
在数据开发与任务执行过程中,明文存储AccessKey或密码等信息容易引发安全风险。通过密文管理功能,您可以将敏感信息进行加密存储,并在数据开发及会话配置中进行动态引用,从而避免代码泄露风险,提升敏感信息的维护效率。
创建密文
进入密文管理页面。
在左侧导航栏,选择EMR Serverless > Spark。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的密文管理。
在密文管理页面,单击新增密文。
在新增密文界面,配置以下信息,单击确认。
参数
说明
变量名称
变量名称在同一个工作空间下保持唯一,创建后不支持修改。
密文
对字母大小写敏感,创建后不支持修改与再次查看。
使用密文
在 Notebook 中使用
在Notebook任务中,可以通过emrssutils.utils工具库使用密文,但所使用的引擎版本必须为esr-2.8.0、esr-3.4.0、esr-4.4.0及其以上版本。
使用示例
导入工具库并加载密文。
# 获取密文示例代码 import emrssutils.utils # 动态获取解密后的值 password = emrssutils.utils.get_secret(key='<变量名称>')引用密文。
# 引用密文示例代码 df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://<jdbc_url>") \ .option("dbtable", "<db>.<table>") \ .option("user", "<username>") \ .option("password", password) \ # 引用密文 .load() df.show()
在Spark配置中使用
在会话或批任务的Spark配置中,通过${secret_values.变量名称}格式使用密文。
使用示例
在进行MaxCompute的读写操作时,可以首先将AccessKey添加到密文管理中。随后,在SQL会话的Spark配置中使用该密文。有关MaxCompute的具体读写操作,请参见读写MaxCompute。
spark.sql.catalog.odps org.apache.spark.sql.execution.datasources.v2.odps.OdpsTableCatalog
spark.sql.extensions org.apache.spark.sql.execution.datasources.v2.odps.extension.OdpsExtensions
spark.sql.sources.partitionOverwriteMode dynamic
spark.hadoop.odps.tunnel.quota.name pay-as-you-go
spark.hadoop.odps.project.name <project_name>
spark.hadoop.odps.end.point https://service.cn-hangzhou-vpc.maxcompute.aliyun-inc.com/api
spark.hadoop.odps.access.id <accessId>
# 引用密文
spark.hadoop.odps.access.key ${secret_values.AccessKey} 在批/流任务中使用
在批或流任务运行参数中,通过${secret_values.变量名称}格式使用密文。
使用示例
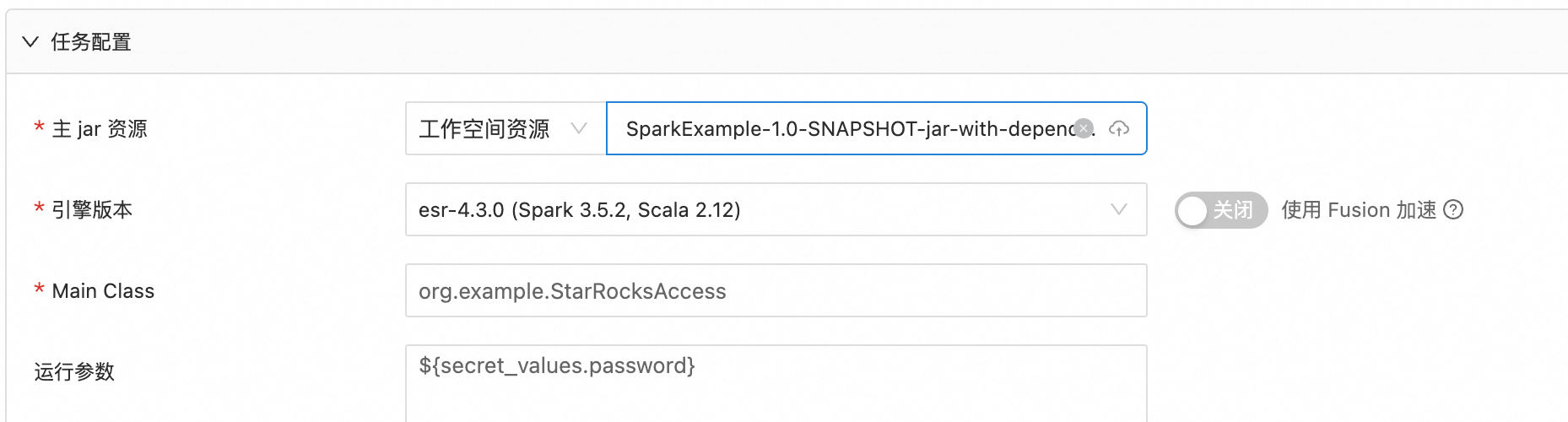
创建JAR批任务时,可以将相关的加密信息添加至密文管理中。随后,在运行参数中可通过使用${secret_values.变量名称}来引用密文。
该文章对您有帮助吗?