
实时计算Flink版支持基于DataStream作业运行动态更新规则的Flink CEP任务。本文结合实时营销中的场景,为您介绍如何基于实时计算Flink版快速构建一个动态加载最新规则来处理上游Kafka数据的Flink CEP作业。
应用场景
在实际应用中,Flink CEP基于Flink的分布式特性、毫秒级处理延迟以及其丰富的规则表达能力有着非常广泛的应用场景。以下我们将展示三个典型场景:
实时风控:Flink CEP可应用于风险用户识别,例如,通过读取并分析客户行为日志,将在5分钟内转账次数超过10次且金额大于10000的客户识别为异常用户。
实时营销:Flink CEP可用于优化营销策略,例如,通过检测用户行为日志,在电商促销期间识别出“在10分钟内添加超过3次商品至购物车但最终未付款”的用户,以便针对性地调整营销策略。此外,在实时营销的反作弊场景中,Flink CEP同样可发挥作用。
物联网:Flink CEP可用于检测异常状态并发出警报,例如,在共享单车被骑出指定区域且15分钟内未返回指定区域时发出风险提示。若与物联网传感器结合,还可以用于检测工业生产中的流水线异常。例如,若在三个时间周期内,温度传感器持续反馈温度超过设定阈值,则应发布报警等措施。
案例演示
本文为您演示如何使用Flink动态CEP解决上述问题。我们假设客户的行为日志会被存放入消息队列Kafka中,Flink CEP作业会消费Kafka数据,同时会去轮询RDS数据库中的规则表,拉取策略人员添加到数据库的最新规则,并用最新规则去匹配事件。针对匹配到的事件,Flink CEP作业会发出告警或将相关信息写入其他数据存储中。示例中整体数据链路如下图所示。

实际演示中,我们会先启动Flink CEP作业,然后插入规则1:连续3条action为0的事件发生后,下一条事件的action仍非1(业务含义为连续3次访问产品后未购买)。还有针对事件具有时效性的处理规则展示,修改规则1为:连续3条的action为0事件发生时,其对应的时间间隔不能超过15分钟(业务含义为在30分钟内连续访问产品3次后仍未购买)。
前提条件
已创建Flink工作空间,详情请参见开通实时计算Flink版。
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
上下游存储
已创建RDS MySQL实例,详情请参见创建RDS MySQL实例。
已创建消息队列Kafka实例,详情请参见消息队列Kafka。
操作流程
本文将介绍如何编写Flink CEP作业,以监测行为日志中符合特定规则的用户并将其记录下来,同时演示如何实现规则的动态更新。具体的操作流程如下:
步骤一:准备测试数据
准备上游Kafka Topic
创建一个名称为demo_topic的Topic,存放模拟的用户行为日志。
操作详情请参见步骤一:创建Topic。
准备RDS数据库
在DMS数据管理控制台上,准备RDS MySQL的测试数据。
使用高权限账号登录RDS MySQL。
详情请参见通过DMS登录RDS MySQL实例。
创建rds_demo规则表,用来记录Flink CEP作业中需要应用的规则。创建match_results结果表,来记录规则匹配到的结果数据。
在已登录的SQLConsole窗口,输入如下命令后,单击执行。
CREATE DATABASE cep_demo_db; USE cep_demo_db; CREATE TABLE rds_demo ( `id` VARCHAR(64), `version` INT, `pattern` VARCHAR(4096), `function` VARCHAR(512) ); CREATE TABLE match_results ( rule_id INT, rule_version INT, user_id INT, user_name VARCHAR(255), production_id INT, PRIMARY KEY (rule_id,rule_version,user_id,production_id) );rds_demo规则表每行代表一条规则,包含id、version等用于区分不同规则与每个规则不同版本的字段、描述CEP API中的模式对象的pattern字段,以及描述如何处理匹配模式的事件序列的function字段。
match_results结果表每行代表某用户针对某产品的行为符合特定规则所产生的匹配结果。后续可基于该条记录制定相应的销售策略,例如发送相应商品的优惠券。
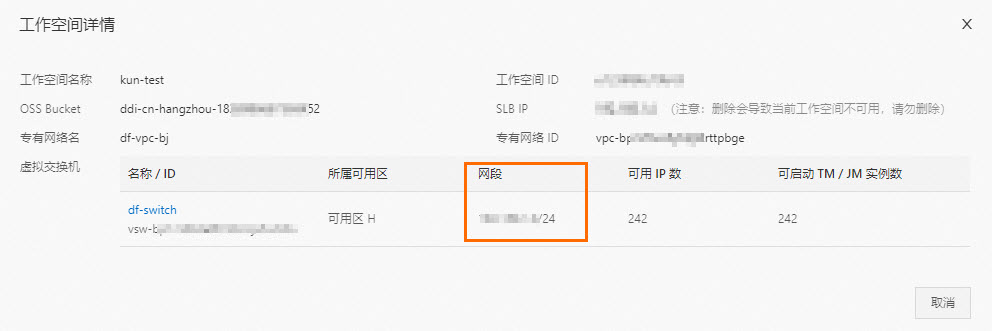
步骤二:配置IP白名单
为了让Flink能访问RDS MySQL实例,您需要将实时计算Flink版的网段添加到RDS MySQL的白名单中。

步骤三:开发并启动Flink CEP作业
本文中提及的所有代码均可在Github仓库中下载。为便于演示,本文中的样例代码在timeOrMoreAndWindow分支上进行了部分修改,您可以直接下载ververica-cep-demo-master.zip压缩包以进行查看和参考。
在作业的Maven POM文件中添加flink-cep作为项目依赖。
其他Flink相关的Jar包处理和冲突解决,详情请参见配置Flink环境依赖。
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-cep</artifactId> <version>1.17-vvr-8.0.8</version> <scope>provided</scope> </dependency>开发作业代码。
构建Kafka Source。
代码编写详情,请参见Kafka DataStream Connector。
构建CEP.dynamicPatterns() API。
为支持CEP规则动态变更与多规则匹配,阿里云实时计算Flink版定义了CEP.dynamicPatterns() API。该API定义代码如下。
public static <T, R> SingleOutputStreamOperator<R> dynamicPatterns( DataStream<T> input, PatternProcessorDiscovererFactory<T> discovererFactory, TimeBehaviour timeBehaviour, TypeInformation<R> outTypeInfo)使用该API时,所需参数如下。您可以根据实际使用情况,更新相应的参数取值。
参数
说明
DataStream<T> input
输入事件流。
PatternProcessorDiscovererFactory<T> discovererFactory
工厂对象。工厂对象负责构造一个探查器(PatternProcessorDiscoverer),探查器负责获取最新规则,即构造一个PatternProcessor接口。
TimeBehaviour timeBehaviour
描述Flink CEP作业如何处理事件的时间属性。参数取值如下:
TimeBehaviour.ProcessingTime:代表按照Processing Time处理事件。
TimeBehaviour.EventTime:代表按照Event Time处理事件。
TypeInformation<R> outTypeInfo
描述输出流的类型信息。
关于DataStream、TimeBehaviour、TypeInformation等Flink作业常见概念详情,请参见DataStream、TimeBehaviour和TypeInformation。
这里重点介绍PatternProcessor接口,一个PatternProcessor包含一个确定的模式(Pattern)用于描述如何去匹配事件,以及一个PatternProcessFunction用于描述如何处理一个匹配(例如发送警报)。除此之外,还包含id与version等用于标识PatternProcessor的信息。因此一个PatternProcessor既包含规则本身,又指明了规则触发时,Flink作业应如何响应。更多背景请参见提案。
而patternProcessorDiscovererFactory用于构造一个探查器去获取最新的PatternProcessor,我们在示例代码中提供了一个默认的周期性扫描外部存储的抽象类。它描述了如何启动一个Timer去定时轮询外部存储拉取最新的PatternProcessor。
public abstract class PeriodicPatternProcessorDiscoverer<T> implements PatternProcessorDiscoverer<T> { ... @Override public void discoverPatternProcessorUpdates( PatternProcessorManager<T> patternProcessorManager) { // Periodically discovers the pattern processor updates. timer.schedule( new TimerTask() { @Override public void run() { if (arePatternProcessorsUpdated()) { List<PatternProcessor<T>> patternProcessors = null; try { patternProcessors = getLatestPatternProcessors(); } catch (Exception e) { e.printStackTrace(); } patternProcessorManager.onPatternProcessorsUpdated(patternProcessors); } } }, 0, intervalMillis); } ... }实时计算Flink版提供了JDBCPeriodicPatternProcessorDiscoverer的实现,用于从支持JDBC协议的数据库(例如RDS或者Hologres等)中拉取最新的规则。在使用时,您需要指定如下参数。
参数
说明
jdbcUrl
数据库JDBC连接地址。
jdbcDriver
数据库驱动类类名。
tableName
数据库表名。
initialPatternProcessors
当数据库的规则表为空时,使用默认的PatternProcessor。
intervalMillis
轮询数据库的时间间隔。
在实际代码中您可以按如下方式使用,作业将会匹配到的规则打印到Flink TaskManager的输出中。
// import ...... public class CepDemo { public static void main(String[] args) throws Exception { ...... // DataStream Source DataStreamSource<Event> source = env.fromSource( kafkaSource, WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner((event, ts) -> event.getEventTime()), "Kafka Source"); env.setParallelism(1); // keyBy userId and productionId // Notes, only events with the same key will be processd to see if there is a match KeyedStream<Event, Tuple2<Integer, Integer>> keyedStream = source.assignTimestampsAndWatermarks( WatermarkStrategy.<Event>forGenerator(ctx -> new EventBoundedOutOfOrdernessWatermarks(Duration.ofSeconds(5))) ).keyBy(new KeySelector<Event, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> getKey(Event value) throws Exception { return Tuple2.of(value.getId(), value.getProductionId()); } }); SingleOutputStreamOperator<String> output = CEP.dynamicPatterns( keyedStream, new JDBCPeriodicPatternProcessorDiscovererFactory<>( params.get(JDBC_URL_ARG), JDBC_DRIVE, params.get(TABLE_NAME_ARG), null, Long.parseLong(params.get(JDBC_INTERVAL_MILLIS_ARG))), Boolean.parseBoolean(params.get(USING_EVENT_TIME)) ? TimeBehaviour.EventTime : TimeBehaviour.ProcessingTime, TypeInformation.of(new TypeHint<String>() {})); output.print(); // Compile and submit the job env.execute("CEPDemo"); } }说明为了方便演示,我们在Demo代码里将输入数据流按照id和product id做了一步keyBy,再与
CEP.dynamicPatterns()连接使用。这意味着只有具有相同id和product id的事件会被纳入到规则匹配的考虑中,不同Key的事件之间不会产生匹配。
在实时计算控制台上,上传JAR包并部署JAR作业,具体操作详情请参见部署作业。
为了让您可以快速测试使用,您需要下载实时计算Flink版测试cep-demo.jar。部署时需要配置的参数填写说明如下表所示。
说明由于目前我们上游的Kafka Source暂无数据,并且数据库中的规则表为空。因此作业运行起来之后,暂时会没有输出。
配置项
说明
部署模式
选择为流模式。
部署名称
填写对应的JAR作业名称。
引擎版本
引擎版本详情请参见引擎版本介绍和生命周期策略。建议您使用推荐版本或稳定版本,版本标记含义详情如下:
推荐版本:当前最新大版本下的最新小版本。
稳定版本:还在产品服务期内的大版本下最新的小版本,已修复历史版本缺陷。
普通版本:还在产品服务期内的其他小版本。
EOS版本:超过产品服务期限的版本。
JAR URI
上传打包好的JAR包,或者直接上传我们提供的测试JAR包。
Entry Point Class
填写为
com.alibaba.ververica.cep.demo.CepDemo。Entry Point Main Arguments
如果您是自己开发的作业,已经配置了相关上下游存储的信息,则此处可以不填写。但是,如果您使用的是我们提供的测试JAR包,则需要配置该参数。代码信息如下。
--kafkaBrokers YOUR_KAFKA_BROKERS --inputTopic YOUR_KAFKA_TOPIC --inputTopicGroup YOUR_KAFKA_TOPIC_GROUP --jdbcUrl jdbc:mysql://YOUR_DB_URL:port/DATABASE_NAME?user=YOUR_USERNAME&password=YOUR_PASSWORD --tableName YOUR_TABLE_NAME --jdbcIntervalMs 3000 --usingEventTime false其中涉及的参数及含义如下:
kafkaBrokers:Kafka Broker地址。
inputTopic:Kafka Topic名称。
inputTopicGroup:Kafka消费组。
jdbcUrl:数据库JDBC连接地址。
说明本示例所使用的JDBC URL中对应的账号和密码需要为普通账号和密码,且密码仅支持英文字母和数字。在实际场景中,您可根据您的需求在作业中使用不同的鉴权方式。
tableName:目标表名称。
jdbcIntervalMs:轮询数据库的时间间隔。
usingEventTime:是否使用事件时间处理(true/false)。
说明需要将以上参数的取值修改为您实际业务上下游存储的信息。
生产环境应避免使用明文密码,建议使用变量管理功能。详情请参见变量管理。
在部署详情页签中的其他配置,添加如下作业运行参数。
在实际应用中,
flink-cep的jar依赖于系统类加载器进行加载,而aviator相关的类通常打包在用户jar中,使用用户类加载器加载。通过下面两个配置,可以确保系统类加载器在尝试加载类时,能够访问到用户jar中的类,从而避免类加载失败的问题。kubernetes.application-mode.classpath.include-user-jar: 'true' classloader.resolve-order: parent-first运行参数配置步骤详情请参见运行参数配置。
在页面,单击目标作业操作列下的启动。
作业启动参数配置详情请参见作业启动。
步骤四:插入规则
启动Flink CEP作业,然后插入规则1:连续3条action为0的事件发生后,下一条事件的action仍非1,其业务含义为连续3次访问产品后没有购买。
登录RDS MySQL控制台。
插入动态更新规则。
将JSON字符串与id、version、function类名等拼接后插入到RDS中。
INSERT INTO rds_demo ( `id`, `version`, `pattern`, `function` ) values( '1', 1, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}', 'com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction') ;为了方便您使用并提高数据库中的Pattern字段的可读性,实时计算Flink版定义了一套JSON格式的规则描述,详情请参见动态CEP中规则的JSON格式定义。上述SQL语句中的pattern字段的值就是按照JSON格式的规则,给出的序列化后的pattern字符串。它的物理意义是去匹配这样的模式:连续3条action为0的事件发生后,下一条事件的action仍为非1。
说明在EndCondtion相关代码中,定义的条件为“action != 1"。
对应的CEP API描述如下。
Pattern<Event, Event> pattern = Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent()) .where(new StartCondition("action == 0")) .timesOrMore(3) .followedBy("end") .where(new EndCondition());可以通过CepJsonUtils中的方法将其转换为对应的JSON字符串。
public void printTestPattern(Pattern<?, ?> pattern) throws JsonProcessingException { System.out.println(CepJsonUtils.convertPatternToJSONString(pattern)); }对应的JSON字符串如下。
通过Kafka Client向demo_topic中发送消息。
在本Demo中,您也可以使用消息队列Kafka提供的快速体验消息收发页面发送测试消息。
1,Ken,0,1,1662022777000 1,Ken,0,1,1662022778000 1,Ken,0,1,1662022779000 1,Ken,0,1,1662022780000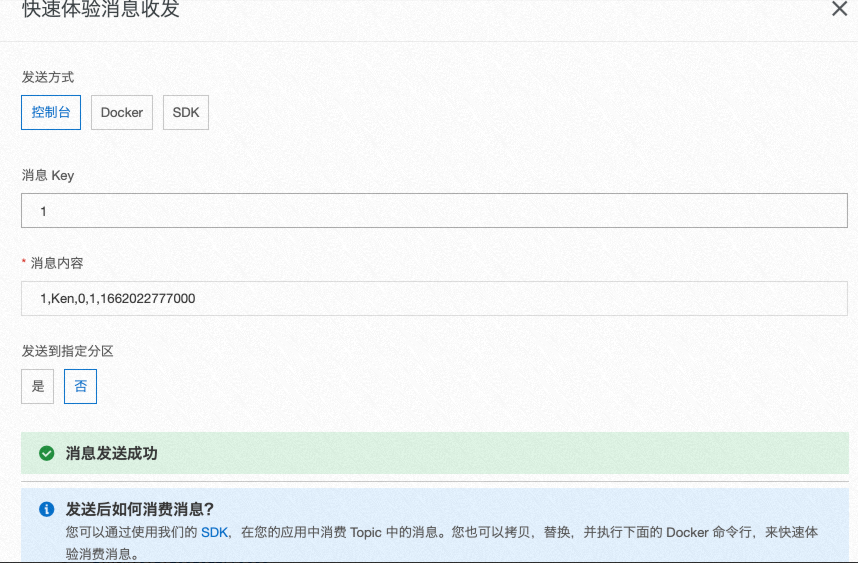
demo_topic字段说明如下表所示。
字段
说明
id
用户ID。
username
用户名。
action
用户动作,取值如下:
0代表浏览操作。
1代表购买动作。
product_id
商品ID。
event_time
该行为发生的事件时间。
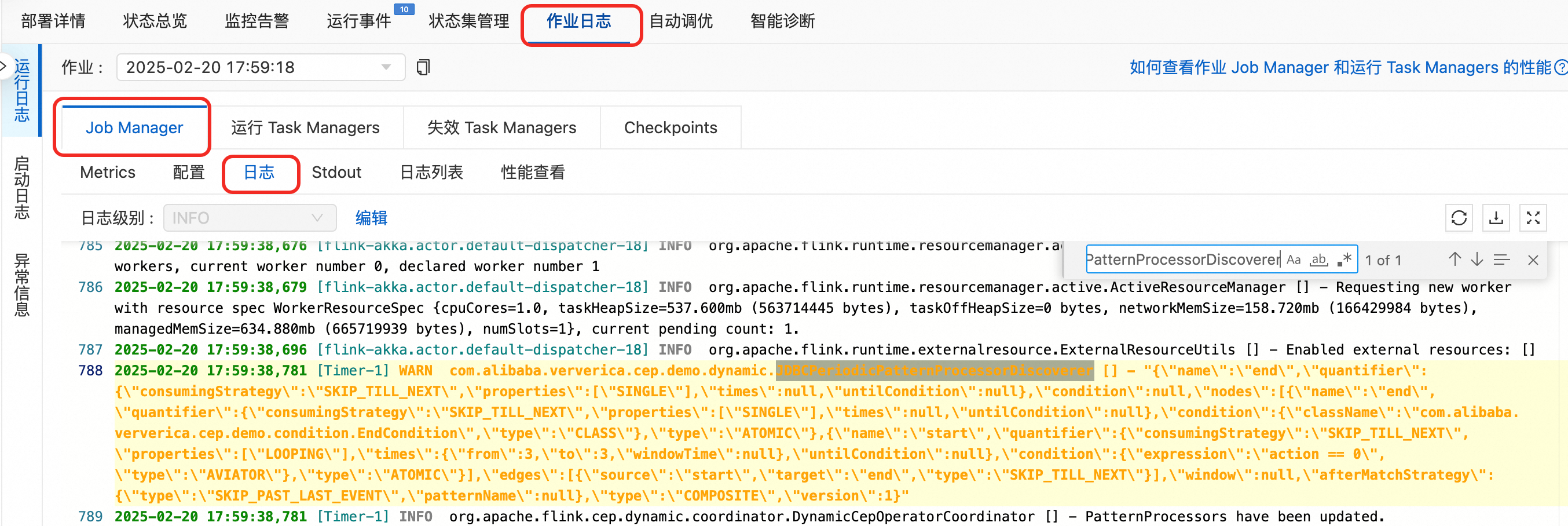
查看JobManager日志中打印的最新规则和TaskManager日志中打印的匹配。
在JobManager日志中,通过JDBCPeriodicPatternProcessorDiscoverer关键词搜索,查看最新的规则。
在TaskManager中以.out结尾的日志文件中,通过
A match for Pattern of (id, version): (1, 1)关键词搜索,查看日志中打印的匹配。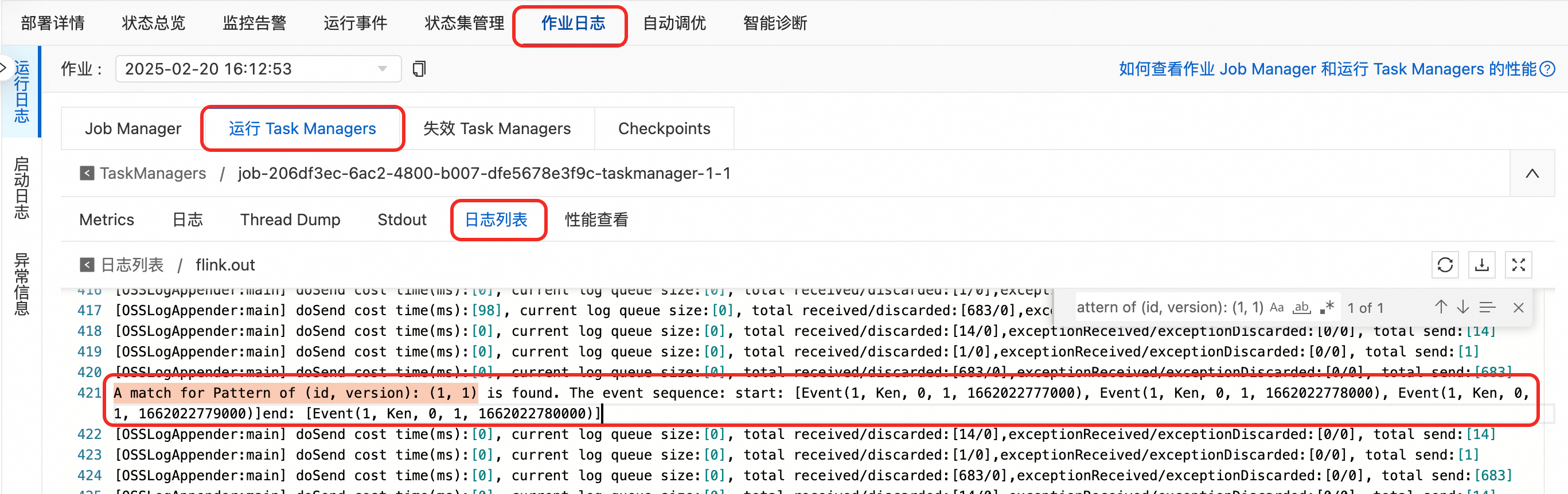
查看match_results结果表,
SELECT * FROM `match_results` ;查询规则所匹配到的结果信息。
步骤五:更新匹配规则
在实际应用中,针对用户制定对应的营销策略时,往往需要具有时效性,我们将规则更新为:连续3条的action为0事件发生时,其相应的时间间隔不能超过15分钟。
设置usingEventTime参数为true。
在页面,单击目标作业操作列下的停止。
在中编辑,修改
usingEventTime参数为true后,点击保存。重新启动作业。
插入新规则。
对应的CEP API描述如下。
Pattern<Event, Event> pattern = Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent()) .where(new StartCondition("action == 0")) .timesOrMore(3,Time.minutes(15)) .followedBy("end") .where(new EndCondition()); printTestPattern(pattern);向rds_demo表中插入新规则。
# 为避免规则相同影响演示效果,我们先删除之前的规则 DELETE FROM `rds_demo` WHERE `id` = 1; # 插入新规则:连续3条的action为0事件发生时,其相应的时间间隔不能超过15分钟,下一条事件的action仍为非1。规则版本为(1,2)。 INSERT INTO rds_demo (`id`,`version`,`pattern`,`function`) values('1',2,'{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":{"unit":"MINUTES","size":15}},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction');在Kafka控制台上发送8条简单的消息,来触发匹配。
8条简单的消息示例如下。
2,Tom,0,1,1739584800000 #10:00 2,Tom,0,1,1739585400000 #10:10 2,Tom,0,1,1739585700000 #10:15 2,Tom,0,1,1739586000000 #10:20 3,Ali,0,1,1739586600000 #10:30 3,Ali,0,1,1739588400000 #11:00 3,Ali,0,1,1739589000000 #11:10 3,Ali,0,1,1739590200000 #11:30查看match_results结果表,
SELECT * FROM `match_results` ;查询规则所匹配到的结果信息。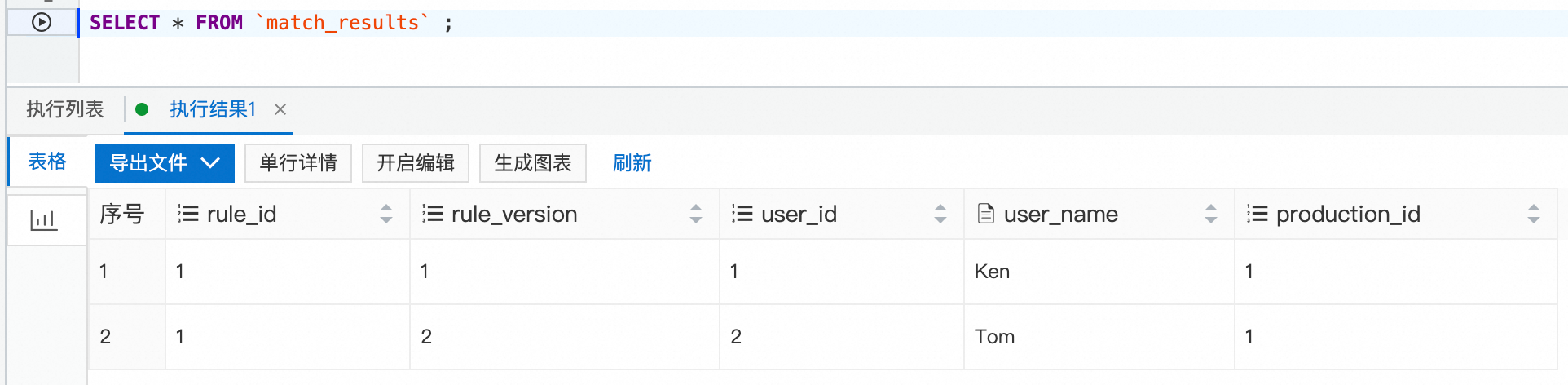
从结果来看,仅有用户Tom的行为符合规则匹配,由于Ali的行为周期超过15分钟,未满足相应的规则。在某些限时促销活动中,针对在规定时间内多次访问特定产品的用户,可以向其发放优惠券等,以引导用户进行消费。