
通过使用阿里云Elasticsearch 7.10内核增强版Indexing Service系列,可以为您实现云托管写入加速和按流量付费(即您无需按集群峰值写入吞吐预留资源),能够极低成本实现海量时序日志分析。本文为您介绍如何基于Indexing Service系列实现数据流管理以及日志场景分析。
背景信息
在复杂业务场景下,海量服务器、物理机、Docker容器、移动设备和IoT传感器等设备中往往存在着结构分散、种类多样且规模庞大的各类指标和日志数据,而除了底层系统的各类指标和日志数据外,往往还存在着规模庞大的业务数据,例如用户行为、行车轨迹等。当面对海量时序数据和日志数据写入出现性能瓶颈时,您可以根据业务需求选择使用阿里云Elasticsearch 7.10内核增强版Indexing Service系列,此功能基于读写分离架构以及写入按量付费的Serverless模式,实现了Elasticsearch集群的云端写入托管和降本提效的目标。
在阿里云Elasticsearch 7.10内核增强版Indexing Service系列中,推荐使用数据流管理,可以帮您实现跨多索引存储仅追加时间序列数据,为请求提供唯一的命名资源;并且您可以根据关联的索引模板和Rollover策略实现自动取消托管,从而达到云端托管数据的自动清理和成本优化。数据流管理非常适用于日志、事件、指标和其他连续生成数据的场景。除此之外,您还可以通过使用索引生命周期管理(ILM)定期管理后备索引,帮助您降低成本及开销。
Elasticsearch集群中既可以存在数据流(Data Stream),也可以存在独立索引(Index)对象。除系统索引不托管外,其他索引均默认开启云端托管功能。独立索引支持增、删、改、查操作,操作前需要您手动取消云端托管。为了帮助您更好的使用数据流管理云端托管索引,阿里云Elasticsearch控制台分别提供了数据流管理、索引管理和创建索引模板功能模块,通过白屏化的方式为您实现数据流一站式管理。
使用场景
本文通过将采集到的nginx服务日志数据,写入到阿里云Elasticsearch 7.10内核增强版Indexing Service系列实例中,通过数据流管理和索引生命周期管理,实现日志数据的分析和检索。
注意事项
因为数据流写入依赖时间字段@timestamp,所以请确保写入数据中存在@timestamp字段的数据,否则数据流写入过程中会报错。如果源数据中没有@timestamp字段数据,您可以使用ingest pipeline指定_ingest.timestamp,获取元数据值,从而引入@timestamp字段数据。
Indexing Service提供了写入Serverless保护机制,因此使用前请参见使用限制,提前优化配置,以避免使用过程中出现不合规的情况。
Indexing Service内核增强版实例与用户集群进行数据同步时,依赖于apack/cube/metadata/sync任务(可通过
GET _cat/tasks?v命令获取该任务信息),不建议手动清理该任务。如果被清理,请尽快使用POST /_cube/meta/sync命令恢复,否则会影响业务写入。
操作流程
创建一个阿里云Elasticsearch 7.10内核增强版Indexing Service系列的实例。
在使用数据流之前,需要创建索引模板,通过模板对数据流后备索引进行结构配置。
创建数据流并写入数据。
对数据流或者独立索引进行云端托管管理。
在节点可视化页面,查看集群当天写入的总流量以及写入托管总数量。
在Kibana控制台中,查看基于Indexing Service实现的数据流管理的实时日志流和实时数据指标。
步骤一:创建Indexing Service实例
购买内核增强版7.10版本,并开通高级增强特性Indexing Service索引构建服务。操作步骤,请参见创建阿里云Elasticsearch实例。
开通Indexing Service索引构建服务后,写入Serverless模块将按实际写入流量及托管存储空间进行按量计费,详情请参见阿里云ES计费。
步骤二:创建索引模板
如果您的业务存在频繁的Put Mapping操作,为避免消耗大量计算资源,对托管服务稳定性造成影响,建议您写数据前提前定义索引模板,降低Put Mapping操作对集群稳定性影响。
- 登录阿里云Elasticsearch控制台。
- 进入目标实例。
- 在顶部菜单栏处,选择资源组和地域。
- 在Elasticsearch实例中单击目标实例ID。
在左侧导航栏,选择。
单击索引模板管理页签。
单击创建索引模板。
可选:在创建索引模板面板,参考下图配置索引生命周期策略。
说明如果您无需对数据流后备索引进行生命周期策略管理,单击跳过此步即可。
部分参数说明如下。未提及参数请参考页面上的具体说明。
参数
示例值
说明
索引生命周期策略
新建索引生命周期策略
新建索引生命周期策略:创建新的索引生命周期策略。
说明Indexing Service架构下,不支持在索引生命周期中自定义freeze。
选择已有索引生命周期策略:集群中存在服务业务逻辑策略,点击下拉框选择即可。
策略名称
nginx_policy
新建索引生命周期策略时,需要自定义输入;选择已有索引生命周期策略时,需要在下拉列表中选择集群中已存在的生命周期策略。
取消托管时间
3天
默认3天取消托管,请根据具体业务场景评估取消托管时间。
删除时间
7天
设置索引保留多少天后会被自动删除。
本步骤使用的命令示例如下。
{ "policy": { "phases": { "hot": { "min_age": "0s", "actions": { "cube_unfollow": { "max_age": "3d", "force_merge": true, "force": false, "read_only": true }, "rollover": { "max_size": "30gb", "max_age": "1d", "max_docs": 10000 }, "set_priority": { "priority": 1000 } } }, "delete": { "min_age": "7d", "actions": { "delete": { "delete_searchable_snapshot": true } } } } } }以上新建的索引生命周期策略表示,当托管索引满足以下任意条件时,将触发滚动更新,生成新的后备索引,原索引保留7天后将自动删除:
写入文件数超过1000000。
索引大小达到30 GB。
索引从创建开始满1天。
单击保存并下一步,配置索引模板信息。
参数
示例值
说明
模板名称
nginx_telplate
定义的模板名称。
索引模式
nginx-*
定义索引模式,使用通配符(*)表达式匹配数据流及索引名称,不允许使用空格和字符
\/?"<>|。创建数据流
开启
开启数据流模式。如果未开启,索引模式无法生成数据流。详细信息,请参见Data stream。
优先级
100
定义模板优先级,数值越大,优先级越高。
索引生命周期策略
nginx_policy
只能引用一个索引生命周期策略。
内容模板配置
Settings配置如下:
{ "index.number_of_replicas": "1", "index.number_of_shards": "6", "index.refresh_interval": "5s" }配置索引Settings、Mappings、Aliases和组合内容模板。
重要写入到数据流中的每个文档都要求包含一个@timestamp字段,建议在索引模板中为@timestamp字段指定映射。如果不指定,该字段会映射为Elasticsearch中的date或者date_nanos类型的字段。
配置格式严格按照Elastic官方配置。
本步骤使用的命令示例值如下:
PUT /_index_template/nginx_telplate { "index_patterns": [ "nginx-*" ], "data_stream": { }, "template": { "settings": { "index.number_of_replicas": "1", "index.number_of_shards": "6", "index.refresh_interval": "5s", "index.lifecycle.name": "nginx_policy", "index.apack.cube.following_index": true } }, "priority": 100 }重要通过命令创建模板时,务必将index.apack.cube.following_index设置为true。
云端托管集群上index.refresh_interval参数已默认配置最优,手动配置不生效。如果需要通过手动配置index.refresh_interval生效,需要先取消云托管功能。
单击确认,索引模板列表中会显示您创建的模板。
步骤三:创建数据流
在索引管理中心页面,单击数据流管理页签。
单击创建数据流。
在创建数据流面板,单击预览已有索引模板,根据对应的索引模板,输入可匹配索引模板的数据流名称。
本步骤使用的命令示例值如下。
PUT /_data_stream/nginx-log重要创建数据流之前必须存在数据流可匹配的索引模板,该模板包含用于配置数据流的后备索引映射及设置。
数据流名称支持以短划线(-)结尾,不支持通配符星号(*)。
单击确定,系统会自动生成数据流及后备索引。
每个数据流创建成功后,都会自动生成一个统一格式的后备索引,格式如下。
.ds-<data-stream>-<yyyy.MM.dd>-<generation>参数
说明
.ds
隐藏索引名统一标识,数据流生成的后备索引名,默认均以.ds开头。
<data-stream>
数据流名称。
<yyyy.MM.dd>
后备索引创建日期。
<generation>
每个数据流都会生成一个六位数,默认从000001开始的累积整数值,generation值更大的后备索引包含更多新数据。
写入数据,具体操作请参见最佳实践。
数据写入过程中,必须带@timestamp字段,否则写入失败。本场景采用filebeat+kafka+logstash架构将日志采集写入到Elasticsearch实例中,采集过程中会自动生成@timestamp字段。命令示例如下。
POST /nginx-log/_doc/ { "@timestamp": "2099-03-07T11:04:05.000Z", "user": { "id": "vlb44hny" }, "message": "Login attempt failed" }
步骤四:管理托管索引
在索引管理中心页面,单击索引管理页签,查看处于云托管状态的索引。

参数
说明
仅查看托管中的索引
系统默认展示集群中的所有索引(不包括系统索引),选择仅查看托管中的索引后,系统仅展示托管中的索引,帮助您快速获取处于托管的数据。
云端托管索引总大小
当前时刻,正处于云端写入托管中的索引总大小。
重要云端托管索引总大小为实时变化数值,不是历史索引总大小。
索引个数
当前时刻,正处于云端写入托管中的索引总个数。 该数值为当前系统中的实时数值。
重要索引个数为实时变化数值,不是历史索引总个数。
写入托管状态
开启:该索引的云端写入托管处于开启状态。默认开启。
关闭:取消该索引的云端写入托管。支持手动关闭,关闭后不支持开启。
说明手动关闭某一索引的云端写入托管,数据将直接写入用户集群中。请在关闭前确认该索引是否持续有数据写入,以及用户集群负载情况,否则可能出现用户集群负载较高风险。
Indexing Service按照写入托管索引总大小和写入流量进行按量计费,业务上建议使用数据流(Data Stream)和索引生命周期管理(ILM)滚动策略实现云端托管空间最优化。
Indexing Service场景,索引处于托管状态,不兼容ILM Action中的shrink操作,建议当索引处于未托管状态时,执行shrink配置。详细信息,请参见ILM-shrink。
在独立索引的云端写入托管过程中,索引数据会全量存储在云托管服务Indexing Service中,将会增加云托管费用。请根据业务使用场景(如索引是否仍有数据写入)评估是否需要手动关闭该索引的写入托管。
说明由于数据流nginx-log配置了索引滚动策略,所以在云托管服务上,每次仅保存最新生成的后备索引(本场景中的.ds-nginx-log-2021.04.26-000004),旧的后备索引会自动从云托管上关闭。
取消索引托管。
独立索引或未设置滚动策略的索引将一直在云托管服务保存,需要手动关闭。关闭后,对应索引的写入托管状态会处于关闭状态。
 重要
重要取消云托管后,无法再次开启云端Indexing Service写入托管功能。
Elasticsearch集群中既可以存在数据流(Data Stream),又可以存在独立索引(Index)对象,除系统索引不托管外,其他索引均默认开启托管功能。
您可以通过Indexing Service API获取更多Indexing Service托管集群信息。
在索引管理页签中,单击对应索引右侧写入托管状态列下的开启开关。
在取消托管弹框中,单击确认。
本步骤对应的命令示例如下。
POST /.ds-nginx-log-xxx/_cube/unfollow
步骤五:查看集群信息
进入节点可视化页面,查看写入Indexing Service实时写入流量和数据量信息。
在Indexing Service区域,单击当天写入总流量,即可查看每小时平均写入吞吐量的曲线图。
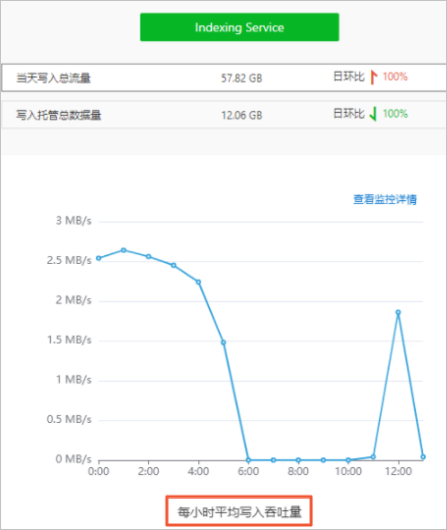 说明
说明Indexing Service写入总流量监控为非实时整点展示的静态趋势监控图,监控数据展示延时最长为1小时。例如在14:00~14:59间写入的总流量,需要等到15:10后,在监控页面的14:00处获取。
单击查看监控详情,将跳转至Grafana监控展示更详细的监控数据。
重要Grafana的登录名和密码请从高级监控报警获取。
在Indexing Service页面,单击写入托管总数据量,即可查看当天写入托管总数据量。
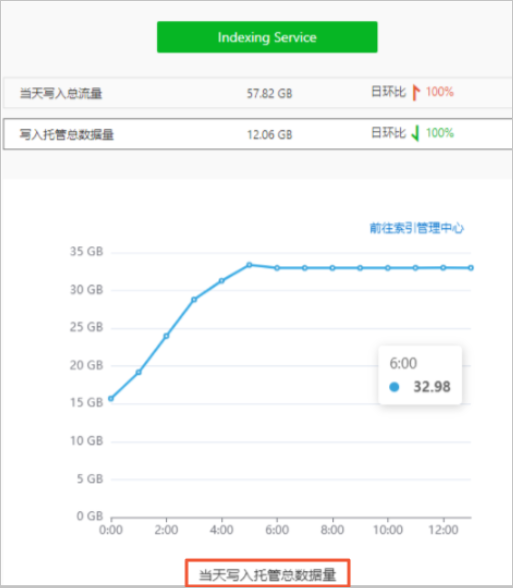 说明
说明Indexing Service写入总流量监控为非实时整点展示的静态趋势监控图,监控数据展示延时最长为1小时,例如在14:00~14:59间写入的总数据量,需要等到15:10后,在监控页面的14:00处获取。
步骤六:分析日志
- 登录目标阿里云Elasticsearch实例的Kibana控制台,根据页面提示进入Kibana主页。登录Kibana控制台的具体操作,请参见登录Kibana控制台。说明 本文以阿里云Elasticsearch 7.10.0版本为例,其他版本操作可能略有差别,请以实际界面为准。
创建索引模板。
单击左上角的
 。
。在左侧导航栏,选择。
在Stack Management页面的Kibana区域,单击Index Patterns。
单击Create index pattern。
在Create index pattern页面的Index pattern name文本框中,输入索引模板名称。
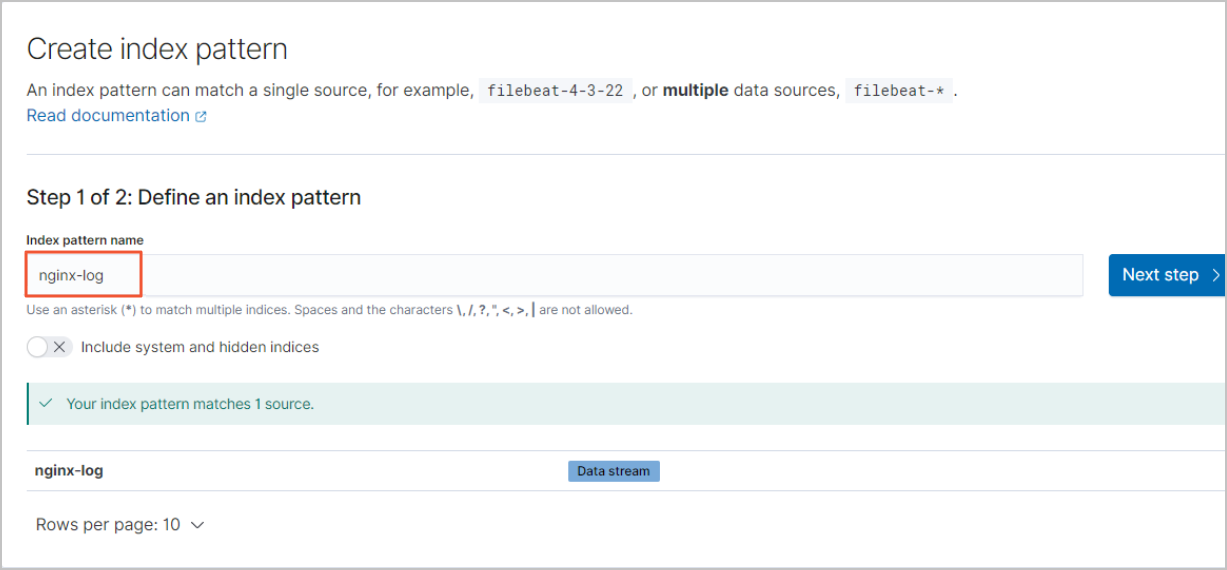 说明
说明Index pattern name不仅可以指定为数据流名称,也可以指定为后备索引名称。
设置Settings。
单击左上角
。在左侧导航栏,选择。
在Logs页面,单击Settings页签。
在Log indices文本框中,输入数据流名称。
本文以nginx-log数据流名称为例,其他字段的默认配置符合数据流数据要求,可不修改。
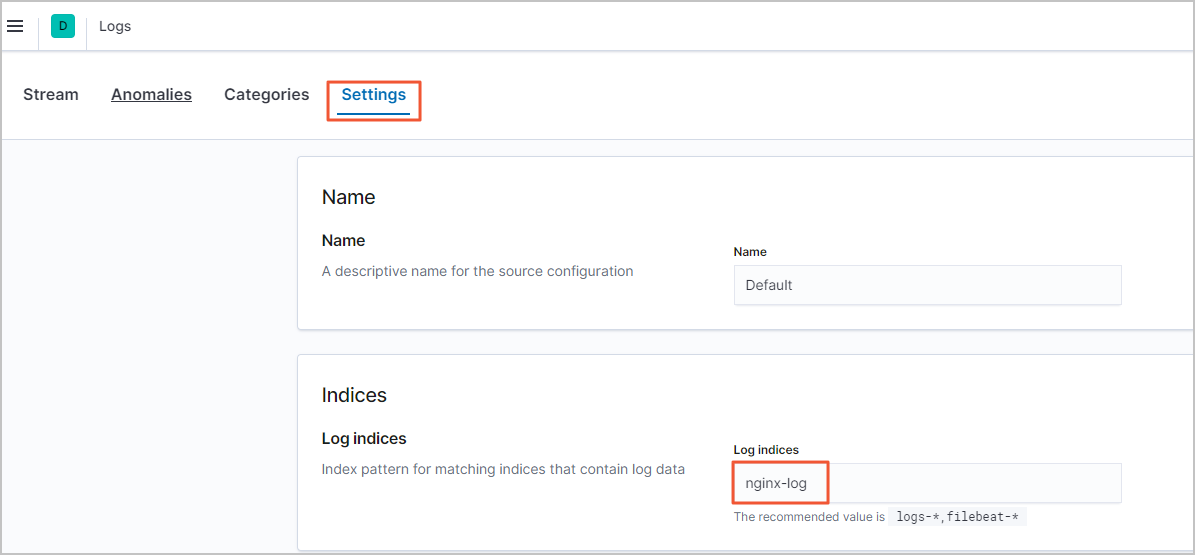
在右下角,单击Apply。
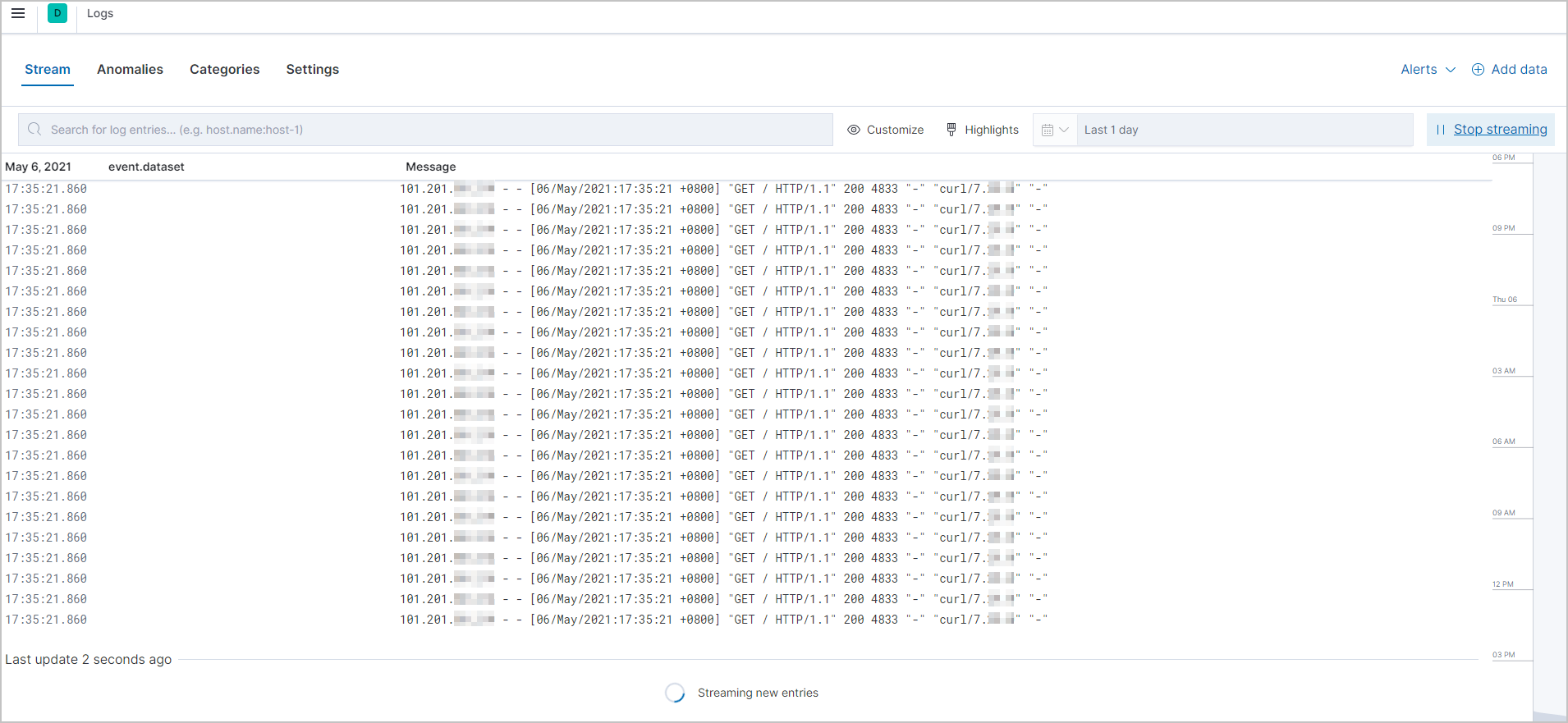
获取实时日志流数据。
在Logs页面,单击Stream页签。
在页面右侧,单击Stream live。
在Stream页签中,查看获取到的实时数据流。
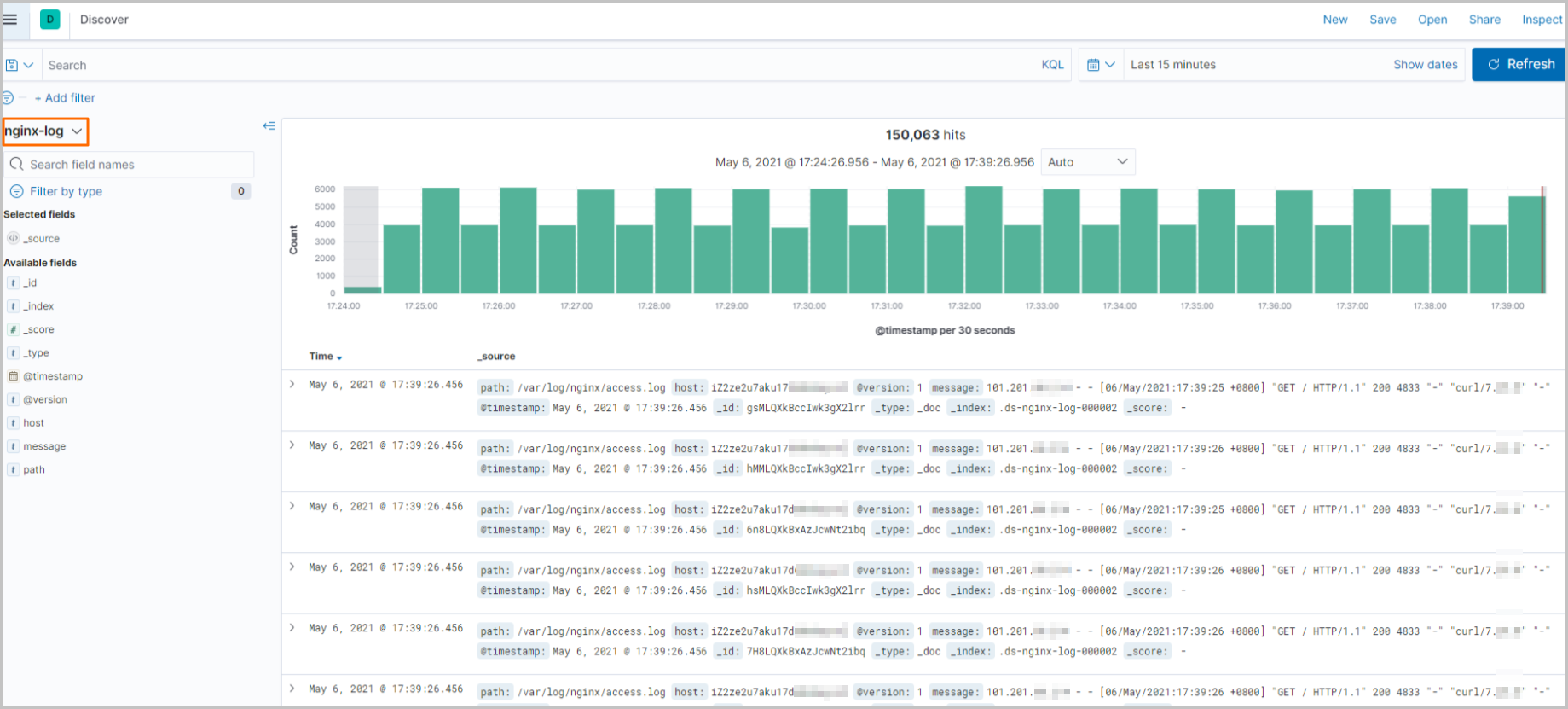
获取实时数据指标。
单击左上角
。在左侧导航栏,选择。
在Discover页面,选择对应索引,获取该索引的实时数据指标。
更多Kibana日志分析功能请参见Kibana Guide。
常见问题
Q:为Indexing Service实例中的写入托管索引配置refresh、merge等写入参数,是否会生效?
A:不会生效。Indexing Service实例中的写入托管索引已使用默认写入参数配置,用户侧配置不生效。默认写入参数配置如下。
"index.merge.policy.max_merged_segment" : "1024mb",
"index.refresh_interval" : "3s",
"index.translog.durability" : "async",
"index.translog.flush_threshold_size" : "2gb",
"index.translog.sync_interval" : "100s"