
本文介绍如何利用 Serverless Spark 内置函数,在超大规模文本集合中快速识别并去除近似重复内容,适用于大模型预训练语料清洗等场景。
MinHash-LSH 算法简介
MinHash-LSH 是一种经典的近似相似性检测算法组合,广泛应用于大规模集合相似度计算(如 Jaccard 相似度)。其核心思想是:
MinHash:将文本转换为 n-gram 集合后,通过多组哈希函数生成紧凑的签名向量,保留原始集合的相似性特征。
LSH(局部敏感哈希):将签名向量划分为多个“band”,每个 band 单独哈希,使得高相似度文本更可能落入同一哈希桶中,从而实现候选对的快速筛选。
Serverless Spark 通过 minhash_lsh 和 build_lsh_edges 函数集成 MinHash-LSH 能力,依托 Fusion 引擎实现向量化加速,在消除数据行列转换开销的同时,提升了去重任务的执行效率。
内置函数说明
minhash_lsh
将输入文本分词后生成 MinHash 签名,并按 bands 划分生成对应的哈希值列表。
命令格式
minhash_lsh(
tokens: ARRAY<STRING>,
perms_a: ARRAY<BIGINT>,
perms_b: ARRAY<BIGINT>,
hash_ranges: ARRAY<INT>,
ngram_size: INT,
min_length: INT
)参数说明
参数 | 类型 | 是否必填 | 说明 |
|
| 是 | 分词后的词元数组(如通过 |
|
| 是 | MinHash 哈希函数组的乘数参数 |
|
| 是 | MinHash 哈希函数组的加数参数 |
|
| 是 | Band 划分边界,格式为 |
|
| 是 | n-gram 大小,建议长文本使用 5–9。 |
|
| 是 | 输入 tokens 最小长度,低于此值的记录将被跳过。 |
返回值
类型:
ARRAY<STRING>含义:每个元素为对应 band 的十六进制哈希字符串,共
个。 输出示例:
["a1b2c3", "d4e5f6", ...]
build_lsh_edges
对落入同一 LSH 桶的一组文档 ID,基于“最小节点连接”策略生成边集,用于后续图连通分量分析以聚类重复文档。
命令格式
build_lsh_edges(doc_ids: ARRAY<BIGINT>)参数说明
参数 | 类型 | 是否必填 | 说明 |
|
| 是 | 同一 LSH 桶中的文档 ID 列表。 |
返回值:
类型:
ARRAY<STRUCT<src: LONG, dst: LONG>>含义:以桶内最小 ID 为源节点,连接其余所有节点所形成的边集合。
示例逻辑:桶内 ID 为
[1003, 1001, 1005]→ 排序后取最小1001,生成边(1001,1003)和(1001,1005)
应用示例:fineweb-edu 数据集去重
本示例使用开源数据集 fineweb-edu 的 sample/10BT 子集进行演示。
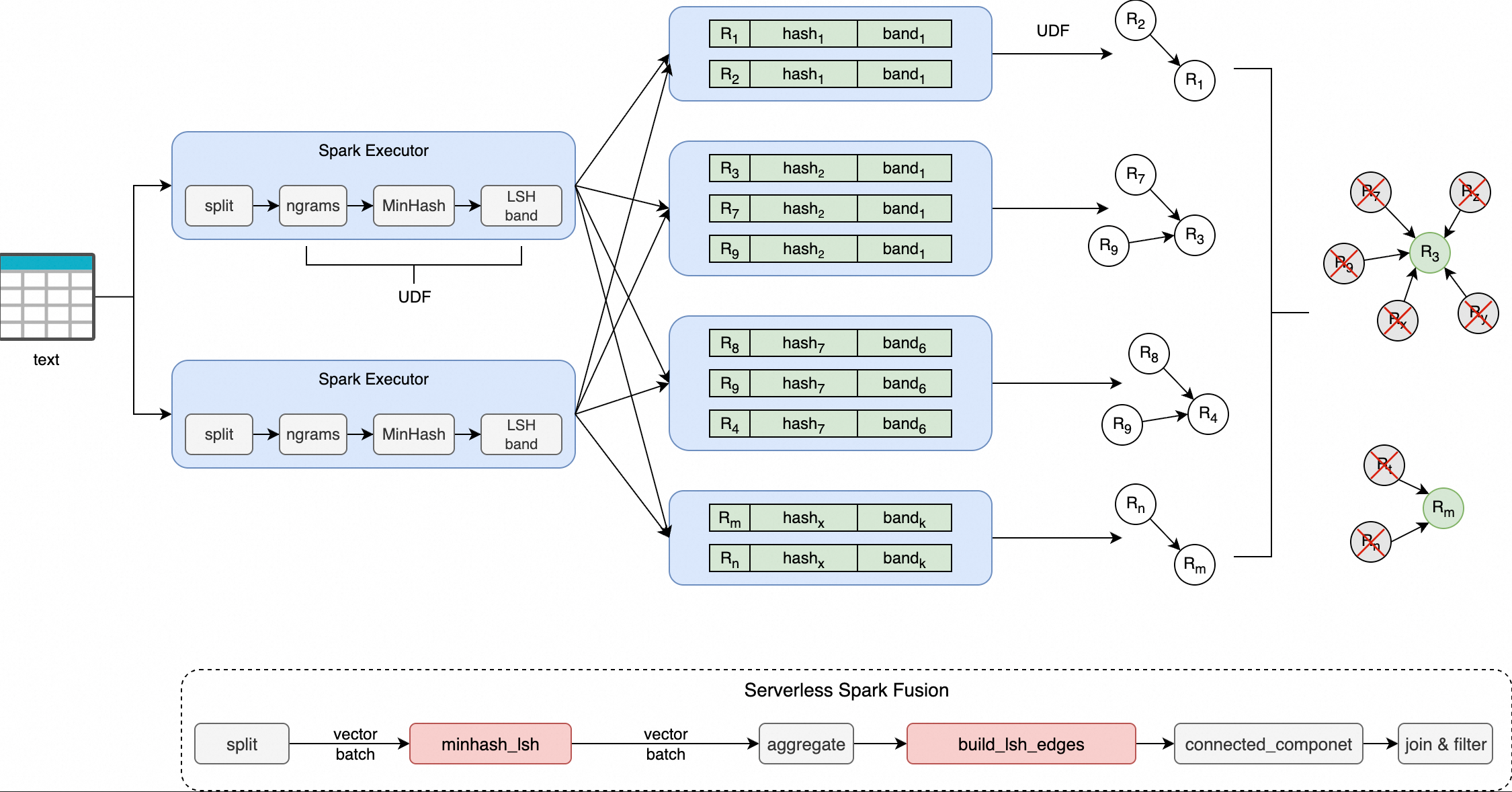
minhash_lsh:该函数将每行输入文本切分为 n-gram 词元集合,通过 MinHash 算法生成固定长度的签名向量;随后根据指定的hash_ranges将签名划分为多个 band,并为每个 band 计算一个十六进制编码的哈希值,最终返回所有 band 的哈希值数组。build_lsh_edges:该函数接收落入同一 LSH 桶的一组文档 ID,基于“最小节点连接”策略——即以桶内最小 ID 作为中心节点,与其他所有节点建立连接——生成边列表,用于后续图连通分量分析,实现重复文档的聚类。
支持版本
仅以下引擎版本支持本文操作:
esr-4.x:esr-4.1.1及之后版本。
esr-3.x:esr-3.1.1及之后版本。
esr-2.x:esr-2.5.1及之后版本。
步骤一:准备数据
下载数据集。
sample/10BT开源数据集的完整大小为28.5GB,请根据实际情况进行下载。本文示例仅使用该数据集的部分数据,大小为2.15GB。
上传数据集至OSS。
使用控制台或 CLI 将 Parquet 文件上传至指定路径,详见简单上传。
查看上传数据。
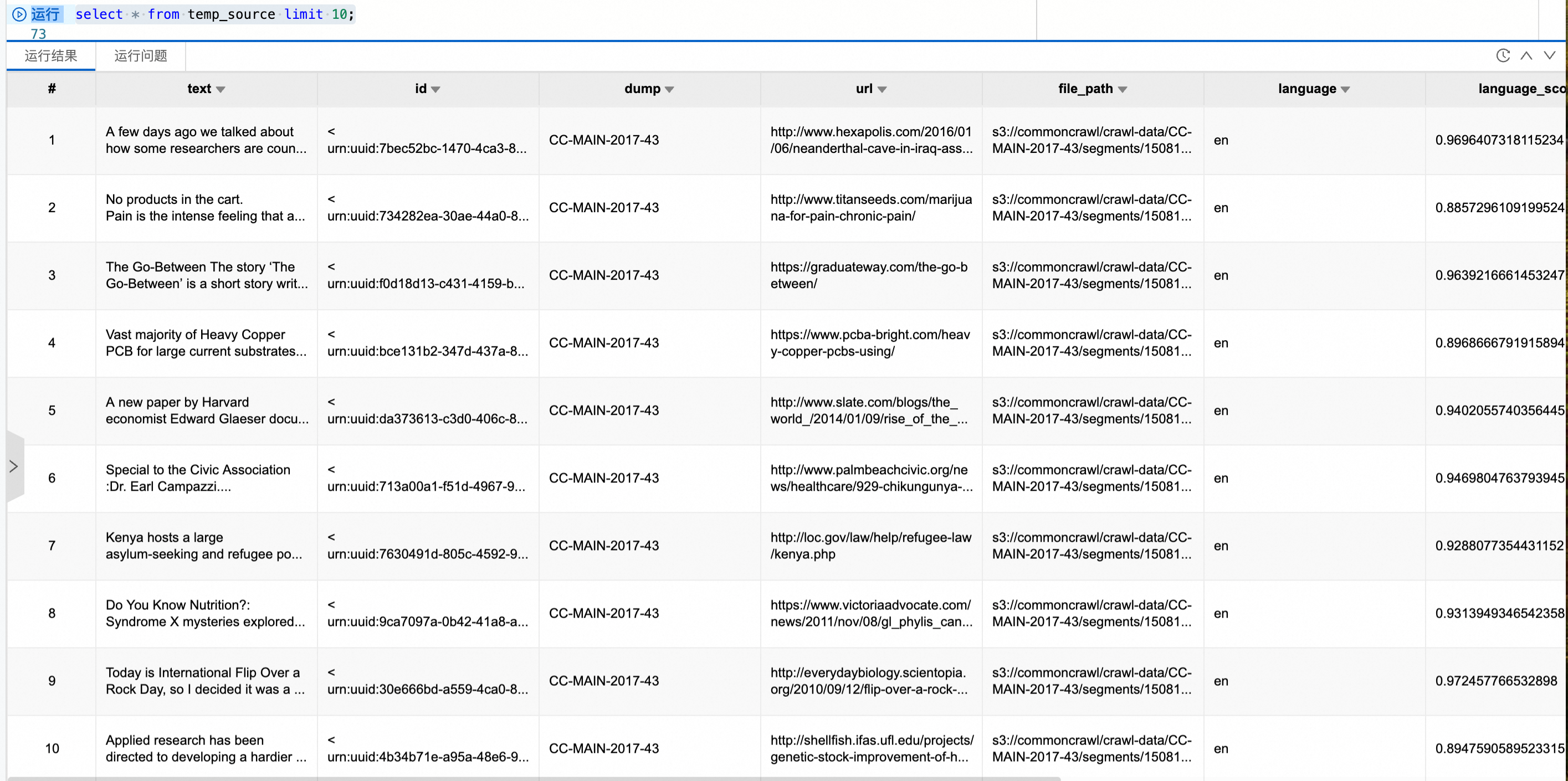
在 Spark 环境中创建临时视图,验证数据是否可正常读取。
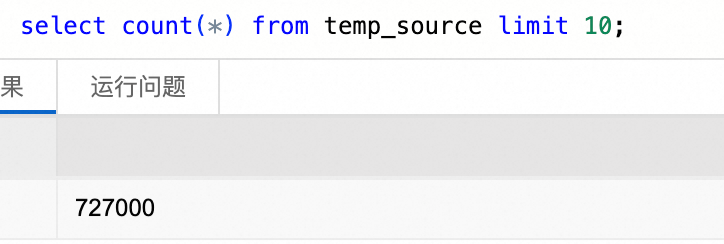
CREATE OR REPLACE TEMPORARY VIEW temp_source USING parquet OPTIONS (path 'oss://<bucket>/fineweb-edu/sample/10BT/') ;查看数据,总条数727000。
步骤二:编写脚本
保存为 MinHash.py,完整代码如下(参数说明见后表):
import re
from typing import List
from typing import Tuple
import pyspark
import numpy as np
import numpy.typing as npt
from graphframes import GraphFrame
from pyspark.sql import SparkSession
from pyspark.sql import functions as sf
from scipy.integrate import quad as integrate
RNG = np.random.RandomState(42)
SPLIT_PATTERN = re.compile(r"[\s\xA0]+") # 设置文本分割符
DTYPE = np.uint32
MAX_HASH = 4_294_967_295 # maximum 32-bit unsigned integer
MOD_PRIME = 4_294_967_291 # maximum 32-bit prime number
input_files = "oss://<bucket>/fineweb-edu/sample/10BT/*.parquet" # 设置需要去重的数据文件
output_path = "oss://<bucket>/fineweb-edu/output/10BT" # 设置输出路径
checkpoint_dir = "oss://<bucket>/fineweb-edu/checkpoints" # 设置checkpoint,用于图连通分量计算时存储中间结果
threshold = 0.8 # 设置 threshold 参数
num_perm = 256 # 设置排列的数量
ngram_size = 5 # 设置 n_gram 大小
min_length = ngram_size # 设置 n_gram 最小长度,通常与 ngram_size 相同
text_column = "text" # 设置去重文本列名
index_column = "__id__"
# 设置固定默认并发度,确保图连通分量计算结果稳定性
conf = (
pyspark.SparkConf()
.set("spark.default.parallelism", "200")
)
spark = SparkSession.Builder() \
.appName("MinHashLSH") \
.config(conf=conf) \
.enableHiveSupport() \
.getOrCreate()
spark.sparkContext.setCheckpointDir(checkpoint_dir)
# 自动计算最优 Band 参数 (B, R)
def optimal_param(
threshold: float,
num_perm: int,
false_positive_weight: float = 0.5,
false_negative_weight: float = 0.5
):
def false_positive_area(threshold: float, b: int, r: int):
a, _ = integrate(lambda s: 1 - (1 - s**r)**b, 0.0, threshold)
return a
def false_negative_area(threshold: float, b: int, r: int):
a, _ = integrate(lambda s: 1 - (1 - (1 - s**r)**b), threshold, 1.0)
return a
min_error = float("inf")
opt = (0, 0)
for b in range(1, num_perm + 1):
max_r = int(num_perm / b)
for r in range(1, max_r + 1):
fp = false_positive_area(threshold, b, r)
fn = false_negative_area(threshold, b, r)
error = fp * false_positive_weight + fn * false_negative_weight
if error < min_error:
min_error = error
opt = (b, r)
return opt
# B (Bands), R (Rows per Band), B × R = num_perm
# B 和 R 会将 MinHash 签名矩阵分成 B 个 bands,每个 band 包含 R 行,可以自行指定该参数,也可以通过 threshold 和 num_perm 进行计算
B, R = optimal_param(threshold, num_perm)
HASH_RANGES_SLICE: List[int] = [i * R for i in range(B + 1)]
PERMUTATIONS: Tuple[npt.NDArray[DTYPE], npt.NDArray[DTYPE]] = (
RNG.randint(1, MOD_PRIME, size=(num_perm,), dtype=DTYPE),
RNG.randint(0, MOD_PRIME, size=(num_perm,), dtype=DTYPE),
)
# 若数据本身具有主键 id 列,可以直接使用主键作为 index_column,无需使用 monotonically_increasing_id 生成 index
# .withColumn(index_column, "主键col")
df = spark.read.parquet(input_files) \
.withColumn(index_column, sf.monotonically_increasing_id())
a, b = PERMUTATIONS
# 使用 minhash_lsh 函数求解 band_hash list,并通过 explode 将 list 展开为 band_idx 和 band_hash
hash_df = df \
.select(index_column,
sf.split(
sf.lower(text_column),
pattern=SPLIT_PATTERN.pattern).alias("tokens")) \
.select(index_column,
sf.minhash_lsh(
"tokens",
a.tolist(),
b.tolist(),
HASH_RANGES_SLICE,
ngram_size,
min_length).alias("hashes")) \
.select(index_column, sf.posexplode("hashes").alias("band_idx", "band_hash"))
# 使用 build_lsh_edges 函数对聚合后属于同一个 LSH 桶的 band_idx 基于 “最小节点连接” 策略生成节点之间的边
edges_df = hash_df.groupBy("band_idx", "band_hash") \
.agg(sf.count(index_column).alias("cnt"), sf.collect_list(index_column).alias("doc_ids")) \
.filter(sf.col("cnt") > 1) \
.select(sf.build_lsh_edges("doc_ids").alias("edges")) \
.select(sf.explode("edges").alias("edge")) \
.selectExpr("edge.src as src", "edge.dst as dst") \
.persist(pyspark.StorageLevel.DISK_ONLY)
# 计算出所有边的顶点
vertices_df = edges_df.select(sf.col("src").alias("id")) \
.union(edges_df.select(sf.col("dst").alias("id"))) \
.distinct() \
.repartition(4096) \
.persist(pyspark.StorageLevel.MEMORY_AND_DISK_DESER)
assignment = GraphFrame(vertices_df, edges_df).connectedComponents()
# 保留每个连通分量中 ID 最小的代表文档
df = df.join(assignment.select(sf.col("id").alias(index_column), sf.col("component").alias("__component__")),
on=index_column, how="left") \
.filter(sf.col("__component__").isNull() | (sf.col("__component__") == sf.col(index_column))) \
.drop("__component__")
# 输出去重结果
df.write.parquet(output_path, mode="overwrite", compression="snappy")
# 清理缓存
edges_df.unpersist()
vertices_df.unpersist()参数说明表
参数 | 示例值 | 说明 |
|
| 输入数据路径(Parquet 格式)。 |
|
| 去重后结果输出路径。 |
|
| 图计算中间状态存储路径。 |
|
| 相似度阈值(推荐 0.7–0.9)。 |
|
| MinHash 签名长度(影响精度与性能)。 |
|
| n-gram 大小(长文本建议 5–9)。 |
|
| 文本最小 token 长度,低于则跳过。 |
|
| 待去重的文本列名。 |
步骤三:上传文件
进入资源上传页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的文件管理。
在文件管理页面,单击上传文件。
在上传文件对话框中,单击待上传文件区域选择MinHash.py,或直接拖拽MinHash.py到待上传文件区域。
步骤四:创建并运行批任务
在完成脚本开发与上传后,您需要在 Serverless Spark 环境中创建一个批处理任务来执行该去重作业。
在EMR Serverless Spark页面,单击左侧的数据开发。
在开发目录页签下,单击
 图标。
图标。在弹出的对话框中,输入名称,类型使用,单击确定。
在右上角选择队列。
添加队列的具体操作,请参见管理资源队列。
在新建的开发页签中,配置以下信息,其余参数无需配置,然后单击运行。
参数
说明
主Python资源
选择前一个步骤中在文件管理页面上传的Python文件。本文示例是
MinHash.py。引擎版本
esr-2.8.0/esr-3.4.0/esr-4.4.0及以上版本。资源配置
建议按照4CPU:16GB的比例进行配置。例如,
spark.executor.cores=4,spark.executor.memory=14GB,spark.executor.memoryOverhead=2GB。Spark配置
spark.rdd.ensureConfigConsistency true:必填项,必须设置为true。执行效率优化参数:
spark.sql.shuffle.partitions 1000:建议 1TB 数据以下配置为 1000 即可,每增加 1TB 数据可增加 1000。spark.sql.files.maxPartitionBytes 256MB:控制读取阶段分区大小,避免小文件过多,通常配置为 128/256MB 即可。
运行任务后,在下方的运行记录区域,单击任务操作列的详情,监控任务执行。
步骤五:验证结果
任务成功完成后,验证去重结果。
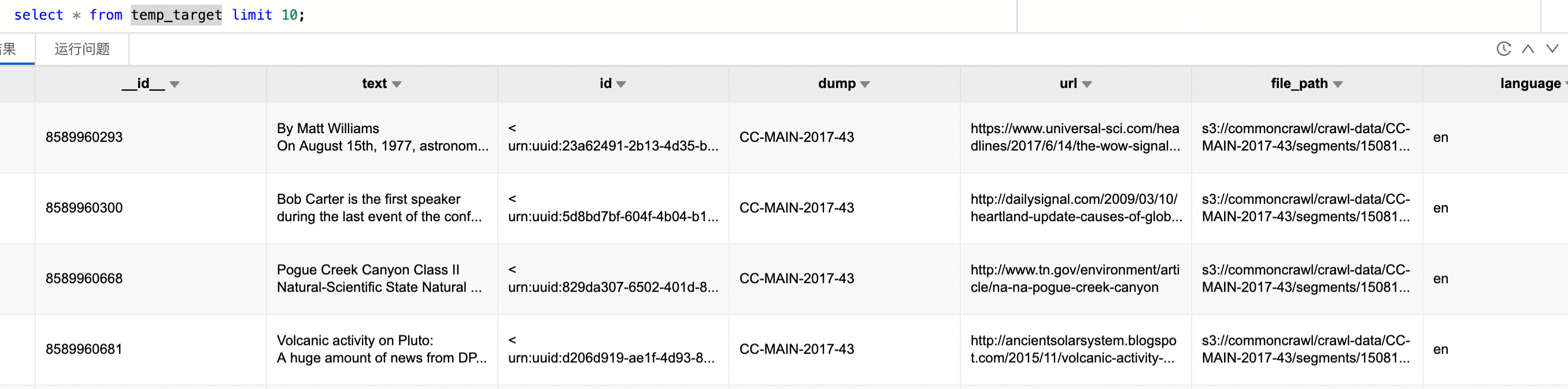
在 Spark SQL 环境中创建临时视图以加载去重后的数据。
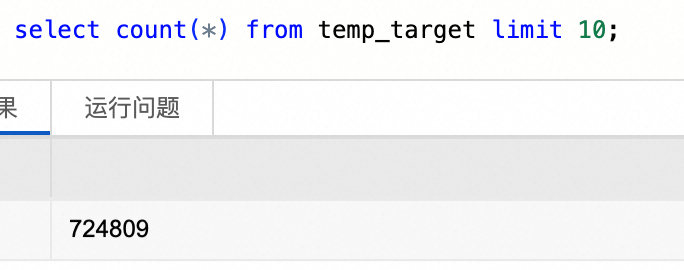
CREATE OR REPLACE TEMPORARY VIEW temp_target USING parquet OPTIONS (path 'oss://<bucket>/fineweb-edu/output/10BT') ;查看数据,总条数724809(原 727,000 → 去除 2,191 条重复项)。
性能调优建议
为在不同数据规模和业务目标下平衡去重的精度、召回率与执行效率,建议从以下三个层面进行系统性调优。
算法参数调优
参数 | 推荐值 | 说明 |
| 128 或 256 | 数值越大精度越高,但计算成本上升;256 通常足够。 |
| 5–9(长文)、2–3(短句) | 控制语义粒度,过大可能损失敏感性。 |
| 0.7–0.9 | 高于 0.9 可能召回不足。 |
LSH 结构设计:B 与 R
MinHash 签名被划分为
理想情况下,应使 LSH 函数:
推荐配置(以 num_perm=256 为例)
目标 | B(band 数) | R(每 band 行数) |
高召回(不漏删) | 32 | 8 |
高精度(不过删) | 8 | 32 |
平衡型(推荐起点) | 16 | 16 |
Spark 执行优化
配置项 | 推荐设置 | 说明 |
| 1TB 数据以下配置为 1000 即可,每增加 1TB 数据可增加 1000。 | 防止单 task 数据倾斜或 OOM。 |
|
| 控制读取阶段分片大小,避免小文件问题。 |