
通过网络连接功能,您可以实现Serverless Spark与自有VPC(Virtual Private Cloud)之间的网络互通,从而访问VPC内的数据源、服务器,或调用VPC内的其他服务。本文将以Spark SQL和Application JAR类型任务连接至自有VPC中的HMS(Hive Metastore)为例,详细介绍如何配置网络连接以实现VPC的互通。
前提条件
已准备好数据源。本文以在EMR on ECS页面创建包含Hive服务,元数据为内置MySQL的DataLake集群为例,详情请参见创建集群。
使用限制
当前仅支持使用下列可用区的交换机。
步骤一:新增网络连接
进入网络连接页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的网络连接。
在网络连接页面,单击新增网络连接。
在新增网络连接对话框中,配置以下信息,单击确定。
参数
说明
连接名称
输入新增连接的名称。
专有网络
选择与EMR集群相同的专有网络。
如果当前没有可选择的专有网络,请单击创建专有网络,前往专有网络控制台创建,详情请参见专有网络与交换机。
说明如果您的Serverless Spark需要访问公网,则必须确保添加的网络连接具备公网访问能力。例如,可以在VPC中部署一个公网NAT网关,以便Serverless Spark实例通过该网关访问公网。更多详情,请参见使用公网NAT网关SNAT功能访问互联网。
交换机
选择与EMR集群部署在同一专有网络下的交换机。
如果当前可用区没有交换机,请单击虚拟交换机,前往专有网络控制台创建,详情请参见创建和管理交换机。
重要仅支持选择特定可用区下的交换机,详情请参见使用限制。
当状态显示为已成功时,表示新增网络连接成功。

步骤二:为EMR集群添加安全组规则
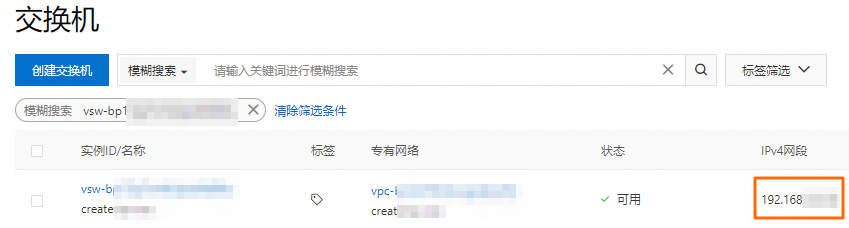
获取已创建网络连接中指定交换机的网段。
您可以登录专有网络管理控制台的交换机页面,获取交换机的网段。
添加安全组规则。
在EMR on ECS页面,单击目标集群的集群ID。
在基础信息页面的安全区域,单击集群安全组后面的链接。
在安全组详情页面的访问规则区域,单击增加规则,填写以下信息,然后单击确定。
参数
说明
协议
指定允许的网络通信协议类型。默认为TCP。
说明如果您的网络连接用于Kerberos认证,建议选择开放88端口的UDP协议。有关Kerberos认证更多信息,请参见开启Kerberos身份认证。
访问来源
填写前一步骤中获取的指定交换机的网段。
重要为防止被外部的用户攻击导致安全问题,授权对象禁止填写为0.0.0.0/0。
访问目的(本实例)
指定允许访问的目标端口号。例如,9083。
(可选)步骤三:连接Hive服务并查询表数据
如果您已有创建并配置好的Hive表,则可以跳过该步骤。
使用SSH方式登录集群的Master节点,详情请参见登录集群。
执行以下命令,进入Hive命令行。
hive执行以下命令,创建表。
CREATE TABLE my_table (id INT,name STRING);执行以下命令,向表中插入数据。
INSERT INTO my_table VALUES (1, 'John'); INSERT INTO my_table VALUES (2, 'Jane');执行以下命令,查询数据。
SELECT * FROM my_table;
(可选)步骤四:准备并上传资源文件
如果您后续使用JAR任务类型,则需提前准备好资源文件。如果使用本文的SparkSQL任务类型,则可以跳过该步骤。
在本地新建一个Maven工程。
使用
mvn package命令打包,编译打包后生成sparkDataFrame-1.0-SNAPSHOT.jar文件。在EMR Serverless Spark页面的目标工作空间下,单击左侧的文件管理。
在文件管理页面,单击上传文件。
上传本地打包好的
sparkDataFrame-1.0-SNAPSHOT.jar文件。
步骤五:新建并运行任务
JAR任务
在EMR Serverless Spark页面,单击左侧的数据开发。
单击新建。
输入名称,类型选择,单击确定。
在新建的任务开发中,配置以下信息,其余参数无需配置,然后单击运行。
参数
说明
主jar资源
选择前一步骤中上传的资源文件。例如,sparkDataFrame-1.0-SNAPSHOT.jar。
Main Class
提交Spark任务时所指定的主类。本文示例填写为com.example.DataFrameExample。
网络连接
选择您在步骤一中新增的网络连接的名称。
Spark配置
配置以下信息。
spark.hadoop.hive.metastore.uris thrift://*.*.*.*:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactory其中,
*.*.*.*为HMS服务的内网IP地址,请您根据实际情况替换。本示例为EMR集群Master节点的内网IP地址,您可以在EMR集群的节点管理页面,打开emr-master节点组前的 图标查看。
图标查看。运行任务后,在下方的运行记录区域,单击任务操作列的日志探查。
在日志探查页签,您可以查看相关的日志信息。
SparkSQL任务
创建并启动SQL会话,详情请参见管理SQL会话。
网络连接:选择您在步骤一中新增的网络连接的名称。
Spark配置:需要配置以下参数信息。
spark.hadoop.hive.metastore.uris thrift://*.*.*.*:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactory其中,
*.*.*.*为HSM服务的内网IP地址,请您根据实际情况替换。本示例为EMR集群Master节点的内网IP地址,您可以在EMR集群的节点管理页面,打开emr-master节点组前的图标查看。
在EMR Serverless Spark页面,单击左侧的数据开发。
在开发目录页签下,单击
 图标。
图标。在新建对话框中,输入名称(例如users_task),类型使用默认的,然后单击确定。
在新建的任务开发中,选择Catalog、数据库和已启动的SQL会话实例,输入以下命令,并单击运行。
SELECT * FROM default.my_table;说明当您计划将基于外部Metastore的SQL代码部署到工作流时,请确保您的SQL语句以
db.table_name的形式指定表名,并且务必在界面右上方“Catalog”选项中选取一个默认库,其格式应为catalog_id.default。下方的运行结果区域会向您展示返回信息。
