
PPU ECC处理流程(v2.1)
1. ECC 介绍
ECC 全称是 Error Correct Code,是一种硬件数据校验算法。相比奇偶校验,ECC 可以实现 single bit 错误的自动纠正,以及 double bit 错误的上报。后面我们把 single bit ecc 简称为 CECC (correctable ECC),double bit ecc 简称为 UECC (uncorrectable ECC)。
PPU 1.0 HBM 有多种校验方式:
- 数据:ECC校验(已默认打开)校验失败上报 ECC exception(only read 触发)。
- 地址和命令:奇偶校验(已默认打开)校验失败上报 parity exception(read write 都会校验)。2. ECC 发生监控
2.1 带内
当监控到 ECC 发生之后,应当立刻参考 Section3 进行现场处理
在 dmesg 中看到 exception ,使用下面命令如果可以搜索到证明发生了 UECC。
dmesg | grep "uncorrected ECC error detected"
通过 ECC counter 查询是否发生 UECC
ppu-smi -q -d ECC

当看到 Volatile DRAM Uncorrectable 的数字大于零,证明此时发生了 UECC。
Aggregate 的数量包含这颗芯片从出厂到当前发生过的总次数,所以通常 reboot 之后 Aggregate 可能会大于零
如果是通过k8s监控组件,可以直接调用nvmlDeviceGetTotalEccErrors接口来查询UECC的信息。
当查询到 count 大于零证明发生了 UECC
unsigned long long count; auto result = nvmlDeviceGetTotalEccErrors( device_handle, NVML_MEMORY_ERROR_TYPE_UNCORRECTED, NVML_VOLATILE_ECC, &count); if (result == NVML_SUCCESS) { std::cout << "UECC counter" << count << "\n"; }
2.2 带外
参考 Ehost Programming Guide BMC_MSG_ID_QUERY_ECC_STATUS
3. ECC 现场处理
当前版本的驱动支持dynamic page retirement,当发生 UECC 之后,所有用户进程会收到错误退出,在最后一个进程退出的时候,驱动会把发生错误的 PPU page (64KB) 做屏蔽(retirement),这样不需要做 PPU reset 或者重启,重新拉起用户进程就可以继续使用。基于这样的机制,ECC 发生之后可以参考这样的处理流程:
UECC 发生之后,处理流程:
当检测到UECC发生之后,第一步需要检查是否还有残留的用户进程需要尽快 kill 掉。
所有进程退出的时候,驱动会把出错的 PPU page 做屏蔽,用户会发现 PPU device memory 有减少,不需要做PPU reset或者重启,重新拉起用户进程可以继续使用。
如果多次发生 UECC,PPU device memory 减少数量过多可能会影响用户正常使用,推荐尽快做一次PPU reset或者重启修复 UECC。
驱动在重启的过程中会对之前发生UECC的memory page进行repair(memory cell replace) 和 retirement操作 (加入黑名单),确保这次驱动加载以后用户不会再碰到这些发生过UECC的显存区域。具体可参考 section5。
CECC 发生:
CECC 发生用户不会感知到,但是大量 CECC 发生之后驱动也会做 retirement,这个时候用户会发现 PPU device memory 有所减少。
不需要PPU reset或者重启,用户进程可以继续正常执行。
4. ECC RMA criteria
如果同一张卡上发生UECC的数量太多,意味着这颗芯片本身质量已经不可靠,应该需要下线退休。ptg 定义的 RMA 共有三种:
4.1 A remapping attempt to repair a bank has used all 4-repair resource and exhausted
4.1.1 可以通过 ppu-smi 查询现在 remap 的整体情况
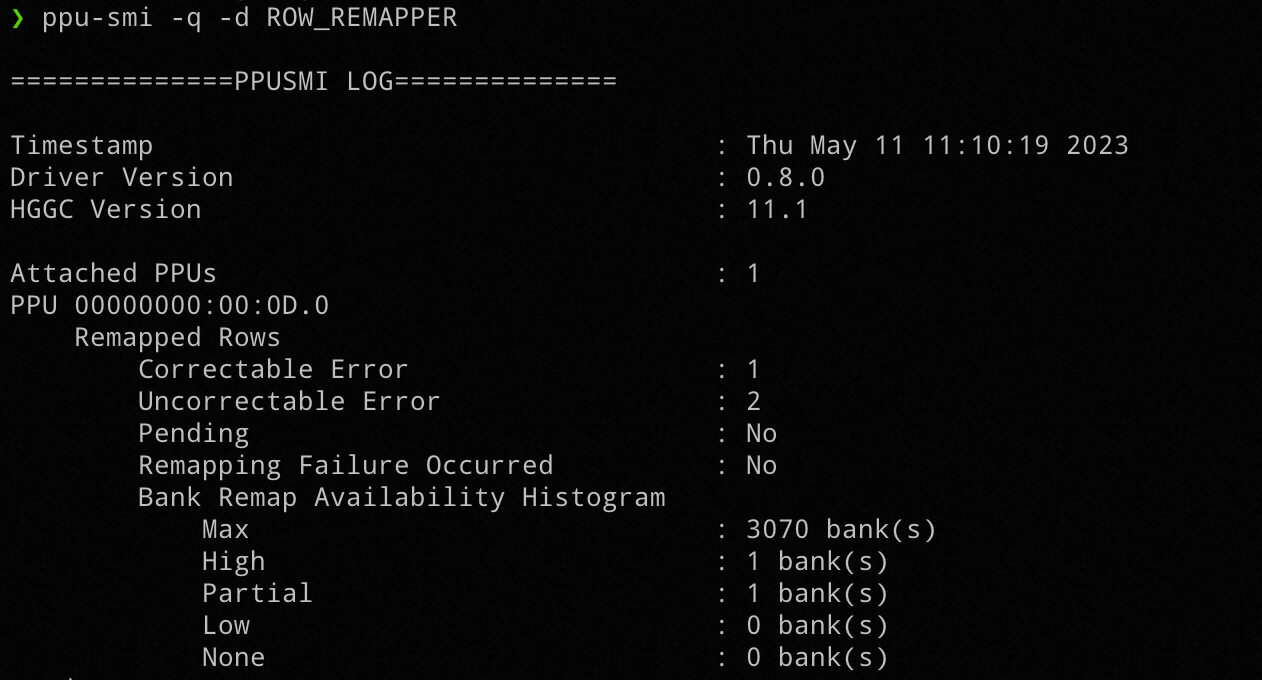
Remapping Failure Occurred 被置为 Yes 的时候满足 a。
4.1.2 如果是通过k8s监控组件,可以直接调用nvmlDeviceGetRemappedRows来获取
unsigned int *corrRows;
unsigned int *uncRows;
unsigned int *isPending;
unsigned int *failureOccurred;
auto result = nvmlDeviceGetGetRemappedRows(
device_handle, corrRows, uncRows,
isPending, failureOccurred);
if (result == NVML_SUCCESS) {
std::cout << "Row Remapped fail happened:" << *failureOccurred << "\n";
}4.2 A remapping attempt to the failure address which has been remapped previously
4.2.1 可以通过 ppu-smi 查询现在 remap 的整体情况
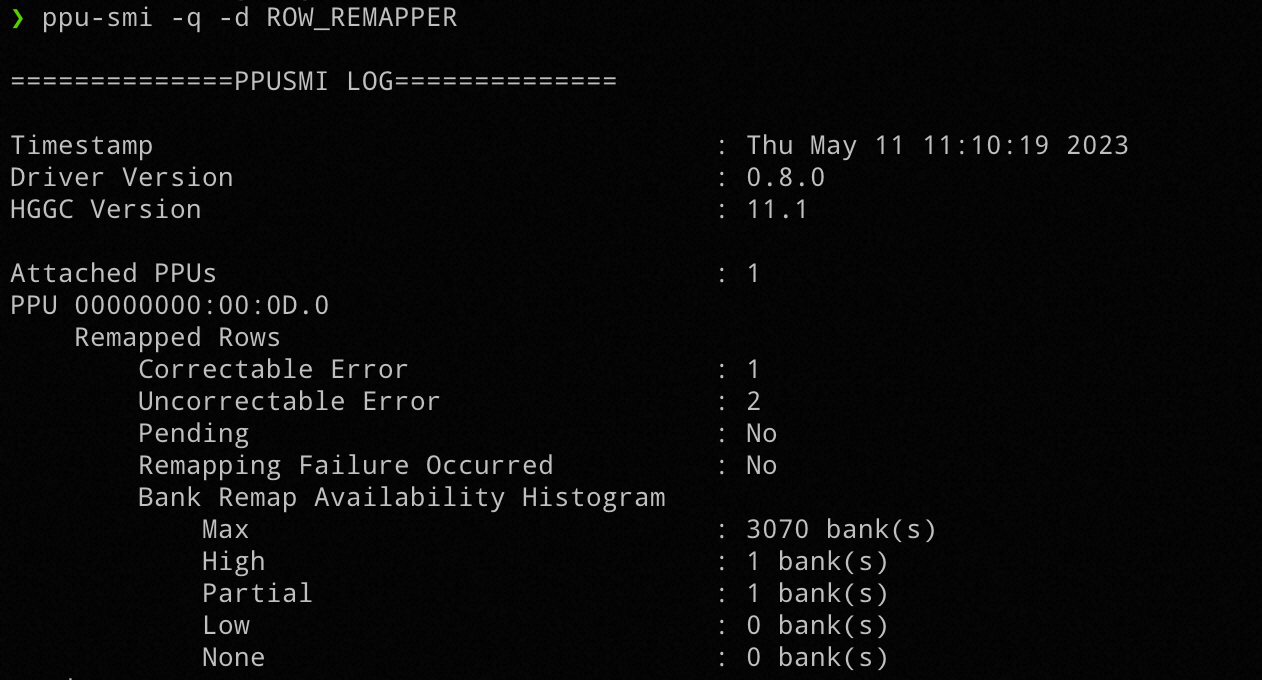
Remapping Failure Occurred 被置为 Yes 的时候满足 b。
4.2.2 如果是通过k8s监控组件,可以直接调用nvmlDeviceGetRemappedRows来获取
unsigned int *corrRows;
unsigned int *uncRows;
unsigned int *isPending;
unsigned int *failureOccurred;
auto result = nvmlDeviceGetGetRemappedRows(
device_handle, corrRows, uncRows,
isPending, failureOccurred);
if (result == NVML_SUCCESS) {
std::cout << "Row Remapped fail happened:" << *failureOccurred << "\n";
}4.3 A total number of 1024 repair resource used
4.3.1 查询方式同 4.1.1
Histogram 中 None & Low & Partial & High banks 加起来大于 1024 满足 c。
4.3.2 如果是通过k8s监控组件,可以直接调用nvmlDeviceGetRowRemapperHistogram来获取
nvmlRowRemapperHistogramValues_t *values
auto result = nvmlDeviceGetRowRemapperHistogram(
device_handle, values);
if (result == NVML_SUCCESS) {
std::cout << "Bank number:" <<
(value->high + value->partial + value->low + value->none) << "\n";
}5. ECC 处理逻辑简介
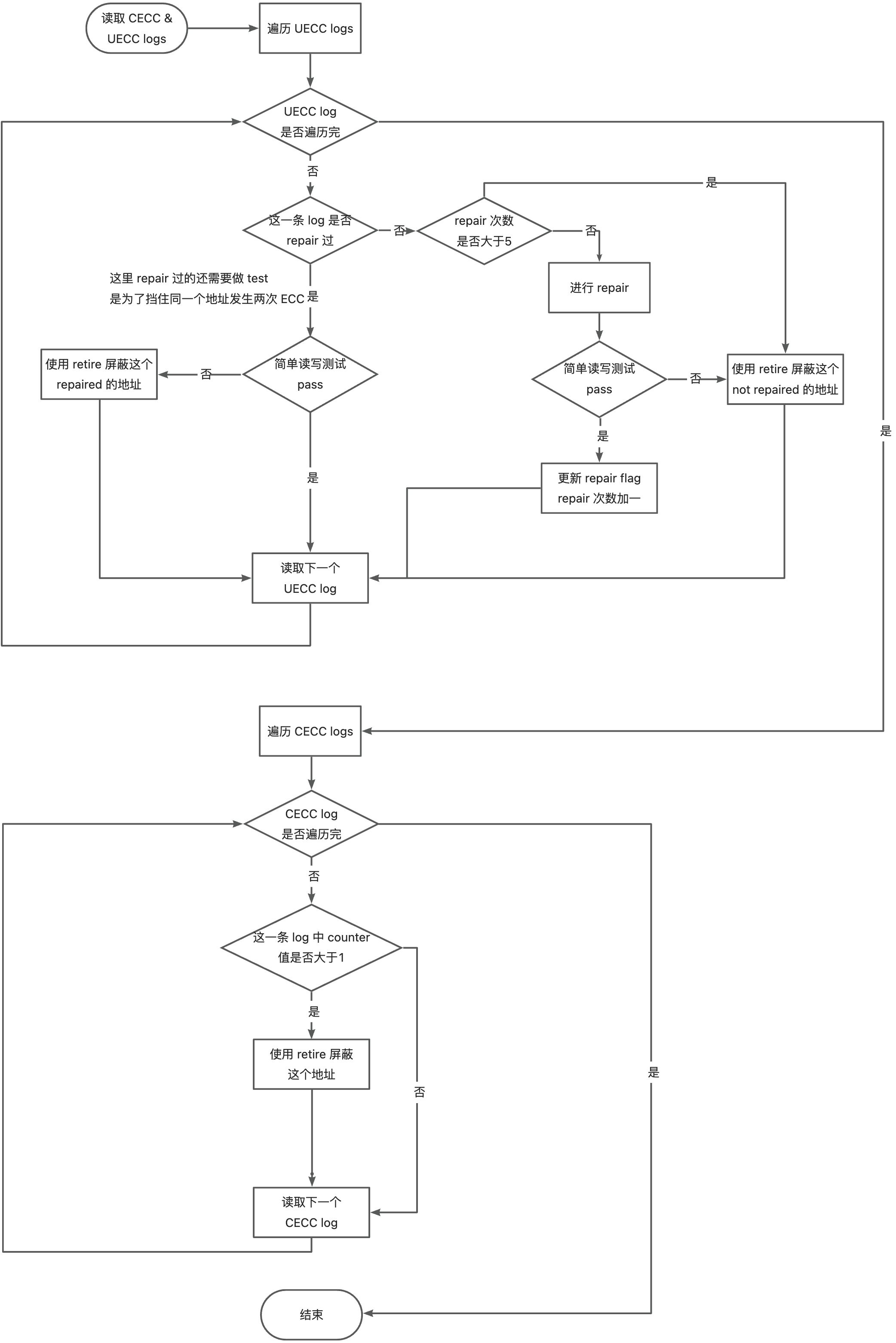
目前 ecc fix 主要有两种策略来 handle:
- 软件在 allocator 屏蔽掉错误地址,保证用户不会分到这一块 memory(<font style="color:#DF2A3F;">GPU page retirement</font>)
- 使用 HBM vendor 提供的 cell repair 功能修复坏块(<font style="color:#DF2A3F;">GPU memory repair</font>)
load driver 中 ecc handling 的 default 策略:
- 首先从 flash 中读取所有的 ecc entry,包括 CECC & UECC,并且对同一地址的 ecc entry 进行合并,也就是说 driver 中维护的 ecc list 每一条都是不同的地址
- 其次对所有 entry 进行 遍历 repair
* 如果没有 repair 过的直接进行 repair,repair 过后都会对这个地址进行简单的读写测试,
* 如果是已经 repair 过的地址,直接进行读写测试。
* 如果 这个地址已经没有错误了且刚进行了一次 repair,则更新 flash 中对应的 repair flag。
* 由于 repair sequence 过长且每一次都需要 reset HBM,driver 在每次 load 期间最多做 **<font style="color:#DF2A3F;">5</font>** 次 repair,之后不会做 repair。
- 如果做完 5 次 repair 之后还存在未处理的 ecc entry,软件会把这个地址按照 GPU page(64KB) 的粒度做屏蔽,page retirement
- UECC 优先级高于 CECC,当且仅当处理完所有的 UECC entry 才会处理 CECC
- CECC repair 的条件是永远不做 repair
- CECC retire 的条件是同一个地址发生 CECC 超过 **<font style="color:#DF2A3F;">2</font>** 次
流程图如下:
5.1 GPU page retirement
每一条 ecc entry 中包含了 driver 使用的 pa 信息,driver 会在所有用户使用 device memory 之前将 allocator 中包含这个错误地址的 GPU page reserve 出去,保证后面的所有 device memory 分配不会 touch 到这一块 memory。
5.2 GPU memory repair
每一条 ecc entry 中包含了这一次 exception 的 row bank sid col 等信息,通过 P1500 接口发送相关的 command,可以将某一个 bank 中已经损坏的 row 做一次替换。