
本文介绍了如何在EMR Serverless Spark中开发并运行一个读写Kafka的流式任务。通过上传JAR包、创建流任务并运行,最终可以通过日志探查或控制台查看结果,验证数据读取和写入的正确性。
前提条件
操作流程
步骤一:上传Kafka相关JAR至OSS
Serverless Spark引擎在esr-2.8.0、esr-3.4.0、esr-4.4.0及以上版本中内置了Kafka JAR,您可以直接跳过该步骤。如果是其他版本的引擎,请按照以下步骤进行操作:
需根据所使用的Spark版本手动添加以下依赖。
Spark 3.5版本:kafka-spark35-jars.zip。
Spark 3.4版本:kafka-spark34-jars.zip。
Spark 3.3版本:kafka-spark33-jars.zip。
解压后,上传所有JAR包至OSS。本文以kafka-spark35-jars.zip为例。
hadoop fs -put /root/spark-sql-kafka-0-10_2.12-3.5.3.jar oss://<YOUR_BUCKET>.<region>.oss-dls.aliyuncs.com/ hadoop fs -put /root/kafka-clients-3.4.1.jar oss://<YOUR_BUCKET>.<region>.oss-dls.aliyuncs.com/ hadoop fs -put /root/spark-token-provider-kafka-0-10_2.12-3.5.3.jar oss://<YOUR_BUCKET>.<region>.oss-dls.aliyuncs.com/ hadoop fs -put /root/commons-pool2-2.11.1.jar oss://<YOUR_BUCKET>.<region>.oss-dls.aliyuncs.com/也可以通过OSS控制台或其他方式进行上传。
步骤二:创建网络连接
Serverless Spark需要能够打通与Kafka之间的网络才可以正常访问Kafka服务。更多网络连接信息,请参见EMR Serverless Spark与其他VPC间网络互通。
步骤三:准备测试文件
Scala代码示例如下,更多示例参考Spark读写Kafka。请单击下载SparkExample-1.0-SNAPSHOT-jar-with-dependencies.jar,以便直接使用测试JAR包或自行进行打包,pom文件的相关配置详见附录。
代码示例
读Kafka
订阅云消息队列Kafka topic消息,以[key,value]的形式在控制台输出。
object StreamingReadKafka {
def main(args: Array[String]): Unit = {
import org.apache.spark.sql.SparkSession
val servers = args(0)
val topic = args(1)
val spark = SparkSession.builder()
.appName("test read kafka")
.getOrCreate()
import spark.implicits._
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", servers)
.option("subscribe", topic)
.load()
val query = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
.writeStream
.format("console")
.start()
query.awaitTermination()
}
}写Kfaka
从 Spark 内置的数据源读取数据,生成包含 value 和 timestamp 的记录,并将value 列同时用作 key 和 value 列,以每秒生成 1 条记录的速率写入Kafka。
object StreamingWriteKafka {
def main(args: Array[String]): Unit = {
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.Trigger
val servers = args(0)
val topic = args(1)
val checkpointDir = args(2)
val spark = SparkSession.builder()
.appName("test write kafka")
.getOrCreate()
val df = spark.readStream
.format("rate")
.option("rowsPerSecond", "1")
.load()
.withColumn("key", col("value"))
.withColumn("value", col("value"))
val query = df
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", servers)
.option("topic", topic)
.option("checkpointLocation", checkpointDir)
.trigger(Trigger.ProcessingTime("10 seconds"))
.start()
query.awaitTermination()
}
}步骤四:上传JAR包
进入资源上传页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的文件管理。
在文件管理页面,单击上传文件。
在上传文件对话框中,单击待上传文件区域选择JAR包,或直接拖拽JAR包到待上传文件区域。
步骤五:创建流任务并运行
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发。
在开发目录页签下,单击
 (新建)图标。
(新建)图标。在弹出的对话框中,输入名称,根据实际需求在流任务中选择JAR类型,然后单击确定。
在右上角选择目标队列。
添加队列的具体操作,请参见管理资源队列。
在新建的开发页签中,配置以下信息,其余参数无需配置,然后单击发布。
参数
说明
主jar资源
选择前一个步骤中上传的JAR包。本文示例是
SparkExample-1.0-SNAPSHOT-jar-with-dependencies.jar。引擎版本
选择合适的Spark版本。本文示例是
esr-4.3.0。Main Class
提交Spark任务时所指定的主类。
读Kafka示例值:
org.example.StreamingReadKafka。写 Kafka示例值:
org.example.StreamingWriteKafka。
运行参数
传递给主类自定义参数。多个参数使用空格分隔。
Kafka接入点信息,本文示例值是:
alikafka-serverless-cn-xxxxxx-1000-vpc.alikafka.aliyuncs.com:9092。订阅Kafka topic,本文示例值是:
test。checkpoint保存路径:
oss://<YOUR_BUCKET_PATH>/。仅写Kafka需要该参数。
网络连接
选择步骤二中创建的网络。
Spark配置
通过
spark.emr.serverless.user.defined.jars参数指定Kafka相关JAR包,多个JAR用逗号分隔。spark.emr.serverless.user.defined.jars oss://<YOUR_BUCKET_PATH>/commons-pool2-2.11.1.jar,oss://<YOUR_BUCKET_PATH>/kafka-clients-3.4.1.jar,oss://<YOUR_BUCKET_PATH>/spark-sql-kafka-0-10_2.12-3.5.3.jar,oss://<YOUR_BUCKET_PATH>/spark-token-provider-kafka-0-10_2.12-3.5.3.jar发布后,单击前往运维,在跳转页面,单击启动。
步骤六:查看结果
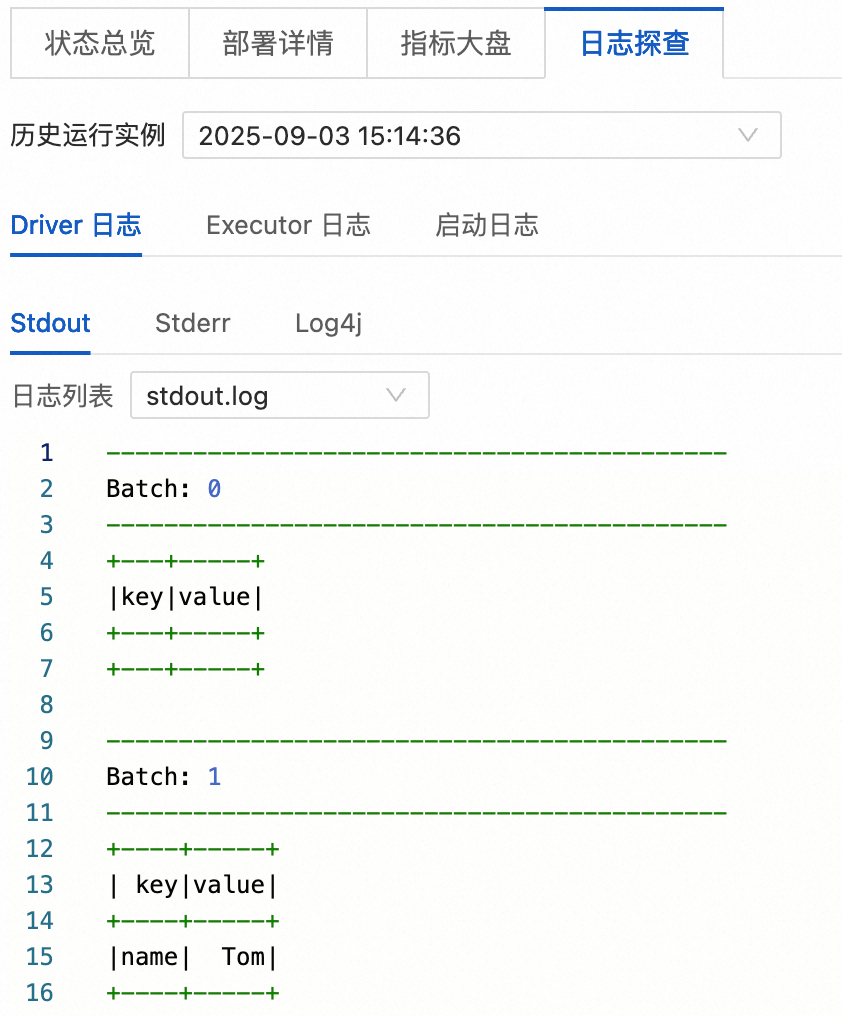
读Kafka
启动任务后,在页签单击目标任务。
在日志探查页签,您可以查看相关的日志信息。
写Kafka
启动任务后,登录Kafka控制台,进入到Kafka实例页面。
在消息查询页签,单击查询,您可以查看到Spark写入Kafka的消息。

附录
本文示例pom文件如下。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.5.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.example.Main</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>