Alink是基于实时计算引擎Flink研发的机器学习算法平台,提供了分类、聚类、回归、推荐、图算法、NLP、异常检测、关联规则和相似度计算等几十种常见的机器学习算法。在此基础上,Alink也为Python用户提供了PyAlink。本文为您介绍如何在DataScience上使用基于Kubernetes的Flink集群运行PyAlink任务。
背景信息
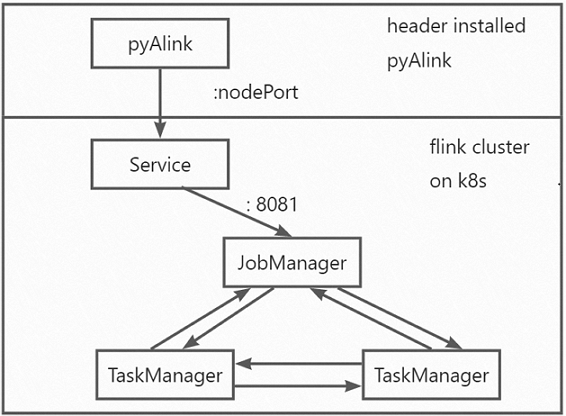
创建DataSicienc集群后,您开启一个终端可以查看到已经安装的K8s集群,您需要在K8s集群上进一步部署Flink集群,并让PyAlink在该Flink集群上运行。您需要安装PyAlink,还需要在K8s部署Flink
Service。Flink Service通过标签关联一组Pod(一个JobManager角色和若干TaskManager角色的Pod),该Service的类型为NodePort,您可以在浏览器通过
<公网IP地址>:nodePort访问Flink UI。
前提条件
已在E-MapReduce控制台上创建DataScience集群,且打开了挂载公网开关,详情请参见创建集群。
使用限制
Master和Core实例组都需要有公网IP地址,Core实例组请在ECS控制台上绑定IP地址,详情请参见绑定和解绑弹性公网IP。
操作步骤
- 开启32211端口,详情请参见添加安全组规则。
- 登录集群的Master节点,下载deploy_alink.zip并上传至任意目录下。
本文示例是上传至
/root/deploy_alink/目录下。登录集群详情,请参见
登录集群。
- 执行以下命令,安装PyAlink。
pip3 install pyalink -i https://pypi.tuna.tsinghua.edu.cn/simple
- 解压缩ZIP文件。
- 执行以下命令,进入ZIP文件上传的目录。
- 执行以下命令,解压缩上传的ZIP文件。
- 执行以下命令,启动服务。
sh start-flink.sh
该步骤会创建一个
TaskManager
的
Flink
集群。您可以手动增加
TaskManager
节点。例如,本文示例增加
TaskManager
节点为
3
个。
kubectl scale deployment flink-taskmanager --replicas 3
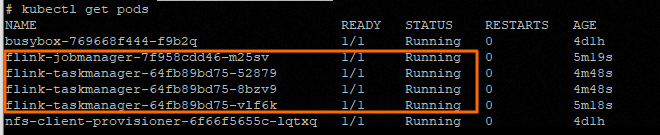
- 执行以下命,检查服务状态。
kubectl get pods
当
STATUS显示为
Running时,表示服务已成功启动。
- 编写PyAlink脚本并运行。
以下是一个KMeans算法的示例。代码示例中的32211是默认端口号,如果您没有在jobmanager-service.yml文件中修改该端口,则使用默认端口号。
- 编写脚本文件demo.py。
from pyalink.alink import *
import pandas as pd
# useRemoteEnv参数为:Flink集群地址、端口和并发度。
useRemoteEnv("localhost",32211,1)
df = pd.DataFrame([
[0, "0 0 0"],
[1, "0.1,0.1,0.1"],
[2, "0.2,0.2,0.2"],
[3, "9 9 9"],
[4, "9.1 9.1 9.1"],
[5, "9.2 9.2 9.2"]
])
data = BatchOperator.fromDataframe(df, schemaStr='id int, vec string')
kmeans = KMeansTrainBatchOp()\
.setVectorCol("vec")\
.setK(2)\
.linkFrom(data)
predictBatch = KMeansPredictBatchOp()\
.setPredictionCol("pred")\
.linkFrom(kmeans, data)
predictBatch.print()
- 执行以下命令,运行脚本文件。
python3 demo.py
返回以下信息。
JVM listening on 127.0.0.1:36576
id vec pred
0 0 0 0 0 0 1
1 0 1 0.1,0.1,0.1 1
2 0 2 0.2,0.2,0.2 1
3 0 3 9 9 9 0
4 0 4 9.1 9.1 9.1 0
5 0 5 9.2 9.2 9.2 0
- 在浏览器中输入
<公网IP地址>:32211。即可查看Flink集群状态。<公网IP地址>可以在集群基础信息页面的主机信息区域获取。
- 执行以下命令,停止服务。
