存算分离版实例适用于对存储成本高度敏感且对查询效率要求相对较低的业务场景,例如OLAP多维分析及数据仓库应用。此外,该实例也适合查询存储于Apache Hive、Apache Iceberg、Apache Hudi以及Apache Paimon等多种数据湖中的数据,涵盖OSS、OSS-HDFS及HDFS等多个平台。通过该实例,无需进行数据迁移即可实现快速的数据湖查询与分析,其性能较Presto高出3到5倍。该实例类型采用存算分离架构,将数据存储于阿里云OSS对象存储中。
前提条件
注意事项
代码的运行环境由所属用户负责管理和配置。
步骤一:创建存算分离版StarRocks实例
进入EMR Serverless StarRocks实例列表页面。
在左侧导航栏,选择。
在顶部菜单栏处,根据实际情况选择地域。
在实例列表页面,单击创建实例。
选择存算分离版的实例类型。
在E-MapReduce Serverless StarRocks页面,完成实例相关配置。
配置项
示例
描述
付费类型
按量付费
支持包年包月和按量付费的计费方式。
地域
华北2(北京)
实例所在的物理位置。
重要实例创建后,无法更改地域,请谨慎选择。
可用区
可用区I
实例所在可用区。
重要实例创建后,无法更改可用区,请谨慎选择。
专有网络
vpc_Hangzhou/vpc-bp1f4epmkvncimpgs****
选择对应地域下的专有网络。如果没有,单击创建VPC进行创建。创建完成后,单击右侧的
 图标,可以选择刚创建的VPC。
图标,可以选择刚创建的VPC。交换机
vsw_i/vsw-bp1e2f5fhaplp0g6p****
选择在对应专有网络下所选可用区内的交换机。如果在所选专有网络下没有交换机,可单击创建交换机前往创建。创建完成后,单击右侧的
图标,可以选择刚创建的交换机。实例系列
标准版
支持入门版和标准版,详情请参见实例系列说明。
版本
3.1
StarRocks的社区版本号。
CN规格
8 CU
StarRocks CN计算节点的规格。支持规格有8CU、16CU、32CU、64CU。
CN节点缓存
使用默认值即可
用于数据缓存,需要结合您期望数据读写性能选择合适的云盘类型、云盘大小,以及云盘个数。
缓存盘类型:推荐ESSD PL1云盘。更多信息,请参见块存储概述。
缓存盘大小:数量范围为50 ~ 65000 GB。
说明您可以输入所需的存储容量,系统将自动提供默认的推荐配置。如果您选择的云盘容量超出建议的阈值,系统会弹出相应的提示帮助您做出适当的调整以确保最佳性能。
缓存盘数量:默认为1个。
CN节点数量
3
StarRocks CN计算节点的数量。
高可用
开启
默认开启。标准版支持开启高可用,打开高可用开关后,StarRocks FE节点数由1增加为3,以降低故障风险。
重要生产环境强烈建议您开通高可用。
FE资源配置
规格:8 CU。
存储大小:100 GB。
节点数量:3个。
入门版:FE的资源配置默认为4 CU,50 GB,节点数量为1。
标准版:FE资源配置会随着BE的数量以及资源配置而自动适配。另外,FE的节点数量取决于是否开启高可用,不开启高可用,FE节点数量为1;开启高可用,FE节点数量为3。
数据存储
按实际使用量计费。
数据存储费用将会按照您的实际使用量,按GB/小时进行计费。为进一步节省成本,建议您购买存算分离存储包,详情请参见存算分离存储包。
资源配置总计
FE计算资源:24CU
存储资源:ESSD PL1云盘(推荐)300GB
CN计算资源:24CU
缓存资源:ESSD PL1云盘(推荐)600GB
数据存储:以实际使用量为准,计费详情请参考计费项
展示FE资源详情、CN资源详情以及数据存储详情。
实例名称
自定义实例名称。
实例名称,长度限制为1~64个字符,仅可使用中文、字母、数字、短划线(-)和下划线(_)。
管理员用户
admin
用于管理StarRocks的管理员用户,默认为admin,无法修改。
登录密码和确认密码
自定义密码。
StarRocks实例内置管理员用户admin的密码。请记录该配置,管理和使用StarRocks实例需要您输入该密码。
密码长度限制为8~30个字符,且必须包含至少一个大写字母、一个小写字母、一个数字和一个特殊字符
@#$%^*_+-。执行RAM角色
AliyunEMRStarRocksAccessingOSSRole
该角色将会授权StarRocks实例访问对象存储OSS的数据内容的权限。
(可选)
选择已创建的资源组
可以使用默认资源组,或者选择已有的资源组,或者单击创建资源组前往资源管理控制台新建一个资源组,详情请参见创建资源组。
说明资源组(Resource Group)是在阿里云账号下进行资源分组管理的一种机制,资源组能够帮助您解决单个阿里云账号内的资源分组和授权管理的复杂性问题。资源组更多信息,请参见什么是资源组。
(可选)
自定义标签
您可以在创建集群时绑定标签,也可以在集群创建完成后添加标签,这可以方便您识别和管理拥有的集群资源,详情请参见设置标签。
选中服务协议,单击创建实例,根据提示完成支付。
支付完成后,回到实例管理页面,查看创建的实例。当实例状态为运行中时,表示实例创建成功。
步骤二:连接StarRocks实例
在实例列表页面,单击操作列的连接实例。
您也可以通过其他方式连接StarRocks实例,详情请参见连接实例。
连接StarRocks实例。
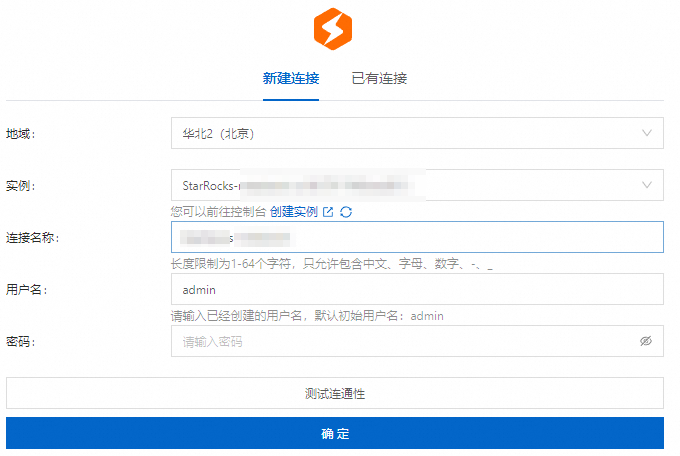
在新建连接页签,配置以下信息。
参数
示例
描述
地域
华东1(杭州)
选择已创建的StarRocks实例所在的物理位置。
实例
StarRocks_Serverlesss
选择已创建的StarRocks实例的名称。
连接名称
Connection_Serverlesss
连接名称,自定义输入。
长度限制为1~64字符,仅可使用中文、字母、数字、短划线(-)和下划线(_)。
用户名
根据实际情况输入
默认初始用户名为admin,您可以选择使用该用户名进行连接,或者根据需要创建其他用户,创建用户详情请参见管理用户及数据授权。
密码
根据实际情况输入
StarRocks实例中已创建的用户名对应的密码。
单击测试连通性。
验证通过后,单击确定。
进入SQL Editor页面,即可执行相关的SQL。更多使用信息,请参见通过EMR StarRocks Manager连接StarRocks实例。
步骤三:SQL查询
在SQL Editor的查询列表页面,单击![]() 图标,输入以下命令,然后单击运行。
图标,输入以下命令,然后单击运行。
/**创建数据库**/
CREATE DATABASE IF NOT EXISTS load_test;
/**使用数据库**/
USE load_test;
/**创建表**/
CREATE TABLE insert_wiki_edit
(
event_time DATETIME,
channel VARCHAR(32) DEFAULT '',
user VARCHAR(128) DEFAULT '',
is_anonymous TINYINT DEFAULT '0',
is_minor TINYINT DEFAULT '0',
is_new TINYINT DEFAULT '0',
is_robot TINYINT DEFAULT '0',
is_unpatrolled TINYINT DEFAULT '0',
delta INT SUM DEFAULT '0',
added INT SUM DEFAULT '0',
deleted INT SUM DEFAULT '0'
)
AGGREGATE KEY(event_time, channel, user, is_anonymous, is_minor, is_new, is_robot, is_unpatrolled)
PARTITION BY RANGE(event_time)
(
PARTITION p06 VALUES LESS THAN ('2015-09-12 06:00:00'),
PARTITION p12 VALUES LESS THAN ('2015-09-12 12:00:00'),
PARTITION p18 VALUES LESS THAN ('2015-09-12 18:00:00'),
PARTITION p24 VALUES LESS THAN ('2015-09-13 00:00:00')
)
DISTRIBUTED BY HASH(user) BUCKETS 10
PROPERTIES("replication_num" = "1");
/**插入数据**/
INSERT INTO insert_wiki_edit VALUES("2015-09-12 00:00:00","#en.wikipedia","GELongstreet",0,0,0,0,0,36,36,0),("2015-09-12 00:00:00","#ca.wikipedia","PereBot",0,1,0,1,0,17,17,0);
/**查询数据**/
select * from insert_wiki_edit;返回信息如下所示。

您可以通过执行SHOW CREATE TABLE load_test.insert_wiki_edit;命令,检查结果中是否包含datacache.enable属性来确认存算分离实例是否已经生效。此外,一旦存算分离库表创建成功,您还可以在OSS Bucket下找到新创建的库表目录。

步骤四:查看表信息
在SQL Editor中,输入以下命令,查看数据库。
SHOW PROC '/dbs';返回信息如下所示。

输入以下命令,查看表的详细信息。
SHOW PROC '/dbs/10061';返回信息如下所示。

其中,在存算分离模式下,CLOUD_NATIVE为表的类型字段标识;StoragePath为表在OSS对象存储中的路径,通过该路径可以定位到存算分离表的数据存储位置。
步骤五:Cache特性演示
在左侧导航栏,选择。
找到对应的Query,单击查询ID。
单击执行详情页签。
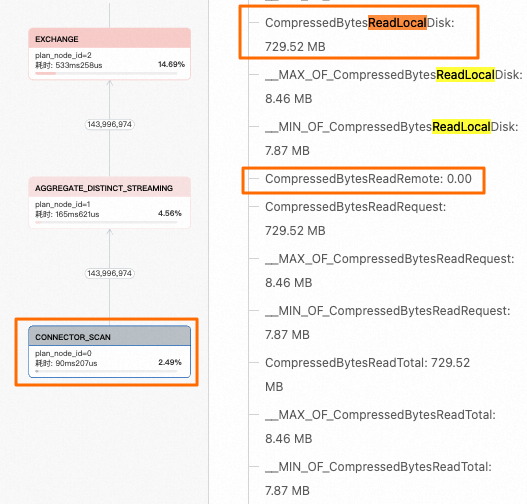
通过查看Profile执行树,您可以定位到相关节点,并重点关注右侧指标中的CompressedBytesReadLocalDisk(从本地缓存读取)和CompressedBytesReadRemote(从远端OSS对象存储读取)两个指标。
本示例中,insert_wiki_edit_cache表开启了本地缓存功能。通过观察相关指标值,可以确定查询全部命中了本地缓存。
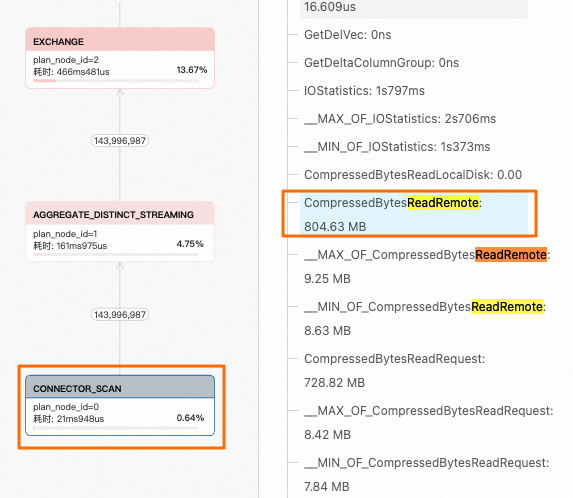
insert_wiki_edit_nocache表未启用本地缓存功能。通过分析其对应的指标值,可以确定该表的查询操作未命中本地缓存,数据全部来自远端OSS对象存储。
步骤六:性能测试
本示例为您展示了存算分离结合本地缓存和存算一体两种模式下的查询性能对比。您可以使用SSB测试集进行更详细的性能对比测试,详情请参见SSB性能测试说明。
准备数据环境。
集群资源配置:1FE(8CU)+3CN(算力:16CU|存储:1000 GB)。
集群参数:使用默认设置,存算分离集群开启本地缓存。
数据量:500 GB(sf=500)
测试结果。
存算一体总计用时:21.586s。
存算分离总计用时(第2次执行时开启本地缓存的情况下): 27.364s。
存算分离没有开启本地缓存,总计用时:117.529s。
执行sh ssb_query.sh ssb脚本进行SSB测试后,结果显示表明在开启本地缓存的情况下,存算分离和存算一体的查询性能基本相同,且明显优于未开启本地缓存时的性能。
SQL | 存算一体 | 存算分离开启data cache | 存算分离没有开启data cache |
Q1.1 | 0m0.373s | 0m0.380s | 0m2.080s |
Q1.2 | 0m0.303s | 0m0.292s | 0m2.141s |
Q1.3 | 0m0.101s | 0m0.097s | 0m0.144s |
Q2.1 | 0m2.461s | 0m2.821s | 0m14.401s |
Q2.2 | 0m2.272s | 0m2.735s | 0m13.048s |
Q2.3 | 0m2.168s | 0m2.588s | 0m13.957s |
Q3.1 | 0m4.536s | 0m4.864s | 0m14.810s |
Q3.2 | 0m2.371s | 0m2.682s | 0m11.292s |
Q3.3 | 0m2.082s | 0m2.648s | 0m13.651s |
Q3.4 | 0m0.195s | 0m0.212s | 0m0.572s |
Q4.1 | 0m5.122s | 0m5.847s | 0m29.576s |
Q4.2 | 0m1.141s | 0m1.369s | 0m1.465s |
Q4.3 | 0m0.661s | 0m0.829s | 0m0.792s |
Total | 21.586s | 27.364s | 117.529 s |
(可选)步骤七:释放实例
该操作将删除实例及该实例下的所有资源,且不可逆,请谨慎操作。
当您不再需要某个实例提供服务时,您可以释放该实例,以免产生额外的费用。
在实例列表页面,单击实例操作列的释放。
在弹出的对话框中,单击确定。
相关文档
如需了解SQL Editor更多操作,请参见SQL Editor。
如需查看当前实例的SQL查询信息,分析SQL的执行计划,及时诊断和排查SQL问题,详情请参见诊断与分析。
如需查看并分析数据库中发生的所有操作,详情请参见审计日志。
联系我们
如果您在使用过程中有任何疑问或问题,可以使用钉钉搜索群号24010016636进行咨询。