实时计算Flink版支持与Apache Sedona集成,为用户提供强大的分布式实时地理空间分析能力。本文以一个实时交通密度分析的场景为例,详细介绍如何在Flink中调用Sedona的空间函数,对数据流进行高效的地理空间计算。
使用限制
实时计算Flink版引擎VVR 8.0.11及以上版本。
Apache Sedona
Apache Sedona是一个专门为处理海量地理空间数据而设计的分布式、高性能计算框架。
Sedona 1.7.2版本支持3个聚合函数(AggregateFunction)和200+个标量函数(ScalarFunction),详细内容请参考官方API Docs。
使用Sedona
SQL作业
本节将会介绍如何编写一个简易的实时交通密度分析SQL作业,并部署至实时计算Flink版。
1.下载JAR包
从Sedona Maven仓库下载所需版本的JAR包,如sedona-flink-shaded_2.12-1.7.2.jar。
或从Sedona官网下载页面获取压缩包,解压后得到Flink所需的sedona-flink-shaded_2.12-1.7.2.jar。
2.注册UDF JAR
在实时计算控制台的数据开发>ETL/数据查询>函数页面,点击+号注册UDF JAR,上传刚才下载的sedona-flink-shaded_2.12-1.7.2.jar,选择所需的函数进行注册。
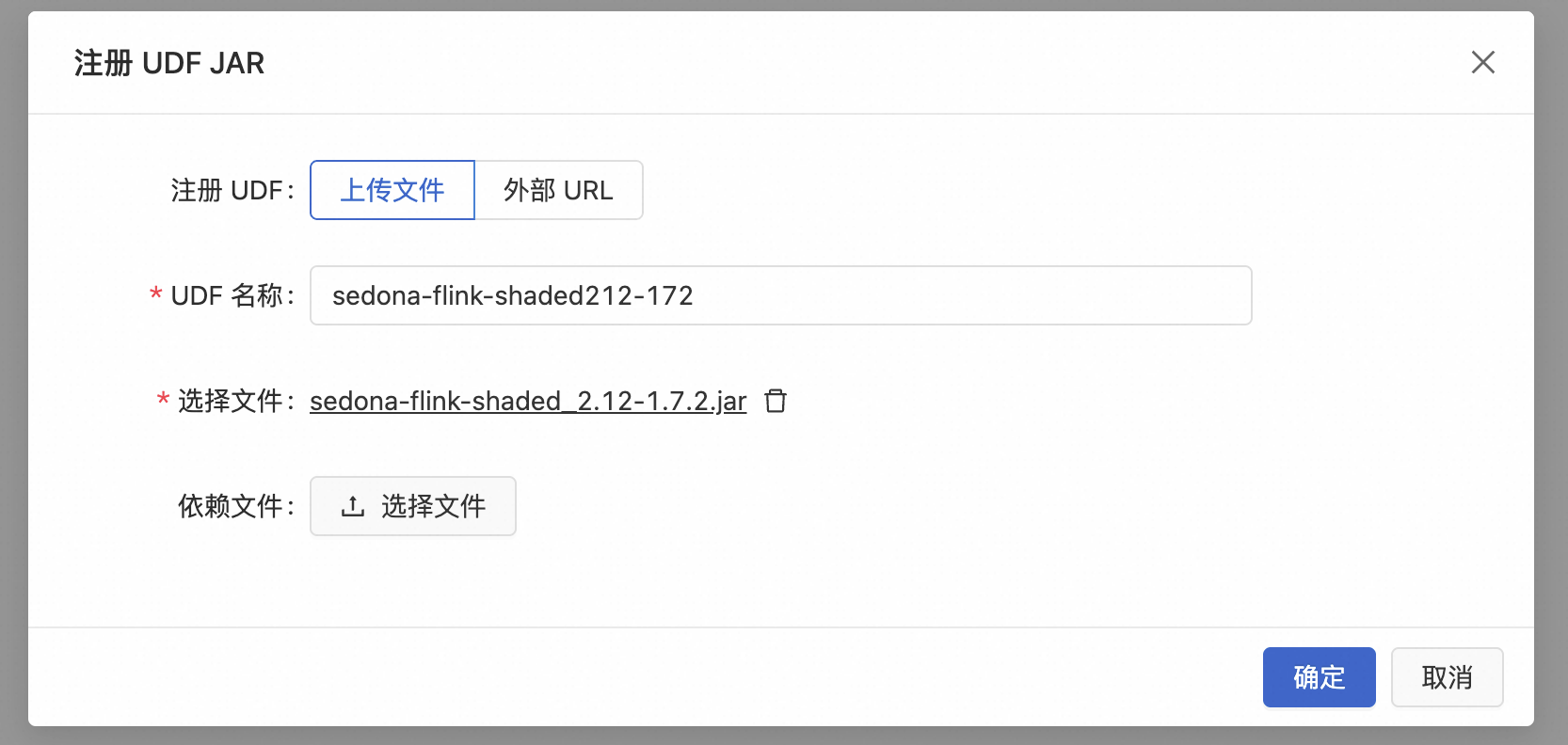
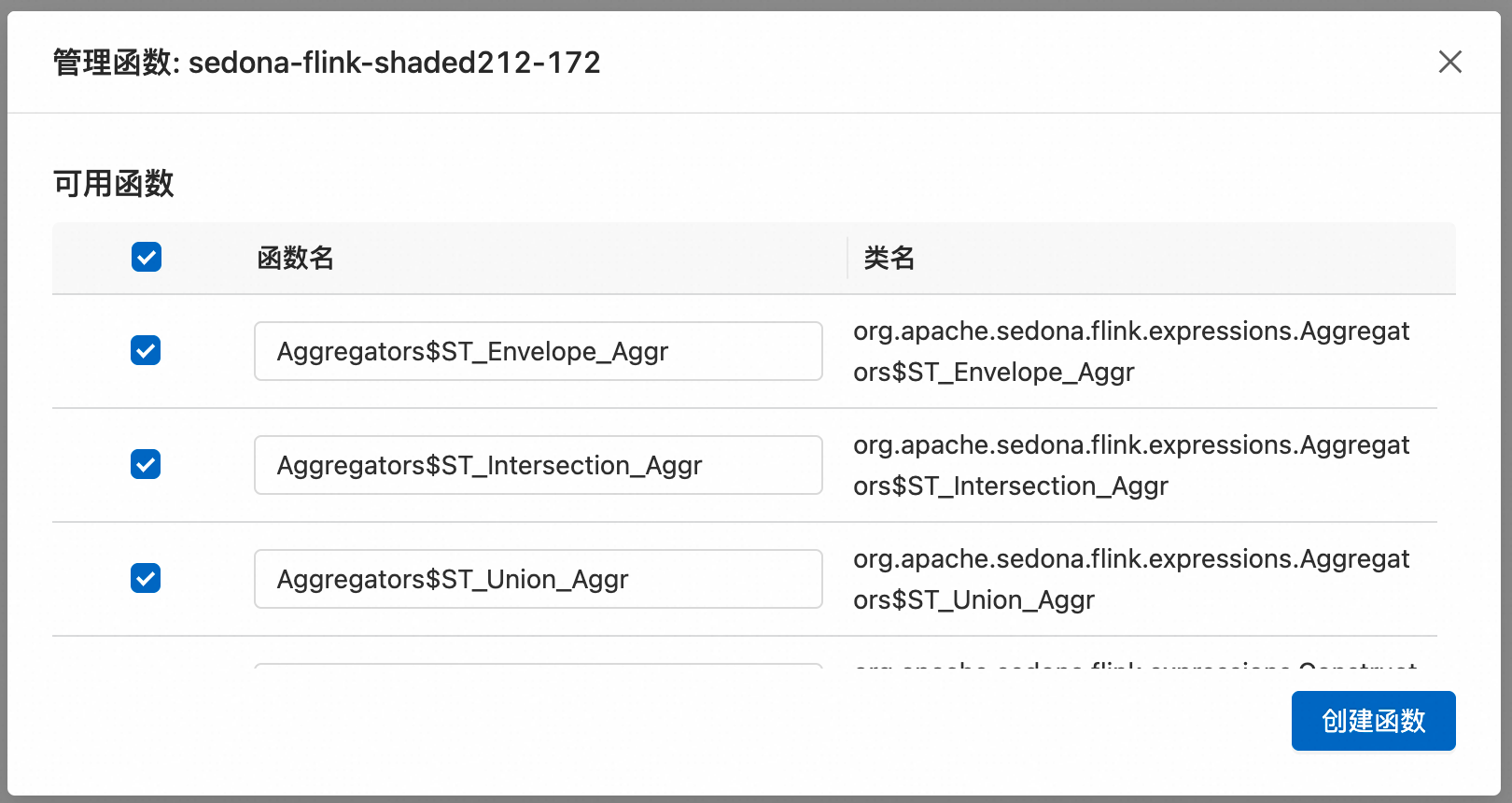
实时计算Flink版自动提取函数名时,对于属于内部类的UDF实现类,默认会包含其外部类名作为前缀,如上图所示,您可以根据需求保持默认函数名或手动修改函数名。
注册完毕后,您可以在数据开发>ETL>函数列表中,查看已注册的所有函数。
3.编写作业并注册序列化器
在数据开发>ETL>作业草稿页面新建空白的流作业草稿,并编写您的作业逻辑。
务必在作业开头配置参数pipeline.default-kryo-serializers来注册专用序列化器,示例如下。相比于不启用,其序列化开销节省约2/3。参数说明请参考pipeline.default-kryo-serializers。
SET 'pipeline.default-kryo-serializers' = 'class:org.locationtech.jts.geom.Geometry,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Point,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.LineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Polygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiPoint,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiLineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiPolygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.GeometryCollection,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.apache.sedona.common.geometryObjects.Circle,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Envelope,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.index.quadtree.Quadtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde;class:org.locationtech.jts.index.strtree.STRtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde';实时计算Flink版提供了一份编写好的实时交通密度分析SQL查询如下。
-- =============================================================================
-- 0. 注册专用序列化器
-- =============================================================================
SET 'pipeline.default-kryo-serializers' = 'class:org.locationtech.jts.geom.Geometry,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Point,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.LineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Polygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiPoint,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiLineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.MultiPolygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.GeometryCollection,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.apache.sedona.common.geometryObjects.Circle,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.geom.Envelope,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;class:org.locationtech.jts.index.quadtree.Quadtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde;class:org.locationtech.jts.index.strtree.STRtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde';
-- =============================================================================
-- 1. 定义数据源表
-- =============================================================================
-- 创建一个临时表来模拟持续产生的载具位置数据流
CREATE TEMPORARY TABLE vehicle_positions (
`vehicle_id` STRING,
`lon` DOUBLE,
`lat` DOUBLE,
`event_time` TIMESTAMP_LTZ(3),
WATERMARK FOR `event_time` AS `event_time` - INTERVAL '2' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.vehicle_id.length' = '5',
'fields.lon.min' = '116.3',
'fields.lon.max' = '116.5',
'fields.lat.min' = '39.85',
'fields.lat.max' = '40.0'
);
-- =============================================================================
-- 2. 定义数据汇表
-- =============================================================================
-- 创建一个临时表,用于将最终的聚合结果打印到控制台
CREATE TEMPORARY TABLE print_sink (
`area_name` STRING,
`vehicle_count` BIGINT,
`window_end` TIMESTAMP(3)
) WITH (
'connector' = 'print',
'print-identifier' = 'AREA_STATS_SQL'
);
-- =============================================================================
-- 3. 核心ETL逻辑
-- =============================================================================
-- 对每个区域和每个窗口内的载具ID进行去重计数
INSERT INTO print_sink
SELECT
F.area_name,
COUNT(DISTINCT V.vehicle_id) AS vehicle_count,
V.window_end
FROM
TABLE(TUMBLE(TABLE vehicle_positions, DESCRIPTOR(event_time), INTERVAL '10' SECOND)) AS V
-- 区域范围
INNER JOIN (
VALUES
('area_01', 'West District', 'POLYGON((116.30 39.90, 116.40 39.90, 116.40 39.95, 116.30 39.95, 116.30 39.90))'),
('area_02', 'East District', 'POLYGON((116.41 39.90, 116.48 39.90, 116.48 39.95, 116.41 39.95, 116.41 39.90))')
)
AS F(area_id, area_name, wkt_polygon)
-- 关联条件为载具是否在划定区域内
ON Predicates$ST_Contains(Constructors$ST_GeomFromWKT(F.wkt_polygon), Constructors$ST_Point(V.lon, V.lat))
GROUP BY
V.window_start,
V.window_end,
F.area_id,
F.area_name;4.部署作业
在SQL编辑界面,点击右上角部署。
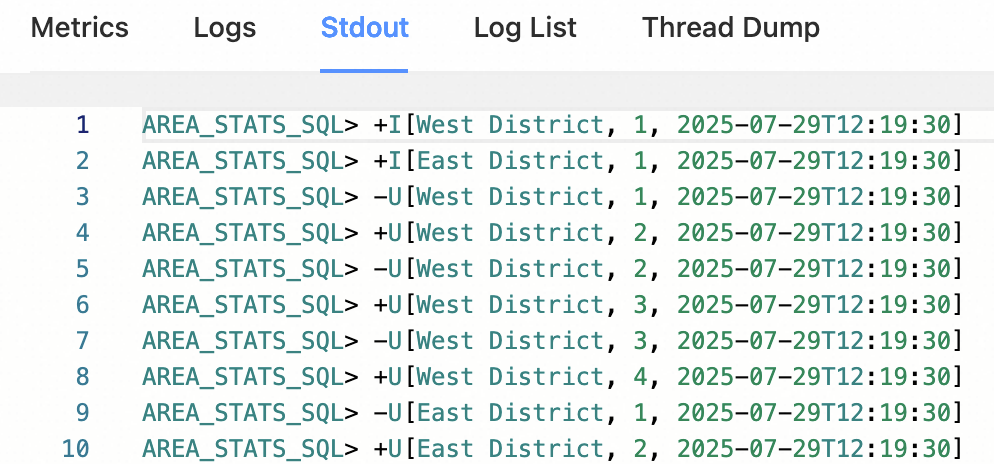
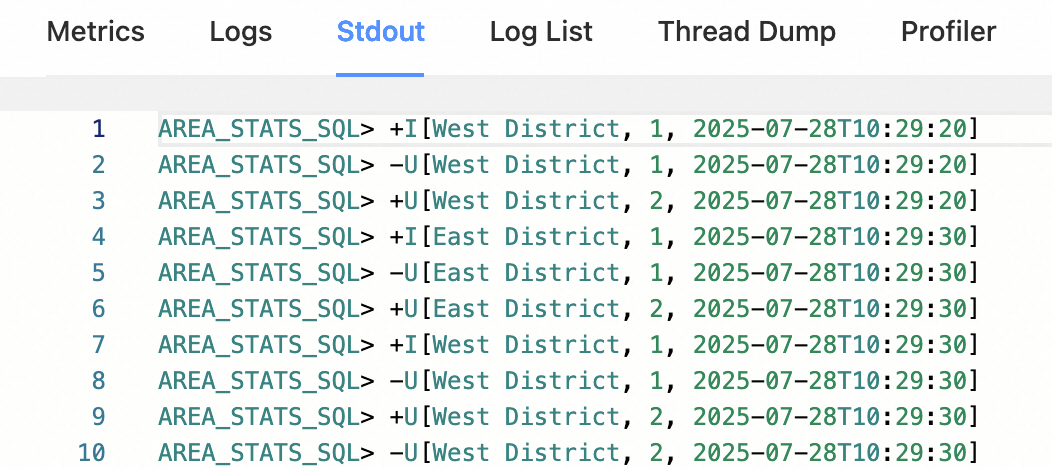
对于上一节提供的SQL查询,部署并启动后您可以在Flink Web UI>Task Manager>Stdout页面看到输出,如下所示。
JAR作业
本节将会介绍如何编写一个简易的实时交通密度分析JAR作业,并部署至实时计算Flink版。
1.添加依赖
若使用Sedona 1.7.2版本,可以参照文档,添加如下依赖。
<dependency>
<groupId>org.apache.sedona</groupId>
<artifactId>sedona-flink-shaded_2.12</artifactId>
<version>1.7.2</version>
</dependency>
<!-- Optional: https://mvnrepository.com/artifact/org.datasyslab/geotools-wrapper -->
<dependency>
<groupId>org.datasyslab</groupId>
<artifactId>geotools-wrapper</artifactId>
<version>1.7.2-28.5</version>
</dependency>2.初始化环境
在编写作业逻辑之前,通过以下代码注册Sedona的函数与序列化器。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 注册函数与序列化器
SedonaContext.create(env, tableEnv);如果您倾向于使用TableEnvironment的接口,可以通过以下代码手动注册,其功能与SedonaContext一致。
TableEnvironment tableEnv =
TableEnvironment.create(EnvironmentSettings.newInstance().build());
TelemetryCollector.send("flink", "java");
// 注册序列化器
tableEnv.getConfig()
.set(
PipelineOptions.KRYO_DEFAULT_SERIALIZERS.key(),
"class:org.locationtech.jts.geom.Geometry,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.Point,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.LineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.Polygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.MultiPoint,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.MultiLineString,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.MultiPolygon,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.GeometryCollection,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.apache.sedona.common.geometryObjects.Circle,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.geom.Envelope,serializer:org.apache.sedona.common.geometrySerde.GeometrySerde;"
+ "class:org.locationtech.jts.index.quadtree.Quadtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde;"
+ "class:org.locationtech.jts.index.strtree.STRtree,serializer:org.apache.sedona.common.geometrySerde.SpatialIndexSerde");
// 注册函数
Arrays.stream(Catalog.getFuncs())
.forEach(
(func) -> {
tableEnv.createTemporarySystemFunction(
func.getClass().getSimpleName(), func);
});
Arrays.stream(Catalog.getPredicates())
.forEach(
(func) -> {
tableEnv.createTemporarySystemFunction(
func.getClass().getSimpleName(), func);
});3.编写作业并打包
编写您的作业逻辑并打包为JAR包。
实时计算Flink版提供了一份编写好的实时交通密度分析作业代码FlinkSedonaExample.zip及其JAR包FlinkSedonaExample-1.0-SNAPSHOT.jar作为参考,代码基于实时计算Flink版引擎VVR 8.0.11版本,对应Apache Flink版本1.17.2。
4.部署作业
在实时计算控制台上部署您的JAR作业,部署入口位于运维中心>作业运维>部署作业>JAR作业。
对于上一节提供的JAR包,部署并启动后您可以在Flink Web UI>Task Manager>Stdout页面看到输出,如下图所示。