数据传输服务DTS(Data Transmission Service)提供的流式数据ETL(Extract Transform Load)数据处理功能,结合DTS的高效流数据复制能力,可以实现流式数据的抽取、数据转换、加工和数据装载。本文介绍在DTS链路内配置ETL的操作步骤及相关语法信息,帮助您在数据过滤、数据脱敏、记录数据修改时间和数据变更审计等场景下使用ETL功能。
背景信息
DTS是一个数据迁移和同步服务,通常用于数据搬迁或实时数据传输。但有时候用户有数据处理的需求,希望先对实时数据做一定转换或过滤,再写入库。为了满足此类需求,DTS提供了流式数据ETL数据处理功能,支持使用DSL(Domain Specific Language)脚本语言灵活地定义数据处理逻辑。DSL的介绍及配置语法,请参见数据处理DSL语法简介。
支持的数据库
ETL支持的源库和目标库如下表所示。
源库 | 目标库 |
SQL Server |
|
MySQL |
|
自建Oracle |
|
PolarDB MySQL版 |
|
PolarDB PostgreSQL版(兼容Oracle) |
|
PolarDB-X 1.0 |
|
PolarDB-X 2.0 |
|
自建Db2 for LUW | MySQL |
自建Db2 for i | MySQL |
PolarDB PostgreSQL |
|
PostgreSQL |
|
TiDB |
|
MongoDB | Lindorm |
在创建同步任务时配置ETL
注意事项
如果您配置的ETL脚本中,包含新增列操作,那么需要您手动在目标端添加列。否则ETL脚本不生效。例如
script:e_set(`new_column`, dt_now()),此处new_column需要您手动在目标端添加。DSL脚本主要处理的是数据转换、清洗等操作,不支持创建数据库对象。
DSL脚本配置的字段需在源库中存在,且不能为过滤条件过滤的字段,否则会导致任务异常。
DSL脚本大小写敏感,库名、表名、字段名称需要和源库保持完全一致。
DSL脚本不支持多个表达式,您可以使用
e_compose函数将多个表达式组合成一个表达式。源库所有表的DML变更,经过DSL脚本处理后需具有相同的列信息,否则可能会导致任务失败。例如,在DSL脚本中使用
e_set函数新增列时,需要设置源库的INSERT、UPDATE或DELETE操作,均会在目标表中增加一列数据。更多信息,请参见记录数据修改时间。
操作步骤
在已有同步任务上修改ETL配置
修改已有同步任务的ETL配置包括:
如果已有同步任务未配置ETL,即创建同步任务时配置ETL功能设置为否,支持将否修改为是,并配置DSL脚本。
如果已有同步任务已配置ETL,支持修改已有的DSL脚本或将配置ETL功能修改为否。
重要在修改已有的DSL脚本时,您需要先将同步对象从已选择对象移动至源库对象,再重新添加至已选择对象后,再修改DSL脚本。
迁移任务不支持修改DSL脚本。
注意事项
已有同步任务上修改ETL配置暂不支持对目标端表的表结构进行变更,如果需要变更,您需要在启动同步任务前在目标端变更表结构。
修改ETL配置可能造成链路中断,请谨慎操作。
ETL配置的修改仅对启动同步任务后的增量数据生效,对修改ETL配置前的历史数据不生效。
DSL脚本主要处理的是数据转换、清洗等操作,不支持创建数据库对象。
DSL脚本配置的字段需在源库中存在,且不能为过滤条件过滤的字段,否则会导致任务异常。
DSL脚本大小写敏感,库名、表名、字段名称需要和源库保持完全一致。
DSL脚本不支持多个表达式,您可以使用
e_compose函数将多个表达式组合成一个表达式。源库所有表的DML变更,经过DSL脚本处理后需具有相同的列信息,否则可能会导致任务失败。例如,在DSL脚本中使用
e_set函数新增列时,需要设置源库的INSERT、UPDATE或DELETE操作,均会在目标表中增加一列数据。更多信息,请参见记录数据修改时间。
操作步骤
在目标同步任务中单击
 ,选择修改ETL配置。
,选择修改ETL配置。在高级配置阶段,将配置ETL功能选择为是。
在输入框中,按照数据处理DSL语法填写数据处理(ETL)语句。
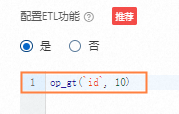 说明
说明例如使用DSL来处理id大于3的记录,此处以
script:e_if(op_gt(`id`, 3), e_drop())为例。op_gt为表达式函数,判断是否大于某个值,id为变量。此时通过该脚本可过滤id大于3的记录。根据实际情况,完成后续步骤。
数据处理DSL语法简介
典型场景示例
数据过滤
按数值列条件过滤:如果id>10000,则丢弃这条记录,不同步到目标库:e_if(op_gt(`id`, 10000), e_drop())。
按字符串匹配条件过滤:如果name包含“hangzhou”,则丢弃这条记录:e_if(str_contains(`name`, "hangzhou"), e_drop())。
按日期过滤:如果订单时间早于某个时间,则不同步:e_if(op_lt(`order_timestamp`, "2015-02-23 23:54:55"), e_drop())。
按多条件过滤:
如果id>1000且name包含“hangzhou”,则丢弃这条记录:e_if(op_and(str_contains(`name`, "hangzhou"), op_gt(`id`, 1000)), e_drop())。
如果id>1000或name包含“hangzhou”,则丢弃这条记录:e_if(op_or(str_contains(`name`, "hangzhou"), op_gt(`id`, 1000)), e_drop())。
数据脱敏
遮掩:将phone手机号列的后四位用星号替换,e_set(`phone`, str_mask(`phone`, 7, 10, '*'))。
记录数据修改时间
对所有表新增列:__OPERATION__的值为INSERT、UPDATE或DELETE时新增1列“dts_sync_time”,值为日志提交时间(__COMMIT_TIMESTAMP__)。
e_if(op_or(op_or( op_eq(__OPERATION__, __OP_INSERT__), op_eq(__OPERATION__, __OP_UPDATE__)), op_eq(__OPERATION__, __OP_DELETE__)), e_set(dts_sync_time, __COMMIT_TIMESTAMP__))对指定表“dts_test_table”新增列: __OPERATION__的值为INSERT或UPDATE或DELETE时新增1列“dts_sync_time”, 值为日志提交时间(__COMMIT_TIMESTAMP__)。
e_if(op_and( op_eq(__TB__,'dts_test_table'), op_or(op_or( op_eq(__OPERATION__,__OP_INSERT__), op_eq(__OPERATION__,__OP_UPDATE__)), op_eq(__OPERATION__,__OP_DELETE__))), e_set(dts_sync_time,__COMMIT_TIMESTAMP__))说明上述新增列操作需要您在任务启动前自行修改目标端表定义,添加“dts_sync_time”列。
数据变更审计
记录表数据变化的类型和时间:在目标端的“operation_type”列记录数据变化类型;在目标端的“updated”列记录数据发生变化的时间。
e_compose( e_switch( op_eq(__OPERATION__,__OP_DELETE__), e_set(operation_type, 'DELETE'), op_eq(__OPERATION__,__OP_UPDATE__), e_set(operation_type, 'UPDATE'), op_eq(__OPERATION__,__OP_INSERT__), e_set(operation_type, 'INSERT')), e_set(updated, __COMMIT_TIMESTAMP__), e_set(__OPERATION__,__OP_INSERT__) )说明您需要在任务启动前在目标端表中添加“operation_type”列和“updated”列。
数据处理DSL语法
常量与变量
常量
类型
示例
int
123
float
123.4
string
"hello1_world"
boolean
true或false
datetime
DATETIME('2021-01-01 10:10:01')
变量
变量
含义
数据类型
示例值
__TB__
表名
string
table
__DB__
库名
string
mydb
__OPERATION__
操作类型
string
__OP_INSERT__,__OP_UPDATE__,__OP_DELETE__
__BEFORE__
UPDATE操作的前镜像值(修改前的值)
说明DELETE操作只有前镜像值。
特殊标记,无类型
v(`column_name`,__BEFORE__)
__AFTER__
UPDATE操作的后镜像值(修改后的值)
说明INSERT操作只有后镜像值。
特殊标记,无类型
v(`column_name`,__AFTER__)
__COMMIT_TIMESTAMP__
事务提交时间
datetime
'2021-01-01 10:10:01'
`column`
某条数据对应column的值
string
`id`、`name`
表达式函数
数值运算
功能
语法
取值范围
返回值
示例
加法
op_sum(value1, value2)
value1:整数或浮点数
value2:整数或浮点数
若参数均为整数,则返回整数,否则返回浮点数。
op_sum(`col1`, 1.0)
减法
op_sub(value1, value2)
value1:整数或浮点数
value2:整数或浮点数
若参数均为整数,则返回整数,否则返回浮点数。
op_sub(`col1`, 1.0)
乘法
op_mul(value1, value2)
value1:整数或浮点数
value2:整数或浮点数
若参数均为整数,则返回整数,否则返回浮点数。
op_mul(`col1`, 1.0)
除法
op_div_true(value1, value2)
value1:整数或浮点数
value2:整数或浮点数
若参数均为整数,则返回整数,否则返回浮点数。
op_div_true(`col1`, 2.0), 若col1=15,则返回7.5。
取模
op_mod(value1, value2)
value1:整数或浮点数
value2:整数或浮点数
若参数均为整数,则返回整数,否则返回浮点数。
op_mod(`col1`, 10),若col1=23,则返回3
逻辑运算
功能
语法
取值范围
返回值
示例
是否相等
op_eq(value1, value2)
value1:整数、浮点数、字符串
value2:整数、浮点数、字符串
boolean类型,true或false
op_eq(`col1`, 23)
是否大于
op_gt(value1, value2)
value1:整数、浮点数、字符串
value2:整数、浮点数、字符串
boolean类型,true或false
op_gt(`col1`, 1.0)
是否小于
op_lt(value1, value2)
value1:整数、浮点数、字符串
value2:整数、浮点数、字符串
boolean类型,true或false
op_lt(`col1`, 1.0)
是否大于等于
op_ge(value1, value2)
value1:整数、浮点数、字符串
value2:整数、浮点数、字符串
boolean类型,true或false
op_ge(`col1`, 1.0)
是否小于等于
op_le(value1, value2)
value1:整数、浮点数、字符串
value2:整数、浮点数、字符串
boolean类型,true或false
op_le(`col1`, 1.0)
AND运算
op_and(value1, value2)
value1:boolean类型
value2:boolean类型
boolean类型,true或false
op_and(`is_male`, `is_student`)
OR运算
op_or(value1, value2)
value1:boolean类型
value2:boolean类型
boolean类型,true或false
op_or(`is_male`, `is_student`)
IN运算
op_in(value, json_array)
value: 任意类型
json_array:JSON格式字符串
boolean类型,true或false
op_in(`id`,json_array('["0","1","2","3","4","5","6","7","8"]'))
值是否为空
op_is_null(value)
value: 任意类型
boolean类型,true或false
op_is_null(`name`)
值是否不为空
op_is_not_null(value)
value: 任意类型
boolean类型,true或false
op_is_not_null(`name`)
字符串函数
功能
语法
取值范围
返回值
示例
字符串拼接
op_add(str_1,str_2,...,str_n)
str_1: 字符串
str_2: 字符串
...
str_n: 字符串
拼接后的字符串
op_add(`col`,'hangzhou','dts')
字符串格式化,字符串拼接
str_format(format, value1, value2, value3, ...)
format:字符串类型,以大括号作为占位符,如 "part1: {}, part2: {}"。
value1:任意
value2:任意
格式化好的字符串
str_format("part1: {}, part2: {}", `col1`, `col2`),若col1="ab", col2="12", 则返回"part1: ab, part2: 12"。
字符串替换
str_replace(original, oldStr, newStr, count)
original:原来的字符串
oldStr:待替换的字符串
newStr:替换后的字符串
count:整数,最多替换次数。若设置为-1,则全部替换。
替换后的字符串
str_replace(`name`, "a", 'b', 1),若name="aba", 则返回"bba" ;str_replace(`name`, "a", 'b', -1);若name="aba", 则返回"bbb"。
所有字符串类型(如varchar、text、char等)的字段值替换
tail_replace_string_field(search, replace, all)
search:待替换的字符串
replace:替换后的字符串
all: 是否替换所有匹配的字符串,目前只支持取值为true。
说明若您无需替换所有匹配的字符串,请使用
str_replace函数。
替换后的字符串
tail_replace_string_field('\u000f','',true),将所有字符串字段类型值的 "\u000f"替换成空格。
移除字符串首尾的特定字符
str_strip(string_val, charSet)
string_val:原来的字符串
char_set:待移除的字符集合
移除首尾字符后的字符串
str_strip(`name`, 'ab'),若name=axbzb, 则返回xbz。
字符串转小写
str_lower(value)
value:字符串列或字符串常量
小写字符串
str_lower(`str_col`)
字符串转大写
str_upper(value)
value:字符串列或字符串常量
大写字符串
str_upper(`str_col`)
字符串转数字
cast_string_to_long(value)
value:字符串
整数
cast_string_to_long(`col`)
数字转字符串
cast_long_to_string(value)
value:整数
字符串
cast_long_to_string(`col`)
字符串统计
str_count(str,pattern)
str:字符串列或字符串常量
pattern:要查找的子串
子串出现的次数
str_count(`str_col`, 'abc'), 若str_col="zabcyabcz",则返回2。
字符串查找
str_find(str, pattern)
str:字符串列或字符串常量
pattern:要查找的子串
子串首次匹配的位置,没有则返回`-1`
str_find(`str_col`, 'abc'), 若`str_col="xabcy"`,则返回`1`。
判断是否全是字母组成的字符串
str_isalpha(str)
str:字符串列或字符串常量
true或false
str_isalpha(`str_col`)
判断是否全是数字组成的字符串
str_isdigit(str)
str:字符串列或字符串常量
true或false
str_isdigit(`str_col`)
正则匹配
regex_match(str,regex)
str:字符串列或字符串常量
regex: 正则表达式字符串列或字符串常量
true或者false
regex_match(__TB__,'user_\\d+')
使用指定字符遮掩字符串的一部分,可用于数据脱敏,例如把手机号的后四位替换为星号
str_mask(str, start, end, maskStr)
str:字符串列或字符串常量
start:整数,遮掩的起始位置,最小值为0。
end:整数,遮掩的结束位置,最大值为字符串长度减一。
maskStr:字符串,长度为1的字符串,例如 '#'。
遮掩掉start至end后的字符串
str_mask(`phone`, 7, 10, '#')
截取字符串cond之后的部分
substring_after(str, cond)
str: 原来的字符串
cond: 字符串
字符串
说明返回值不含字符串cond。
substring_after(`col`, 'abc')
截取字符串cond之前的部分
substring_before(str, cond)
str: 原来的字符串
cond: 字符串
字符串
说明返回值不含字符串cond。
substring_before(`col`, 'efg')
截取字符串cond1和cond2之间的部分
substring_between(str, cond1, cond2)
str: 原来的字符串
cond1: 字符串
cond2: 字符串
字符串
说明返回值不含字符串cond1和cond2。
substring_between(`col`, 'abc','efg')
判断是否为字符串类型
is_string_value(value)
value:字符串或者列名
boolean类型,true或false
is_string_value(`col1`)
字符串类型字段内容替换; 逆序从尾部开始
tail_replace_string_field(search, replace, all)
search:将被替换的字符串
replace:用于替换的字符串
all: 是否替换所有,true或者false
替换后的字符串
将所有字符串字段类型值的 "\u000f"替换成空格
tail_replace_string_field('\u000f','',true)
获取MongoDB中字段(Field)的值
bson_value("field1","field2","field3",...)
field1:一级字段名称。
field2:二级字段名称。
文档(Document)中相应字段的值
e_set(`user_id`, bson_value("id"))
e_set(`user_name`, bson_value("person","name"))
时间函数
功能
语法
取值范围
返回值
示例
当前系统时间
dt_now()
无
DATETIME,精确到秒
dts_now()
dt_now_millis()
无
DATETIME,精确到毫秒
dt_now_millis()
UTC时间戳(秒)转DATETIME
dt_fromtimestamp(value,[timezone])
value:整数
timezone:时区,可选参数
DATETIME,精确到秒
dt_fromtimestamp(1626837629)
dt_fromtimestamp(1626837629,'GMT+08')
UTC时间戳(毫秒)转DATETIME
dt_fromtimestamp_millis(value,[timezone])
value:整数
timezone:时区,可选参数
DATETIME,精确到毫秒
dt_fromtimestamp_millis(1626837629123);
dt_fromtimestamp_millis(1626837629123,'GMT+08')
DATETIME转UTC时间戳(秒)
dt_parsetimestamp(value,[timezone])
value: DATETIME
timezone:时区,可选参数
整数
dt_parsetimestamp(`datetime_col`)
dt_parsetimestamp(`datetime_col`,'GMT+08')
DATETIME转UTC时间戳(毫秒)
dt_parsetimestamp_millis(value,[timezone])
value: DATETIME
timezone:时区,可选参数
整数
dt_parsetimestamp_millis(`datetime_col`)
dt_parsetimestamp_millis(`datetime_col`,'GMT+08')
DATETIME转字符串
dt_str(value, format)
value:DATETIME
format:字符串, yyyy-MM-dd HH:mm:ss 格式表示
字符串
dt_str(`col1`, 'yyyy-MM-dd HH:mm:ss')
字符串转DATETIME
dt_strptime(value,format)
value:字符串
format:字符串, yyyy-MM-dd HH:mm:ss 格式表示
DATETIME
dt_strptime('2021-07-21 03:20:29', 'yyyy-MM-dd hh:mm:ss')
修改时间,对年、月、日、时、分或秒中的一个或多个数值进行增加或减少
dt_add(value, [years=intVal],
[months=intVal],
[days=intVal],
[hours=intVal],
[minutes=intVal]
)
value: DATETIME
intVal: 整数
说明负号(-)表示减。
DATETIME
dt_add(datetime_col,years=-1)
dt_add(datetime_col,years=1,months=1)
条件表达式
功能
语法
取值范围
返回值
示例
类似于C语言中的三目运算符(
? :),返回符合条件的值(cond ? val_1 : val_2)
cond:bool类型的字段或表达式
val_1:返回值1
val_2:返回值2
说明val_1和val_2的类型需相同。
当cond为true时返回val_1否则返回val_2
(id>1000? 1 : 0)
JSON函数
说明value类型表示数据库中任意字段的类型。
功能
语法
取值范围
返回值
示例
将JSON数组字符串转换为Set集合
json_array(arrayText)
说明仅支持在返回值为boolean类型的表达式中使用。
arrayText:字符串类型,待转换的JSON数组字符串。
Set集合
op_in(`id`,json_array('["0","1","2","3"]')),返回Set集合["0","1","2","3"]。创建一个包含指定数据的JSON数组
json_array2(item...)
item...:value类型,JSON数组的数据。
JSON数组
json_array2("0","1","2","3"),返回["0","1","2","3"]。创建一个包含指定数据的JSON对象
json_object(item...)
item...:JSON对象的数据(键值对)。由键名(字符串)和键值(value类型)构成,二者之间以逗号(,)分隔。
JSON
json_object('name','ZhangSan','age',32, 'loginId',100),返回{"name":"ZhangSan","age":32,"loginId":100]}。在JSON对象的指定位置(数组中)插入数据
json_array_insert(json, kvPairs...)
json:字符串类型,待操作的JSON对象。
kvPairs...:待插入的数据。由数组位置(jsonPath,字符串类型)和具体数据(value类型)构成,二者之间以逗号(,)分隔。
JSON
说明若指定的位置不存在,则返回待操作的JSON对象。
若指定位置的元素不存在,则数据将会被添加到目标数组中的末尾。
json_array_insert('{"Address":["City",1]}','$.Address[3]',100),返回{"Address":["City",1,100]}。在JSON对象的指定位置插入数据
json_insert(json, kvPairs...)
json:字符串类型,待操作的JSON对象。
kvPairs...:待插入的数据。由位置(jsonPath,字符串类型)和具体数据(value类型)构成,二者之间以逗号(,)分隔。
JSON
说明若指定的位置存在,则返回待操作的JSON对象。
若指定的位置不存在,则数据将会被添加到待操作的JSON对象中。
json_insert('{"Address":["City","Xian","Number",1]}','$.ID',100),返回{"Address":["City","Xian","Number",1],"ID":100}。在JSON对象的指定位置插入或更新数据
json_set(json, kvPairs...)
json:字符串类型,待操作的JSON对象。
kvPairs...:待插入的数据。由位置(jsonPath,字符串类型)和具体数据(value类型)构成,二者之间以逗号(,)分隔。
value类型
说明若指定的位置存在,则更新该位置的数据。
若指定的位置不存在,则数据将会被添加到待操作的JSON对象中。
json_set('{"ID":1,"Address":["City","Xian","Number",1]}',"$.IP",100),返回{"ID":1,"Address":["City","Xian","Number",1], "IP":100}。在JSON对象中插入或更新数据(键值对)
json_put(json, key, value)
json:字符串类型,待操作的JSON对象。
key:字符串类型,待插入的键名。
value:value类型,待插入的键值。
JSON
说明若参数json不是JSON对象,则返回null。
若指定的键名存在,则更新该键名对应的键值。
若指定的键名不存在,则数据将会被添加到待操作的JSON对象中。
json_put('{"loginId":100}','loginTime','2024-10-10'),返回{"loginId":100, 'loginTime':'2024-10-10'}。替换JSON对象的指定位置的数据
json_replace(json, kvPairs...)
json:字符串类型,待操作的JSON对象。
kvPairs...:待替换的数据。由位置(jsonPath,字符串类型)和具体数据(value类型)构成,二者之间以逗号(,)分隔。
value类型
说明若指定的位置不存在,则返回待操作的JSON对象。
json_replace('{"ID":1,"Address":["City","Xian","Number",1]}',"$.IP",100),返回{"ID":1,"Address":["City","Xian","Number",1]}查询JSON对象的指定位置是否存在指定的数据
json_contains(json, jsonPath, item)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,JSON对象中的指定位置。
item:value类型,待查询的具体数据。
boolean类型,true或false
json_contains('{"ID":1,"Address":["City","Xian","Number",1]}','$.ID',1),返回true。查询JSON对象中是否存在指定的位置
json_contains_path(json, jsonPath)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,待查询的位置信息。
boolean类型,true或false
json_contains_path('{"ID":1,"Address":["City","Xian","Number",1]}','$.ID'),返回true。获取JSON对象中指定位置的数据
json_extract(json, jsonPath)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,JSON对象中的指定位置。
value类型
json_extract('{"ID":1,"Address":["City","Xian","Number",1]}','$.ID'),返回1。获取JSON对象中指定Key的键值
json_get(json, key)
json:字符串类型,待操作的JSON对象。
key:字符串类型,待获取数据的键名(Key)。
value类型
json_get('{"ID":1,"Address":["City","Xian","Number",1]}','ID'),返回1。获取JSON对象中指定位置的所有Key
json_keys(json, jsonPath)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,JSON对象中的指定位置。
JSON数组
json_keys('{"ID":1,"Address":["City","Xian","Number",1]}','$'),返回["ID","Address"]。查询JSON对象中指定位置的长度(Key的个数)
json_length(json, jsonPath)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,JSON对象中的指定位置。
说明若jsonPath的取值为
"$",则等效于json_length(json)。
整数
json_length('{"ID":1,"Address":["City","Xian","Number",1]}','$'),返回2。查询JSON对象根节点的长度(Key的个数)
json_length(json)
json:字符串类型,待操作的JSON对象。
整数
json_length('{"ID":1,"Address":["City","Xian","Number",1]}'),返回2。将JSON字符串转换为JSON对象
json_parse(json)
json:字符串类型,待操作的JSON对象。
value类型
json_parse('{"ID":1,"Address":["City","Xian","Number",1]}'),返回{"ID":1,"Address":["City","Xian","Number",1]}。移除JSON对象中指定位置的数据
json_remove(json, jsonPath)
json:字符串类型,待操作的JSON对象。
jsonPath:字符串类型,JSON对象中的指定位置。
JSON
json_remove('{"loginId":100, 'loginTime':'2024-10-10'}','$.loginTime'),返回{"loginId":100}。
全局函数
流程控制函数
功能
语法
参数说明
示例
if语句
e_if(bool_expr, func_invoke)
bool_expr:bool常量或函数调用。常量:true或false。函数调用:op_gt(`id`, 10)。
func_invoke:函数调用。e_drop,e_keep,e_set,e_if,e_compose
e_if(op_gt(`id`, 10), e_drop()), 如果ID大于10,则丢弃这条记录。
if else语句
e_if_else(bool_expr, func_invoke1, func_invoke2)
bool_expr:bool常量或函数调用。常量:true或false。函数调用:op_gt(`id`, 10)。
func_invoke1:函数调用。条件为true时执行。
func_invoke2:函数调用。条件为false时执行。
e_if_else(op_gt(`id`, 10), e_set(`tag`, 'large'), e_set(`tag`, 'small')),如果ID大于10,则设置tag列为"large", 否则设置为"small"。
类switch语句,进行多次条件判断,第一次满足条件时执行对应操作,如无匹配则执行默认操作。
s_switch(condition1, func1, condition2, func2, ..., default = default_func)
condition1:bool常量或函数调用。常量:true或false。函数调用:op_gt(`id`, 10)。
func_invoke:函数调用。检查condition1,若为true则执行此函数,并退出整个switch,若为false则继续检查下一个条件。
default_func:函数调用。当前面的所有condition都为false时,执行此默认函数。
e_switch(op_gt(`id`, 100), e_set(`str_col`, '>100'), op_gt(`id`, 90), e_set(`str_col`, '>90'), default=e_set(`str_col`, '<=90'))。
组合多个操作
e_compose(func1, func2, func3, ...)
func1:函数调用。可以为e_set, e_drop, e_if。
func2:函数调用。可以为e_set, e_drop, e_if。
e_compose(e_set(`str_col`, 'test'), e_set(`dt_col`, dt_now())), 设置str_col列的值为test,并设置dt_col列的值为当前时间。
数据操作函数
功能
语法
参数说明
示例
丢弃此条数据,不同步
e_drop()
无
e_if(op_gt(`id`, 10), e_drop()),丢弃ID大于10的记录。
保留此条数据,同步到目标端
e_keep(condition)
condition:boolean类型表达式
e_keep(op_gt(id, 1)) ,仅同步ID大于1的数据。
设置列值
e_set(`col`, val, NEW)
col:列名
val:常量或函数调用。类型需要和col的类型匹配
NEW:将col列的数据类型转换为val的数据类型,为可选字段
重要若不传入NEW,则也不能传入NEW前面的逗号(,)。同时需要注意数据类型的兼容性,否则会导致任务报错。
e_set(`dt_col`, dt_now()),设置dt_col为当前时间。
e_set(`col1`, `col2` + 1),设置col1为col2+1。
e_set(`col1`, 1, NEW),将col1列转换为数字类型,并将值设置为1。
MongoDB保留字段、丢弃字段、字段名映射功能
e_expand_bson_value('*', 'fieldA',{"fieldB":"fieldC"})
*:需要保留的字段名称,*表示所有字段。
fieldA:需要丢弃的字段名称。
{"fieldB":"fieldC"}:字段名映射,fieldB表示源端字段名称,fieldC表示目标端字段名称。
说明字段名映射是一个可选表达式。
e_expand_bson_value("*", "_id,name"),将除_id和name两个字段以外的其他字段写入目标端。