参与者有智能体设计的能力,如未设计过智能体,可以参考另一个实验中对智能体设计的详细说明。
基础:包括大模型、多模态生成和知识库。
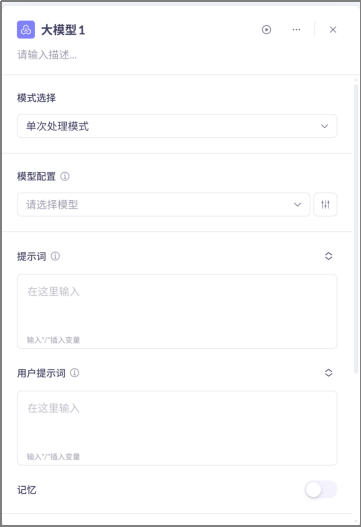
大模型节点
完成的是文本类任务,可以选择配置不同的模型并设置参数,可以通过填写提示词和用户提示词来说明大模型节点的工作任务。
模态生成节点
需要配置具有多模态能力的大模型,目前支持图像、视频、音频三种能力的大模型节点,如果任务中需要进行多模态任务,可以引入此类节点。
知识库节点
通过调用已上传的知识库内容完成任务。
如果开发者已经尝试过智能体的开发,可以将这三个节点理解为对智能体设计的拆分,即把智能体的设计模块化为可独立配置、灵活组合的节点,从而实现更精细化的任务编排与调试。如果智能体的任务足够清晰,也可以先设计智能体,再在工作流中引入设计好的智能体。
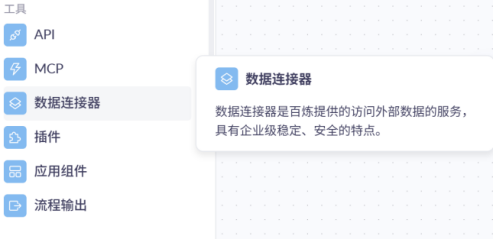
工具:包括API、MCP、数据连接器、插件、应用组件和流程输出。
这一部分通过调用外部已开发的工具来增强工作流的能力。相关内容可通过鼠标悬停于节点库的节点进行了解。如下图中的数据连接器:
逻辑:包括脚本、条件判断、意图分类、循环、批处理。
脚本节点
可以自行撰写Python或JavaScript代码完成数据处理等工作。
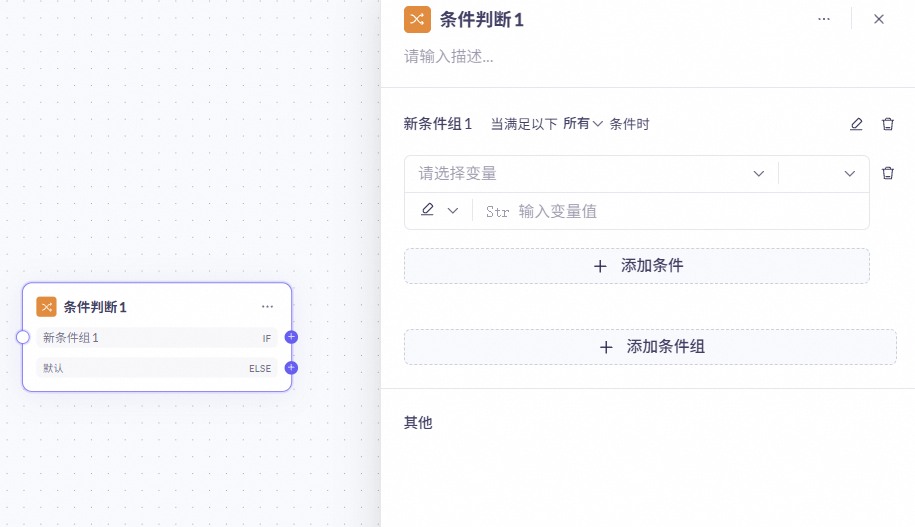
条件判断节点
可以通过设定不同的条件组,满足不同的条件进入不同的分支。
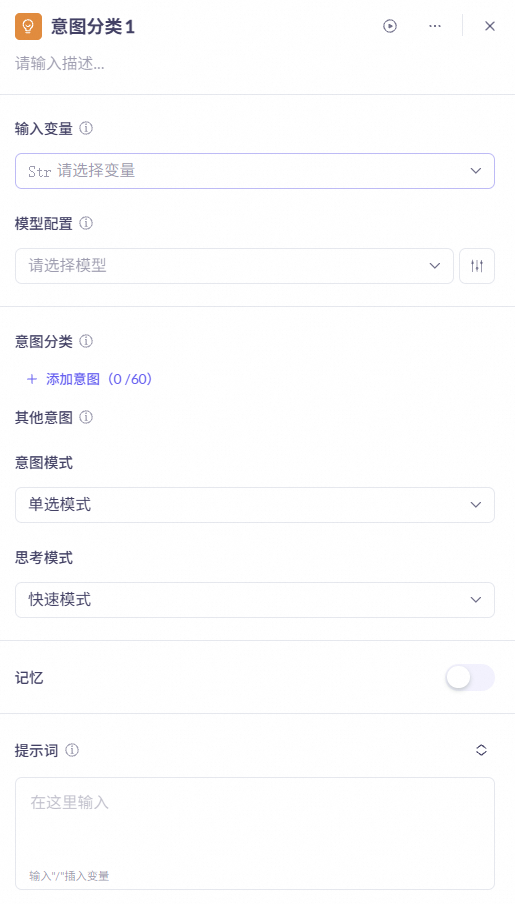
意图分类节点
是利用大模型自动识别用户意图的节点。
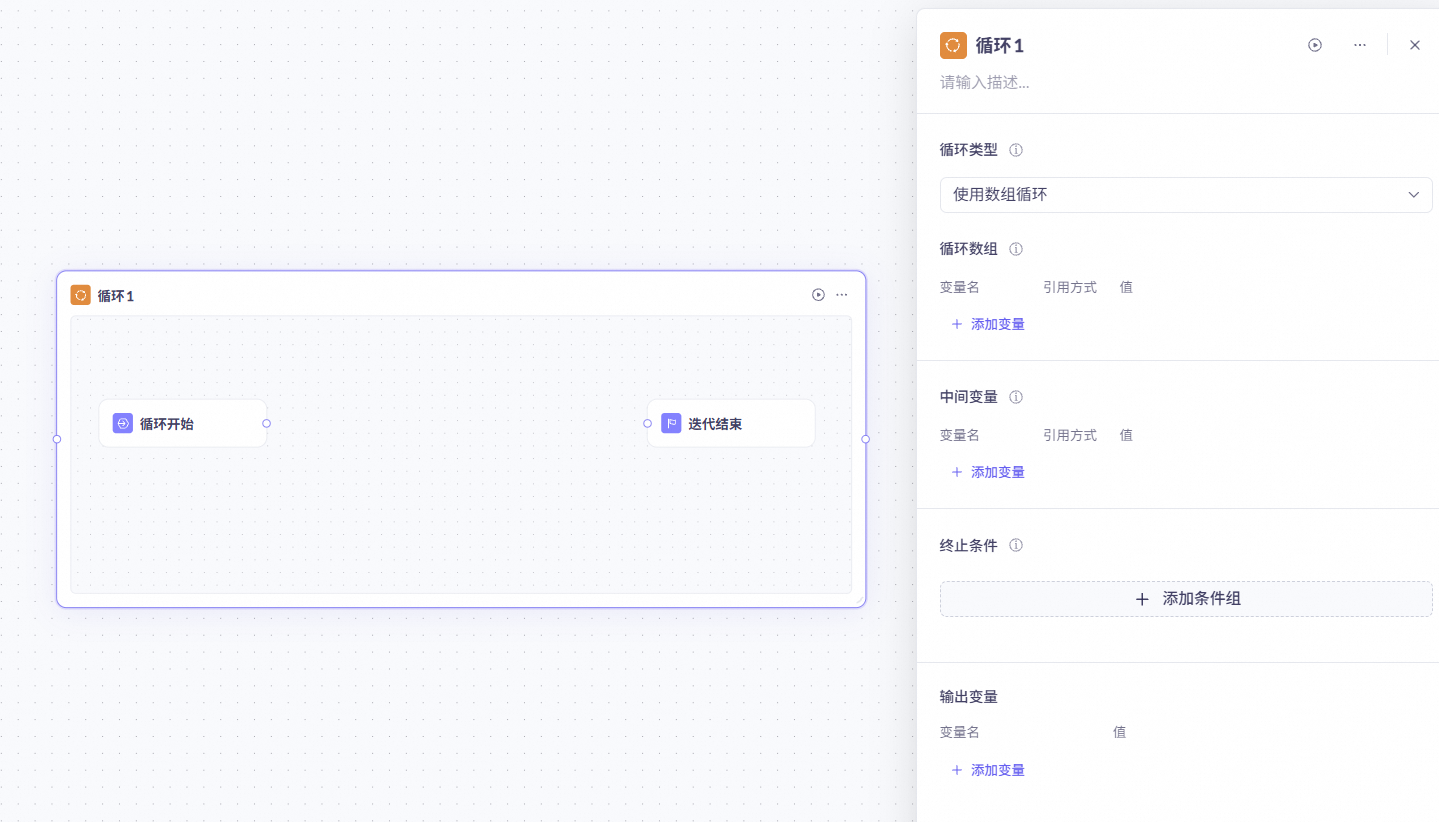
循环节点
可以设计循环体,指定循环特定次数或满足特定循环条件。
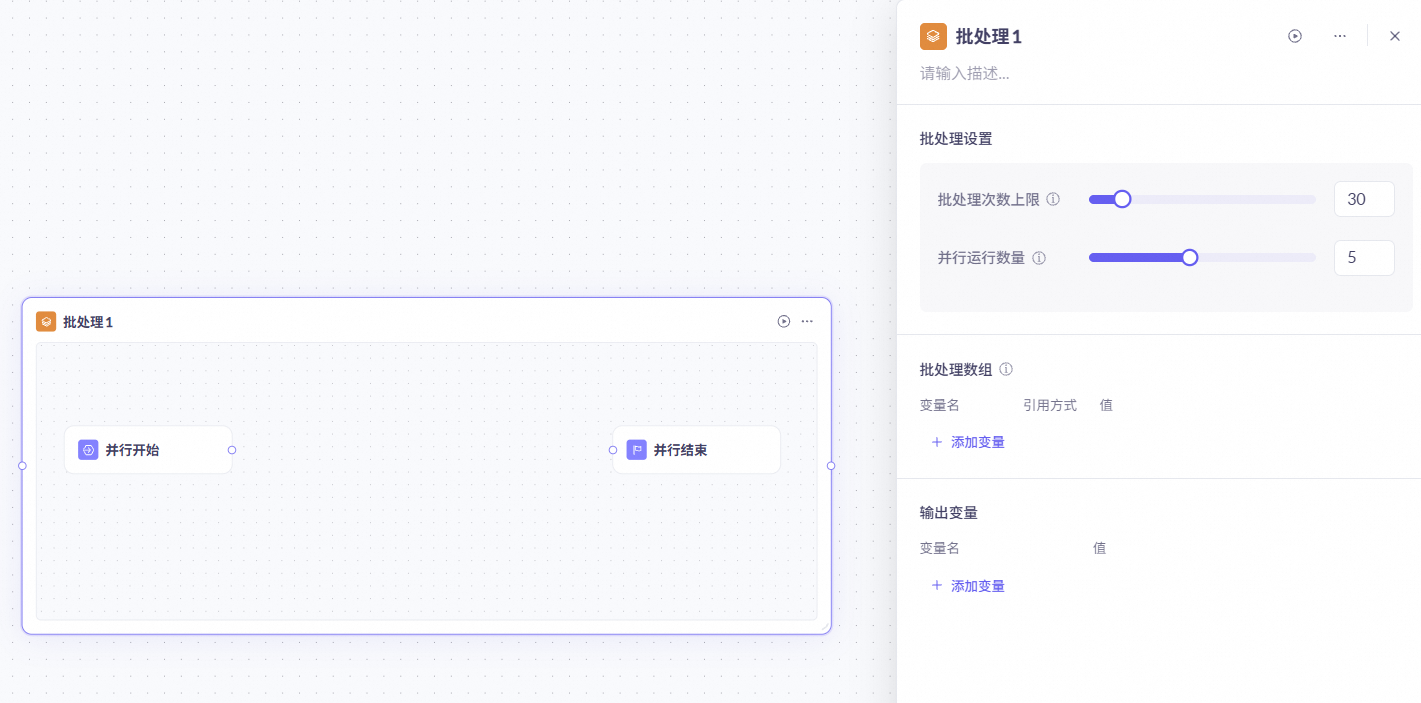
批处理节点
可以对数组内容进行批量化的并行处理
变量:包括变量处理、变量赋值、参数提取。
变量处理节点
用于文本内容的转换与处理,如抽取特定内容、格式转换等。
变量赋值节点
仅支持在循环节点中使用,可以将特定的值赋予循环体的中间变量,从而实现变量值的动态更新与传递。
参数提取节点
通过大模型提取一段文本中的结构化参数
数据:包括文档解析、图片解析、视频解析、音频解析。
如果工作流设计支持用户输入相关文件形式,可以引入此类节点进行分析,提取其中的结构化内容。
智能体:包括智能体创建和智能体群组。
智能体创建节点
支持直接在工作流中创建智能体,具体设计与智能体设计相同,使智能体成为工作流的一个节点。
智能体群组节点
包含多个子智能体,群组中的决策模型可以根据任务需求自动规划任务执行流程,灵活调度子智能体,协同多个子智能体执行任务。该节点适合需要智能规划的任务。
工作流设计
本实验通过构建简单的工作流,实现自动化的中图法基本大类的分类任务。工作逻辑为:
用户输入:书名、作者、出版社中的一个或多个信息。
大模型补全图书简介:配置图书简介补全大模型,支持联网搜索功能,自动补全图书简介。
图书分类号生成:使用Qwen-Flash和Deepseek-V3两个大模型,分别根据书名和简介进行基本大类的分类。
变量提取:由两个变量处理的节点进行分类结果的提取。
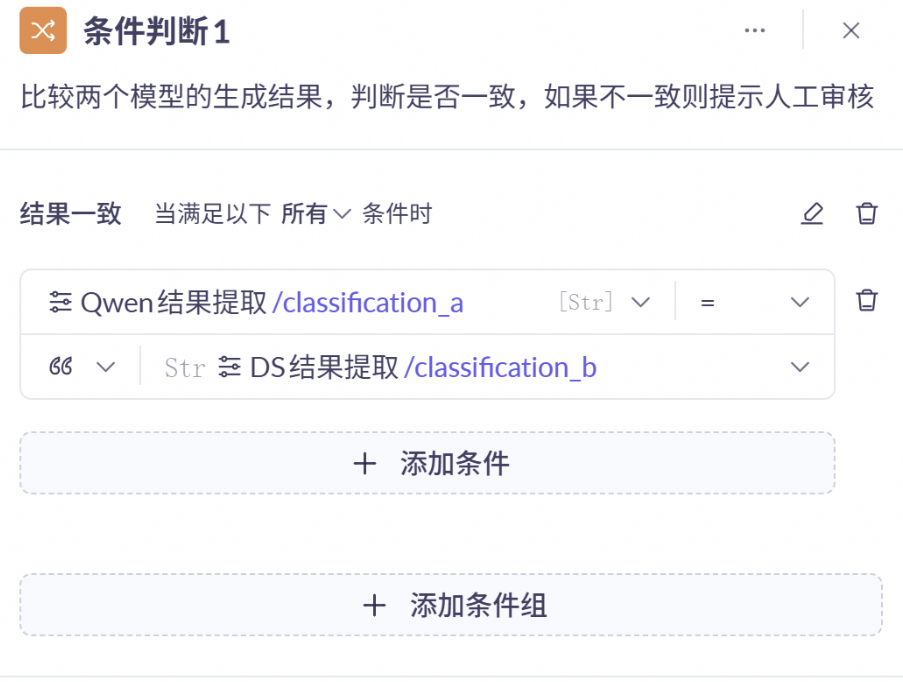
结果判断:使用条件判断节点进行结果比较,如果结果一致,则返回其中一个大模型的分类结果及原因;如果不一致,则需输出两个大模型的分类结果及原因。
结果整合:使用变量处理节点进行结果整合。
输出:输出最终整合的结果
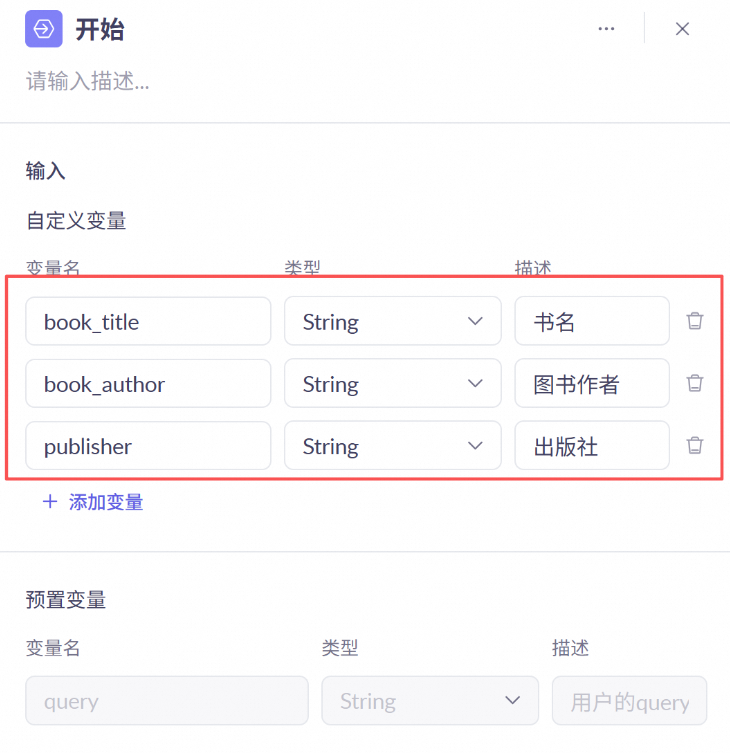
开始节点
设计三个结构化的字符串变量,分别为书名、作者和出版社。本实验通过处理结构化的数据完成后续工作。如需要,可自行探索并增加对用户自然语言输入进行解析的节点
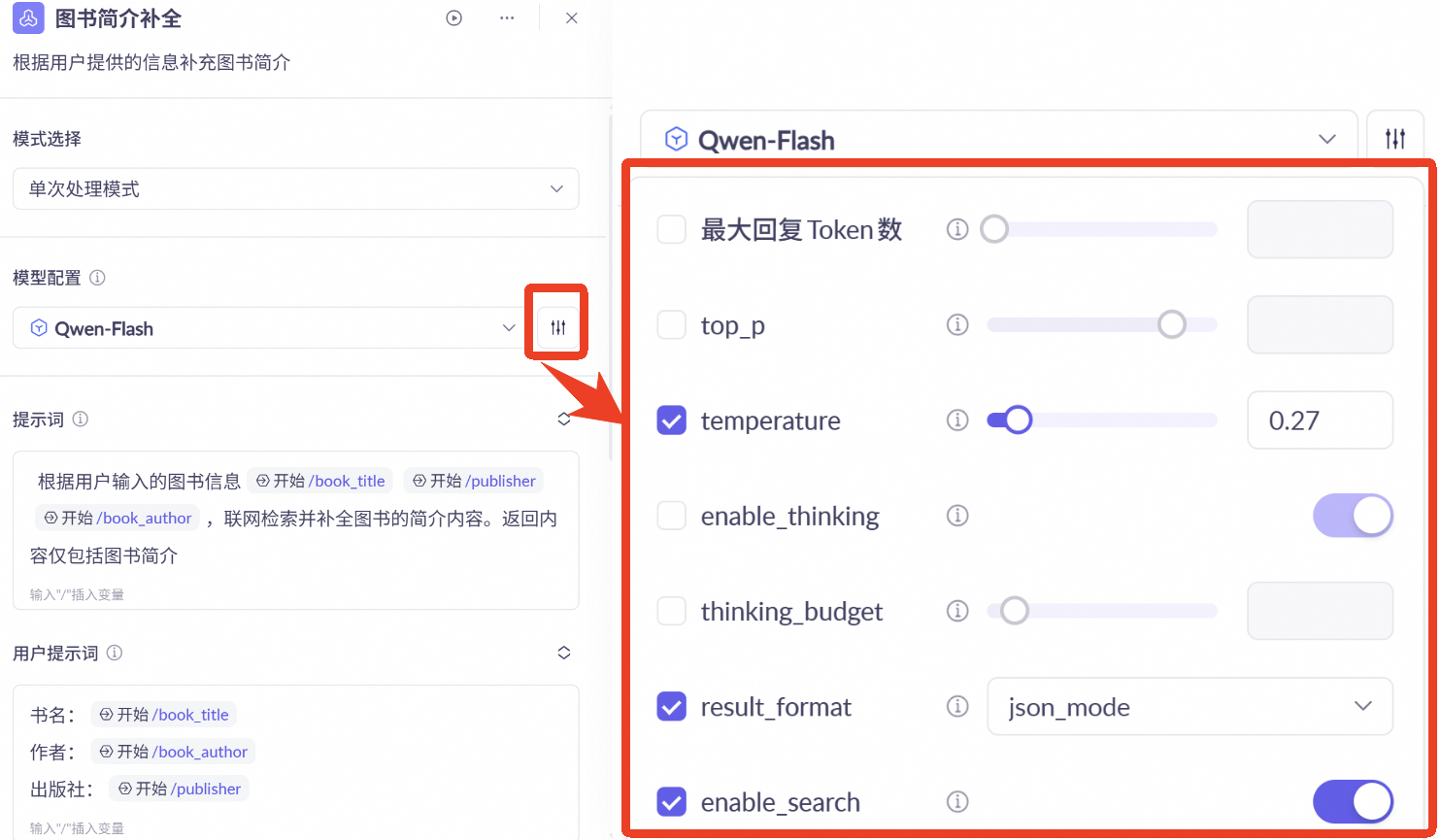
图书简介补全节点
拖入大模型节点,配置Qwen-Flash模型
调低温度以提高结果的客观性
输出结果格式设置为json_mode
支持检索功能(enable_search)
设定提示词
"根据用户输入的图书信息${Start_0dYE.book_title}${Start_0dYE.publisher}${Start_0dYE.book_author},联网检索并补全图书的简介内容。返回内容仅包括图书简介。"
说明此处请注意,三个变量可以通过“/”符号引出并选择设计的三个变量。节点必须与开始节点连接,才能够看到前面设计的变量
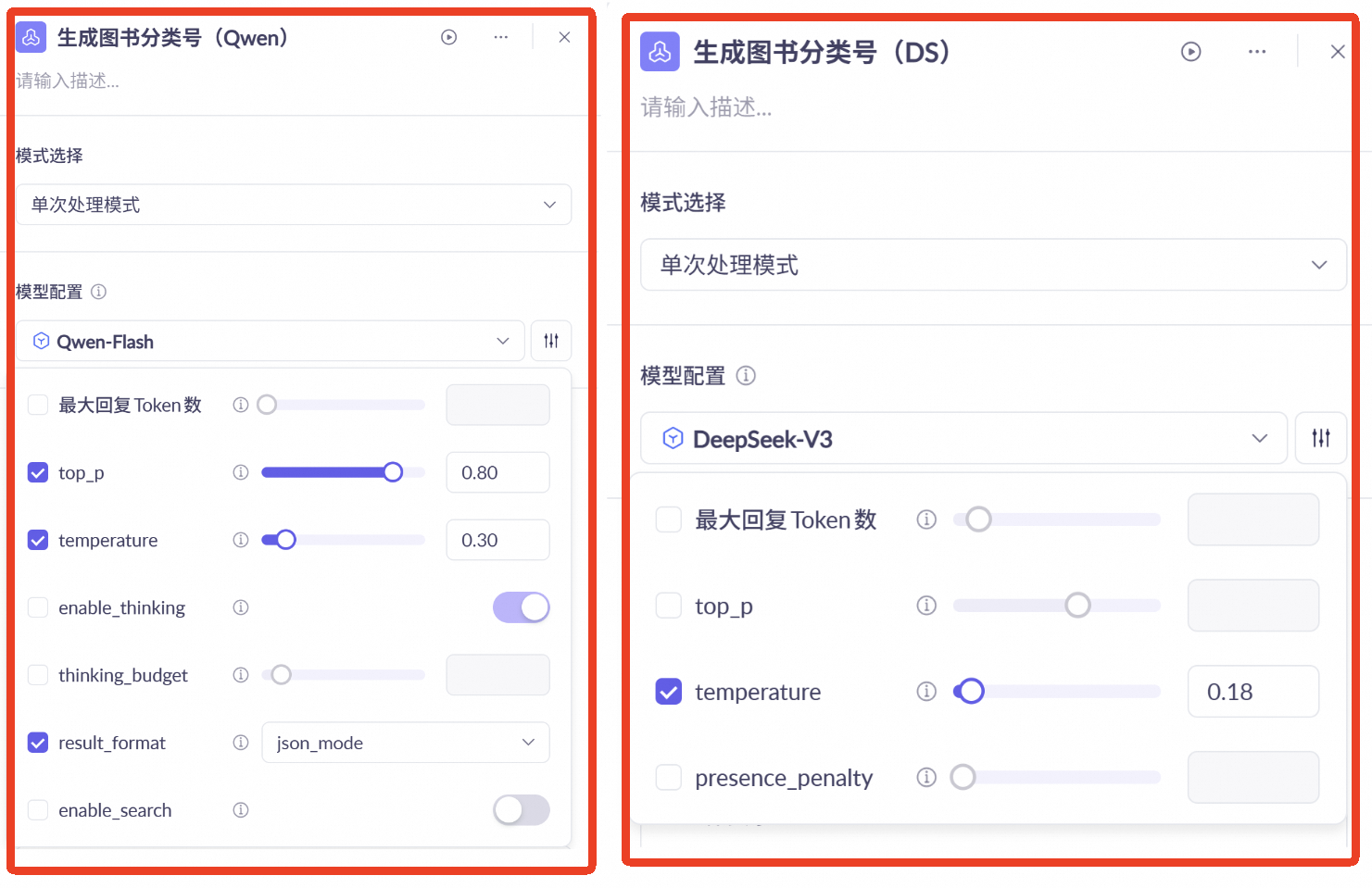
生成图书分类号节点
分别拖入两个大模型节点并与图书简介节点连接
分别在两个节点中选择Qwen-Flash 和 Deepseek-V3模型
设定提示词
"你是一位专业的图书分类专家,精通中国图书馆分类法(中图法)。你的任务是根据图书的基本信息(书名、摘要),为图书生成准确的中图法基本大类(字母)。
# 工作要求
1. 仔细阅读图书的书名、作者和摘要信息(如提供)
2. 根据图书的主题内容、学科领域,参照中图法的分类规则
3. 生成合适的中图法分类号基本大类字母
4. 提供生成该分类字母的理由说明
# 中图法基本大类参考
中国图书馆分类法,简称《中图法》,现为第五版。包括22个基本大类,其中,T大类可以根据内容进一步细分为两个字母组成的细分类,具体如下:
A马克思主义、列宁主义、毛泽东思想、邓小平理论
B哲学、宗教
C社会科学总论
D政治、法律
E军事
F经济
G文化、科学、教育、体育
H语言、文字
I文学
J艺术
K历史、地理
N自然科学总论
O数理科学和化学
P天文学、地球科学
Q生物科学
R医药、卫生
S农业科学
T工业技术
TB 一般工业技术
TD 矿业工程
TE 石油、天然气工业
TF 冶金工业
TG 金属学、金属工艺
TH 机械、仪表工艺
TJ 武器工业
TK 能源与动力工程
TL 原子能技术
TM 电工技术
TN 电子技术、通信技术
TP 自动化技术、计算机技术
TQ 化学工业
TS 轻工业、手工业、生活服务业
TU 建筑科学
TV 水利工程
U交通运输
V航空、航天
X环境科学、安全科学
Z综合性图书
# 输出格式要求
必须以 JSON 格式输出,包含以下字段:
- classification: 仅包含中图法基本大类字母
- reason: 生成该分类号的理由说明
示例输出:
{
"classification": "TP",
"reason": "该书主题为Python编程,属于计算机编程技术领域。根据中图法,TP为工业技术大类下的自动化技术、计算机技术。"
}"
设定用户提示词:
“请根据以下图书信息生成中图法基本大类的字母:
书名:${Start_0dYE.book_title}
摘要:${LLM_ZaaV.result}
请分析该图书的主题和学科领域,并生成合适的基本大类。''
这两个变量分别为开始时输入的书名 和 大模型补全的摘要内容
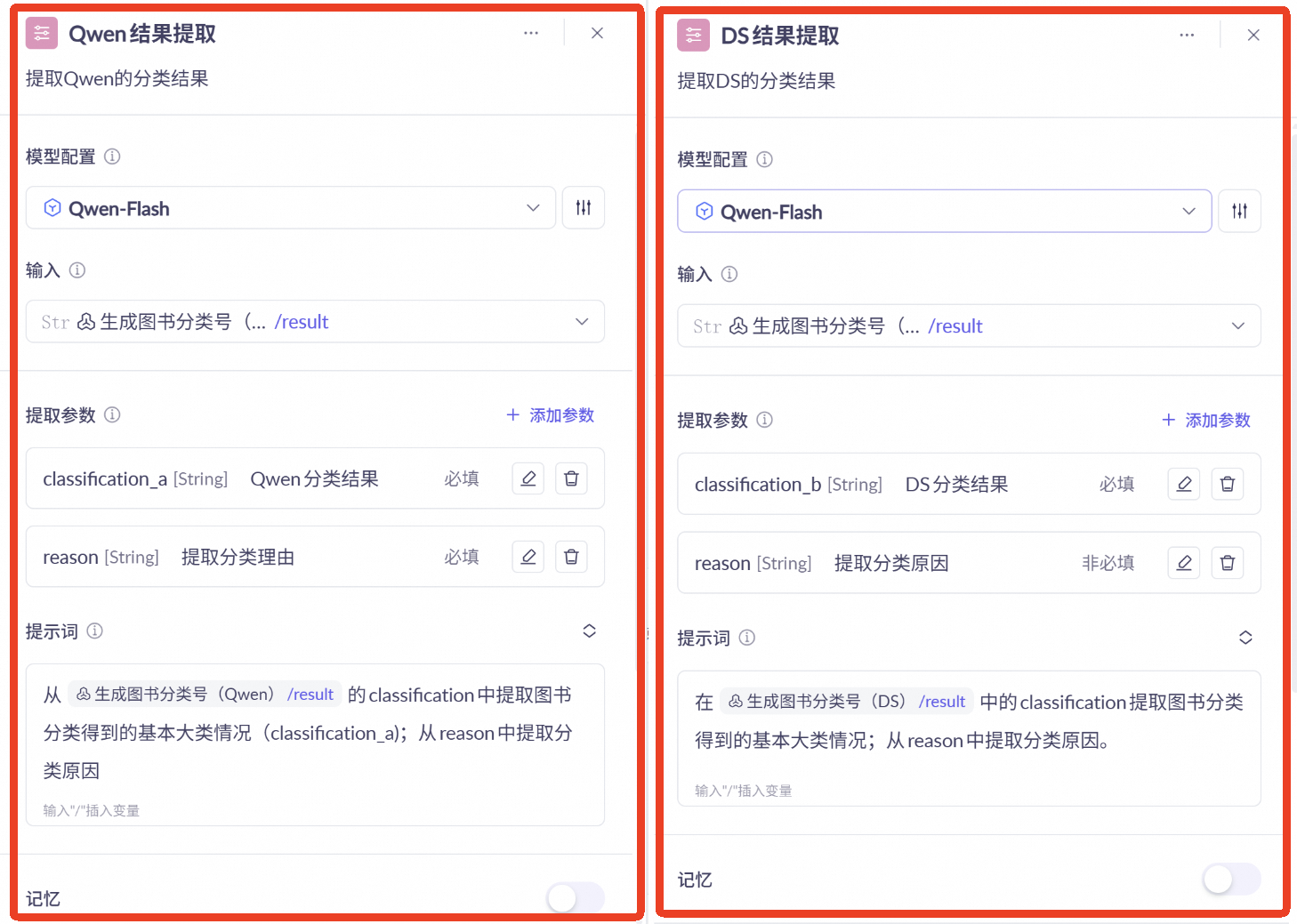
参数提取节点
由于大模型输出结果不能直接以结构化的形式返回,因此引入两个参数提取节点进行提取
两个节点均使用Qwen-Flash模型
设定提示词
“从大模型结果(需替换成对应变量)的classification中提取图书分类得到的基本大类情况;从reason中提取分类原因”
条件判断节点:比较前序两个节点分类的结果
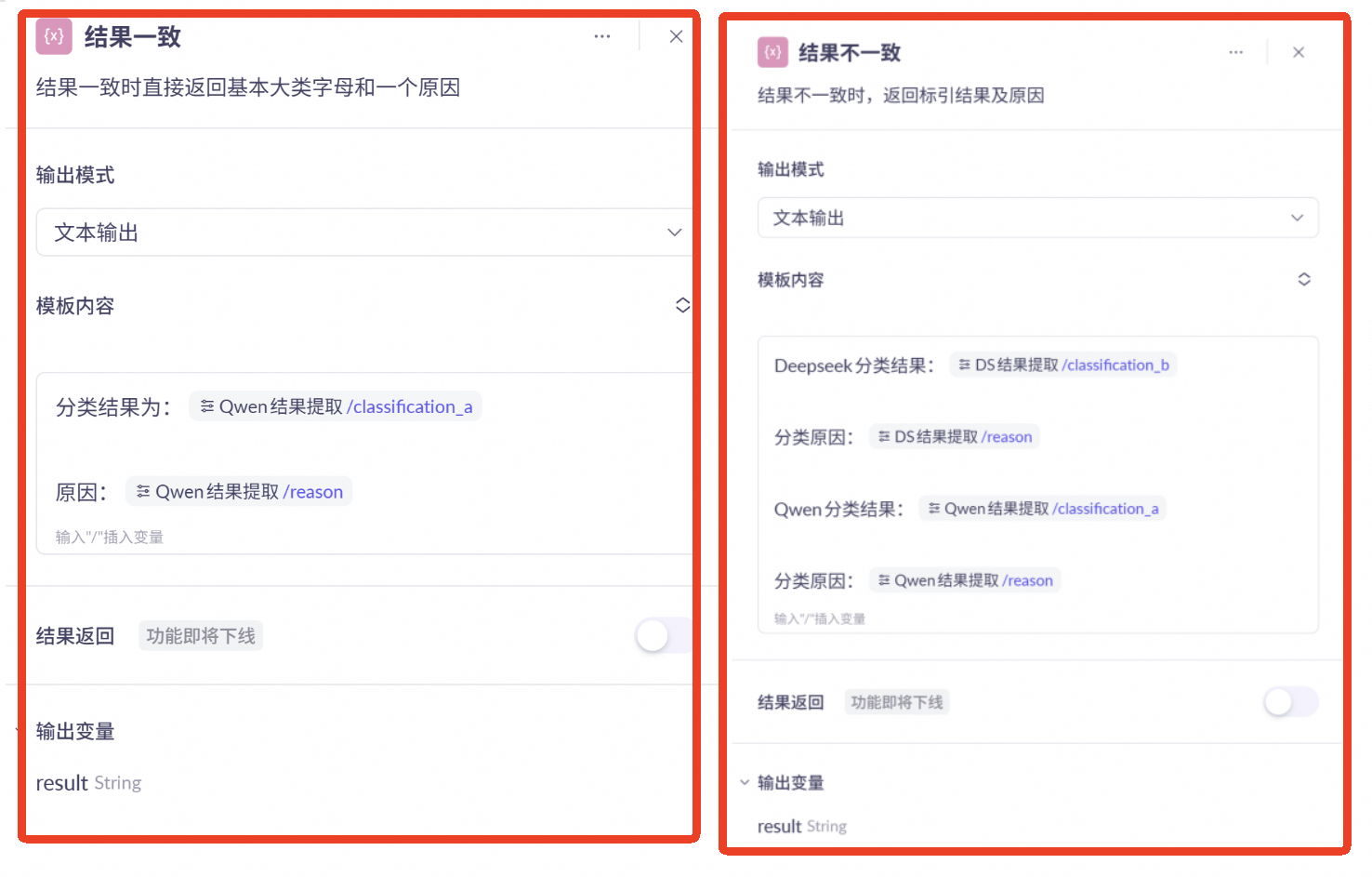
结果输出节点:
分别设置变量处理节点
选择“文本输出”模式
连接到不同前序条件判断的分支
根据结果分别参考输出模板撰写内容
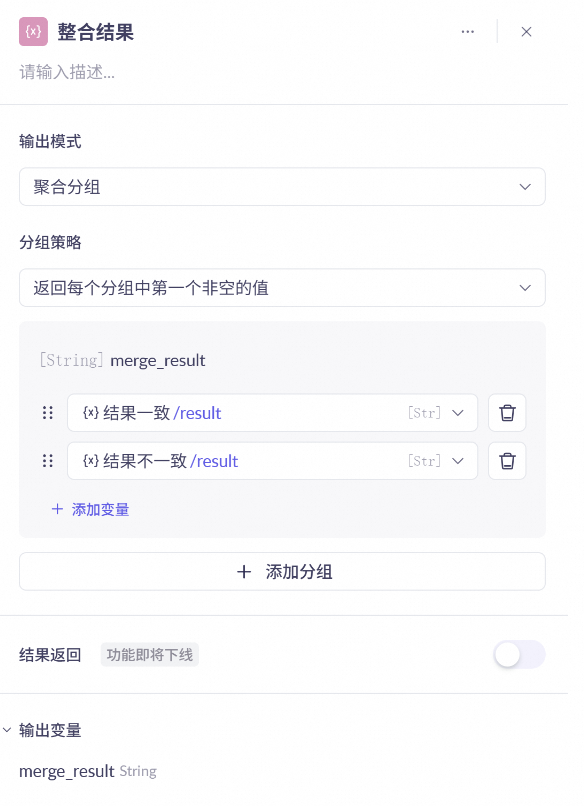
整合结果节点:
选择“聚合分组”输出模型
选择分组策略为“返回每个分组中第一个非空的值”
并选择前序两个结果(注意需要节点相连)
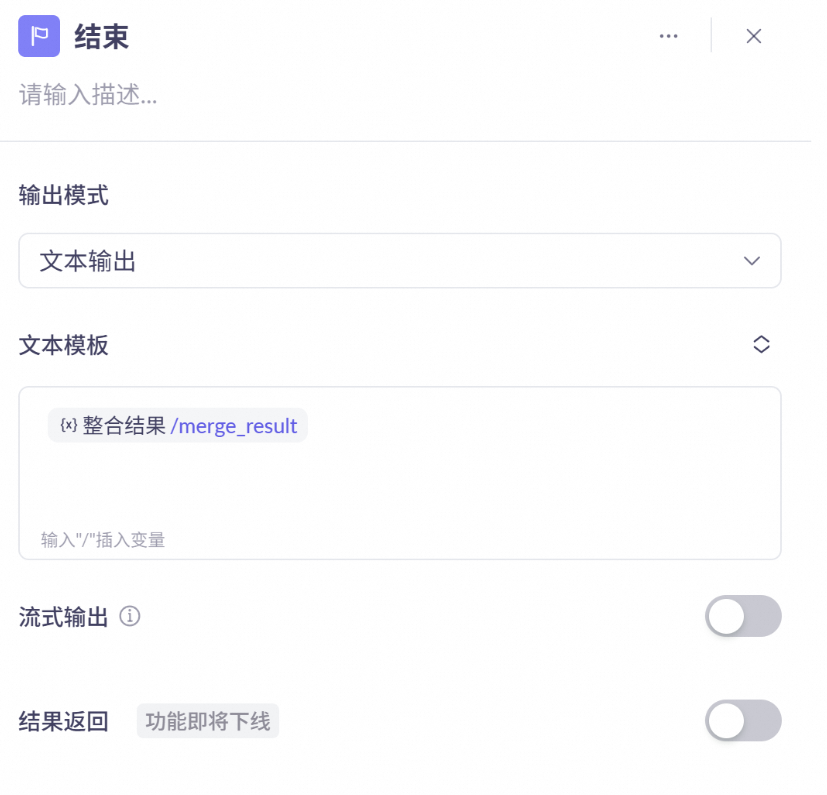
结束节点:输出整合结果节点的返回结果
测试工作流
工作流中的每一个大模型节点均可以单独测试,如下图。建议设计者测试每一个大模型节点的效果,并调整prompt和参数以提高可用性
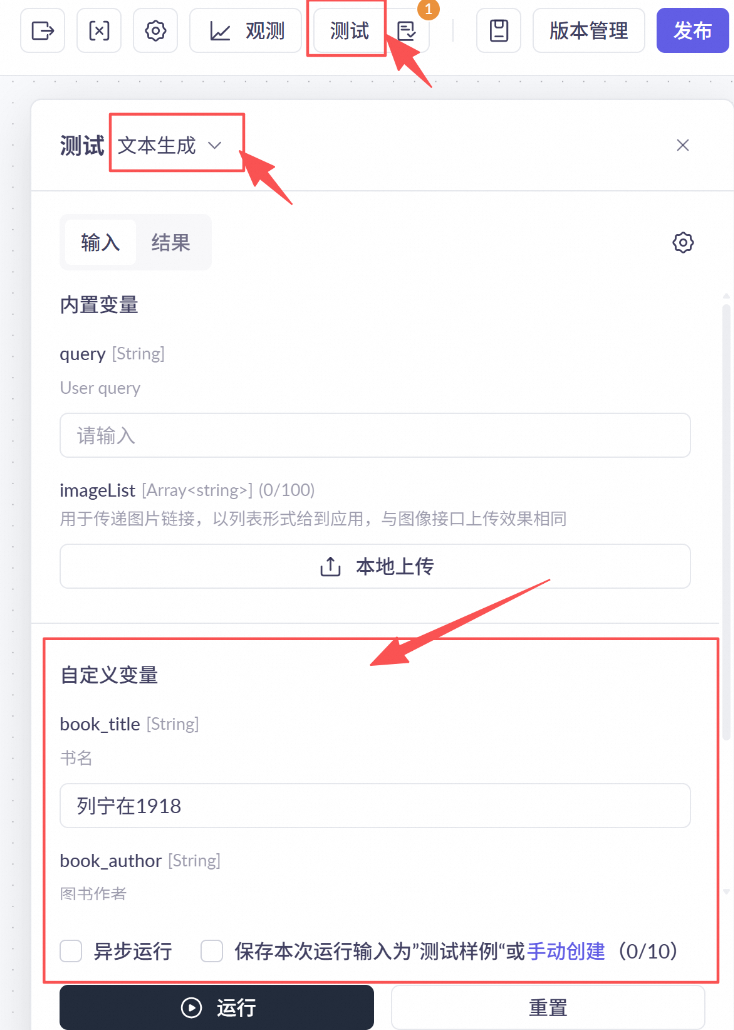
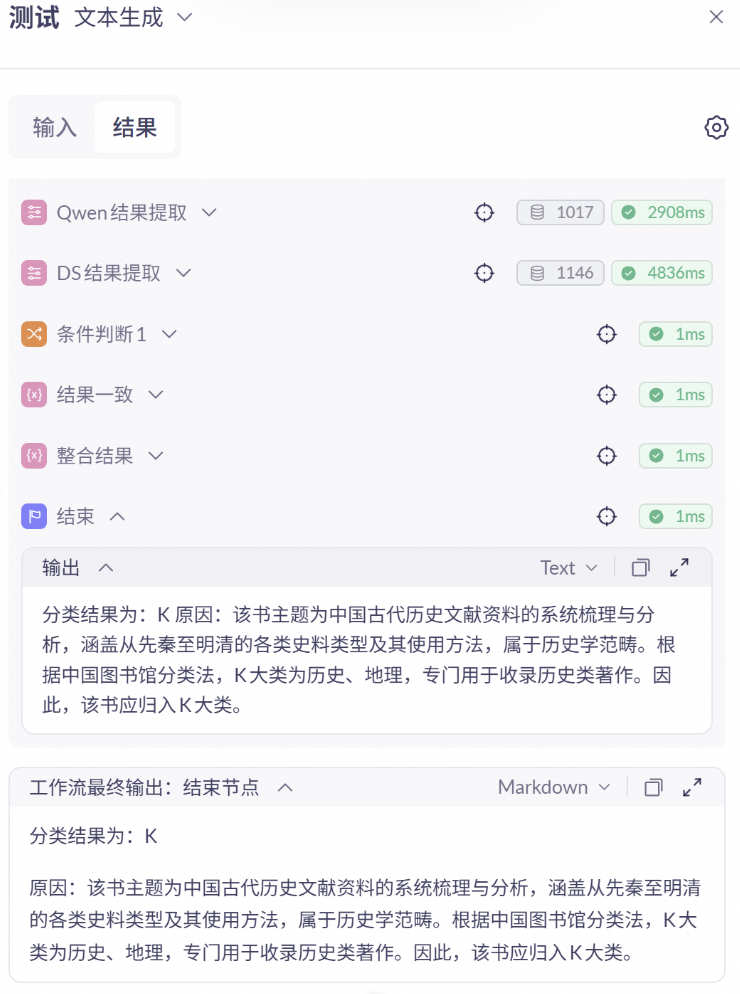
如果每一个节点都比较稳定,可以点击画布上方的“测试”查看整个工作流的效果。由于我们要求输入的是结构化的文本,请选择“文本生成”功能,并在自定义变量中输入书名等信息,点击“运行”查看结果。工作流会根据流程依此返回每一个节点的结果和最终结果
测试样例:
列宁在1918 兹拉托戈洛瓦 (Zlatogorova, T.) 全国图书馆文献缩微中心
(分类结果应为I)
工业企业统计分析原理 胡永良 南开大学出版社
(分类结果应为F)
中国古代史史料学 何忠礼 上海古籍出版社
(分类结果应为K)
检查运行结果是否出错,如有问题可到对应节点中查看。
发布工作流
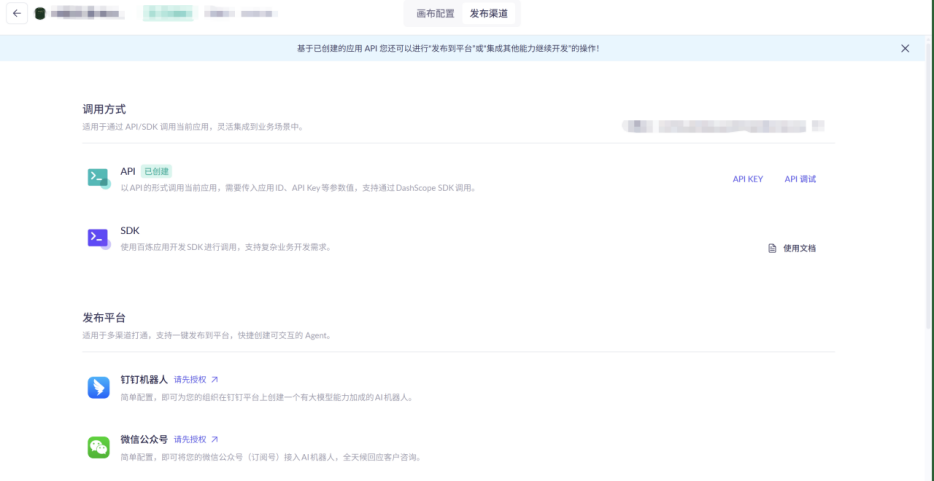
当结果符合预期后,点击画布右上角的发布,就可以将写好的工作流分享给其他人使用。可以根据需要选择不同的发布渠道
实验资源释放
重要注意:
销实验结束后,阿里云百炼账号无需注销,无资源释放。如已发布应用至其他渠道中,请关注token消耗量;
在阿里云百炼,模型训练部署等需要付费,请谨慎操作。模型体验、构建应用等需要消耗Token,在测试前请先确认是否有免费额度。
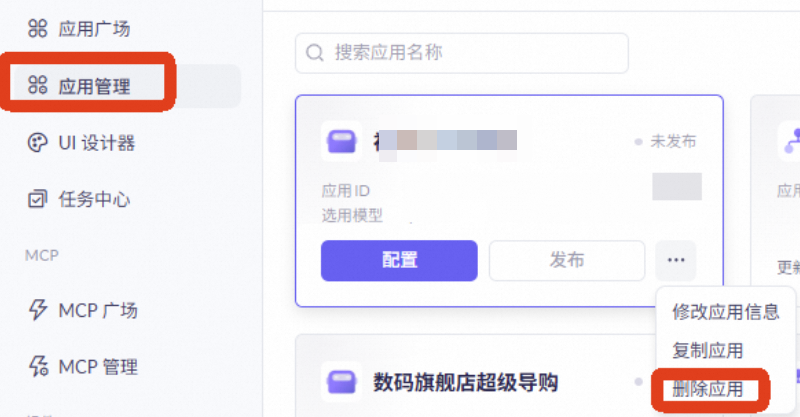
删除智能体应用
登录阿里云百炼控制台,进入应用管理页面。找到创建的智能体应用,点击应用名称进入详情页。在应用配置页面,找到删除应用的选项并确认删除。此操作将释放与该应用关联的模型配置、MCP服务集成以及知识库关联。


背景知识
本场景主要涉及产品:阿里云百炼。
在本实验中,需要注意您当前账号中是否有免费额度,若无免费额度或免费额度已过期,本次实验会消耗token,可能产生费用。
模型token费用:请查看模型列表:模型列表
如何查看模型免费额度:登录阿里云百炼,在【模型】—【模型广场】—【全部模型】对应模型卡片查看详情,查看模型的免费额度,也可以关注系统管理-系统工具中的调用统计。
关闭实验
完成实验后,点击 结束实操
点击 取消 回到实验页面,点击 确定 退出实验界面,关闭页面结束实验
说明阿里云百炼账号无需注销