
实时计算Flink版提供了丰富强大的数据实时入仓能力。通过Flink的全增量自动切换、元信息自动发现、表结构变更自动同步和整库同步等功能,简化了数据实时入仓的链路,使得实时数据同步更加高效便捷。本文介绍如何快速构建一个从MySQL到Hologres的数据摄入作业。
背景信息
假设MySQL实例中有一个tpc_ds库,里面有24张表结构不相同的业务表。另外还有user_db1~user_db3三个库,由于进行了分库分表的设计,每个库中分别有3张表结构相同的表,共包含名称为user01~user09的9张表。在阿里云DMS控制台观察到MySQL中的库和表情况如下图所示。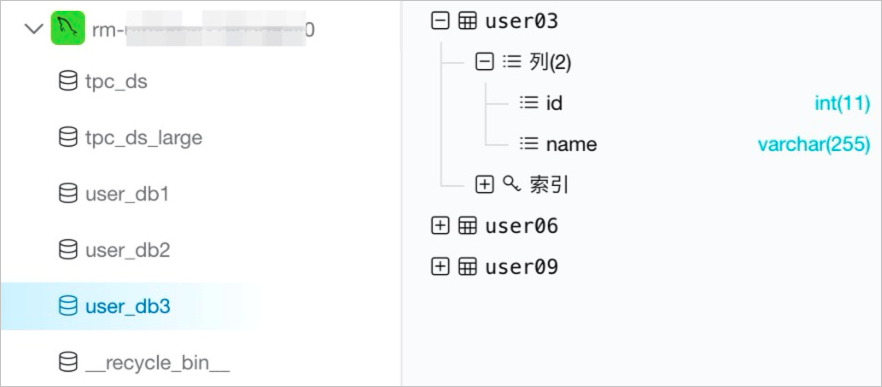
此时,如果您希望开发一个数据摄入的作业,将这些表和数据都同步到Hologres中,其中user分库分表能合并到Hologres的一张表中,则可以按照以下步骤进行:
本文使用Flink CDC数据摄入作业开发(公测中)来完成整库同步、分库分表合并同步,一键完成数据的全量和增量同步,以及实时的表结构变更同步。
前提条件
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
已创建Flink工作空间,详情请参见开通实时计算Flink版。
上下游存储
已创建RDS MySQL实例,详情请参见快速创建RDS MySQL实例。
已创建Hologres实例,详情请参见购买Hologres。
说明RDS MySQL和Hologres需要与Flink工作空间在相同地域相同VPC下,否则需要打通网络,详情请参见如何访问跨VPC的其他服务?和如何访问公网?。
已准备好测试数据,并配置好白名单。详情请参见准备MySQL测试数据和Hologres数据库和配置IP白名单。
准备MySQL测试数据和Hologres数据库
单击tpc_ds.sql、user_db1.sql、user_db2.sql和user_db3.sql下载测试数据到本地。
在DMS数据管理控制台上,准备RDS MySQL的测试数据。
通过DMS登录RDS MySQL。
详情请参见通过DMS登录RDS MySQL。
在已登录的SQLConsole窗口,输入如下命令后单击执行。
创建tpc_ds、user_db1、user_db2和user_db3四个数据库。
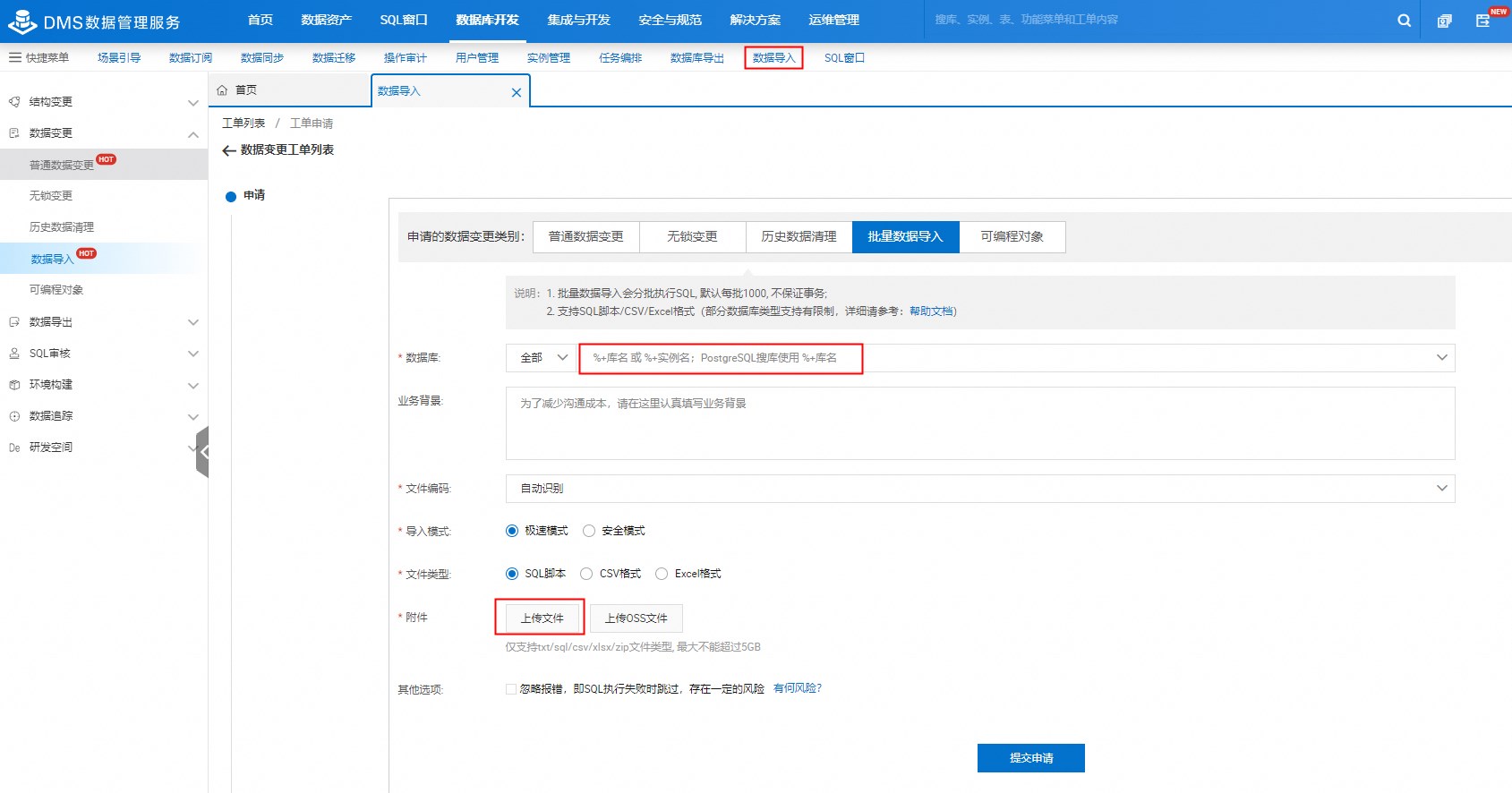
CREATE DATABASE tpc_ds; CREATE DATABASE user_db1; CREATE DATABASE user_db2; CREATE DATABASE user_db3;在顶部快捷菜单栏,单击数据导入。
在批量数据导入页签下选择需要导入的数据库,上传对应的SQL文件,单击提交申请后,单击执行变更。在弹出的对话框中单击确定执行。
同样的操作依次为tpc_ds、user_db1、user_db2和user_db3数据库导入对应的数据文件。
在Hologres控制台创建my_user数据库,用于存放合并后的user表数据。
操作步骤详情请参见创建数据库。
配置IP白名单
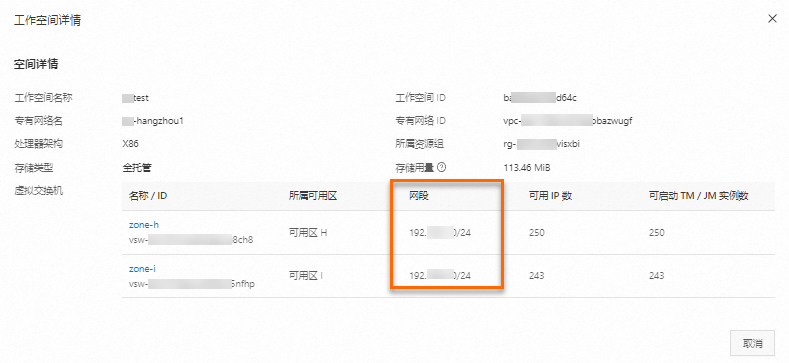
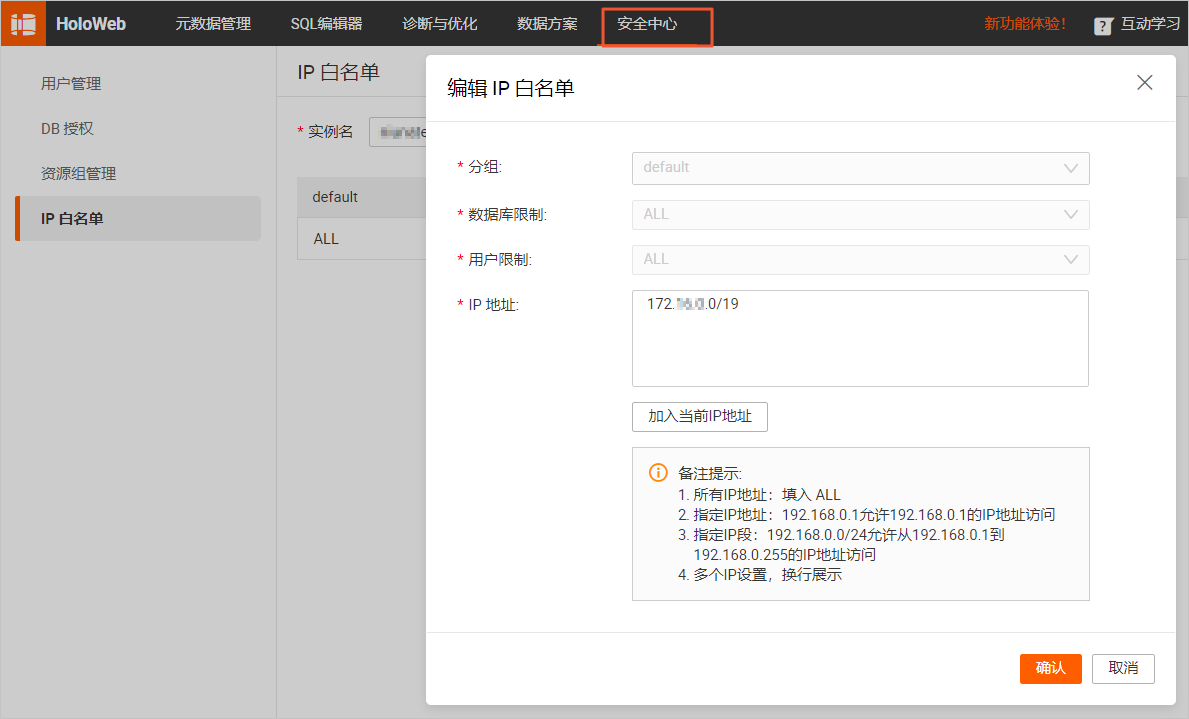
为了让Flink能访问MySQL和Hologres实例,您需要将Flink工作空间的网段添加到MySQL和Hologres的白名单中。

步骤一:开发数据同步作业
登录Flink开发控制台,新建作业。
在页面,单击新建。
单击空白的数据摄入草稿。
Flink为您提供了丰富的代码模板,每种代码模板都为您提供了具体的使用场景、代码示例和使用指导。您可以直接单击对应的模板快速地了解Flink产品功能和相关语法,实现您的业务逻辑。
单击下一步。
在新建数据摄入作业草稿对话框,填写作业配置信息。
作业参数
说明
示例
文件名称
作业的名称。
说明作业名称在当前项目中必须保持唯一。
flink-test
存储位置
指定该作业的代码文件所属的文件夹。
您还可以在现有文件夹右侧,单击
 图标,新建子文件夹。
图标,新建子文件夹。作业草稿
引擎版本
当前作业使用的Flink的引擎版本。引擎版本号含义、版本对应关系和生命周期重要时间点详情请参见引擎版本介绍。
vvr-11.1-jdk11-flink-1.20
单击确定。
将以下作业代码拷贝到作业文本编辑区。
将tpc_ds库中所有表同步至Hologres,并将user的分库分表合并同步到Hologres的单表中。代码示例如下所示。
source: type: mysql name: MySQL Source hostname: localhost port: 3306 username: username password: password tables: tpc_ds.\.*,user_db[0-9]+.user[0-9]+ server-id: 8601-8604 #(可选)同步表注释和字段注释 include-comments.enabled: true #(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题 scan.incremental.snapshot.unbounded-chunk-first.enabled: true #(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题 scan.incremental.snapshot.unbounded-chunk-first.enabled: true #(可选)开启解析过滤,加速读取 scan.only.deserialize.captured.tables.changelog.enabled: true sink: type: hologres name: Hologres Sink endpoint: ****.hologres.aliyuncs.com:80 dbname: cdcyaml_test username: ${secret_values.holo-username} password: ${secret_values.holo-password} sink.type-normalize-strategy: BROADEN route: # 将user的分库分表合并同步到my_user.users表中 - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.users说明MySQL tpc_ds库中的所有表直接映射到下游的同名库表中,因此不需要在route模块中额外配置映射关系。如果您希望同步到其他名称的数据库,例如ods_tps_ds库,可以配置route模块为:
route: # 将user的分库分表合并同步到my_user.users表中 - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.users # 统一修改表名,将tpc_ds库下所有表同步到ods_tps_ds库中 - source-table: tpc_ds.\.* sink-table: ods_tps_ds.<> replace-symbol: <>
步骤二:启动作业
在页面,单击部署后,在弹出的对话框中,单击确认。

在页面,单击目标作业操作中的启动。填写配置信息,详情请参见作业启动。
单击启动。
作业启动后,您可以在作业运维页面观察作业的运行信息和状态。

步骤三:观察全量同步结果
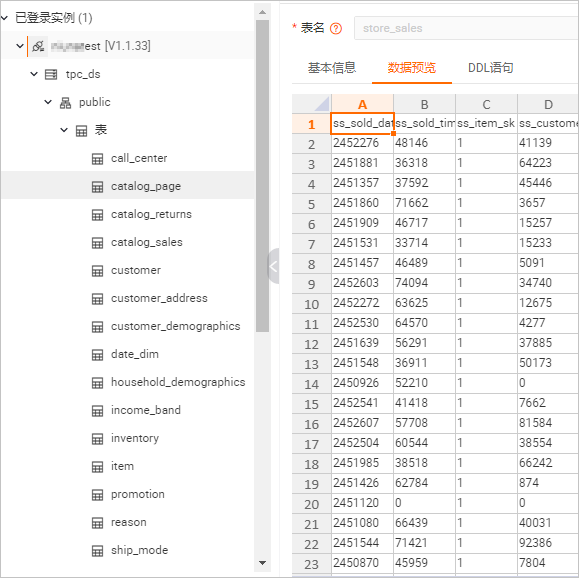
在元数据管理页签,查看Hologres实例下的tpc_ds数据库中24张表和表数据。
在元数据管理页签,查看my_user库下users表结构。
同步后的表结构和数据如下图所示。
表结构
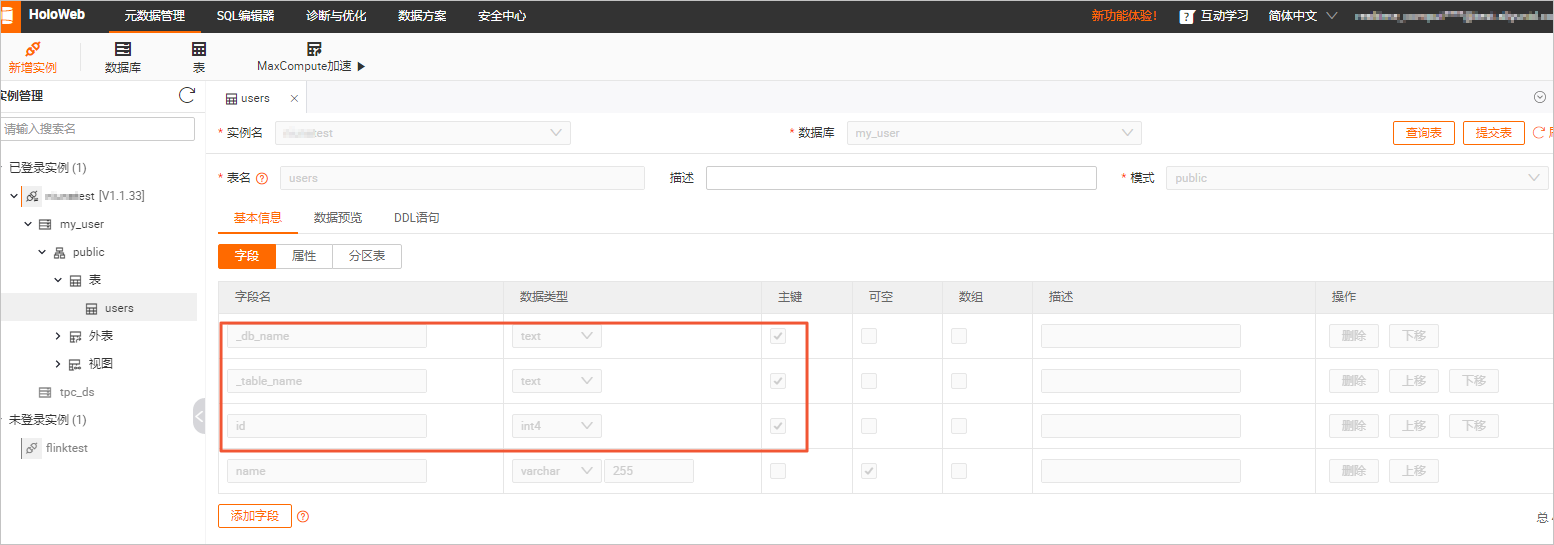
users表的表结构比MySQL源表中多了_db_name和_table_name两列,代表数据来源的库名和表名,且作为联合主键的一部分来保证分库分表合并后的数据唯一性。
表数据
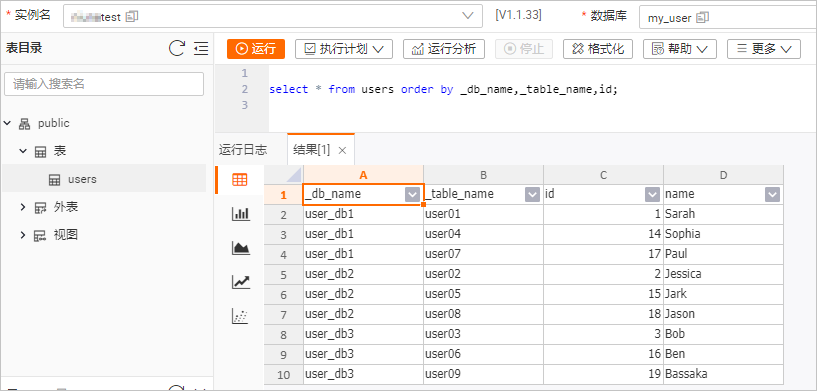
在users表信息页面右上角,单击查询表后,输入如下命令,单击运行。
select * from users order by _db_name,_table_name,id;表数据结果如下图所示。
步骤四:观察增量同步结果
同步作业会在全量数据同步完以后自动切换到增量数据同步阶段,无需干预。您可以通过监控告警页签的currentEmitEventTimeLag值来确定数据同步的阶段。
登录实时计算控制台。
单击对应工作空间操作列下的控制台。
在页面,单击目标作业名称。
单击监控告警(或数据曲线)页签。
观察currentEmitEventTimeLag曲线图,确定数据同步阶段。
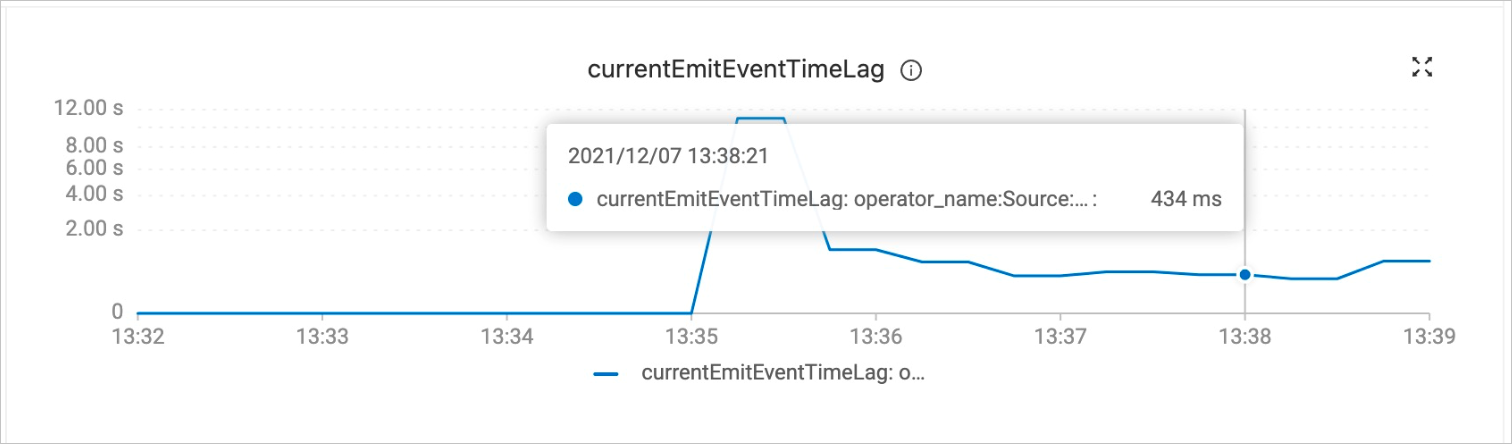
值为0时,代表还在全量同步阶段。
值大于0时,代表已经进入增量同步阶段。
验证实时同步数据变更和结构变更的能力。
MySQL CDC数据源支持在增量同步阶段,实时同步表的数据变更以及表的结构变更。您可以在作业进入到增量同步阶段后,通过修改MySQL的user分表的表结构和数据,来验证实时同步数据变更和结构变更的能力。
通过DMS登录RDS MySQL。
详情请参见通过DMS登录RDS MySQL。
在user_db2数据库下,执行如下命令修改user02表的表结构,并插入和更新数据。
USE DATABASE `user_db2`; ALTER TABLE `user02` ADD COLUMN `age` INT; -- 添加age列。 INSERT INTO `user02` (id, name, age) VALUES (27, 'Tony', 30); -- 插入带有age的数据。 UPDATE `user05` SET name='JARK' WHERE id=15; -- 更新另一张表,名字改成大写。在Hologres控制台,查看users表结构和数据的变化。
在users表信息页面右上角,单击查询表后,输入如下命令,单击运行。
select * from users order by _db_name,_table_name,id;表数据结果如下图所示。
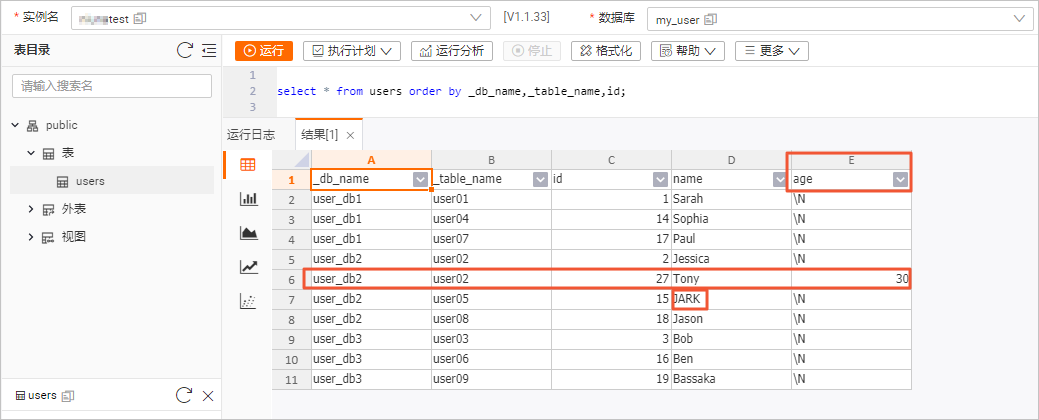 虽然多张分表的Schema并不一致,但是在user02上的表结构变更,以及数据变更都能实时地同步到下游表中。在Hologres的users表中,看到了新增的age字段,插入的Tony数据以及更新成大写的JARK数据。
虽然多张分表的Schema并不一致,但是在user02上的表结构变更,以及数据变更都能实时地同步到下游表中。在Hologres的users表中,看到了新增的age字段,插入的Tony数据以及更新成大写的JARK数据。
(可选)步骤五:作业资源配置
根据数据量的不同,我们往往需要调节并发和TaskManager的资源,以达到更优的作业性能。您可以使用资源配置调节作业并发度和内存/CU数。
在页面,单击目标作业名称。
在部署详情页签下,单击资源配置区域右上角的编辑。
手动设置Task Manager Memory与并发度等资源参数。
在资源配置右侧,单击保存。
重启作业。
作业资源配置后,需重启作业才能生效。
相关文档
数据摄入各个模块语法介绍,请参见Flink CDC数据摄入作业开发参考。
数据摄入作业运行过程中出现异常,请参见Flink CDC数据摄入作业常见问题和解决方案。