
本文通过简单的示例,带您快速体验Flink SQL作业的创建、部署和启动等操作,以了解Flink SQL作业的操作流程。
前提条件
如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
已创建Flink工作空间,详情请参见开通实时计算Flink版。
步骤一:创建作业
 后,单击新建流作业,填写文件名称并选择引擎版本。
后,单击新建流作业,填写文件名称并选择引擎版本。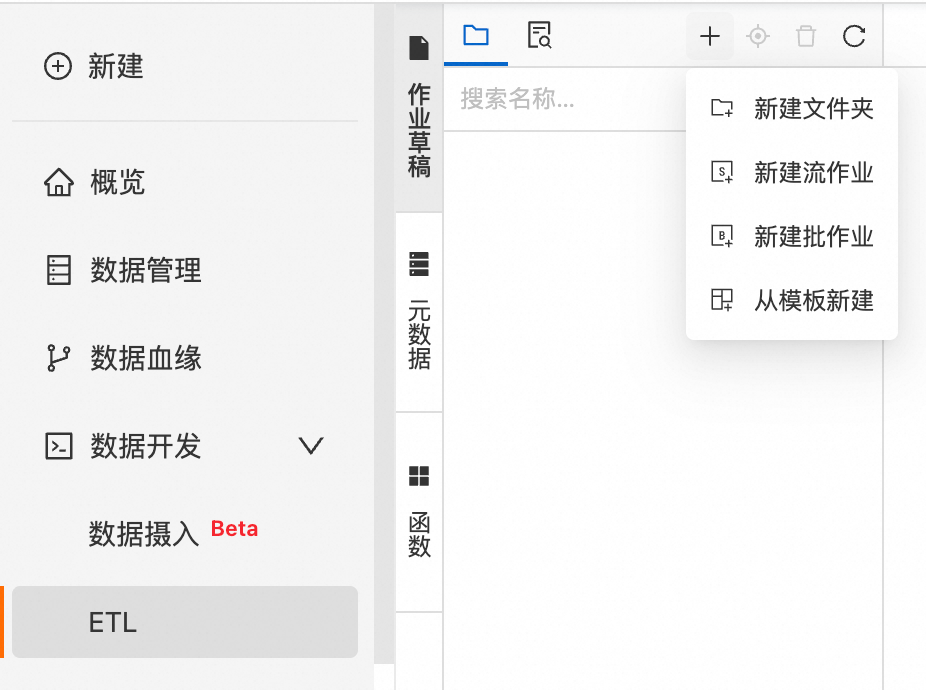
步骤二:编写SQL作业并查看配置信息
编写SQL作业。
拷贝如下SQL到SQL编辑区域。本SQL示例使用Datagen连接器生成随机的数据流,并通过Print连接器将计算结果打印到实时计算开发控制台上。支持的更多连接器请参见支持的连接器。
--创建临时源表datagen_source。 CREATE TEMPORARY TABLE datagen_source( randstr VARCHAR ) WITH ( 'connector' = 'datagen' -- datagen连接器 ); --创建临时结果表print_table。 CREATE TEMPORARY TABLE print_table( randstr VARCHAR ) WITH ( 'connector' = 'print', -- print连接器 'logger' = 'true' -- 控制台显示计算结果 ); --将randstr字段截取后打印出来。 INSERT INTO print_table SELECT SUBSTRING(randstr,0,8) from datagen_source;说明本SQL示例给出了用
INSERT INTO写入一个Sink,INSERT INTO也可以写入多个Sink,有关详情请参见INSERT INTO语句。在实际生产作业中,建议您尽量减少临时表的使用,直接使用元数据管理中已经注册的表,详情请参见数据管理。
查看配置信息。
在SQL编辑区域右侧页签,您可以查看或上传相关配置。
页签名称
配置说明
更多配置
引擎版本:引擎版本详情请参见引擎版本介绍和生命周期策略。建议您使用推荐版本或稳定版本,引擎版本标记含义详情如下:
推荐版本(Recommend):当前最新大版本下的最新小版本。
稳定版本(Stable):还在产品服务期内的大版本下最新的小版本,已修复历史版本缺陷。
普通版本(Normal):还在产品服务期内的其他小版本。
EOS版本(Deprecated):超过产品服务期限的版本。
附加依赖文件:作业中需要使用到的附加依赖,例如临时函数等。
Kerberos 认证:开启Kerberos认证,配置已注册的Kerberos集群和Principal用户信息。如尚未注册Kerberos集群,请参考注册Hive Kerberos集群。
代码结构
数据流向图:您可以通过数据流向图快速查看数据的流向。
树状结构图:您可以通过树状结构图快速查看数据的来源。
版本信息
您可以在此处查看作业版本信息,操作列下的功能详情请参见管理作业版本。
(可选)步骤三:作业深度检查与调试
作业深度检查。
深度检查能够检查作业的SQL语义、网络连通性以及作业使用的表的元数据信息。同时,您可以单击结果区域的SQL优化,展开查看SQL风险问题提示以及对应的SQL优化建议。
在SQL编辑区域右上方,单击深度检查。
在深度检查对话框,单击确认。
说明在作业深度检查时出现超时错误,报错信息如下:
The RPC times out maybe because the SQL parsing is too complicated. Please consider enlarging the `flink.sqlserver.rpc.execution.timeout` option in flink-configuration, which by default is `120 s`.
解决方案:您需要在作业编辑页面的最上面添加以下参数配置。
SET 'flink.sqlserver.rpc.execution.timeout' = '600s';作业调试。
您可以使用作业调试功能模拟作业运行、检查输出结果,验证SELECT或INSERT业务逻辑的正确性,提升开发效率,降低数据质量风险。
说明作业调试功能不会将产生的数据写入到下游结果表中。
在SQL编辑区域右上方,单击调试。
在调试对话框,选择调试集群后,单击下一步。
如果没有可用集群则需要创建新的Session集群,Session集群与SQL作业引擎版本需要保持一致并处于运行中,详情请参见步骤一:创建Session集群。
配置调试数据,单击确定。
配置详情请参见步骤二:作业调试。
步骤四:作业部署
在SQL编辑区域右上方,单击部署,在部署新版本对话框,可根据需要填写或选中相关内容,单击确定。
在部署作业时部署目标可以选择资源队列或者Session集群,具体如下:
部署目标 | 适用环境 | 核心特性 |
资源队列 | 正式生产环境 |
|
Session集群 | 开发测试环境 |
重要 Seesion集群运行的作业无法进行作业日志查看。 |
步骤五:启动作业并查看结果
在左侧导航栏,单击。
单击目标作业名称操作列中的启动。
选择无状态启动后,单击启动。当您看到作业状态变为运行中,则代表作业运行正常。作业启动参数配置,详情请参见作业启动。
在作业运维详情页面,查看Flink计算结果。
在页面,单击目标作业名称。
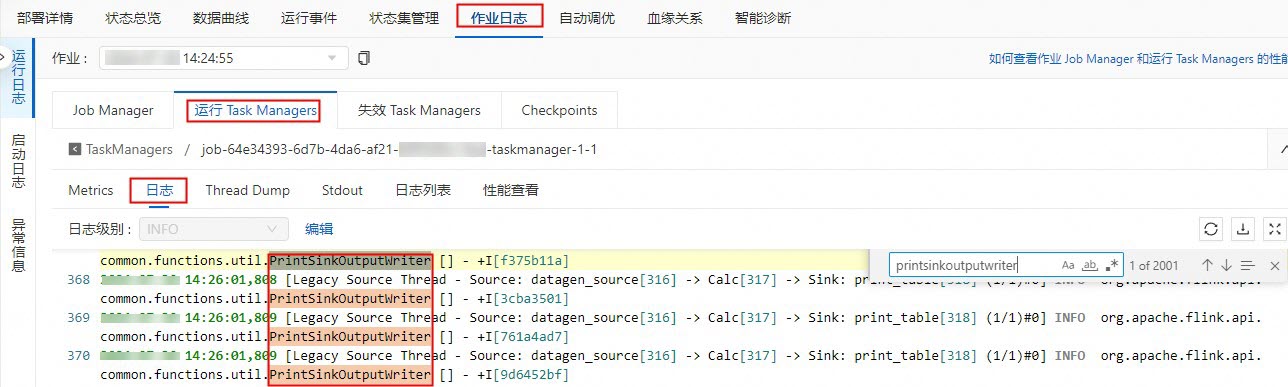
在作业日志页签,单击运行Task Managers页签下的Path, ID的任务。
单击日志,在页面搜索PrintSinkOutputWriter相关的日志信息。
(可选)步骤六:停止作业
如果您对作业进行了修改(例如更改代码、增删改WITH参数、更改作业版本等),且希望修改生效,则需要重新部署作业,然后停止再启动。另外,如果作业无法复用State,希望作业全新启动时,或者更新非动态生效的参数配置时,也需要停止后再启动作业。作业停止详情请参见作业停止。
在页面,单击目标作业操作列下的停止。
单击确定。
相关文档
作业开发&作业运维常见问题
配置作业相关信息
其他类型作业开发流程
Flink相关的最佳实践