
本文介绍如何通过设置函数计算的预留模式实例优化按量模式实例的冷启动和函数性能。
什么是冷启动
函数计算提供了按量模式和预留模式两种实例使用模式。按量模式是指函数实例的分配和释放完全由函数计算系统负责,您只需要根据实例执行请求的时间按需付费。按量模式降低了管理应用资源的难度,但也造成了冷启动、延时等性能问题。
冷启动是指在函数调用链路中的代码下载、启动函数实例容器、运行时初始化、代码初始化等环节。当冷启动完成后,函数实例就绪,后续请求就能直接被执行。

优化按量模式的冷启动
冷启动的优化需要用户和平台配合完成。函数计算已经对系统侧的冷启动做了大量优化。对于用户侧的冷启动,建议您从以下几方面优化:
精简代码包
开发者要尽量缩小代码包。去掉不必要的依赖。例如,在Node.js中执行npm prune命令,在Python中执行autoflake 。另外,某些第三方库中可能会包含测试用例源代码、无用的二进制文件和数据文件等,删除无用文件可以降低函数代码下载和解压时间。
选择合适的函数语言
由于语言理念的差异,Java运行时冷启动时间通常要高于其他语言。对于对冷启动延迟敏感的应用,在热启动延迟差别不大的情况下,使用Python轻量语言可以大幅降低长尾延迟。
选择合适的内存
在并发量一定的情况下,函数内存越大,分配的CPU资源相应越多,因此冷启动表现越优。
降低冷启动概率
使用定时触发器预热函数。
使用Initializer回调,函数计算会异步调用初始化接口,消除掉代码初始化的时间,在函数计算系统升级或者函数更新过程中,您对冷启动无感知。
混合模式
用户侧的冷启动一般难以消除。例如,在深度学习推理中,要加载大量的模型文件时;函数要和遗留系统交互,必须使用初始化耗时很长的客户端时。在这些场景下,如果函数对延时非常敏感,您可以为函数设置预留模式实例,或者在同一个函数里同时使用预留模式实例和按量模式实例。
预留模式实例的分配和释放由您管理,根据实例的运行时长计费。当负载对资源的需求超过预留模式实例的能力后,系统自动使用按量模式实例,从而在性能和资源利用率上获得平衡。通过预留模式实例,您能够根据函数的负载变化提前分配好计算资源,系统能够在扩容按量模式实例时仍然使用预留模式实例处理请求,从而彻底消除冷启动带来的延时。
下图展示了混合使用预留模式实例和按量模式实例,既避免了冷启动的延时,又实现了极高的资源利用率。
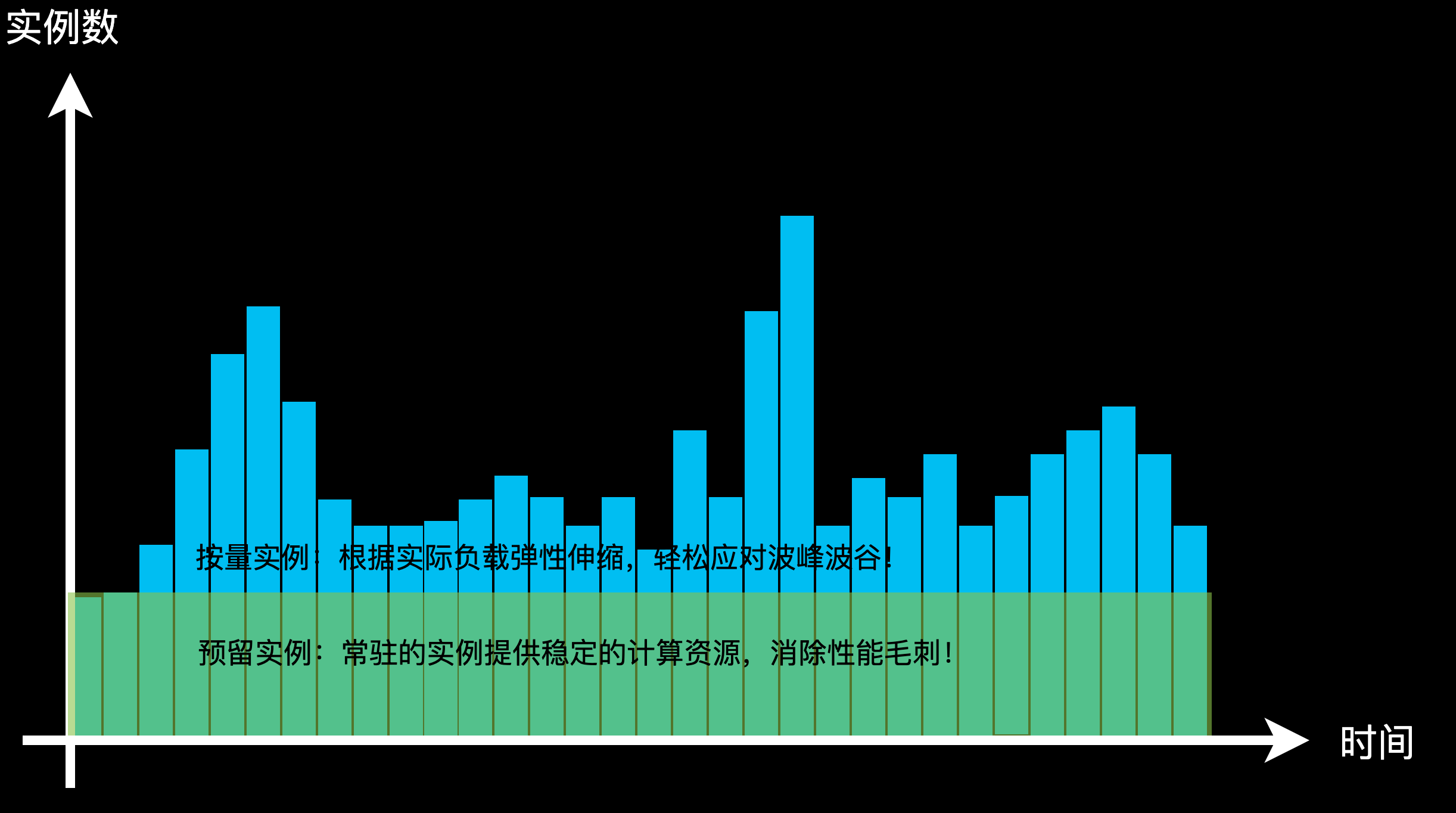
当您混合使用预留模式实例和按量模式实例时,保证优先使用预留模式实例。假设您为函数预留了10个实例,如果一秒内需要的实例数超过10个,系统会创建新的按量模式实例处理请求。判断一个实例是否满载和该实例上的并发请求数配置有关。系统追踪每个函数实例上正在处理的请求数,当并发的请求数达到您设定的上限后,系统会选择其他的函数实例。当所有实例的请求数都达到上限后,创建新的实例。预留模式实例由您管理,即使没有请求,您也需要为浅休眠(原闲置)的预留模式实例付费。按量模式实例由函数计算系统管理,系统在适当的时候将回收没有请求处理的浅休眠(原闲置)按量模式实例。您只需为按量模式实例实际处理请求的时间段付费。计费规则详情,请参见计费概述。您可以设置按量模式实例的使用上限,确保资源的使用在期望的范围内。