
Ray集群是EMR Serverless Spark工作空间提供的分布式计算框架,支持Python原生分布式计算、机器学习模型训练与推理等场景。本文介绍如何创建、启动Ray集群,以及如何提交Ray作业。
前提条件
当前Ray集群为白名单功能,使用前需提交工单,提供工作空间ID和地域(Region)信息,申请开通Ray集群使用权限。
创建Ray集群
-
登录EMR Serverless Spark控制台,进入目标工作空间。
-
在左侧导航栏,单击集群管理,然后单击RAY集群页签。
-
单击创建Ray集群,在创建面板中配置以下参数,然后单击创建。
-
集群名称:输入集群名称。
-
引擎版本:选择引擎版本。当前提供默认版本err-1.0.1 (Ray 2.47.1, Python 3.12)。
-
节点组:单击+添加Worker节点组,配置以下信息。
-
节点组名称:输入节点组名称,不同节点组的名称不能重复。
-
资源队列:选择资源队列。
-
资源规格:选择节点规格。
-
节点数量:设置Worker节点数量。
-
(可选)弹性伸缩:配置弹性伸缩策略,按需自动扩缩Worker节点数量。
-
(可选)Worker节点自动终止:开启后,闲置的弹性创建的Worker节点将被自动销毁。
-
-
(可选)网络连接:如需从Ray集群访问同VPC内的服务或公网,选择已创建的网络连接。
-
(可选)纳管文件:如需在Ray集群中挂载目录,在左侧导航栏单击文件管理 > 纳管文件中添加,支持挂载OSS和NAS。详情请参见OSS挂载配置(纳管文件)。
-
(可选)集群高级配置:以JSON格式配置高级参数,详情请参见集群高级配置参数说明。
-
当前控制台暂不支持配置Worker节点自动伸缩,如需配置,可通过API方式修改,详情请参见CreateRayCluster - 创建Ray集群。
OSS挂载配置(纳管文件)
通过文件管理 > 纳管文件添加挂载文件时,支持配置以下挂载参数。
-
authType:挂载OSS时的鉴权方式。取值如下:
-
provider(默认):使用工作空间角色进行鉴权。 -
AK:使用AccessKey进行鉴权,需同时配置accessKeyId和accessKeySecret。
-
-
accessKeyId:当
authType为AK时,填写AccessKey ID。 -
accessKeySecret:当
authType为AK时,填写AccessKey Secret。 -
其他参数:挂载模式配置(字符串格式),
fs.jindo.args会被作为挂载启动参数,除此以外的参数会被写入到jindo配置文件中。支持以下挂载模式:-
快速读写(默认):读写速度快,但并发读写时可能存在数据不一致问题,适合挂载训练数据集和模型文件,不适合作为工作目录。
{ "fs.oss.download.thread.concurrency": "cpu核数2倍", "fs.oss.upload.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" } -
增量读写:增量写入时能保证数据一致性,覆盖已有数据时可能存在一致性问题,读取速度略慢,适合保存模型训练过程中的权重文件。
{ "fs.oss.upload.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oattr_timeout=3 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" } -
读写一致:并发读写时能保持数据一致性,读取速度较慢,适合对数据一致性要求高的场景,如保存代码项目。
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" } -
只读:仅允许读取,不允许写入,适合挂载公共数据集。
{ "fs.oss.download.thread.concurrency": "cpu核数2倍", "fs.jindo.args": "-oro -oattr_timeout=7200 -oentry_timeout=7200 -onegative_timeout=7200 -okernel_cache -ono_symlink" }
-
纳管文件高级配置示例
-
挂载时对读写一致要求高,使用工作空间角色鉴权:
{ "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" } -
挂载时对读写一致要求高,且使用自定义AccessKey鉴权:
{ "authType": "AK", "accessKeyId": "LTxxxxxxxxx", "accessKeySecret": "xxxxxxxxxxxxxx", "fs.jindo.args": "-oattr_timeout=0 -oentry_timeout=0 -onegative_timeout=0 -oauto_cache -ono_symlink" }
集群高级配置参数说明
集群高级配置以JSON格式填写,当前支持以下参数。
-
userDefinedFiles:指定在集群启动时需要下载到Head节点和Worker节点的OSS文件。支持OSS和OSS-HDFS路径,多个路径之间用英文逗号(,)分隔。文件下载至各节点的
/home/ray/work-dir目录下。示例:oss://mybucket/hello.py,oss://mybucket2/test/test.jar -
userRequirementsFile:指定用于初始化Head节点和Worker节点Python基础环境的requirements.txt文件。支持OSS和OSS-HDFS路径,路径格式必须为
oss://<bucket>/<path>/requirements.txt。Ray集群启动后,系统自动执行pip install -r requirements.txt命令(异步执行,不影响集群启动)。 -
gpuDriverVersion(仅GPU机型支持):指定GPU驱动版本。取值如下:
-
tesla=470:Tesla 470,CUDA 11.4。 -
tesla=535:Tesla 535,CUDA 12.2。 -
tesla=550(默认):Tesla 550,CUDA 12.4。
-
高级配置示例
以下示例配置了启动时下载OSS文件和初始化Python环境:
{
"userDefinedFiles": "oss://mybucket/hello.py,oss://mybucket2/test/test.jar",
"userRequirementsFile": "oss://mybucket/env/requirements.txt"
}启动Ray集群
-
在Ray集群列表中,找到目标集群,单击启动。
-
等待集群运行状态变为运行中。
说明工作空间内首次启动Ray集群时,系统需要创建额外组件,启动时间约需2~3分钟;后续启动速度会明显加快。
-
集群启动后,单击调用信息,记录提交Ray作业所需的地址和Token信息。
警告当前版本中,Token对同一Ray集群永久有效,请妥善保管,避免泄露。
单击Dashboard,可进入Ray集群的监控界面,查看集群资源使用情况。
单击指标大盘,可查看Ray集群的Metrics监控信息。
提交Ray作业
方式一:代码提交(批任务)
本地环境要求:Python 3.12。
-
安装Ray Job Submission客户端库:
pip install "ray[default]==2.47.1" -
在集群的调用信息页面,获取公网调用地址和Token。
-
使用以下示例代码连接Ray集群并提交作业:
import time from ray.job_submission import JobSubmissionClient custom_headers = { "ray-token": "<yourToken>" } client = JobSubmissionClient("<公网调用地址>", headers=custom_headers) # 或者用内网,需要保证提交端在同一region vpc下,建议内网提交,更加稳定 # client = JobSubmissionClient("http://emr-spark-ray-gateway-cn-beijing-internal.spark.emr.aliyuncs.com", headers=custom_headers) job_id = client.submit_job( entrypoint="python -c 'print(\"Hello from Ray Client!\")'" ) print(f"Submitted job with ID: {job_id}") while True: status = client.get_job_status(job_id) print(f"Job status: {status}") if status.is_terminal(): break time.sleep(1) logs = client.get_job_logs(job_id) print("Job logs:") print(logs)
方式二:命令行提交(批任务)
本地环境要求:Python 3.12。
-
安装Ray Job Submission客户端库:
pip install "ray[default]==2.47.1" -
在集群的调用信息页面,获取公网调用地址和Token。
-
执行以下命令提交Ray作业:
# ray job submit前必须设置ray address和headers export RAY_ADDRESS='<公网调用地址>' export RAY_JOB_HEADERS='{"ray-token": "<yourToken>"}' ## 提交任务 ### working dir 支持本地 & Ray core distrubuted sort ray job submit --working-dir "." -- python test-ray-core-sort.py ### 支持OSS读写 ray job submit --working-dir "." -- python test-saving-data-test.py ### 支持OSS-HDFS读写 ray job submit --working-dir "." -- python test-saving-data-oss-hdfs-test.py ### 代码支持Mount读写 ray job submit --working-dir "." -- python test-saving-data-test-mount.py
更多命令行参数,请参见Ray Job Submission CLI官方文档。
方式三:交互式开发
与Ray集群相同地域的VPC内访问,且环境为Python 3.12。
-
安装Ray客户端:
pip install ray[client]==2.47.1 -
在集群的调用信息页面,获取gRPC 地址和Token。
-
使用以下示例代码连接Ray集群,进行交互式开发:
import ray import os def get_metadata(): headers = {"ray-token": "<yourToken>"} return [(key.lower(), value) for key, value in headers.items()] ray.init(address="<your_gRPC_address>", _metadata=get_metadata()) import time @ray.remote def square(x): time.sleep(0.1) return x * x futures = [square.remote(i) for i in range(10)] results = ray.get(futures) print("平方结果:", results)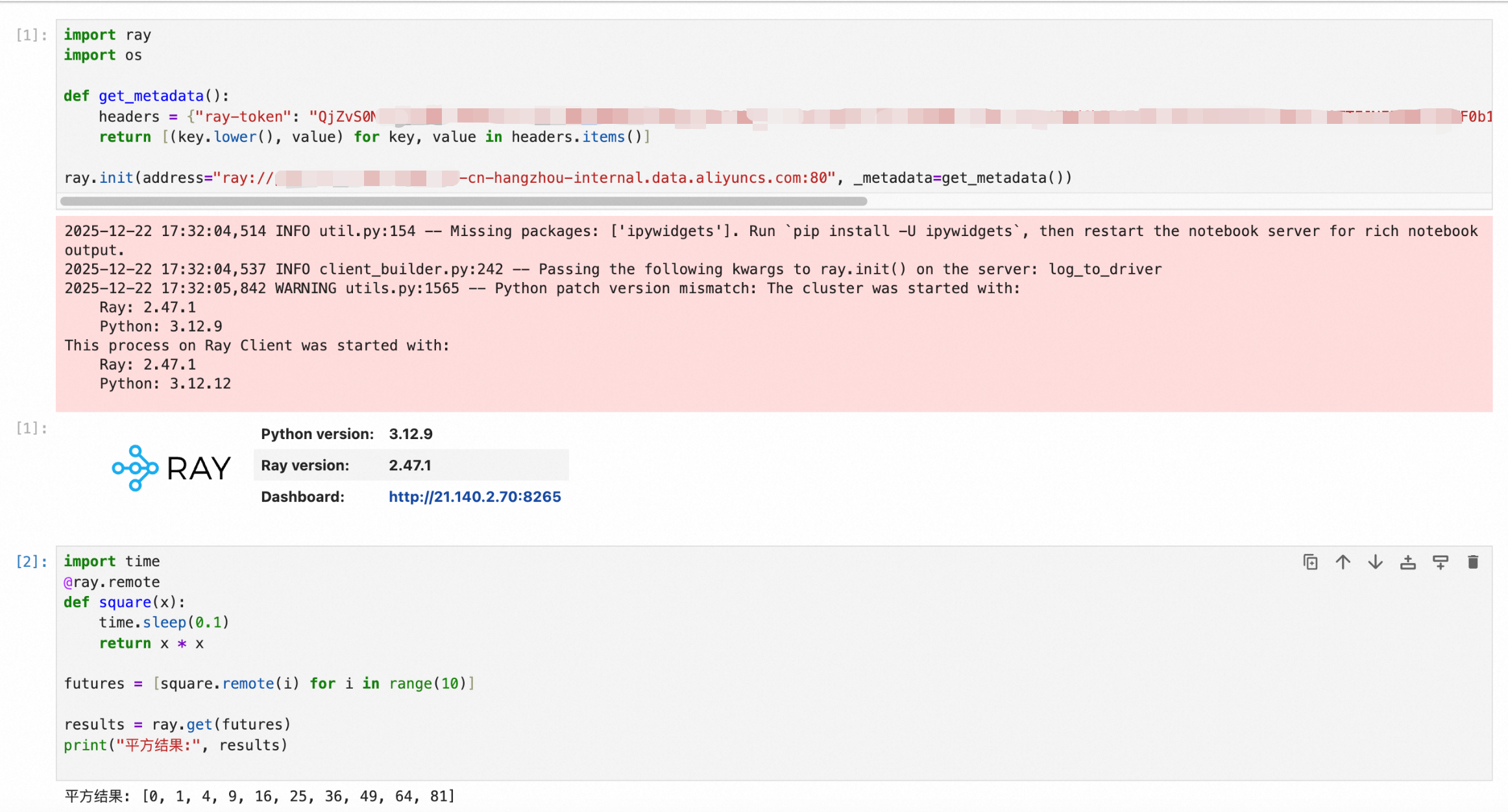
高级用法
Kerberos身份认证
EMR Serverless Ray支持以Kerberos身份访问OSS和OSS-HDFS。
前提条件
选择err-1.1.0及以上引擎版本。
操作步骤
-
在EMR Serverless Spark工作空间的安全中心开启Kerberos身份认证,绑定krb5.conf文件。krb5.conf文件可从EMR集群的/etc目录中获取。配置示例如下:
[logging] default = FILE:/mnt/disk1/log/kerberos/krb5libs.log kdc = FILE:/mnt/disk1/log/kerberos/krb5kdc.log admin_server = FILE:/mnt/disk1/log/kerberos/kadmind.log [libdefaults] default_realm = EMR.C-XXX.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true rdns = false dns_canonicalize_hostname = true pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt kdc_timeout = 30s max_retries = 3 [realms] EMR.XXX.COM = { kdc = master-1-1.c-xxx.cn-hangzhou.emr.aliyuncs.com:88 admin_server = master-1-1.c-xxx.cn-hangzhou.emr.aliyuncs.com:749 } -
绑定core-site.xml文件。在EMR半托管集群开启Kerberos + Ranger + OSS/DLS权限后,拷贝Hadoop core-site.xml文件,绑定到配置管理 > 自定义配置文件 > Ray中。配置路径为
/etc/ray/conf,文件名称为core-site.xml。文件内容需做以下修改:<property> <name>fs.oss.jindoauth.rpc.address</name> <value>[master真实域名或IP]:8201</value> </property> <property> <name>fs.dls.jindoauth.rpc.address</name> <value>[master真实域名或IP]:8201</value> </property> <property> <name>fs.jdo.plugin.dir</name> <value>/opt/apps/JINDOSDK/jindosdk-current/plugins</value> </property> -
启动新的Ray集群。
-
使用合法的Principal及Keytab文件,放在代码目录,并通过Ray CLI提交作业:
ray job submit --runtime-env-json='{"env_vars": {"KERBEROS_PRINCIPAL": "test@EMR.XXX.COM", "KERBEROS_KEYTAB": "test.keytab"}}' --working-dir "." -- python test.py
读写DLF(Paimon表)
EMR Serverless Ray支持通过PyPaimon读写DLF中的Paimon表。
Ray集群中需要已安装pypaimon(pypaimon依赖pyarrow)。EMR提供的镜像Python环境已预安装pypaimon。
仅支持VPC网络访问,不支持公网。
DLF服务接入点信息,请参见DLF服务接入点。
以下示例代码演示如何通过Ray读写DLF中的Paimon表:
import ray
import pandas as pd
data = [
(10, 'pic10.jpg'),
(11, 'pic11.png'),
(12, 'pic12.gif')
]
# 转换为DataFrame
df = pd.DataFrame(data, columns=['id', 'pic'])
ds = ray.data.from_pandas(df)
# 写入Paimon表(仅支持VPC网络)
ds.write_paimon(
table_identifier="default.my_table",
catalog_kwargs={
'metastore': 'rest',
'warehouse': '<DLF Catalogs名称>',
'uri': 'http://<region>-vpc.dlf.aliyuncs.com',
'dlf.region': '<region>'
}
)
# 读取Paimon表
ds1 = ray.data.read_paimon(
table_identifier="default.my_table",
catalog_kwargs={
'metastore': 'rest',
'warehouse': '<DLF Catalogs名称>',
'uri': 'http://<region>-vpc.dlf.aliyuncs.com',
'dlf.region': '<region>'
}
)
records = ds1.take_all()
for i, record in enumerate(records, 1):
print(f"记录 {i}: {record}")如果遇到权限问题,请参见DLF无权限问题排查。
读写Paimon File System
以下示例代码演示如何通过Ray读取OSS上的Paimon表:
import ray
# 读取Paimon表
ds = ray.data.read_paimon(
table_identifier="default.calculate_tbl",
catalog_kwargs={
"warehouse": "oss://<bucket>/paimon_warehouse",
"fs.oss.endpoint": "oss-<region>.aliyuncs.com",
"fs.oss.region": "<region>"
}
)
records = ds.take_all()
for i, record in enumerate(records, 1):
print(f"记录 {i}: {record}")