StarRocks提供Apache Flink连接器(以下简称Flink Connector),可以通过Flink导入数据至StarRocks表。相比于Flink自带的flink-connector-jdbc,StarRocks的Flink Connector性能更优越且稳定性更强,特别适合大规模数据导入场景。
背景信息
StarRocks Flink Connector通过在内存中缓存小批次数据,并利用StarRocks的Stream Load功能进行批量导入,支持DataStream API、Table API & SQL以及 Python API,能够显著提升数据导入效率。
前提条件
使用限制
确保Flink所在机器能够访问StarRocks实例中FE节点的http_port端口(默认
8030)和query_port端口(默认9030),以及BE节点的be_http_port端口(默认8040)。使用Flink Connector导入数据至StarRocks需要目标表的SELECT和INSERT权限。
Flink Connector版本与Java、Scala环境及Flink版本等兼容性要求如下。
Connector
Flink
StarRocks
Java
Scala
1.2.9
1.15~1.18
2.1及以上
8
2.11、2.12
1.2.8
1.13~1.17
2.1及以上
8
2.11、2.12
1.2.7
1.11~1.15
2.1及以上
8
2.11、2.12
配置相关
这部分将为您介绍StarRocks的参数设置及其相应的数据类型映射。有关更详细的信息,请参见从 Apache Flink® 持续导入 | StarRocks。
参数说明
参数 | 是否必填 | 默认值 | 描述 |
| Yes | NONE | 指定连接器为StarRocks,固定设置为 |
| Yes | NONE | 用于在StarRocks中执行查询操作。 例如,jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030。其中, 说明 关于如何获取EMR Serverless StarRocks实例FE节点的内网地址,请参见查看实例列表与详情。 |
| Yes | NONE | 指定FE节点的内网地址和HTTP端口,格式为 例如,fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030。 |
| Yes | NONE | StarRocks数据库名。 |
| Yes | NONE | StarRocks表名。 |
| Yes | NONE | StarRocks实例的用户名。例如,默认的admin。 使用Flink Connector导入数据至StarRocks需要目标表的SELECT和INSERT权限。如果您的用户账号没有这些权限,则需要为用户授权,详情请参见管理用户及数据授权。 |
| Yes | NONE | StarRocks实例的用户密码。 |
| No | at-least-once | 定义Sink的语义保证级别,用于确保数据写入目标系统时的可靠性和一致性。取值如下:
|
| No | AUTO | 导入数据的接口。此参数自Flink Connector 1.2.4开始支持。
|
| No | NONE | 指定Stream Load使用的label的前缀。 如果Flink Connector版本为1.2.8及以上,并且Sink保证exactly-once语义,则建议配置label前缀。 |
| No | 94371840(90M) | 积攒在内存的数据大小,达到该阈值后数据通过Stream Load一次性导入StarRocks。设置较大的值可以提高导入性能,但可能导致更高的导入延迟。 取值范围:[64MB, 10GB]。 说明
|
sink.buffer-flush.max-rows | No | 500000 | 积攒在内存的数据条数,达到该阈值后数据通过Stream Load一次性导入StarRocks。 取值范围:[64000, 5000000]。 说明 该参数仅在 |
sink.buffer-flush.interval-ms | No | 300000 | 设置数据发送的时间间隔,控制数据写入StarRocks的延迟。 取值范围:[1000, 3600000]。 说明 该参数仅在 |
sink.max-retries | No | 3 | Stream Load失败后的重试次数。超过该数量上限,则数据导入任务报错。 取值范围:[0, 10]。 说明 该参数仅在 |
sink.connect.timeout-ms | No | 30000 | 与FE建立HTTP连接的超时时间。 取值范围:[100, 60000]。 Flink Connector v1.2.9之前,默认值为 |
sink.socket.timeout-ms | No | -1 | 此参数自Flink connector 1.2.10开始支持。HTTP 客户端等待数据的超时时间。单位:毫秒。默认值 |
sink.wait-for-continue.timeout-ms | No | 10000 | 此参数自Flink Connector 1.2.7开始支持。等待FE HTTP 100-continue应答的超时时间。 取值范围:[3000, 60000]。 |
sink.ignore.update-before | No | TRUE | 此参数自Flink Connector 1.2.8开始支持。将数据导入到主键表时,是否忽略来自Flink的UPDATE_BEFORE记录。如果将此参数设置为false,则将该记录在主键表中视为DELETE操作。 |
sink.parallelism | No | NONE | 写入的并行度,仅适用于Flink SQL。如果未设置, Flink planner将决定并行度。在多并行度的场景中,用户需要确保数据按正确顺序写入。 |
sink.properties.* | No | NONE | Stream Load的参数,控制Stream Load导入行为。 |
sink.properties.format | No | csv | Stream Load导入时的数据格式。Flink Connector会将内存的数据转换为对应格式,然后通过Stream Load导入至StarRocks。取值为CSV或JSON。 |
sink.properties.column_separator | No | \t | CSV数据的列分隔符。 |
sink.properties.row_delimiter | No | \n | CSV数据的行分隔符。 |
sink.properties.max_filter_ratio | No | 0 | 导入作业的最大容错率,即导入作业能够容忍的因数据质量不合格而过滤掉的数据行所占的最大比例。 取值范围:0~1。 |
sink.properties.partial_update | No | false | 是否使用部分更新。取值包括 |
sink.properties.partial_update_mode | No | row | 指定部分更新的模式,取值如下:
|
sink.properties.strict_mode | No | false | 是否为Stream Load启用严格模式。严格模式会在导入数据中出现不合格行(如列值不一致)时影响导入行为。 有效值: |
sink.properties.compression | No | NONE | 此参数自Flink Connector 1.2.10开始支持。指定用于Stream Load的压缩算法。当前仅支持JSON格式的压缩。 有效值: 说明 仅StarRocks v3.2.7及更高版本支持JSON格式的压缩。 |
数据类型映射
Flink数据类型 | StarRocks数据类型 |
BOOLEAN | BOOLEAN |
TINYINT | TINYINT |
SMALLINT | SMALLINT |
INTEGER | INTEGER |
BIGINT | BIGINT |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DECIMAL | DECIMAL |
BINARY | INT |
CHAR | STRING |
VARCHAR | STRING |
STRING | STRING |
DATE | DATE |
TIMESTAMP_WITHOUT_TIME_ZONE(N) | DATETIME |
TIMESTAMP_WITH_LOCAL_TIME_ZONE(N) | DATETIME |
ARRAY<T> | ARRAY<T> |
MAP<KT,VT> | JSON STRING |
ROW<arg T...> | JSON STRING |
准备工作
获取Flink Connector JAR并上传至Flink集群
您可以通过以下方式获取Flink Connector JAR包。
方式1:直接下载
从Maven Central Repository获取不同版本的Flink Connector JAR文件。
方式2:Maven依赖
在Maven项目的
pom.xml文件中,根据以下格式将Flink Connector添加为依赖项。适用于Flink 1.15版本及以后的Flink Connector。
<dependency> <groupId>com.starrocks</groupId> <artifactId>flink-connector-starrocks</artifactId> <version>${connector_version}_flink-${flink_version}</version> </dependency>适用于Flink 1.15版本之前的Flink Connector。
<dependency> <groupId>com.starrocks</groupId> <artifactId>flink-connector-starrocks</artifactId> <version>${connector_version}_flink-${flink_version}_${scala_version}</version> </dependency>
方式3:手动编译
执行以下命令,将Flink Connector的源代码编译成一个JAR文件。
sh build.sh <flink_version>例如,如果您的环境中的Flink版本为1.17,您需要执行以下命令。
sh build.sh 1.17编译完成后,在
target/目录下找到生成的JAR文件。例如,文件名通常为
flink-connector-starrocks-1.2.7_flink-1.17-SNAPSHOT.jar格式。说明非正式发布的Flink Connector版本会带有
SNAPSHOT后缀。
Flink Connector JAR文件的命名格式如下:
适用于Flink 1.15版本及以后的Flink Connector命名格式为
flink-connector-starrocks-${connector_version}_flink-${flink_version}.jar。例如您安装了Flink 1.17,并且想要使用1.2.8版本的Flink Connector,则您可以使用flink-connector-starrocks-1.2.8_flink-1.17.jar。适用于Flink 1.15版本之前的Flink Connector命名格式为
flink-connector-starrocks-${connector_version}_flink-${flink_version}_${scala_version}.jar。例如您安装了Flink 1.14和Scala 2.12,并且您想要使用1.2.7版本的Flink Connector,您可以使用flink-connector-starrocks-1.2.7_flink-1.14_2.12.jar。说明请根据实际情况替换以下信息:
flink_version:Flink的版本号。scala_version:Scala的版本号。connector_version:Flink Connector的版本号。
将获取到的Flink Connector JAR文件上传至Flink集群的
flink-{flink_version}/lib目录下。例如,如果您使用的是EMR集群,且集群版本为EMR-5.19.0,则JAR文件应放置于
/opt/apps/FLINK/flink-current/lib目录下。
启动Flink集群
登录Flink集群的Master节点,详情请参见登录集群。
执行以下命令,启动Flink集群。
/opt/apps/FLINK/flink-current/bin/start-cluster.sh
使用示例
使用Flink SQL写入数据
在StarRocks中创建一个名为
test的数据库,并在其中创建一张名为score_board的主键表。CREATE DATABASE test; CREATE TABLE test.score_board( id int(11) NOT NULL COMMENT "", name varchar(65533) NULL DEFAULT "" COMMENT "", score int(11) NOT NULL DEFAULT "0" COMMENT "" ) ENGINE=OLAP PRIMARY KEY(id) DISTRIBUTED BY HASH(id);登录Flink集群的Master节点,详情请参见登录集群。
执行以下命令,启动Flink SQL。
/opt/apps/FLINK/flink-current/bin/sql-client.sh执行以下命令,创建一个名为
score_board的表,并向其中插入数据。CREATE TABLE `score_board` ( `id` INT, `name` STRING, `score` INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>', ); INSERT INTO `score_board` VALUES (1, 'starrocks', 100), (2, 'flink', 100);如果目标是将数据导入StarRocks主键表,则必须在Flink表的DDL中明确指定主键。对于其他类型的StarRocks表(如Duplicate Key表),定义主键则为可选项。
使用Flink DataStream写入数据
根据输入记录(input records)的不同类型,编写对应Flink DataStream作业。
写入CSV格式的字符串数据
如果输入记录为CSV格式的字符串,对应的Flink DataStream作业的主要代码如下所示,完整代码请参见LoadCsvRecords。
/** * Generate CSV-format records. Each record has three values separated by "\t". * These values will be loaded to the columns `id`, `name`, and `score` in the StarRocks table. */ String[] records = new String[]{ "1\tstarrocks-csv\t100", "2\tflink-csv\t100" }; DataStream<String> source = env.fromElements(records); /** * Configure the Flink connector with the required properties. * You also need to add properties "sink.properties.format" and "sink.properties.column_separator" * to tell the Flink connector the input records are CSV-format, and the column separator is "\t". * You can also use other column separators in the CSV-format records, * but remember to modify the "sink.properties.column_separator" correspondingly. */ StarRocksSinkOptions options = StarRocksSinkOptions.builder() .withProperty("jdbc-url", jdbcUrl) .withProperty("load-url", loadUrl) .withProperty("database-name", "test") .withProperty("table-name", "score_board") .withProperty("username", "root") .withProperty("password", "") .withProperty("sink.properties.format", "csv") .withProperty("sink.properties.column_separator", "\t") .build(); // Create the sink with the options. SinkFunction<String> starRockSink = StarRocksSink.sink(options); source.addSink(starRockSink);写入JSON格式的字符串数据
如果输入记录为JSON格式的字符串,对应的Flink DataStream作业的主要代码如下所示,完整代码请参见LoadJsonRecords。
/** * Generate JSON-format records. * Each record has three key-value pairs corresponding to the columns id, name, and score in the StarRocks table. */ String[] records = new String[]{ "{\"id\":1, \"name\":\"starrocks-json\", \"score\":100}", "{\"id\":2, \"name\":\"flink-json\", \"score\":100}", }; DataStream<String> source = env.fromElements(records); /** * Configure the Flink connector with the required properties. * You also need to add properties "sink.properties.format" and "sink.properties.strip_outer_array" * to tell the Flink connector the input records are JSON-format and to strip the outermost array structure. */ StarRocksSinkOptions options = StarRocksSinkOptions.builder() .withProperty("jdbc-url", jdbcUrl) .withProperty("load-url", loadUrl) .withProperty("database-name", "test") .withProperty("table-name", "score_board") .withProperty("username", "root") .withProperty("password", "") .withProperty("sink.properties.format", "json") .withProperty("sink.properties.strip_outer_array", "true") .build(); // Create the sink with the options. SinkFunction<String> starRockSink = StarRocksSink.sink(options); source.addSink(starRockSink);写入自定义Java对象数据
如果输入记录为自定义的Java对象,对应的Flink DataStream作业的主要代码如下所示,完整代码请参见LoadCustomJavaRecords。
本示例中,定义一个简单的POJO类
RowData,用于表示每条记录。public static class RowData { public int id; public String name; public int score; public RowData() {} public RowData(int id, String name, int score) { this.id = id; this.name = name; this.score = score; } }主要代码如下所示。
// Generate records which use RowData as the container. RowData[] records = new RowData[]{ new RowData(1, "starrocks-rowdata", 100), new RowData(2, "flink-rowdata", 100), }; DataStream<RowData> source = env.fromElements(records); // Configure the Flink connector with the required properties. StarRocksSinkOptions options = StarRocksSinkOptions.builder() .withProperty("jdbc-url", jdbcUrl) .withProperty("load-url", loadUrl) .withProperty("database-name", "test") .withProperty("table-name", "score_board") .withProperty("username", "root") .withProperty("password", "") .build(); /** * The Flink connector will use a Java object array (Object[]) to represent a row to be loaded into the StarRocks table, * and each element is the value for a column. * You need to define the schema of the Object[] which matches that of the StarRocks table. */ TableSchema schema = TableSchema.builder() .field("id", DataTypes.INT().notNull()) .field("name", DataTypes.STRING()) .field("score", DataTypes.INT()) // When the StarRocks table is a Primary Key table, you must specify notNull(), for example, DataTypes.INT().notNull(), for the primary key `id`. .primaryKey("id") .build(); // Transform the RowData to the Object[] according to the schema. RowDataTransformer transformer = new RowDataTransformer(); // Create the sink with the schema, options, and transformer. SinkFunction<RowData> starRockSink = StarRocksSink.sink(schema, options, transformer); source.addSink(starRockSink);其中
RowDataTransformer定义如下所示。private static class RowDataTransformer implements StarRocksSinkRowBuilder<RowData> { /** * Set each element of the object array according to the input RowData. * The schema of the array matches that of the StarRocks table. */ @Override public void accept(Object[] internalRow, RowData rowData) { internalRow[0] = rowData.id; internalRow[1] = rowData.name; internalRow[2] = rowData.score; // When the StarRocks table is a Primary Key table, you need to set the last element to indicate whether the data loading is an UPSERT or DELETE operation. internalRow[internalRow.length - 1] = StarRocksSinkOP.UPSERT.ordinal(); } }
使用Flink CDC 3.0同步数据
Flink CDC 3.0框架能够轻松构建从CDC数据源(如MySQL、Kafka)到StarRocks的流式ELT管道。通过该管道,您可以实现以下功能:
自动创建数据库和表
同步全量和增量数据
同步Schema Change
自StarRocks Flink Connector v1.2.9版本起,该连接器已整合至Flink CDC 3.0框架中,并被命名为StarRocks Pipeline Connector。该连接器具备上述所有功能,建议与StarRocks v3.2.1及以上版本配合使用,以充分利用fast_schema_evolution特性,进一步提升列的增减速度并降低资源消耗。
最佳实践
导入至主键表
在StarRocks中创建一个名为
test的数据库,并在其中创建一个主键表score_board。CREATE DATABASE `test`; CREATE TABLE `test`.`score_board` ( `id` int(11) NOT NULL COMMENT "", `name` varchar(65533) NULL DEFAULT "" COMMENT "", `score` int(11) NOT NULL DEFAULT "0" COMMENT "" ) ENGINE=OLAP PRIMARY KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`);向StarRocks表中插入数据。
INSERT INTO `test`.`score_board` VALUES (1, 'starrocks', 100), (2, 'flink', 100);执行以下命令,启动Flink SQL客户端。
/opt/apps/FLINK/flink-current/bin/sql-client.sh更新数据。
部分更新
部分更新允许您仅更新指定列(如
name),而不影响其他列(如score)。在Flink SQL客户端创建表
score_board,并启用部分更新功能。CREATE TABLE `score_board` ( `id` INT, `name` STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>', 'sink.properties.partial_update' = 'true', -- only for Flink connector version <= 1.2.7 'sink.properties.columns' = 'id,name,__op' );sink.properties.partial_update:启用部分更新。sink.properties.columns:指定需要更新的列。如果 Flink Connector版本小于等于1.2.7,则还需要将选项sink.properties.columns设置为id,name,__op,以告诉 Flink connector 需要更新的列。请注意,您需要在末尾附加字段__op。字段__op表示导入是 UPSERT 还是 DELETE 操作,其值由 Flink connector 自动设置。
插入更新数据。
插入两行数据,主键与现有数据相同,但
name列的值被修改。INSERT INTO score_board VALUES (1, 'starrocks-update'), (2, 'flink-update');在SQL Editor中查询StarRocks表。
SELECT * FROM `test`.`score_board`;您会看到只有
name列的值发生了变化,而score列保持不变。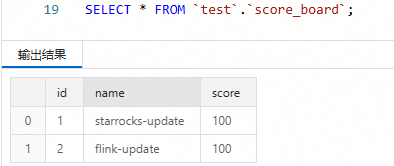
条件更新
本示例展示如何根据
score列的值进行条件更新。只有导入的数据行中score列值大于等于StarRocks表当前值时,该数据行才会更新。在Flink SQL客户端按照以下方式创建表
score_board。CREATE TABLE `score_board` ( `id` INT, `name` STRING, `score` INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'score_board', 'username' = 'admin', 'password' = '<password>', 'sink.properties.merge_condition' = 'score', 'sink.version' = 'V1' );sink.properties.merge_condition:设置为score,表示在数据写入时,Flink Connector会以score列作为更新条件。sink.version:设置为V1,表示Flink Connector使用Stream Load接口导入数据。
在Flink SQL客户端插入两行数据到表中。
数据行的主键与StarRocks表中的行相同。第一行数据
score列中具有较小的值,而第二行数据score列中具有较大的值。INSERT INTO `score_board` VALUES (1, 'starrocks-update', 99), (2, 'flink-update', 101);在SQL Editor中查询StarRocks表。
SELECT * FROM `test`.`score_board`;您会看到只有第二行数据发生了变化,而第一行数据未发生变化。
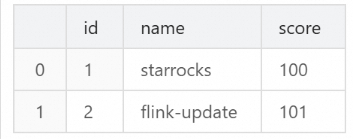
导入至Bitmap列
Bitmap类型常用于加速精确去重计数场景,例如计算独立访客数(UV)。以下是一个完整的示例,展示如何通过Flink SQL将数据导入到StarRocks表的Bitmap列中,并在StarRocks中查询UV数。
在SQL Editor中创建StarRocks聚合表。
在数据库
test中创建一个聚合表page_uv,其中:visit_users列被定义为 BITMAP 类型,并配置聚合函数BITMAP_UNION。page_id和visit_date作为聚合键(AGGREGATE KEY),用于分组和去重。
CREATE TABLE `test`.`page_uv` ( `page_id` INT NOT NULL COMMENT 'page ID', `visit_date` datetime NOT NULL COMMENT 'access time', `visit_users` BITMAP BITMAP_UNION NOT NULL COMMENT 'user ID' ) ENGINE=OLAP AGGREGATE KEY(`page_id`, `visit_date`) DISTRIBUTED BY HASH(`page_id`);在Flink SQL客户端中创建表。
由于Flink不支持Bitmap类型,需要通过以下方式实现列映射和类型转换:
在Flink表中,将
visit_user_id列定义为BIGINT类型,以代表StarRocks表中的visit_users列。使用
sink.properties.columns配置,将visit_user_id列的数据通过to_bitmap函数转换为Bitmap类型。
CREATE TABLE `page_uv` ( `page_id` INT, `visit_date` TIMESTAMP, `visit_user_id` BIGINT ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'page_uv', 'username' = 'admin', 'password' = '<password>', 'sink.properties.columns' = 'page_id,visit_date,visit_user_id,visit_users=to_bitmap(visit_user_id)' );在Flink SQL客户端中插入数据。
向表
page_uv插入多行数据,模拟不同用户在不同时间访问页面的行为。visit_user_id是BIGINT类型,Flink会将其自动转换为Bitmap类型。INSERT INTO `page_uv` VALUES (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 13), (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 23), (1, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 33), (1, CAST('2020-06-23 02:30:30' AS TIMESTAMP), 13), (2, CAST('2020-06-23 01:30:30' AS TIMESTAMP), 23);在SQL Editor中查询UV数。
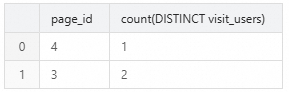
通过StarRocks的聚合能力,使用
COUNT(DISTINCT visit_users)计算每个页面的独立访客数(UV)。SELECT page_id, COUNT(DISTINCT visit_users) FROM page_uv GROUP BY page_id;返回结果如下所示。
导入至HLL列
HLL(HyperLogLog)是一种用于近似去重计数的数据类型,适合处理大规模数据的独立访客数(UV)计算。以下是一个完整的示例,展示如何通过Flink SQL将数据导入到StarRocks表的HL 列中,并在StarRocks中查询UV数。
在SQL Editor中创建StarRocks聚合表。
在数据库
test中创建一个聚合表hll_uv,其中:visit_users列被定义为HLL类型,并配置聚合函数HLL_UNION。page_id和visit_date作为聚合键(AGGREGATE KEY),用于分组和去重。
CREATE TABLE `test`.`hll_uv` ( `page_id` INT NOT NULL COMMENT 'page ID', `visit_date` DATETIME NOT NULL COMMENT 'access time', `visit_users` HLL HLL_UNION NOT NULL COMMENT 'user ID' ) ENGINE=OLAP AGGREGATE KEY(`page_id`, `visit_date`) DISTRIBUTED BY HASH(`page_id`);在Flink SQL客户端中创建表。
由于Flink不支持HLL类型,需要通过以下方式实现列映射和类型转换:
在Flink表中,将
visit_user_id列定义为BIGINT类型,以代表StarRocks表中的visit_users列。使用
sink.properties.columns配置列映射,并通过hll_hash函数将BIGINT类型的visit_user_id数据转换为HLL类型。
CREATE TABLE `hll_uv` ( `page_id` INT, `visit_date` TIMESTAMP, `visit_user_id` BIGINT ) WITH ( 'connector' = 'starrocks', 'jdbc-url' = 'jdbc:mysql://<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:9030', 'load-url' = '<fe-{srClusterId}-internal.starrocks.aliyuncs.com>:8030', 'database-name' = 'test', 'table-name' = 'hll_uv', 'username' = 'admin', 'password' = '<password>', 'sink.properties.columns' = 'page_id,visit_date,visit_user_id,visit_users=hll_hash(visit_user_id)' );在Flink SQL客户端中插入数据。
向表
hll_uv插入多行数据,模拟不同用户在不同时间访问页面的行为。visit_user_id是BIGINT类型,Flink会将其自动转换为HLL类型。INSERT INTO `hll_uv` VALUES (3, CAST('2023-07-24 12:00:00' AS TIMESTAMP), 78), (4, CAST('2023-07-24 13:20:10' AS TIMESTAMP), 2), (3, CAST('2023-07-24 12:30:00' AS TIMESTAMP), 674);在SQL Editor中查询UV数。
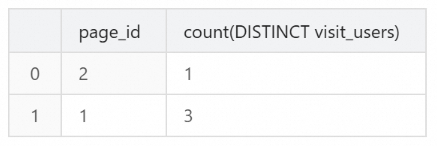
通过StarRocks的聚合能力,使用
COUNT(DISTINCT visit_users)计算每个页面的独立访客数(UV)。SELECT `page_id`, COUNT(DISTINCT `visit_users`) FROM `hll_uv` GROUP BY `page_id`;返回结果如下所示。