对于时序数据场景,随着时间的积累数据量会越来越大。如果一直保留详细数据,会导致存储成本线性增长,此时您可以通过Elasticsearch(简称ES)的RollUp机制节省数据存储成本。本文以汇总Logstash流量为例介绍RollUp的使用方法。
前提条件
- 确保您已拥有manage或manage_rollup权限。
使用RollUp必须要有manage或manage_rollup权限,详情请参见Security Privileges。
- 已创建阿里云ES实例。
详情请参见创建阿里云Elasticsearch实例,本文使用的实例版本为通用商业版7.4。说明 下文中的RollUp命令适用于ES 7.4版本,6.x版本的命令请参见RollUp Job。
背景信息
- 每15分钟定时汇总整小时内instanceId的networkoutTraffic、networkinTraffic流量。
- 通过Kibana大图展示指定instanceId的入口流量和出口流量。
本文以monitordata-logstash-sls-*为前缀的索引为例,该索引以每天创建一个索引的规则切分索引。索引的Mapping格式如下。
"monitordata-logstash-sls-2020-04-05" : {
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"__source__" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"disk_type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"host" : {
"type" : "keyword"
},
"instanceId" : {
"type" : "keyword"
},
"metricName" : {
"type" : "keyword"
},
"monitor_type" : {
"type" : "keyword"
},
"networkinTraffic" : {
"type" : "double"
},
"networkoutTraffic" : {
"type" : "double"
},
"node_spec" : {
"type" : "keyword"
},
"node_stats_node_master" : {
"type" : "keyword"
},
"resource_uid" : {
"type" : "keyword"
}
}
}
}
}说明 本文中的命令均可在Kibana控制台上执行,详情请参见登录Kibana控制台。
操作流程
步骤一:创建RollUp作业
RollUp作业配置包含该作业如何运行、何时索引文档及将来对汇总索引执行哪些查询的详情信息。以下示例通过
PUT _rollup/job命令定义1小时内汇总的作业。
PUT _rollup/job/ls-monitordata-sls-1h-job1
{
"index_pattern": "monitordata-logstash-sls-*",
"rollup_index": "monitordata-logstash-rollup-1h-1",
"cron": "0 */15 * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "1h"
},
"terms": {
"fields": ["instanceId"]
}
},
"metrics": [
{
"field": "networkoutTraffic",
"metrics": ["sum"]
},
{
"field": "networkinTraffic",
"metrics": ["sum"]
}
]
}| 参数 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
index_pattern |
是 | string | 汇总的索引或索引模式。支持通配符(*)。 |
rollup_index |
是 | string | 汇总结果的索引。不支持通配符,必须是一个完整的名称。 |
cron |
是 | string | 执行汇总作业任务的时间间隔。与汇总数据的时间间隔无关。 |
page_size |
是 | integer | 汇总索引每次迭代中处理的存储桶的结果数。值越大,执行越快,但是处理过程中需要更多的内存。 |
groups |
是 | object | 为汇总作业定义分组字段和聚合。 |
└ date_histogram |
是 | object | 将date字段汇总到基于时间的存储桶中。 |
└field |
是 | string | 需要汇总的date字段。 |
└fixed_interval |
是 | time units | 数据汇总的时间间隔。例如设置为1h,表示按照1小时汇总field指定的时间字段。该参数定义了数据能够聚合的最小时间间隔。 |
terms |
否 | object | 无。 |
└fields |
是 | string | 定义terms字段集。此数组字段可以是keyword也可以是numerics类型,无顺序要求。 |
metrics |
否 | object | 无。 |
└field |
是 | string | 定义需要采集的指标的字段。例如以上示例是分别对networkoutTraffic、networkinTraffic进行采集。 |
└metrics |
是 | array | 定义聚合算子。设置为sum,表示对networkinTraffic进行sum运算。仅支持min、max、sum、average、value count。 |
说明 └表示子参数。
更多参数说明请参见Create rollup jobs API。配置参数时,请注意:
index_pattern中指定通配符时,请确保不会匹配到rollup_index指定的汇总索引名,否则报错。- 由于汇总索引的Mapping是object类型,请确保集群中不存在与汇总索引相匹配的索引模板,否则报错。
- 字段分组聚合仅支持Date Histogram aggregation、Histogram aggregation、Terms aggregation,详细限制说明请参见Rollup aggregation limitations。
步骤二:启动RollUp作业并查看作业信息
步骤三:查询汇总索引的数据
在Rollup内部,由于汇总文档使用的文档结构和原始数据不同,Rollup查询端口会将标准查询DSL重写为与汇总文档匹配的格式,然后获取响应并将其重写回给原始查询的客户端所期望的格式。
- 使用match_all获取汇总索引的所有数据。
GET monitordata-logstash-rollup-1h-1/_search { "query": { "match_all": {} } }- 查询仅能指定一个汇总索引,即不支持模糊匹配。对实时索引数据查询没有限制要求,查询可指定多个索引。
- 查询仅支持Term、Terms、Range query、MatchAll query、Any compound query(Boolean、Boosting、ConstantScore等),更多限制请参见Rollup search limitations。
- 使用
_rollup_search聚合出口流量总数据。GET /monitordata-logstash-rollup-1h-1/_rollup_search { "size": 0, "aggregations": { "sum_temperature": { "sum": { "field": "networkoutTraffic" } } } }_rollup_search支持常规的Search API特性子集:- query:指定DSL查询参数,但受一些限制,详情请参见Rollup search limitations和Rollup aggregation limitations。
- aggregations:指定聚合参数。
_rollup_search不可用功能包括:- size:由于汇总适用于聚合数据,无法返回查询结果,因此将size设置为0或者完全省略。
- 不支持highlighter、suggestors、post_filter、profile、explain等参数。
步骤四:创建Rollup索引模式
- 在左侧导航栏,单击Management图标。
- 单击。
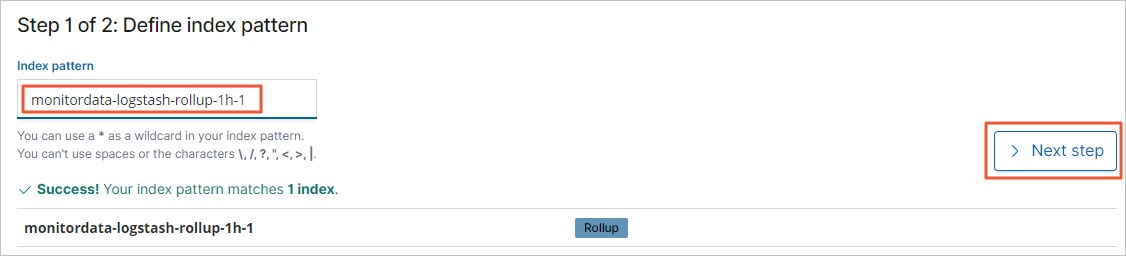
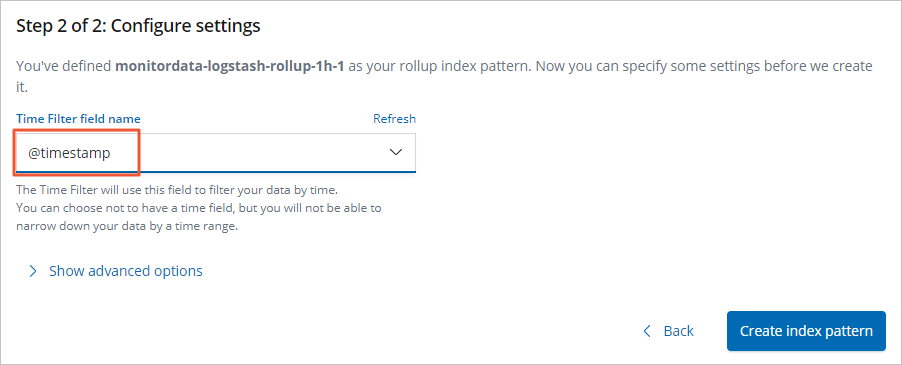
- 输入索引模式名称(monitordata-logstash-rollup-1h-1),然后单击Next step。
- 从Time Filter field name列表中,选择@timestamp。




步骤五:创建Kibana流量监控大图
在Kibana上分别配置汇总索引的入口流量及出口流量监控大图,操作步骤如下:
- 创建Line曲线图。
- 在左侧导航栏,单击Visualize图标。
- 在左侧导航栏,单击Visualize图标。
- 设置Metrics和Buckets。
- 在Metrics区域,单击
 。
。 - 设置Y-axis参数。
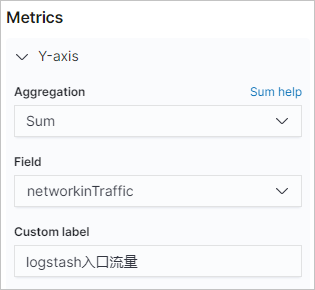
参数 说明 Aggregation 选择Sum。 Field 选择networkinTraffic或networkoutTraffic。 Custom label 自定义Y轴标签。 - 设置X-axis参数。
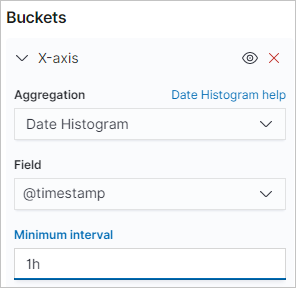
参数 说明 Aggregation 设置为步骤一:创建RollUp作业时, group中定义的date_histogram。Field 选择@timestamp。 Minimum interval 默认为RollUp作业中定义的聚合时间粒度。必须是汇总配置间隔的整数倍,例如2h、3h等。 - 单击
 图标。
图标。
- 在Metrics区域,单击
- 在顶部菜单栏,单击Save。
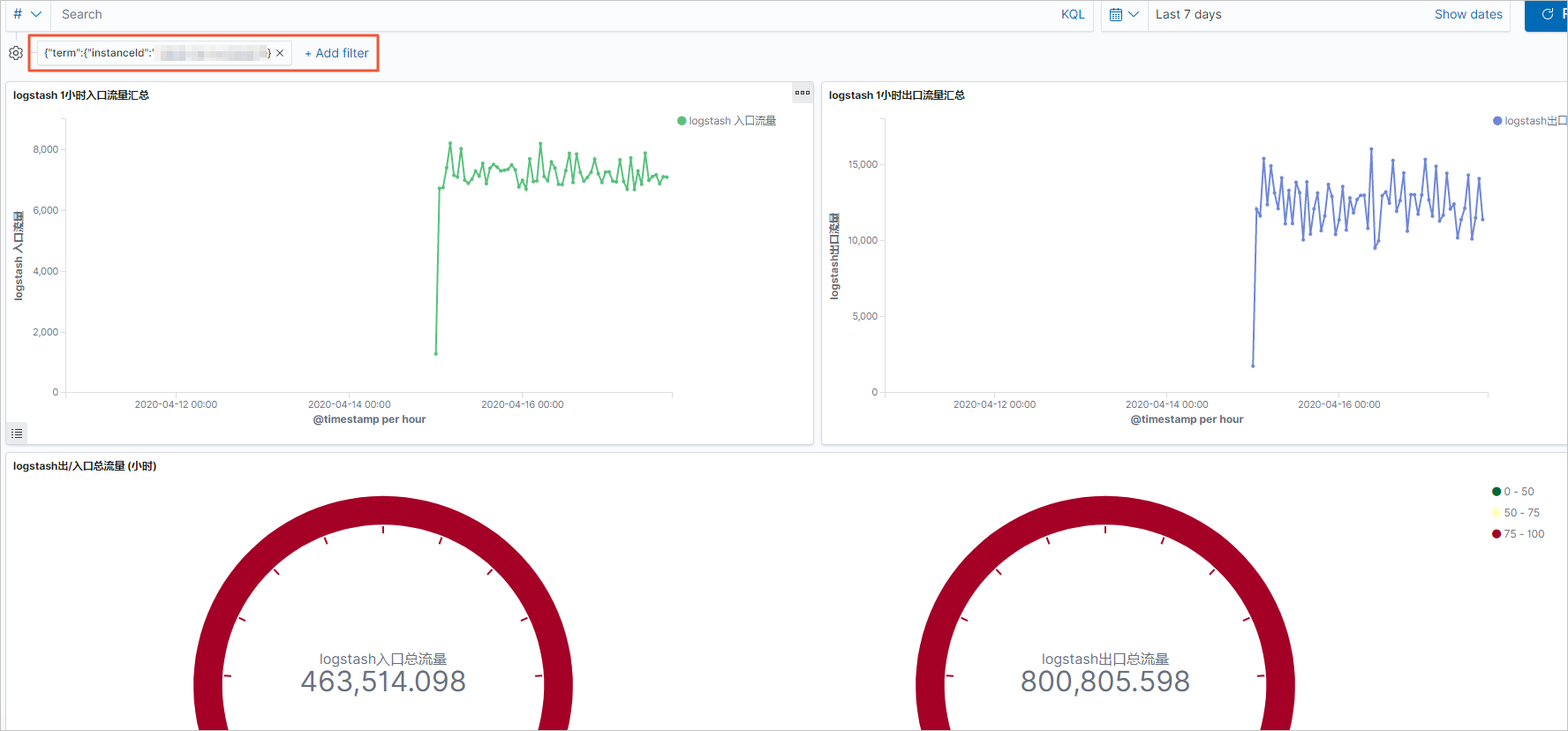
配置成功后,可看到如下结果。
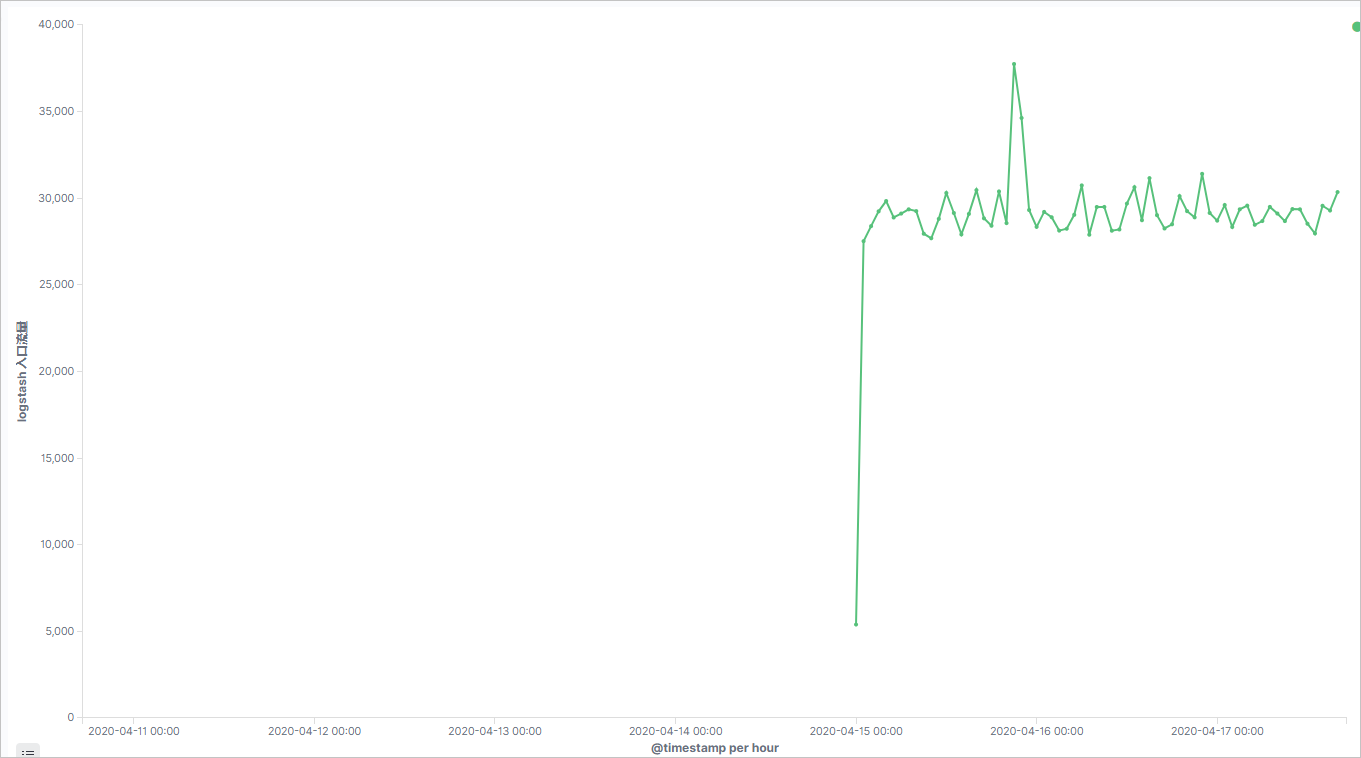
- 使用同样的方式创建Gauge图。
- 参考下图配置Gauge图。


 。
。

 图标。
图标。


步骤六:创建Kibana流量监控仪表板
- 在Kibana控制台中,单击左侧导航栏的Dashboard图标。
- 修改仪表板名称,单击Confirm Save。
仪表板保存成功后,可查看仪表板展示结果。
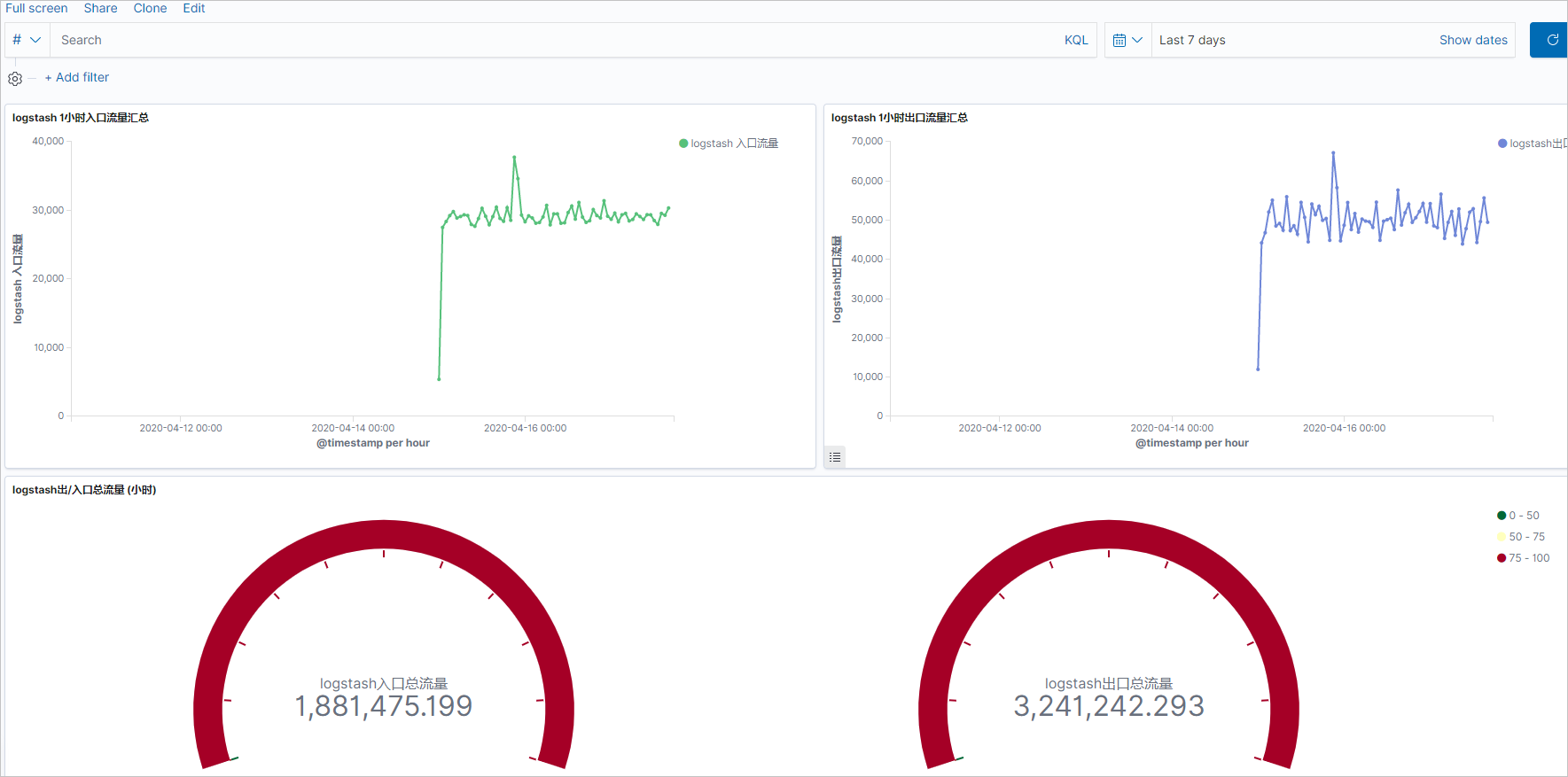
- 单击+ Add filter,选择一个过滤项并配置过滤条件,单击Save。
本文使用term过滤项,指定查询某个instance的流量,最终结果如下。