
本文介绍如何通过整合阿里云Milvus、阿里云DashScope Embedding模型与阿里云PAI(EAS)模型服务,构建一个由LLM(大型语言模型)驱动的问题解答应用,并着重演示了如何搭建基于这些技术的RAG对话系统。
前提条件
已创建Milvus实例。具体操作,请参见快速创建Milvus实例。
已开通PAI(EAS)并创建了默认工作空间。具体操作,请参见开通PAI并创建默认工作空间。
已开通服务并获得API-KEY。具体操作,请参见开通DashScope并创建API-KEY。
使用限制
Milvus实例和PAI(EAS)须在相同地域下。
请确保您的运行环境中已安装Python 3.8或以上版本,以便顺利安装并使用DashScope。
方案架构
该方案架构如下图所示,主要包含以下几个处理过程:
知识库预处理:您可以借助LangChain SDK对文本进行分割,作为Embedding模型的输入数据。
知识库存储:选定的Embedding模型(DashScope)负责将输入文本转换为向量,并将这些向量存入阿里云Milvus的向量数据库中。
向量相似性检索:Embedding模型处理用户的查询输入,并将其向量化。随后,利用阿里云Milvus的索引功能来识别出相应的Retrieved文档集。
RAG(Retrieval-Augmented Generation)对话验证:您使用LangChain SDK,并将相似性检索的结果作为上下文,将问题导入到LLM模型(本例中用的是阿里云PAI EAS),以产生最终的回答。此外,结果可以通过将问题直接查询LLM模型得到的答案进行核实。
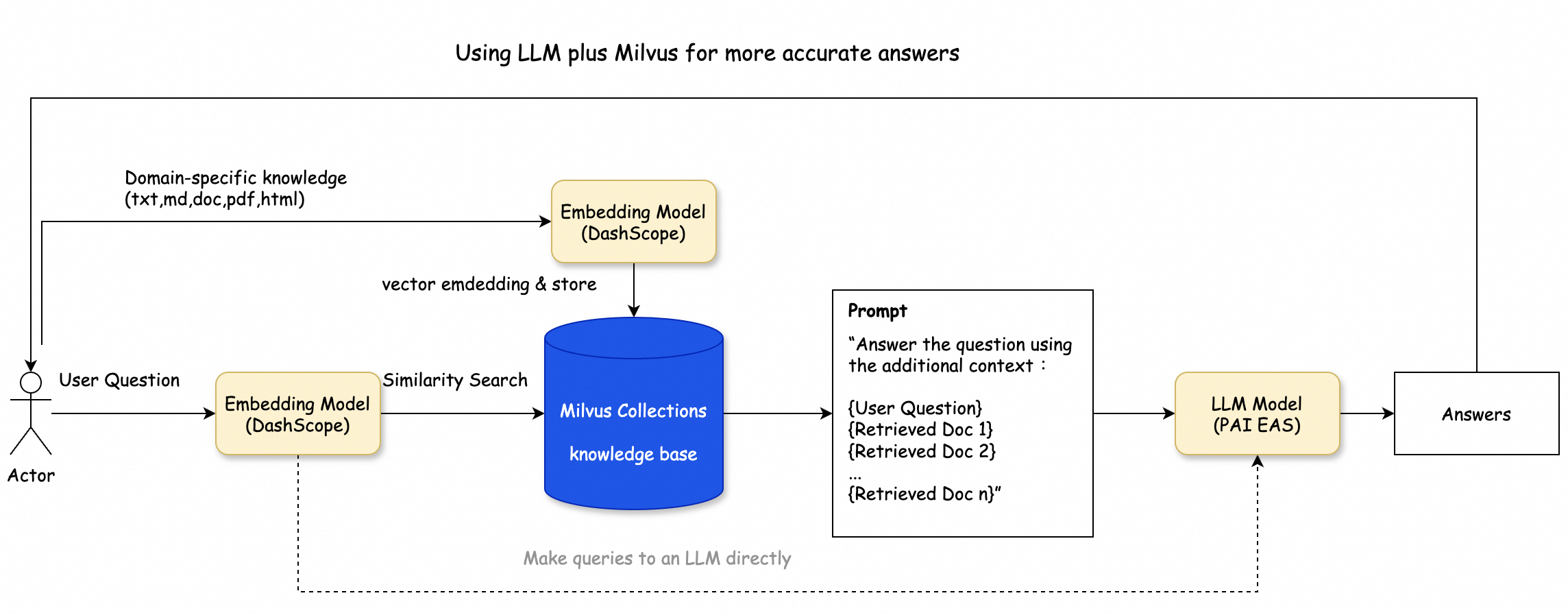
操作流程
步骤一:部署对话模型推理服务
进入模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入模型在线服务(EAS)页面。

在PAI-EAS模型在线服务页面,单击部署服务。
在部署服务页面,选择大模型RAG对话系统。
在部署大模型RAG对话系统页面,配置以下关键参数,其余参数可使用默认配置,更多参数详情请参见大模型RAG对话系统。
参数
描述
基本信息
服务名称
您可以自定义。
模型来源
使用默认的开源公共模型。
资源配置
模型类别
通常选择通义千问7B。例如,Qwen1.5-7b。
资源配置选择
按需选择GPU资源配置。例如,ml.gu7i.c16m30.1-gu30。
向量检索库设置
版本类型
选择Milvus。
数据库文件夹名称
您在Milvus中自定义的Collection名称。
访问地址
Milvus实例的内网地址。您可以在Milvus实例的实例详情页面查看。
代理端口
Milvus实例的Proxy Port。您可以在Milvus实例的实例详情页面查看。
账号
配置为root。
密码
配置为创建Milvus实例时,您自定义的root用户的密码。
Collection删除
是否删除已存在的Collection。取值如下:
True:删除同名的Collection,再创建新的Collection。如果不存在同名Collection,则直接进行创建。
False:保留现有的同名Collection,新加入的数据将追加到该Collection中。
专有网络配置
VPC
创建Milvus实例选择时的VPC、交换机和安全组。您可以在Milvus实例的实例详情页面查看。
交换机
安全组名称
单击部署。
当服务状态变为运行中时,表示服务部署成功。
获取VPC地址调用的服务访问地址和Token。
单击服务名称,进入服务详情页面。
在基本信息区域,单击查看调用信息。
在调用信息对话框的VPC地址调用页签,获取服务访问地址和Token,并保存到本地。
步骤二:创建并执行Python文件
(可选)在ECS控制台创建并启动一个开通公网的ECS实例,用于运行Python文件,详情请参见通过控制台使用ECS实例(快捷版)。
您也可以在本地机器执行Python文件,具体请根据您的实际情况做出合适的选择。
执行以下命令,安装相关依赖库。
pip3 install pymilvus langchain dashscope beautifulsoup4执行以下命令,创建
milvusr-llm.py文件。vim milvusr-llm.pymilvusr-llm.py文件内容如下所示。from langchain_community.document_loaders import WebBaseLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores.milvus import Milvus from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.llms.pai_eas_endpoint import PaiEasEndpoint # 设置Milvus Collection名称。 COLLECTION_NAME = 'doc_qa_db' # 设置向量维度。 DIMENSION = 768 loader = WebBaseLoader([ 'https://milvus.io/docs/overview.md', 'https://milvus.io/docs/release_notes.md', 'https://milvus.io/docs/architecture_overview.md', 'https://milvus.io/docs/four_layers.md', 'https://milvus.io/docs/main_components.md', 'https://milvus.io/docs/data_processing.md', 'https://milvus.io/docs/bitset.md', 'https://milvus.io/docs/boolean.md', 'https://milvus.io/docs/consistency.md', 'https://milvus.io/docs/coordinator_ha.md', 'https://milvus.io/docs/replica.md', 'https://milvus.io/docs/knowhere.md', 'https://milvus.io/docs/schema.md', 'https://milvus.io/docs/dynamic_schema.md', 'https://milvus.io/docs/json_data_type.md', 'https://milvus.io/docs/metric.md', 'https://milvus.io/docs/partition_key.md', 'https://milvus.io/docs/multi_tenancy.md', 'https://milvus.io/docs/timestamp.md', 'https://milvus.io/docs/users_and_roles.md', 'https://milvus.io/docs/index.md', 'https://milvus.io/docs/disk_index.md', 'https://milvus.io/docs/scalar_index.md', 'https://milvus.io/docs/performance_faq.md', 'https://milvus.io/docs/product_faq.md', 'https://milvus.io/docs/operational_faq.md', 'https://milvus.io/docs/troubleshooting.md', ]) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=0) # 使用LangChain将输入文档安照chunk_size切分 all_splits = text_splitter.split_documents(docs) # 设置embedding模型为DashScope(可以替换成自己模型)。 embeddings = DashScopeEmbeddings( model="text-xxxx", dashscope_api_key="your_api_key" ) # 创建connection,host为阿里云Milvus的访问域名。 connection_args = {"host": "c-xxxx.milvus.aliyuncs.com", "port": "19530", "user": "your_user", "password": "your_password"} # 创建Collection vector_store = Milvus( embedding_function=embeddings, connection_args=connection_args, collection_name=COLLECTION_NAME, drop_old=True, ).from_documents( all_splits, embedding=embeddings, collection_name=COLLECTION_NAME, connection_args=connection_args, ) # 利用Milvus向量数据库进行相似性检索。 query = "What are the main components of Milvus?" docs = vector_store.similarity_search(query) print(len(docs)) # 声明LLM 模型为PAI EAS(可以替换成自己模型)。 llm = PaiEasEndpoint( eas_service_url="your_pai_eas_url", eas_service_token="your_token", ) # 将上述相似性检索的结果作为retriever,提出问题输入到LLM之后,获取检索增强之后的回答。 retriever = vector_store.as_retriever() template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" rag_prompt = PromptTemplate.from_template(template) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | llm ) print(rag_chain.invoke("Explain IVF_FLAT in Milvus."))以下参数请根据实际环境替换。
参数
说明
COLLECTION_NAME
设置Milvus Collection名称,您可以自定义。
model
模型服务灵积的模型名称。您可以在模型服务灵积控制台的总览页面查看。
本文示例使用的设置Embedding模型为DashScope,您也可以替换成您实际使用的模型。
dashscope_api_key
模型服务灵积的密钥。您可以在模型服务灵积控制台的API-KEY管理页面查看。
connection_args
"host":Milvus实例的公网地址。您可以在Milvus实例的实例详情页面查看。"port":Milvus实例的Proxy Port。您可以在Milvus实例的实例详情页面查看。"user":配置为创建Milvus实例时,您自定义的用户名。"password":配置为创建Milvus实例时,您自定义用户的密码。
eas_service_url
配置为步骤1中获取的服务访问地址。本文示例声明LLM模型为PAI(EAS),您也可以替换成您实际使用的模型。
eas_service_token
配置为步骤1中获取的服务Token。
执行以下命令运行文件。
python3 milvusr-llm.py返回如下类似信息。
4 IVF_FLAT is a type of index in Milvus that divides vector data into nlist cluster units and compares distances between the target input vector and the center of each cluster. It uses a smaller number of clusters than IVF_FLAT, which means it may have slightly higher query time but also requires less memory. The encoded data stored in each unit is consistent with the original data.
相关文档
更多关于Milvus的介绍,请参见什么是EMR Serverless Milvus。
更多关于EAS的介绍,请参见EAS模型服务概述。
更多关于Embedding和LLM模型的介绍,请参见LangChain官方网站。