
本文介绍如何在阿里云EMR Serverless Spark环境中开发SparkSQL任务,并指导您如何访问Spark UI以查看任务详情。
前提条件
创建SQL任务
DLF Catalog 相关参数(如 spark.sql.catalog.dlf.warehouse)在 SparkSession 初始化时加载,通过 PySpark 代码中的 spark.conf.set() 动态设置不会生效。如需自定义 DLF Catalog 参数,请在提交作业时通过启动参数传入,例如在 EMR Serverless Spark 控制台的配置项中添加,或在 CLI 中使用 --conf 参数指定。
-
进入开发页面。
-
在左侧导航栏,选择EMR Serverless > Spark。
-
在Spark页面,单击目标工作空间名称。
-
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发。
-
新建任务。
-
在开发目录页签下,单击
 (新建)图标。
(新建)图标。 -
在弹出的对话框中,输入名称,类型选择SparkSQL,然后单击确定。
-
在右上角选择数据目录、数据库和一个已启动的SQL会话实例。
您也可以在下拉列表中选择创建 SQL 会话,直接创建一个新的SQL会话实例。SQL会话更多介绍,请参见管理SQL会话。

-
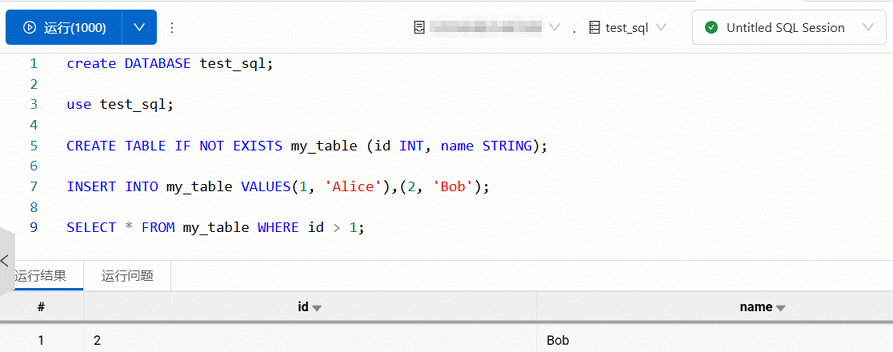
在新建的任务编辑器中输入SQL语句。
示例1:基础SQL操作
以下示例演示了如何创建数据库、切换数据库、创建表、插入数据并执行查询。
create DATABASE test_sql; use test_sql; CREATE TABLE IF NOT EXISTS my_table (id INT, name STRING); INSERT INTO my_table VALUES(1, 'Alice'),(2, 'Bob'); SELECT * FROM my_table WHERE id > 1;返回信息
示例2:基于CSV的外部表
以下示例演示了如何创建一个基于OSS存储中CSV文件的外部表,并执行查询操作。本示例代码中的Bucket地址(
oss://<bucketname>/user/)需要根据实际情况修改。-
创建临时视图。
基于OSS上的CSV文件创建一个临时视图
orders,用于后续数据分析。视图的字段定义如下:-
order_id:订单ID。 -
order_date:订单日期和时间(例如'2025-07-01 10:00:00')。 -
order_category:商品品类(例如 "数码"、"服饰" 等)。 -
order_revenue:订单金额。
CREATE TABLE orders ( order_id STRING, -- 订单 ID order_date STRING,-- 订单日期和时间 order_category STRING, -- 商品 SKU ID order_revenue DOUBLE -- 订单金额 ) USING CSV OPTIONS ( path 'oss://<bucketname>/user/', header 'true' ); -
-
插入测试数据。
INSERT OVERWRITE TABLE orders VALUES ('o1', '2025-07-01 10:00:00', '数码', 5999.0), ('o2', '2025-07-02 11:30:00', '服饰', 299.0), ('o3', '2025-07-03 14:45:00', '数码', 899.0), ('o4', '2025-07-04 09:15:00', '家居', 99.0), ('o5', '2025-07-05 16:20:00', '数码', 1999.0), ('o6', '2025-07-06 08:00:00', '服饰', 199.0), ('o7', '2025-07-07 12:10:00', '数码', 799.0), ('o8', '2025-07-08 18:30:00', '家居', 59.0), ('o9', '2025-07-09 20:00:00', '数码', 399.0), ('o10', '2025-07-10 07:45:00', '服饰', 599.0), ('o11', '2025-07-11 09:00:00', '数码', 1299.0), ('o12', '2025-07-12 13:20:00', '家居', 159.0), ('o13', '2025-07-13 17:15:00', '服饰', 499.0), ('o14', '2025-07-14 21:30:00', '数码', 999.0), ('o15', '2025-07-15 06:10:00', '家居', 299.0); -
执行复杂查询。
基于
orders表执行一个复杂的查询,统计最近15天内不同品类的销售表现。具体查询内容包括:-
订单数量:每个品类的订单总数。
-
总销售额(GMV):每个品类的订单金额总和。
-
平均订单金额:每个品类的订单金额平均值。
-
最近一笔订单时间:每个品类的最新订单时间。
SELECT order_category, COUNT(order_id) AS order_count, SUM(order_revenue) AS gmv, AVG(order_revenue) AS avg_order_amount, MAX(order_date) AS latest_order_date FROM orders WHERE CAST(order_date AS TIMESTAMP) BETWEEN '2025-07-01' AND '2025-07-15' GROUP BY order_category HAVING SUM(order_revenue) > 1000 ORDER BY gmv DESC, order_category ASC;返回信息如下所示。
-
示例3:创建 Hive Parquet 表
EMR Serverless Spark 默认使用 Paimon 作为表格式。如需创建 Hive Parquet 表,需要通过启动参数覆盖默认配置,并使用
USING PARQUET语法建表。前置配置
在作业启动参数(EMR Serverless Spark 控制台的配置项或 CLI 的
--conf参数)中添加以下配置,防止 Paimon 默认接管表创建:spark.sql.catalog.spark_catalog=org.apache.spark.sql.hive.HiveCatalog spark.sql.defaultFileFormat=parquet方式一:通过 SQL 创建 Hive Parquet 表
CREATE TABLE my_hive_table ( id INT, name STRING, dt STRING ) USING PARQUET PARTITIONED BY (dt);说明建表时请使用
USING PARQUET语法,避免使用STORED AS PARQUET。方式二:通过 DataFrame API 创建 Hive Parquet 表
df.write.format("parquet").saveAsTable("my_hive_table")说明若工作空间已绑定 DLF Catalog,建议优先通过 SQL 语句建表。
-
-
(可选)在开发页面右侧,您可以单击版本信息页签,查看版本信息。
您可以在此处查看或对比任务版本信息,支持对SQL代码内容进行版本间的对比,并将不同之处进行标记。
-
-
运行并发布任务。
-
单击运行。
返回结果信息可以在下方的运行结果中查看。如果有异常,则可以在运行问题中查看。右侧的运行记录提供近三天的运行历史供查阅。
-
确认运行无误后,单击右上角的发布。
-
在发布对话框中,可以输入发布信息,然后单击确定。
-
访问Spark UI
通过Spark UI,您可以查看任务的执行情况、资源使用情况、日志信息等,从而更好地分析和优化Spark任务。
在运行结果区域访问
仅以下引擎版本支持该功能:
-
esr-4.x:esr-4.2.0及之后版本。
-
esr-3.x:esr-3.2.0及之后版本。
-
esr-2.x:esr-2.6.0及之后版本。
执行完SQL语句后,您可以在运行结果页签的最下方,单击Spark UI,系统将自动跳转至Spark UI页面。

在会话实例处访问
执行完SQL语句后,您可以在会话实例处,选择 > Spark UI,系统将自动跳转至Spark UI页面。
> Spark UI,系统将自动跳转至Spark UI页面。

快捷键说明
为方便开发者高效编写和调试 SQL,平台提供以下常用快捷键:
|
功能 |
Windows 快捷键 |
Mac 快捷键 |
说明 |
|
运行当前脚本 |
|
|
立即执行编辑器中全部或选中的 SQL 语句,等同于点击【运行】按钮。 |
|
格式化 SQL |
|
|
自动美化 SQL 代码结构,统一缩进、换行和关键字大小写,提升可读性。适用于复杂查询的整理。 |
|
查找文本 |
|
|
在当前脚本中搜索关键词,支持逐个定位匹配项,便于快速定位字段或表名。 |
|
保存任务 |
|
|
手动保存当前未发布的任务内容,防止意外丢失修改。 |
|
选中当前行 |
|
|
将光标所在整行设为选中状态,可以仅运行选中内容。 |
|
切换行注释 |
|
|
对当前行或选中的多行添加/移除 |
|
移动到文件开头 |
|
|
光标瞬移至脚本首行首字符位置。 |
|
移动到文件末尾 |
|
|
光标瞬移至脚本末行末字符位置。 |
|
剪切内容 |
|
|
剪切所选内容;若未选中任何内容,则剪切光标所在的整行。 |
|
复制内容 |
|
|
复制所选内容;若未选中,则复制光标所在的整行。 |
|
增加缩进 |
|
|
对当前行或选中行块整体右移一个缩进层级。 |
|
减少缩进 |
|
|
对当前行或选中行块整体左移一个缩进层级。 |
后续操作
创建完任务后,您可以创建工作流来定期调度任务,详情请参见创建工作流。工作流的完整调度示例,请参见SparkSQL开发快速入门。
常见问题
数据开发界面的查询结果下载条数能否突破 10000 条限制?
不能。EMR Serverless Spark 数据开发的查询结果受平台硬性限制,最多支持下载 10000 条且总量不超过 10 MB,无法通过配置修改突破该限制。
如需获取更多数据,可以采用以下方式:
-
通过
spark-submit提交作业,将查询结果写入 OSS 或 HDFS。 -
使用 DataWorks 的离线同步任务导出数据。
Serverless Spark History 是否提供对外 API?
EMR Serverless Spark 已提供相关 API,可以通过API 概览查阅具体接口列表。