
DeepNCCL是阿里云神龙异构产品开发的用于多GPU互联的AI通信加速库,能够无感地加速基于NCCL进行通信算子调用的分布式训练或多卡推理等任务。开发人员可以根据实际业务情况,在不同的GPU云服务器上安装DeepNCCL通信库,以加速分布式训练或推理性能。本文主要介绍在Ubuntu或CentOS操作系统的GPU实例上安装和使用DeepNCCL的操作方法。
关于DeepNCCL的更多信息,请参见什么是AI通信加速库DeepNCCL。
使用限制
已创建阿里云GPU实例,且GPU实例需满足以下限制:
操作系统为Ubuntu 18.04或更高版本,以及CentOS 7.x或更高版本。
已安装GPU Driver、CUDA 11.4或更高版本。
创建GPU实例时,选择镜像后,建议您同时选中安装GPU驱动选项,然后依次选择CUDA版本、Driver版本以及cuDNN版本,具体操作,请参见创建GPU实例。
仅部分GPU实例支持使用DeepNCCL。
DeepNCCL支持的NCCL通信算法如下所示,本文以常用的allreduce(全局归约)通信算法为例展示DeepNCCL的优化效果。
NCCL通信算法
支持的GPU实例
说明
allgather(全收集)
多机优化
V100:ecs.gn6v-c10g1.20xlarge、ecs.gn6e-c12g1.24xlarge、ecs.ebmgn6e.24xlarge、ecs.ebmgn6v.24xlarge
ecs.ebmgn7e.32xlarge、ecs.ebmgn7ex.32xlarge、ecs.sccgn7ex.32xlarge、ecs.gn7e-c16g1.32xlarge
训练2个机型提升60%。
多机最大支持扩展20个机型。
reduce-scatter(分散归约)
多机优化
V100:ecs.gn6v-c10g1.20xlarge、ecs.gn6e-c12g1.24xlarge、ecs.ebmgn6e.24xlarge、ecs.ebmgn6v.24xlarge
ecs.ebmgn7e.32xlarge、ecs.ebmgn7ex.32xlarge、ecs.sccgn7ex.32xlarge、ecs.gn7e-c16g1.32xlarge
训练2个机型提升60%。
多机最大支持扩展8个机型。
allreduce(全局归约)
多机优化:
V100:ecs.gn6v-c10g1.20xlarge、ecs.gn6e-c12g1.24xlarge、ecs.ebmgn6e.24xlarge、ecs.ebmgn6v.24xlarge
ecs.ebmgn7e.32xlarge、ecs.ebmgn7ex.32xlarge、ecs.sccgn7ex.32xlarge、ecs.gn7e-c16g1.32xlarge
ecs.ebmgn8v.48xlarge
训练2个机型提升40%。
多机最大支持扩展8个机型。
单机优化:
A10:ecs.ebmgn7ix.32xlarge
ebmgn7ix单机在512 B~2 MB下训练效率提升10%~100%。
安装DeepNCCL
根据GPU实例的操作系统,选择不同方式安装DeepNCCL。
Ubuntu操作系统
(推荐)PyPi安装方式
执行以下命令,直接从阿里云Pip源中安装最新的DeepNCCL 2.1.0。
pip install deepnccl.deb安装包方式执行以下命令,从OSS中直接下载DeepNCCL的
.deb安装包。本步骤以下载DeepNCCL 2.1.0版本为例。
wget http://aiacc.oss-cn-beijing.aliyuncs.com/deepnccl/release/2.1.0/deb/deep-nccl-2.1.0.deb执行以下命令,安装DeepNCCL。
dpkg -i deep-nccl-2.1.0.deb
CentOS操作系统
(推荐)PyPi安装方式
执行以下命令,直接从阿里云Pip源中安装最新的DeepNCCL 2.1.0。
pip install deepnccl.rpm安装包方式执行以下命令,从OSS中直接下载DeepNCCL的
.rpm安装包。本步骤以下载DeepNCCL 2.1.0版本为例。
wget http://aiacc.oss-cn-beijing.aliyuncs.com/deepnccl/release/2.1.0/rpm/deep-nccl-2.1.0.rpm执行以下命令,安装DeepNCCL。
rpm -i deep-nccl-2.1.0.rpm
执行以下命令,查看DeepNCCL是否安装成功。
ldconfig -p | grep nccl回显结果如下图所示,显示
libnccl.so.2表示DeepNCCL已安装成功。
使用DeepNCCL
DeepNCCL(包括aiacc-nccl-plugin)安装成功后,您可以直接使用DeepNCCL的通信优化功能,无需再进行其他配置。以下示例通过nccl-tests展示DeepNCCL在V100两机16卡模型上,采用allreduce通信算法进行加速的效果。
脚本示例
在NVIDIA nccl-tests中下载nccl-tests软件包,按照nccl-tests软件包中的README.md中的说明,复制以下脚本示例来加载优化算法。
mpirun --allow-run-as-root \
--np 16 -npernode 8 \
--hostfile hostfile \
-mca btl_tcp_if_include eth0 \
-x NCCL_DEBUG=info \
-x NCCL_ALGO=Ring \
./build/${op}_perf -b 256K -e 1G -d $datatype -f 2 -g 1 -w 10 -n 100算法加载与当前机型拓扑有关,如下图所示,表示优化算法加载成功。

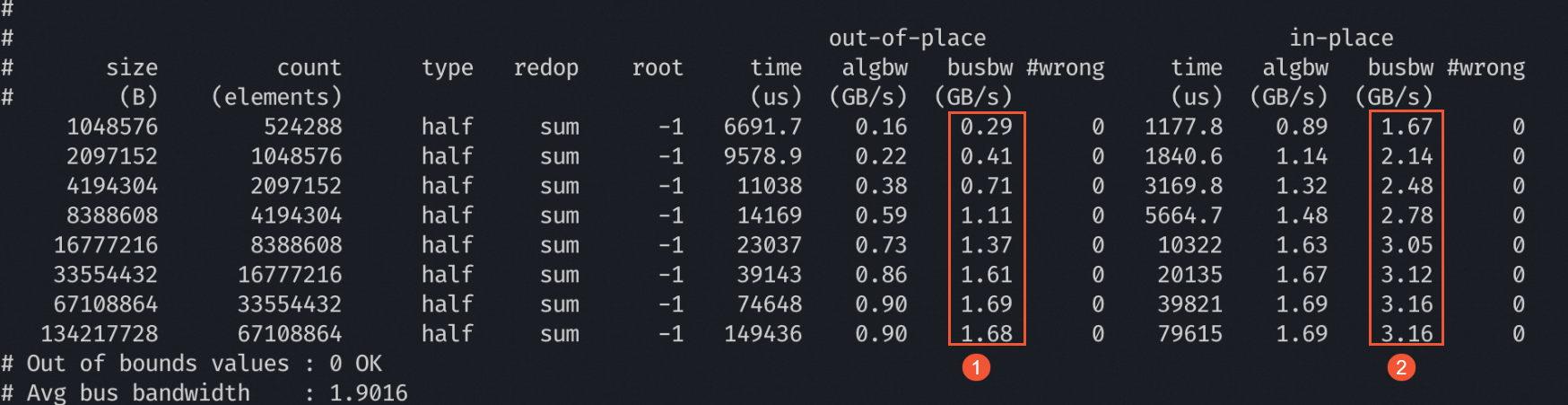
性能提升效果
相比NCCL优化性能(Baseline),使用DeepNCCL在V100两机16卡模型上进行分布式优化时,采用allreduce通信算法,其优化提升效果显著,具体busbw值如下图所示:
①:表示使用NCCL(Baseline)进行分布式优化时,其优化性能的busbw值。
②:表示使用DeepNCCL进行分布式优化时,其优化性能的busbw值。
卸载DeepNCCL
如果您的业务暂不需要使用DeepNCCL优化能力,您可以通过以下方式卸载DeepNCCL。
Ubuntu操作系统
如果您采用PyPi安装方式安装了DeepNCCL,则执行以下命令卸载DeepNCCL。
pip uninstall deepnccl如果您采用
.deb安装包方式安装了DeepNCCL,则执行以下命令卸载DeepNCCL。dpkg -r deep-nccl
CentOS操作系统
如果您采用PyPi安装方式安装了Deepnccl,则执行以下命令卸载Deepnccl。
pip uninstall deepnccl如果您采用
.rpm安装包方式安装了Deepnccl,则执行以下命令卸载Deepnccl。rpm -e deep-nccl