
在分析社交媒体、论坛或在线交流中的文本时,可能会遇到含糊不清、无逻辑性或乱码的文本,导致数据分析的准确性降低,进而影响到数据驱动决策的质量。本文介绍如何在Elasticsearch(简称ES)中通过一个NLP模型识别和过滤出乱码的文本。
准备工作
上传模型
本文选择huggingface仓库中的text_classification模型madhurjindal/autonlp-Gibberish-Detector-492513457。
由于中国内地网络访问huggingface较慢,本文采用离线上传模型的方式。
下载模型,请单击madhurjindal--autonlp-gibberish-detector-492513457.tar.gz。
将模型上传到ECS中。
在ECS的根目录下新建一个文件夹,例如model,将模型上传到该文件夹中,请不要将模型上传到/root/目录下。
由于模型比较大,建议通过WinSCP的方式上传,请参见在本地Windows使用WinSCP向Linux实例传输文件。
在ECS中执行如下命令,在模型文件目录下解压该模型。
cd /model/ tar -xzvf madhurjindal--autonlp-gibberish-detector-492513457.tar.gz cd在ECS中执行如下命令,将模型上传到ES中。
eland_import_hub_model --url 'http://es-cn-lbj3l7erv0009****.elasticsearch.aliyuncs.com:9200' \ --hub-model-id '/model/root/.cache/huggingface/hub/models--madhurjindal--autonlp-Gibberish-Detector-492513457/snapshots/c068f552cdee957e45d8773db9f7158d43902244' --task-type text_classification --es-username elastic --es-password **** --es-model-id models--madhurjindal--autonlp-gibberish-detector \
部署模型
登录Kibana。具体操作,请参见登录Kibana控制台。
单击Kibana页面左上角的
 图标,选择Analytics > Machine Learning。
图标,选择Analytics > Machine Learning。在左侧菜单栏,单击模型管理(Model Management) > 已训练模型(Trained Models)。
(可选)在页面上方,单击同步作业和已训练模型(Synchronize your jobs and trained models),在弹出的面板中单击同步(Synchronize)。
将鼠标移动到目标模型操作(Actions)列的前面,单击
 图标,启动模型。
图标,启动模型。
在弹出的对话框中,配置模型后,单击启动(Start)。
页面右下角弹出已成功启动的提示对话框,表明模型部署成功。
说明模型无法启动可能是集群内存不足,升配集群后再试。无法启动的具体原因,请在提示对话框中单击请参阅完整的错误信息查看。
测试模型
在已训练模型页面,在已部署模型的操作列,选择
 > 测试模型(Test model)。
> 测试模型(Test model)。
在弹出的面板中,测试已训练模型,查看输出结果是否符合预期。
输出结果说明:
word salad:描述语言沟通中混乱或无法理解的术语和乱码。用于检测乱码,得分越高表明是乱码的概率越大。
以下测试示例中word salad得分最高,证明测试文本大概率是乱码。
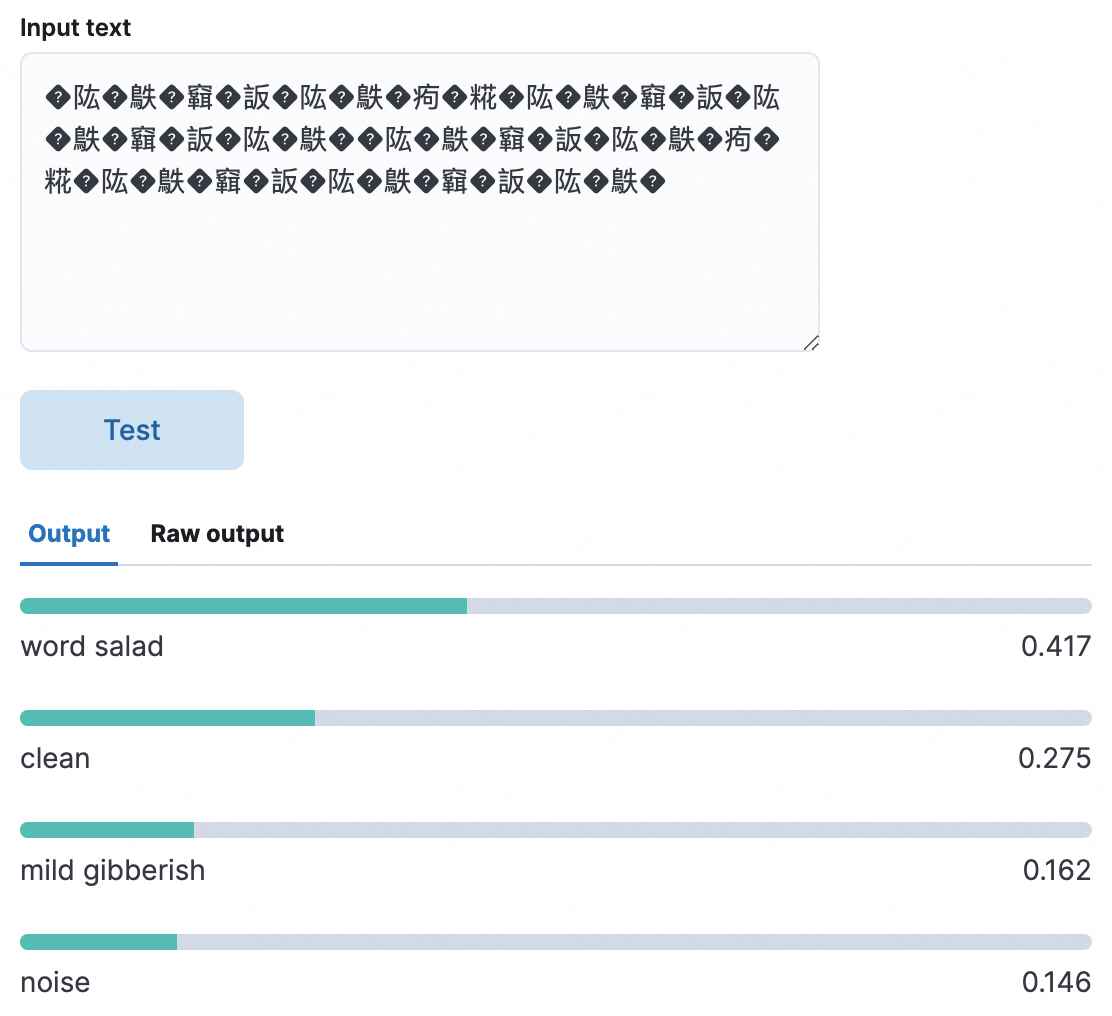
clean:正常文本。
mild gibberish:疑似胡言乱语。
noise:胡言乱语。
以下测试示例中noise得分最高,证明输入的文本大概率是胡言乱语。
通过Kibana Dev Tools实现乱码文本识别
单击Kibana页面左上角的
图标,选择Management > 开发工具(Dev Tools)。依次执行以下代码。
1.创建索引 PUT /gibberish_index { "mappings": { "properties": { "text_field": { "type": "text" } } } } 2.添加数据 POST /gibberish_index/_doc/1 { "text_field": "how are you" } POST /gibberish_index/_doc/2 { "text_field": "sdfgsdfg wertwert" } POST /gibberish_index/_doc/3 { "text_field": "I am not sure this makes sense" } POST /gibberish_index/_doc/4 { "text_field": "�䧀�䳀�䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�䳀�" } POST /gibberish_index/_doc/5 { "text_field": "测试" } POST /gibberish_index/_doc/6 { "text_field": "䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�" } 3.创建摄取(ingest)管道 inference处理器字段: model_id——用于推理的机器学习模型 target_field——推理的结果将存储在文档的这个字段中 field_map.text_field——用于将文档的输入字段映射到模型预期的字段 PUT /_ingest/pipeline/gibberish_detection_pipeline { "description": "A pipeline to detect gibberish text", "processors": [ { "inference": { "model_id": "models--madhurjindal--autonlp-gibberish-detector", "target_field": "inference_results", "field_map": { "text_field": "text_field" } } } ] } 4.使用管道更新索引中的文档 POST /gibberish_index/_update_by_query?pipeline=gibberish_detection_pipeline 5.搜索具有推理结果的文档 GET /gibberish_index/_search { "query": { "exists": { "field": "inference_results" } } } 6.精确查询 inference_results.predicted_value.keyword 字段的值匹配字符串 "word salad" inference_results.prediction_probability 字段的值大于等于0.1 GET /gibberish_index/_search { "query": { "bool": { "must": [ { "match": { "inference_results.predicted_value.keyword": "word salad" } }, { "range": { "inference_results.prediction_probability": { "gte": 0.1 } } } ] } } }精确查询得到以下两条数据。这两条数据的word salad得分都是最高,大概率属于乱码。
{ "took": 6, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 2.0296195, "hits": [ { "_index": "gibberish_index", "_id": "4", "_score": 2.0296195, "_source": { "text_field": "�䧀�䳀�䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�䳀�", "inference_results": { "predicted_value": "word salad", "prediction_probability": 0.37115721979929084, "model_id": "models--madhurjindal--autonlp-gibberish-detector" } } }, { "_index": "gibberish_index", "_id": "6", "_score": 2.0296195, "_source": { "text_field": "䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�", "inference_results": { "predicted_value": "word salad", "prediction_probability": 0.3489011155424212, "model_id": "models--madhurjindal--autonlp-gibberish-detector" } } } ] } }
通过Python实现乱码文本识别
您也可以通过Python实现乱码文本识别。在ECS中执行Python3加载Python环境后,执行以下命令。
from elasticsearch import Elasticsearch
es_username = 'elastic'
es_password = '****'
# 使用 basic_auth 参数创建 Elasticsearch 客户端实例
es = Elasticsearch(
"http://es-cn-lbj3l7erv0009****.elasticsearch.aliyuncs.com:9200",
basic_auth=(es_username, es_password)
)
# 创建索引和映射
create_index_body = {
"mappings": {
"properties": {
"text_field": { "type": "text" }
}
}
}
es.indices.create(index='gibberish_index2', body=create_index_body)
# 插入文档
docs = [
{"text_field": "how are you"},
{"text_field": "sdfgsdfg wertwert"},
{"text_field": "I am not sure this makes sense"},
{"text_field": "�䧀�䳀�䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�䳀�"},
{"text_field": "测试"},
{"text_field": "䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�"}
]
for i, doc in enumerate(docs):
es.index(index='gibberish_index2', id=i+1, body=doc)
# 创建处理器和管道
pipeline_body = {
"description": "A pipeline to detect gibberish text",
"processors": [
{
"inference": {
"model_id": "models--madhurjindal--autonlp-gibberish-detector",
"target_field": "inference_results",
"field_map": {
"text_field": "text_field"
}
}
}
]
}
es.ingest.put_pipeline(id='gibberish_detection_pipeline2', body=pipeline_body)
# 使用管道更新现有文档
es.update_by_query(index='gibberish_index2', body={}, pipeline='gibberish_detection_pipeline2')
# 搜索具有推理结果的文档
search_body = {
"query": {
"exists": {
"field": "inference_results"
}
}
}
response = es.search(index='gibberish_index2', body=search_body)
print(response)
# 精确查询
# 1.inference_results.predicted_value.keyword字段的值匹配字符串 "word salad"
# 2.inference_results.prediction_probability 字段的值大于等于0.1
search_query = {
"query": {
"bool": {
"must": [
{
"match": {
"inference_results.predicted_value.keyword": "word salad"
}
},
{
"range": {
"inference_results.prediction_probability": {
"gte": 0.1
}
}
}
]
}
}
}
response = es.search(index='gibberish_index2', body=search_query)
print(response)精确查询得到以下两条数据。这两条数据的word salad得分都是最高,大概率属于乱码。
{
'took': 3,
'timed_out': False,
'_shards': {
'total': 1,
'successful': 1,
'skipped': 0,
'failed': 0
},
'hits': {
'total': {
'value': 2,
'relation': 'eq'
},
'max_score': 2.0296195,
'hits': [{
'_index': 'gibberish_index2',
'_id': '4',
'_score': 2.0296195,
'_source': {
'text_field': '�䧀�䳀�䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�䳀�',
'inference_results': {
'predicted_value': 'word salad',
'prediction_probability': 0.37115721979929084,
'model_id': 'models--madhurjindal--autonlp-gibberish-detector'
}
}
}, {
'_index': 'gibberish_index2',
'_id': '6',
'_score': 2.0296195,
'_source': {
'text_field': '䇀�䛀�䧀�䳀�痀�糀�䧀�䳀�䇀�䛀�䧀�䳀�䇀�䛀�䧀�',
'inference_results': {
'predicted_value': 'word salad',
'prediction_probability': 0.3489011155424212,
'model_id': 'models--madhurjindal--autonlp-gibberish-detector'
}
}
}]
}
}