Serverless StarRocks基于可视化的Query Profile提供了诊断建议功能,您可以在查看Query Profile的同时,根据Query Profile诊断建议分析SQL性能问题、优化SQL性能。
前提条件
已启用Query Profile功能,详情请参见启用Query Profile。
使用Query Profile诊断建议
查看SQL语句诊断建议
在执行详情页面,如果存在SQL语句层面的诊断建议,则会在右侧执行概览面板中展现相关内容。SQL语句层面诊断建议说明,请查看SQL语句诊断建议。
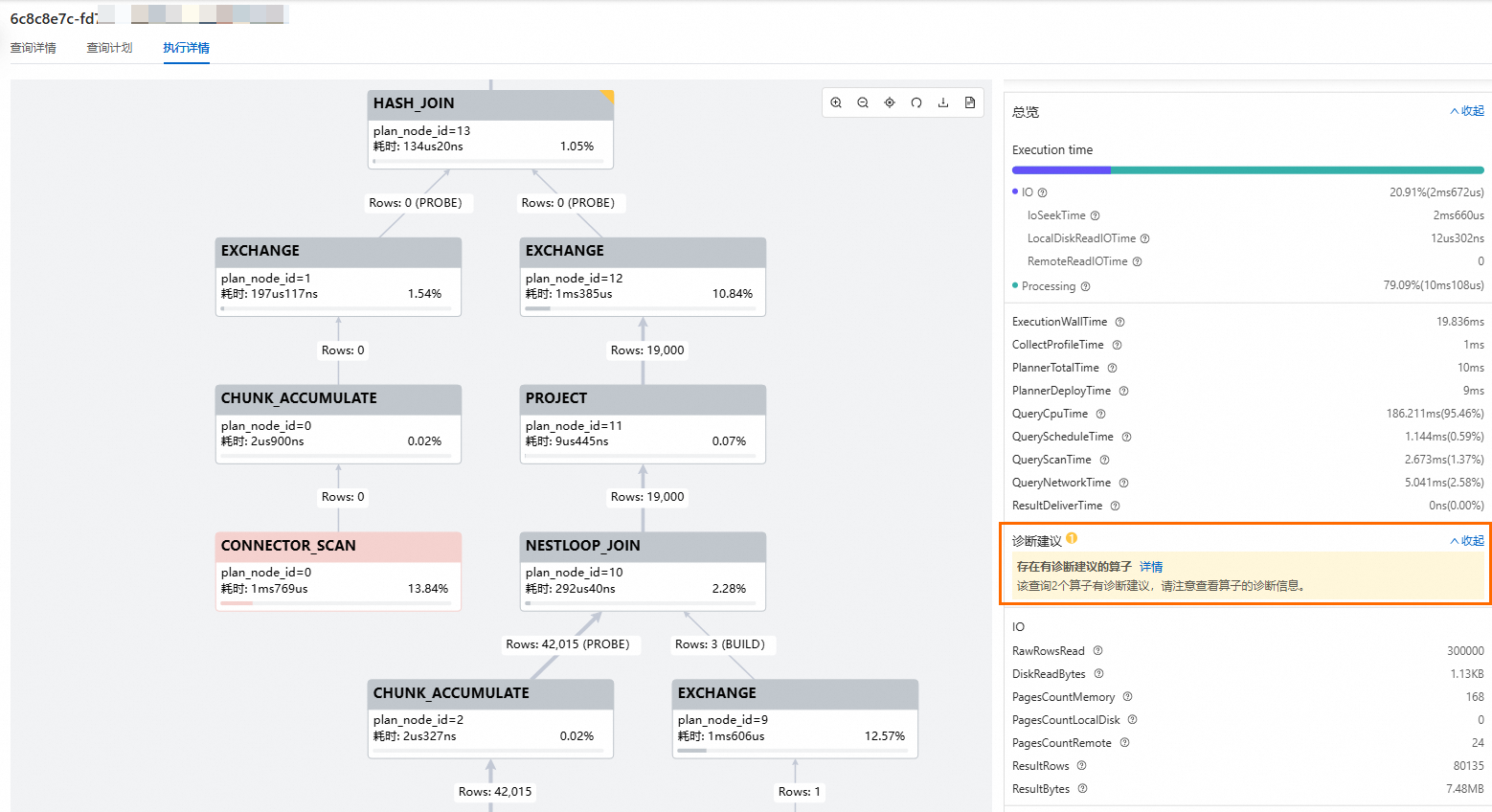
查看SQL算子诊断建议
在执行详情页面,选中右上角有黄色标记的算子节点,会在右侧面板中展现出关于该算子的诊断建议。SQL算子诊断建议说明,请查看SQL算子诊断建议。
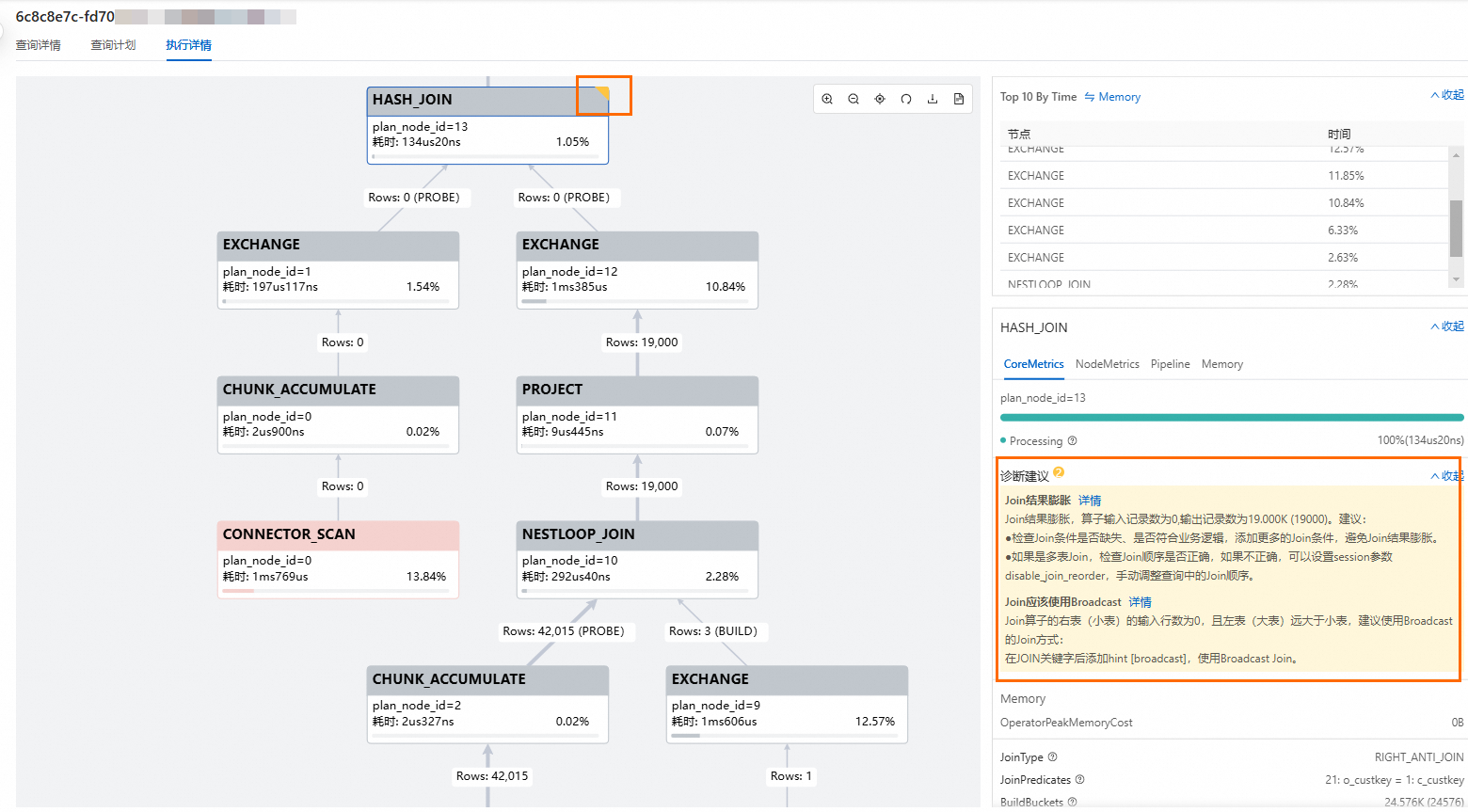
SQL语句诊断建议
Serverless StarRocks在分析Query Profile指标时,会自顶向下逐层分析各个层级的指标。在执行概览页面,除算子层面的指标外,系统汇总其他指标的分析结果,作为SQL语句整体的诊断建议,为SQL性能调优提供直观指导。
SQL语句层面的诊断建议包含以下内容:
Query Profile Summary部分的指标是否正常。例如,CollectProfileTime指标是否过大。
Query Profile Planner部分的指标是否正常。例如,CoordDeliverExec指标是否正常。
Fragment的指标是否正常。例如,是否存在Fragment各个实例执行时间倾斜的情况。
整合算子层面指标分析结果,汇总提示本次诊断分析的各个算子诊断建议数据。
SQL算子诊断建议
Serverless StarRocks基于Wall Time、执行CPU成本等指标相关模型选择需要诊断的算子,根据算子类别解读Query Profile指标,并给出算子的诊断建议。通常Wall Time占整体SQL语句执行时间比重越大的算子优化收益越大。但是,基于执行计划树整体的上下游算子的联动关系,即使对执行时间占比小的算子进行调整,也可能会触发计划树结构的优化重组,从而间接提升SQL语句的执行性能。
Query Profile算子诊断建议,分为通用算子的诊断建议和特定算子的诊断建议。本文列举一些常见的诊断建议,更多的诊断建议在实际使用Query Profile诊断功能时,会输出相应的诊断结果概要说明、建议以及详细诊断原因说明。
通用算子诊断建议
通用算子诊断建议是指该诊断建议适用于所有算子。
算子执行时间占比过高
StarRocks是个MPP执行引擎,一个算子通常会在多个节点以及同一个节点多个实例并发执行。当某个算子多个实例的最大执行时间占整个SQL执行时间的比例超过设置的阈值,且诊断引擎基于已有数据无法更进一步的诊断执行时间占比过高的原因时,系统会给出“算子执行时间占比过高”的诊断建议。请关注并优化执行时间占比过高的算子。
Scan算子诊断建议
诊断建议 | 问题描述 | 建议措施 |
数据倾斜 | StarRocks数据在各个存储节点分布不均,使得某些节点在读取数据时需要扫描更多的数据,导致查询延迟。 | 建议检查并优化分桶键设置,确保数据更均匀分布。 |
IO倾斜 | Scan算子多个实例在读取数据时,部分实例花费的时间显著大于其它实例时间。 | 建议从以下方面进行排查:
|
数据扫描未有效过滤 | 基于扫描原始数据量以及最终查询语句输出数据量、结合Query Profile执行树信息进行判断。当Scan算子本身扫描数据量较大,同时输出给下游算子的数据量未显著过滤的情况下,认为数据扫描未有效过滤。 | StarRocks提供索引、谓词下推、Join Runtime Filter等多种方式过滤Scan算子的数据量,可以通过多种方式来提高Scan算子的扫描过滤效率。建议从以下方面进行排查:
|
Join算子诊断建议
诊断建议 | 问题描述 | 建议措施 |
Join结果膨胀 | 正常情况下,Join算子的输出结果行数一般小于等于输入行数。如果输出结果显著大于输入结果,则视为Join结果膨胀。此种情况通常是缺少Join条件造成Cross Join,或者Join条件错误导致Join的两张表数据出现1:N的情况。还有一些情况是缺少统计信息、或者数据变更后统计信息过期,导致优化器选择了错误的计划。 | 建议从以下方面进行排查:
|
Join build表选择不合理 | 在Join算子中,Build阶段系统通常会在内存中创建哈希表,Build表数据量过大会消耗更多的内存资源。此种情况,通常是因为执行优化器没有正确的选择Build表所致。 | 建议从以下方面进行排查:
|
Join不应该使用Broadcast | 当小表与大表Join时,如果小表远小于大表,Broadcast Join可以将小表广播到大表所在节点,避免大表的数据重分布,从而有效降低了网络传输的开销。但某些情况下,由于统计信息错误等原因,优化器错误地估计了表的大小,导致较大的表也使用了Broadcast Join,增加网络和计算的成本。 | 建议在JOIN关键字后添加 |
Aggregate算子诊断建议
诊断建议 | 问题描述 | 建议措施 |
Aggregate本地聚合度低 | 在执行聚合操作时,各个计算节点通常会先在本地聚合获取较小聚合结果后再分发到其它节点,以减少网络数据传输。但某些情况下,本地聚合时未能有效缩减数据量,不仅不能减少网络数据传输,反而会消耗大量的计算资源。 | 如果Aggregate整体(包括非本地聚合部分)执行时间较长,则建议通过修改Session参数 |
相关文档
如果您想了解Query Profile的结构和指标,详情请参见Query Profile介绍。