
本文介绍如何创建JDBC Connector,将MySQL和云消息队列 Kafka 版的数据进行互相同步。
前提条件
步骤一:创建数据表
登录RDS管理控制台,创建RDS MySQL实例。更多信息,请参见创建RDS MySQL实例。
创建实例时,请选择与前提条件中相同的VPC,并将此VPC网段加入白名单。
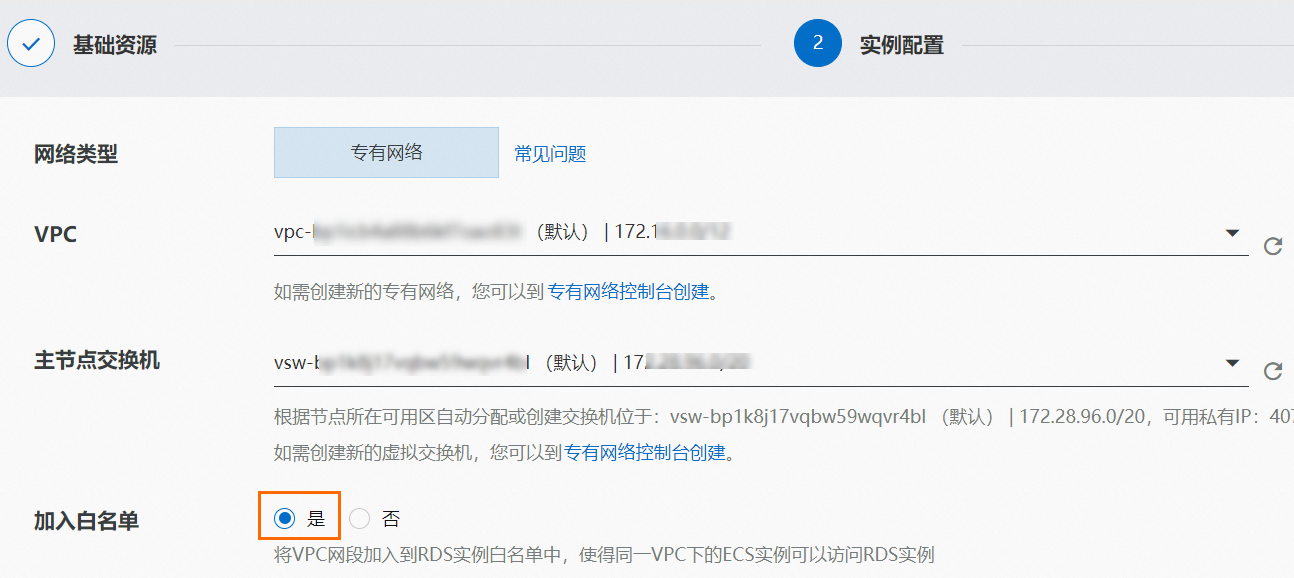
实例创建完成后,在实例列表页面单击目标实例,然后在实例详情页面的左侧导航栏,完成以下操作。
在实例详情页面,单击登录数据库进入DMS数据管理服务平台,单击目标数据库,使用SQL语句创建表格。例如,创建一个列参数分别为id和number的表格,命令如下。更多信息,请参见SQL Commands。
CREATE TABLE sql_table(id INT ,number INT);重要创建表格时,请将任一列参数设置为主键并且设为递增。更多信息,请参见查询与变更表结构。

步骤二:创建Connector
Source Connector
下载JDBC Connector文件,上传至提前创建好的OSS Bucket。更多信息,请参见控制台上传文件。
重要下载JDBC Connector文件时请选择适配Java 8的版本。
登录云消息队列 Kafka 版控制台,在概览页面的资源分布区域,选择地域。
在左侧导航栏,选择。
在任务列表页面,单击创建任务列表。
在创建任务面板。设置任务名称,配置以下配置项。
任务创建
在Source(源)配置向导,选择数据提供方为Apache Kafka Connect,单击下一步。
在连接器配置配置向导,设置以下配置项,然后单击下一步。
配置项
参数
说明
Kafka Connect插件
Bucket存储桶
选择OSS Bucket。
文件
选择上传的.ZIP文件。
Kafka资源信息
Kafka参数配置
选择Source Connect。
Kafka实例
选择前提条件中创建的实例。
专有网络VPC
选择VPC ID。
交换机
选择vSwitch ID。
安全组
选择安全组。
Kafka Connect配置信息
解析当前ZIP包下的properties文件
选择新建properties文件。选择.ZIP文件中包含的SourceConnector对应的.properties文件。路径为/etc/source-xxx.properties。
Connector全量参数配置,请参见JDBC Source Connector Configuration Properties。
在实例配置配置向导,设置以下参数,然后单击下一步。
配置项
参数
说明
Worker规格
Worker规格
选择合适的Worker规格。
最小Worker数
设置为1。
最大Worker数
设置为1。
Kafka Connect Worker 配置
自动创建Kafka Connect Worker依赖资源
建议勾选此项,此时会在选择的Kafka实例中自动创建Kafka Connect运行所需的一些Internal Topic以及ConsumerGroup,并将这些必填配置自动填入配置框中,包括以下配置项:
Offset Topic:用于存储源数据偏移量,命名规则为
connect-eb-offset-<任务名称>。Config Topic:用于存储Connectors以及Tasks的配置信息,命名规则为
connect-eb-config-<任务名称>。Status Topic:用于存储Connectors以及Tasks状态信息,命名规则为
connect-eb-status-<任务名称>。Kafka Connect Consumer Group:Kafka Connect Worker用于消费Internal Topics的消费组,命名规则为
connect-eb-cluster-<任务名称>。Kafka Source Connector Consumer Group:只针对Sink Connector有效,用于消费源Topic中的数据,命名规则为
connector-eb-cluster-<任务名称>-<connector名称>。
在运行配置配置向导,将日志投递方式设置为投递至SLS或者投递至Kafka,在角色授权卡片设置Connect依赖的角色配置,然后单击保存。
重要建议配置的角色包含AliyunSAEFullAccess权限,否则可能会导致任务运行失败。
任务属性
设置此任务的重试策略及死信队列。更多信息,请参见重试和死信。
等待任务状态变为运行中,此时Connector已经在正常工作中。
Sink Connector
下载JDBC Connector文件,上传至提前创建好的OSS Bucket。更多信息,请参见控制台上传文件。
重要下载JDBC Connector文件时请选择适配Java 8的版本。
登录云消息队列 Kafka 版控制台,在概览页面的资源分布区域,选择地域。
在左侧导航栏,选择。
在任务列表页面,单击创建任务列表。
在创建任务面板。设置任务名称,配置以下配置项。
任务创建
在Source(源)配置向导,选择数据提供方为Apache Kafka Connect,单击下一步。
在连接器配置配置向导,设置以下配置项,然后单击下一步。
配置项
参数
说明
Kafka Connect插件
Bucket存储桶
选择OSS Bucket。
文件
选择上传的.ZIP文件。
Kafka资源信息
Kafka参数配置
选择Sink Connect。
Kafka实例
选择前提条件中创建的实例。
专有网络VPC
选择VPC ID。
交换机
选择vSwitch ID。
安全组
选择安全组。
Kafka Connect配置信息
解析当前ZIP包下的properties文件
选择新建properties文件。选择.ZIP文件中包含的SinkConnector对应的.properties文件。路径为/etc/sink-xxx.properties。
Connector全量参数配置,请参见JDBC Sink Connector Configuration Properties。
在实例配置配置向导,设置以下参数,然后单击下一步。
配置项
参数
说明
Worker规格
Worker规格
选择合适的Worker规格。
最小Worker数
设置为1。
最大Worker数
设置为1。此值不能超过tasks.max的取值。
Kafka Connect Worker 配置
自动创建Kafka Connect Worker依赖资源
建议勾选此项,此时会在选择的Kafka实例中自动创建Kafka Connect运行所需的一些Internal Topic以及ConsumerGroup,并将这些必填配置自动填入配置框中,包括以下配置项:
Offset Topic:用于存储源数据偏移量,命名规则为
connect-eb-offset-<任务名称>。Config Topic:用于存储Connectors以及Tasks的配置信息,命名规则为
connect-eb-config-<任务名称>。Status Topic:用于存储Connectors以及Tasks状态信息,命名规则为
connect-eb-status-<任务名称>。Kafka Connect Consumer Group:Kafka Connect Worker用于消费Internal Topics的消费组,命名规则为
connect-eb-cluster-<任务名称>。Kafka Source Connector Consumer Group:只针对Sink Connector有效,用于消费源Topic中的数据,命名规则为
connector-eb-cluster-<任务名称>-<connector名称>。
在运行配置区域,将日志投递方式设置为投递至SLS或者投递至Kafka,在角色授权卡片设置Connect依赖的角色配置,然后单击保存。
重要建议配置的角色包含AliyunSAEFullAccess权限,否则可能会导致任务运行失败。
任务属性
设置此任务的重试策略及死信队列。更多信息,请参见重试和死信。
等待任务状态变为运行中,此时Connector已经在正常工作中。
步骤三:测试Connector
Source Connector
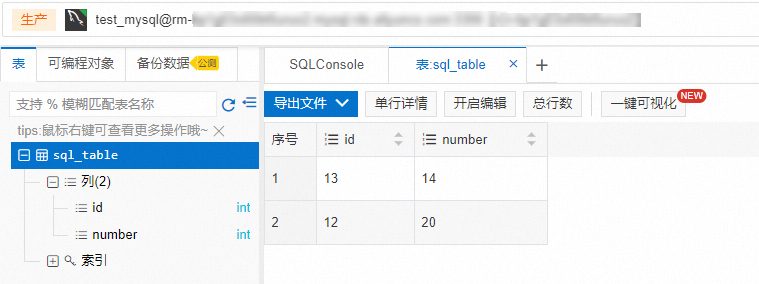
在DMS数据管理服务平台,向步骤一:创建数据表中创建的数据表插入一条数据。例如,插入一条id为12,number为20的数据,命令如下。
INSERT INTO sql_table(id, number) VALUES(12,20);登录云消息队列 Kafka 版控制台,在实例列表页面,单击目标实例。
在目标实例页面,单击目标Topic,然后单击消息查询,查看插入的消息数据,消息Value示例如下。
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"number"}],"optional":false,"name":"sql_table"},"payload":{"id":12,"number":20}}
Sink Connector
登录云消息队列 Kafka 版控制台,在实例列表页面,单击目标实例。
在左侧导航栏,单击Topic管理,然后单击目标Topic。
在Topic详情页面右上角,单击体验发送消息。
在快速体验消息收发面板,设置消息内容。例如在目标表格中添加一条id为13,number为14的数据,消息内容如下。
{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"number"}],"optional":false,"name":"sql_table"},"payload":{"id":13,"number":14}}在DMS数据管理服务平台,查看目标表格中是否有数据写入。
常见报错
场景一:所有Tasks运行失败
错误信息:
All tasks under connector mongo-source failed, please check the error trace of the task.解决方法:在消息流入任务详情页面,单击基础信息区域的诊断链接,即可跳转到Connector监控页面,可以看到Tasks运行失败的详细错误信息。
场景二:Kafka Connect退出
错误信息:
Kafka connect exited! Please check the error log /opt/kafka/logs/connect.log on sae application to find out the reason why kafka connect exited and update the event streaming with valid arguments to solve it.解决方法:由于状态获取可能会有延迟,建议您先尝试刷新页面。若刷新后仍然是失败状态,您可以按照以下步骤查看错误信息。
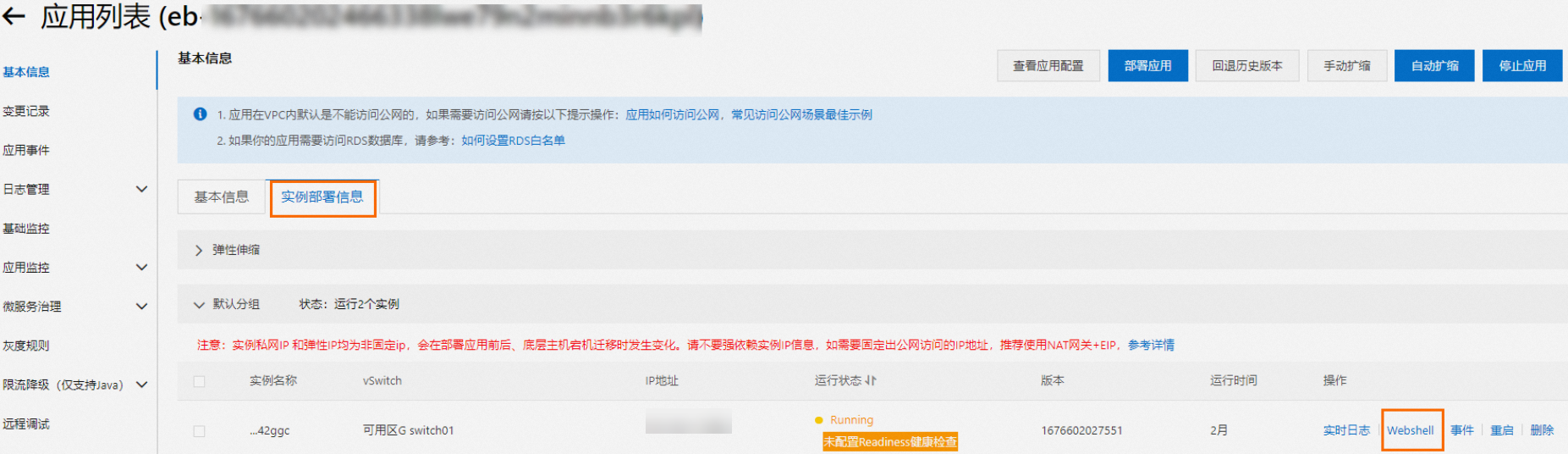
在消息流入任务详情页面的Worker信息区域,单击SAE应用后的实例名称,跳转到SAE应用详情页面。
在基本信息页面,单击实例部署信息页签。
在实例右侧操作列,单击Webshell登录Kafka Connect运行环境。
执行
vi /home/admin/connector-bootstrap.log命令,查看Connector启动日志,查找其中是否包含错误信息。执行
vi /opt/kafka/logs/connect.log命令,查看Connector运行日志,在其中查找ERROR或者WARN字段来查看是否有错误信息。
基于错误信息提示进行修复操作后,可以重新启动对应任务。
场景三:Connector参数校验失败
错误信息:
Start or update connector xxx failed. Error code=400. Error message=Connector configuration is invalid and contains the following 1 error(s):
Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery
You can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`解决方法:此时需要根据错误信息,找出具体哪个参数出错,更新对应参数即可。若基于上述错误信息无法定位具体的出错参数,可以参考上文场景二中的步骤登录Kafka Connect运行环境,执行以下命令,查询参数是否校验通过。
curl -i -X PUT -H "Accept:application/json" -H "Content-Type:application/json" -d @$CONNECTOR_PROPERTIES_MAPPING http://localhost:8083/connector-plugins/io.confluent.connect.jdbc.JdbcSinkConnector/config/validate该指令会返回Connector参数中每个参数是否校验通过,若不通过,则errors属性非空,如下所示。
"value":{
"name":"snapshot.mode",
"value":null,
"recommended_values":[
"never",
"initial_only",
"when_needed",
"initial",
"schema_only",
"schema_only_recovery"
],
"errors":[
"Value must be one of never, initial_only, when_needed, initial, schema_only, schema_only_recovery"
],
"visible":true
}