
在AI领域的大语言模型LLM(Large Language Model)应用中,检索增强生成RAG(Retrieval-augmented Generation)技术通过检索外部的辅助知识库,能够显著提升模型输出的准确性和时效性,解决了LLM知识更新慢、容易产生幻觉(回答不准确)的问题。与传统的关键词检索相比,向量检索具备语义层面的相似性检索能力,支持非结构化数据和多模态数据检索。PostgreSQL的pgvector插件,能够在保持PostgreSQL原有结构化数据管理能力的基础上,支持向量检索功能。DTS的数据同步能力,能够将写入到PostgreSQL数据库的向量数据快速地更新至不同地域的其他数据库中,帮助您在数据密集型场景中实现异地容灾、低延迟查询、实时决策、多区域数据分析等。
前提条件
了解DTS同步实例支持的源库和目标库的版本。更多信息,请参见同步方案概览。
了解DTS在PostgreSQL数据库间单向同步的注意事项、费用信息、增量同步支持的SQL操作。更多信息,请参见附录。
已将自建PostgreSQL数据库接入至阿里云。更多信息,请参见本地IDC接入至阿里云、将AWS平台的数据库接入至阿里云、将Azure平台的数据库接入至阿里云。
已在自建PostgreSQL数据库中,准备一个具备superuser权限的账号,以便于进行数据同步。更多信息,请参见CREATE USER和GRANT。
方案概览
创建数据库实例
创建目标RDS PostgreSQL实例。
创建账号
在目标RDS PostgreSQL实例中,创建用于数据同步的账号。
创建数据库
在目标RDS PostgreSQL实例中,创建用于接收数据的数据库。
安装插件
在目标RDS PostgreSQL实例中,为目标数据库安装pgvector插件,以支持写入vector类型的数据。
创建数据同步实例
使用DTS进行数据同步操作。
准备工作
以下以Linux系统为例。
登录自建PostgreSQL所属的服务器。
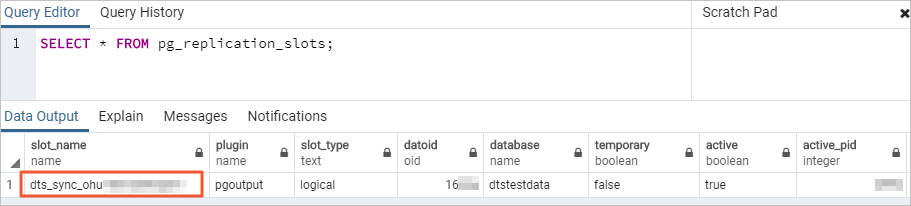
执行如下命令,查询数据库已使用复制槽数量。
select count(1) from pg_replication_slots;修改配置文件
postgresql.conf,将配置文件中的wal_level设置为logical,并确保max_wal_senders和max_replication_slots的参数值,均大于数据库复制槽已使用数与需要以该自建PostgreSQL为源创建的DTS实例数的总和。# - Settings - wal_level = logical # minimal, replica, or logical # (change requires restart) ...... # - Sending Server(s) - # Set these on the master and on any standby that will send replication data. max_wal_senders = 10 # max number of walsender processes # (change requires restart) #wal_keep_segments = 0 # in logfile segments, 16MB each; 0 disables #wal_sender_timeout = 60s # in milliseconds; 0 disables max_replication_slots = 10 # max number of replication slots # (change requires restart)说明配置文件修改完成后,您需要重启自建PostgreSQL使参数生效。
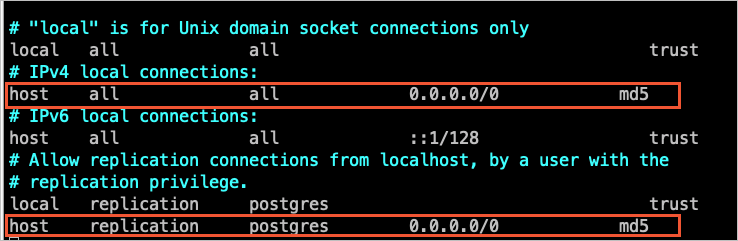
将DTS的IP地址加入至自建PostgreSQL的配置文件pg_hba.conf中。您只需添加目标数据库所在区域对应的DTS IP地址段,详情请参见添加DTS服务器的IP地址段。
说明配置文件修改完成后,您需要执行
SELECT pg_reload_conf();命令或重启自建PostgreSQL使参数生效。关于该配置文件的设置请参见pg_hba.conf文件。如果您已将信任地址配置为
0.0.0.0/0(如下图所示),可跳过本步骤。
根据待同步对象所属的数据库和Schema信息,在目标RDS PostgreSQL中创建相应数据库和Schema(Schema名称须一致),详情请参见创建数据库和Schema管理。
步骤一:创建数据库实例
进入RDS实例购买页面。
选择实例的配置参数。
将引擎选择为14、15或16版本的PostgreSQL,其他参数请根据实际情况选择。更多信息,请参见创建RDS PostgreSQL实例。
确认订单信息、购买量和购买时长(仅包年包月实例),勾选服务协议,单击去支付,并完成支付。控制台将提示支付成功或开通成功。
说明对于包年包月实例,建议选中启用自动续费,避免因忘记续费而导致业务中断。
按月购买,自动续费周期为1个月;按年购买,自动续费周期为1年,具体以订单时间为准。自动续费可随时取消。更多详情,请参见续费管理/资源续订使用介绍和自动续费。
查看实例。
进入实例列表,在上方选择实例所在地域,根据创建时间找到刚刚创建的实例。
说明实例创建需要约1~10分钟。请刷新页面查看。
查看目标RDS PostgreSQL实例的内核小版本。
实例创建成功后,单击目标实例的ID。
在目标实例的基本信息页面的配置信息区域,查看小版本信息。
确保目标实例的内核小版本为20230430或以上。
说明若目标RDS PostgreSQL实例的内核小版本不满足要求,请进行升级操作。更多信息,请参见升级内核小版本。
步骤二:创建账号
步骤三:创建数据库
步骤四:安装插件
访问RDS实例列表,在上方选择地域,然后单击目标实例ID。
在左侧导航栏单击插件管理。
在插件市场页签单击AIGC,并单击vector卡片的安装。
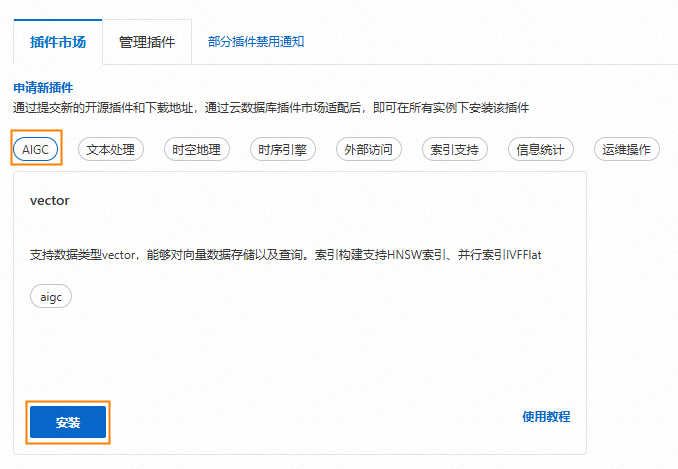
在弹出的对话框,选择数据库名称和数据库账户。
单击安装。
您可以在页面,查看插件的安装情况。

步骤五:创建数据同步实例
本操作以简易配置为例,为您进行介绍创建数据同步实例的方法。更多信息,请参见自建PostgreSQL同步至RDS PostgreSQL。
进入目标地域的同步任务列表页面(二选一)。
通过DTS控制台进入
登录数据传输服务DTS控制台。
在左侧导航栏,单击数据同步。
在页面左上角,选择同步实例所属地域。
通过DMS控制台进入
说明实际操作可能会因DMS的模式和布局不同,而有所差异。更多信息,请参见极简模式控制台和自定义DMS界面布局与样式。
登录DMS数据管理服务。
在顶部菜单栏中,选择。
在同步任务右侧,选择同步实例所属地域。
单击创建任务,进入任务配置页面。
可选:在页面右上角,单击试用新版配置页。
说明若您已进入新版配置页(页面右上角的按钮为返回旧版配置页),则无需执行此操作。
新版配置页和旧版配置页部分参数有差异,建议使用新版配置页。
配置源库及目标库信息。
类别
配置
说明
源库信息
数据库类型
选择PostgreSQL。
接入方式
请根据源库的部署位置进行选择,本示例选择专线/VPN网关/智能网关。
说明源库为自建数据库时,您需要执行相应的准备工作。更多信息,请参见准备工作概览。
实例地区
选择自建PostgreSQL数据库所属专有网络VPC的地域。
是否跨阿里云账号
本示例使用当前阿里云账号下的数据库实例,需选择不跨账号。
已和源端数据库联通的VPC
选择与自建PostgreSQL数据库所属的专有网络VPC。
域名或IP地址
填入自建PostgreSQL数据库的服务器IP地址。
端口
填入自建PostgreSQL数据库提供服务的端口,默认为3433。
数据库名称
填入自建PostgreSQL数据库中待同步对象所属数据库的名称。
数据库账号
填入自建PostgreSQL数据库中具备superuser权限的账号。
数据库密码
填入该数据库账号对应的密码。
连接方式
请根据实际情况选择,本示例保持默认的非加密连接。
目标库信息
数据库类型
选择PostgreSQL。
接入方式
选择云实例。
实例地区
选择步骤一:创建数据库实例创建的RDS PostgreSQL实例所属的地域。
实例ID
选择步骤一:创建数据库实例创建的RDS PostgreSQL实例的ID。
数据库名称
填入步骤三:创建数据库创建的数据库。
数据库账号
填入步骤二:创建账号创建的账号。
数据库密码
填入该数据库账号对应的密码。
连接方式
请根据实际情况选择,本示例保持默认的非加密连接。
配置完成后,在页面下方单击测试连接以进行下一步。
说明请确保DTS服务的IP地址段能够被自动或手动添加至源库和目标库的安全设置中,以允许DTS服务器的访问。更多信息,请参见添加DTS服务器的IP地址段。
若源库或目标库为自建数据库(接入方式不是云实例),则还需要在弹出的DTS服务器访问授权对话框单击测试连接。
配置任务对象。
在对象配置页面,配置待同步的对象。
配置
说明
同步类型
默认已选中增量同步,本示例同时选中库表结构同步和全量同步。
同步拓扑
本示例为单向同步,需选择单向同步。
目标已存在表的处理模式
保持默认的预检查并报错拦截。
源库对象
在源库对象框中,选中待同步的对象,然后单击
 将其移动至已选择对象框。重要
将其移动至已选择对象框。重要若待同步的表有依赖的序列(Sequence),且目标Schema中没有同名的Sequence,您还需要在源库对象框中选中该Sequence。
已选择对象
本示例无需额外配置,保持默认即可。
单击下一步高级配置,进行高级参数配置。
本示例无需进行修改,保持默认的配置。
单击下一步数据校验,进行数据校验任务配置。
本示例不使用数据校验功能,保持默认的配置。
单击页面下方的下一步保存任务并预检查。
预检查通过率显示为100%时,单击下一步购买。
购买实例。
在购买页面,选择数据同步实例的计费方式、链路规格,详细说明请参见下表。
本示例无需进行修改,保持默认的配置。
勾选《数据传输(按量付费)服务条款》。
单击购买并启动,并在弹出的确认对话框,单击确定。
您可在数据同步界面查看具体任务进度。
附录
注意事项
类型 | 说明 |
源库限制 |
|
其他限制 |
|
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
增量同步支持的SQL操作
操作类型 | SQL操作语句 |
DML | INSERT、UPDATE、DELETE |
DDL |
|