
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用数据传输服务DTS(Data Transmission Service),结合Kafka集群与TiDB数据库的Pump、Drainer组件,将自建TiDB数据库同步至云原生数据仓库AnalyticDB MySQL。
前提条件
已创建云原生数据仓库AnalyticDB MySQL3.0版本,详情请参见创建云原生数据仓库AnalyticDB MySQL3.0版本。
确保目标云原生数据仓库AnalyticDB MySQL具备充足的存储空间。
背景信息
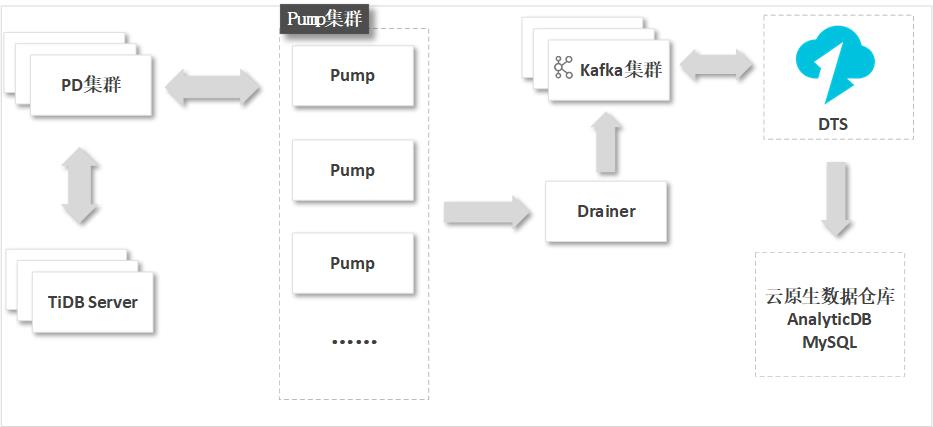
由于TiDB的Binlog格式和实现机制与MySQL数据库存在一定区别,为实现增量数据同步,同时减少对源数据库的改动,您需要部署Kafka集群以及TiDB数据库的Pump和Drainer组件。
由Pump组件实时记录TiDB产生的Binlog并提供给Drainer组件,然后由Drainer组件将获取到的Binlog写入到下游的Kafka集群。DTS在执行增量数据同步时将从Kafka集群中获取对应的数据并实时同步至目标数据库(例如云原生数据仓库AnalyticDB MySQL)。
注意事项
DTS在执行全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据同步前评估源库和目标库的性能,同时建议您在业务低峰期执行数据同步(例如源库和目标库的CPU负载在30%以下)。
请勿在数据同步时,对源库的同步对象使用gh-ost或pt-online-schema-change等类似工具执行在线DDL变更,否则会导致同步失败。
说明如果同步的目标为云原生数据仓库AnalyticDB MySQL(3.0),您可以使用DMS提供的相关功能来执行在线DDL变更,详情请参见通过无锁变更工单实现无锁结构变更。
由于云原生数据仓库AnalyticDB MySQL(3.0)本身的使用限制,当云原生数据仓库AnalyticDB MySQL(3.0)集群中的节点磁盘空间使用量超过80%,该集群将被锁定。请提前根据待同步的对象预估所需空间,确保目标集群具备充足的存储空间。
暂不支持同步前缀索引,如果源库存在前缀索引可能导致数据同步失败。
若DTS任务运行时目标AnalyticDB MySQL版 3.0集群处于备份中的状态,则会导致任务失败。
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
支持同步的SQL操作
DDL操作:CREATE TABLE、DROP TABLE、RENAME TABLE、TRUNCATE TABLE、ADD COLUMN、DROP COLUMN
DML操作:INSERT、UPDATE、DELETE
如果在数据同步的过程中变更了源表的字段类型,同步作业将报错并中断。您可以手动修复,详情请参见修复因变更字段类型导致的同步失败。
准备工作
为减少网络延迟对数据同步的影响,Pump组件、Drainer组件和Kafka集群所部署的服务器需要与源库所属的服务器在同一内网中。
部署Pump和Drainer组件,详情请参见TiDB Binlog集群部署。
修改Drainer组件的配置文件,设置输出为Kafka,详情请参见Kafka自定义开发。
选择下述方法准备Kafka集群:
部署自建Kafka集群,详情请参见Apache Kafka官网。
警告为保障Kafka集群可正常接收到TiDB产生的较大的Binlog数据,请适当将Broker组件中的
message.max.bytes、replica.fetch.max.bytes参数以及Consumer组件中的fetch.message.max.bytes参数对应的值调大,详细说明请参见Kafka配置说明。使用阿里云
云消息队列 Kafka 版(MQ for Apache Kafka),详情请参见阿里云
云消息队列 Kafka 版快速入门。
说明为保障正常通信和减少网络延迟对增量数据同步的影响,部署阿里云消息队列Kafka实例时,需配置和源库服务器相同的专有网络。
在自建Kafka集群或阿里云消息队列Kafka实例中创建Topic。
将DTS服务器的IP地址段加入至TiDB数据库的白名单安全设置中,具体IP地址段信息请参见添加DTS服务器的IP地址段。
操作步骤
购买数据同步作业,详情请参见购买流程。
说明购买时,选择源实例为TiDB,目标实例为AnalyticDB MySQL。
登录数据传输控制台。
说明若数据传输控制台自动跳转至数据管理DMS控制台,您可以在右下角的
 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。在左侧导航栏,单击数据同步。
在同步作业列表页面顶部,选择数据同步实例所属地域。
定位至已购买的数据同步实例,单击配置同步链路。
配置同步通道的源实例及目标实例信息。
配置同步任务的名称和源实例信息。
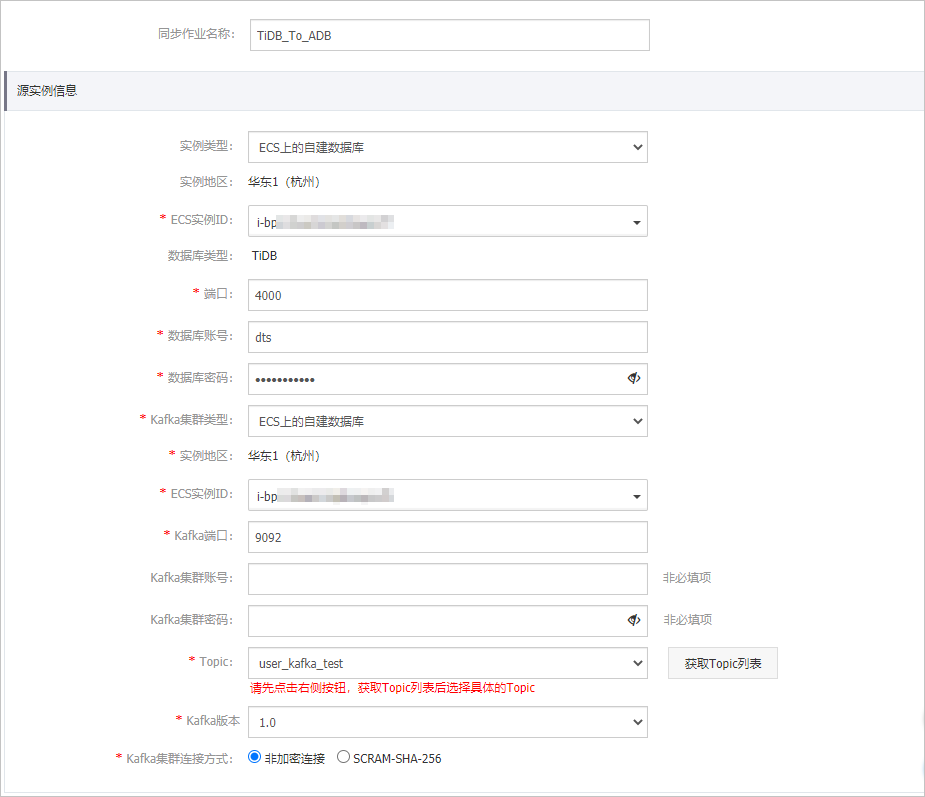
配置
说明
同步任务名称
DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
实例类型
根据源库的部署位置进行选择, 本文以ECS上的自建数据库为例介绍配置流程。
说明当自建数据库为其他实例类型时,您还需要执行相应的准备工作,详情请参见准备工作。
实例地区
购买数据同步实例时选择的源实例地域信息,不可变更。
数据库类型
固定为TiDB。
端口
填入TiDB数据库的服务端口,默认为4000。
数据库账号
填入TiDB数据库账号,需具备SHOW VIEW和待同步对象的SELECT权限,授权方法请参见TiDB权限管理。
数据库密码
填入该数据库账号的密码。
Kafka集群类型
根据Kafka的部署位置进行选择, 本文以ECS上的自建数据库为例介绍配置流程。当自建Kafka为其他实例类型时,您还需要执行相应的准备工作,详情请参见准备工作概览。
说明由于DTS暂时不支持直接选择阿里云
云消息队列 Kafka 版,如果您使用的是阿里云消息队列Kafka实例,此处需将其作为自建Kafka来配置,即选择为通过专线/VPN网关/智能接入网关接入的自建数据库,然后选择阿里云消息队列Kafka实例所属的专有网络。
实例地区
和源库的实例地区保持一致,不可变更。
ECS实例ID
选择自建Kafka所属的ECS实例ID。
Kafka端口
自建Kafka的服务端口,默认为9092。
Kafka集群账号
填入自建Kafka的用户名,如自建Kafka未开启验证可不填写。
Kafka集群密码
填入该用户的密码,如自建Kafka未开启验证可不填写。
Topic
单击右侧的获取Topic列表,然后在下拉框中选择具体的Topic。
Kafka版本
根据自建Kafka的版本进行选择。
Kafka集群连接方式
根据业务及安全需求,选择非加密连接或SCRAM-SHA-256。
配置同步任务的目标实例信息。
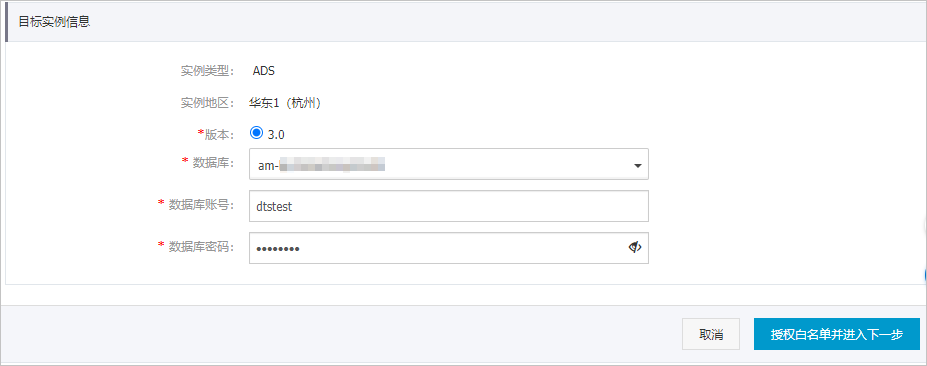
配置
说明
实例类型
固定为ADS。
实例地区
购买数据同步实例时选择的目标实例地域信息,不可变更。
版本
固定为3.0。
数据库
选择目标云原生数据仓库AnalyticDB MySQL的集群ID。
数据库账号
填入云原生数据仓库AnalyticDB MySQL的数据库账号,需具备目标库的读写权限,授权方法请参见创建数据库账号。
数据库密码
填入该数据库账号对应的密码。
单击页面右下角的授权白名单并进入下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单中;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添加到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添加到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
配置同步策略及对象信息。
配置
说明
同步初始化
默认情况下,您需要同时选中结构初始化和全量数据初始化。预检查完成后,DTS会将源实例中待同步对象的结构及数据在目标集群中初始化,作为后续增量同步数据的基线数据。
目标已存在表的处理模式
预检查并报错拦截:检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步作业不会被启动。
说明如果目标库中同名的表不方便删除或重命名,您可以更改该表在目标库中的名称,详情请参见设置同步对象在目标实例中的名称。
忽略报错并继续执行:跳过目标数据库中是否有同名表的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
表结构一致的情况下,在目标库遇到与源库主键的值相同的记录,则会保留目标集群中的该条记录,即源库中的该条记录不会同步至目标数据库中。
表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败。
多表归并
选择为是:DTS将在每个表中增加
__dts_data_source列来存储数据来源,且不再支持DDL同步。选择为否:默认选项,支持DDL同步。
说明多表归并功能基于任务级别,即不支持基于表级别执行多表归并。如果需要让部分表执行多表归并,另一部分不执行多表归并,您可以创建两个数据同步作业。
同步操作类型
根据业务选中需要同步的操作类型,支持的同步操作详情请参见支持同步的SQL操作,默认情况下都处于选中状态。
选择同步对象
在源库对象框中单击待同步的对象,然后单击
 图标将其移动至已选择对象框。
图标将其移动至已选择对象框。同步对象的选择粒度为库、表。
说明如果选择整个库作为同步对象,那么该库中所有对象的结构变更操作会同步至目标库。
如果选择某个表作为同步对象,那么只有这个表的ADD COLUMN操作会同步至目标库。
默认情况下,同步对象的名称保持不变。如果您需要同步对象在目标集群上名称不同,请使用对象名映射功能,详情请参见设置同步对象在目标实例中的名称。
映射名称更改
如需更改同步对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源表DMS_ONLINE_DDL过程中是否复制临时表到目标库
如源库使用数据管理DMS(Data Management)执行Online DDL变更,您可以选择是否同步Online DDL变更产生的临时表数据。
是:同步Online DDL变更产生的临时表数据。
说明Online DDL变更产生的临时表数据过大,可能会导致同步任务延迟。
否:不同步Online DDL变更产生的临时表数据,只同步源库的原始DDL数据。
说明该方案会导致目标库锁表。
源、目标库无法连接重试时间
当源、目标库无法连接时,DTS默认重试720分钟(即12小时),您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,同步任务将自动恢复。否则,同步任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
上述配置完成后,单击页面右下角的下一步。
设置待同步的表在目标库中类型。
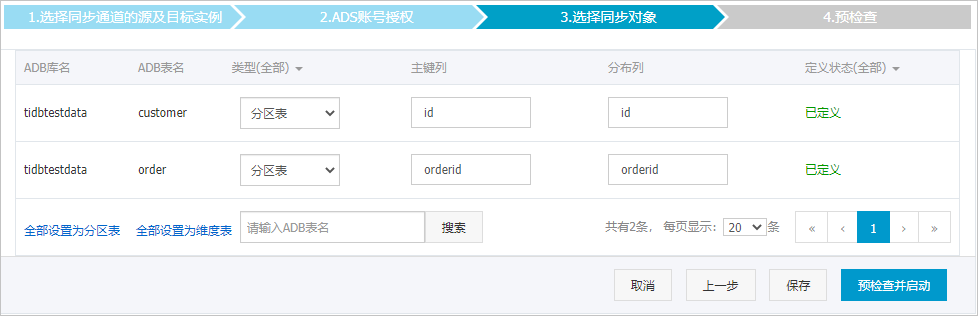 说明
说明选择了结构初始化后,您需要定义待同步的表在云原生数据仓库AnalyticDB MySQL中的类型、主键列、分区列等信息,详情请参见ADB 3.0 SQL手册。
上述配置完成后,单击页面右下角的预检查并启动。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
在预检查对话框中显示预检查通过后,关闭预检查对话框,同步作业将正式开始。
等待同步作业的链路初始化完成,直至处于同步中状态。
您可以在数据同步页面,查看数据同步作业的状态。
