本文档提供实时计算 Flink 的关键告警指标、告警配置建议及运维实践示例,帮助您更好地监控系统性能并进行故障诊断。
前提条件
请参见配置监控告警,根据您工作空间使用的监控服务类型,选择相应配置方式。
ARMS的多指标监控只能通过自定义PromQL支持,如果需要简易化配置,仍可以通过云监控进行告警配置。
推荐告警规则配置
场景 | 组合指标/事件名称 | 规则配置 | 级别 | 处理动作 |
作业运行状态事件 | = FAILED(事件告警) | P0 | ①检查重启策略是否配置不当(建议使用默认配置)。 ②定位是重启策略导致,还是 JobManager/TaskManager 异常导致。 ③从最近的快照/成功的Checkpoint 恢复生产。 | |
Overview/作业每分钟错误恢复次数 | ≥ 1 连续 1 个周期 | P0 | ①定位问题
②从最近的快照/成功的Checkpoint 恢复生产。 | |
Checkpoint 成功次数(5 min 累计) | ≤ 0 连续 1 周期 | P0 | ①参阅系统检查点排查checkpoint失败根本原因。 ②定位问题
③动态更新配置或从最近成功的Checkpoint恢复生产。 | |
Overview/业务延时 && 每秒Source端输入记录数 | 最大值延时≥180000 输入记录数≥0 连续 3 个周期 | P1 | ①参阅监控指标说明排查延迟原因。
②根据具体原因调整
| |
Overview/每秒Source端输入记录数 && 源端未处理数据时间 | 输入记录数≤0(业务而定) 最大值未处理时间≥60000 持续 5 个周期 | P1 | ①可查看taskmanager.log、火焰图、上游服务指标等。确认问题是上游无数据/限流/异常,还是线程栈卡死。 ②根据具体原因调整
| |
Overview/每秒输出到Sink端记录数 | ≤ 0 连续 5 个周期 | P1 | ①确认数据是否抵达 Sink 算子
②确认 Sink 是否能写入外部系统
③临时双写降级,将数据写入备用存储。 | |
CPU/ 单个TM 的CPU利用率 | ≥ 85 % 连续 10 周期 | P2 | ①看火焰图或Flink UI定位热点算子。
②适当增加瓶颈算子的并行度,或为TaskManager分配更多CPU Core。 | |
TM的堆内存已使用 | ≥ 90 % 连续 10 周期 | P2 | ①查看 GC 日志定位问题。
②根据具体原因调整:增加Heap或调大并行度降低单槽数据量。 |
作业可用性
作业失败告警
开发控制台(ARMS)
登录实时计算控制台,单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
单击告警配置页签。
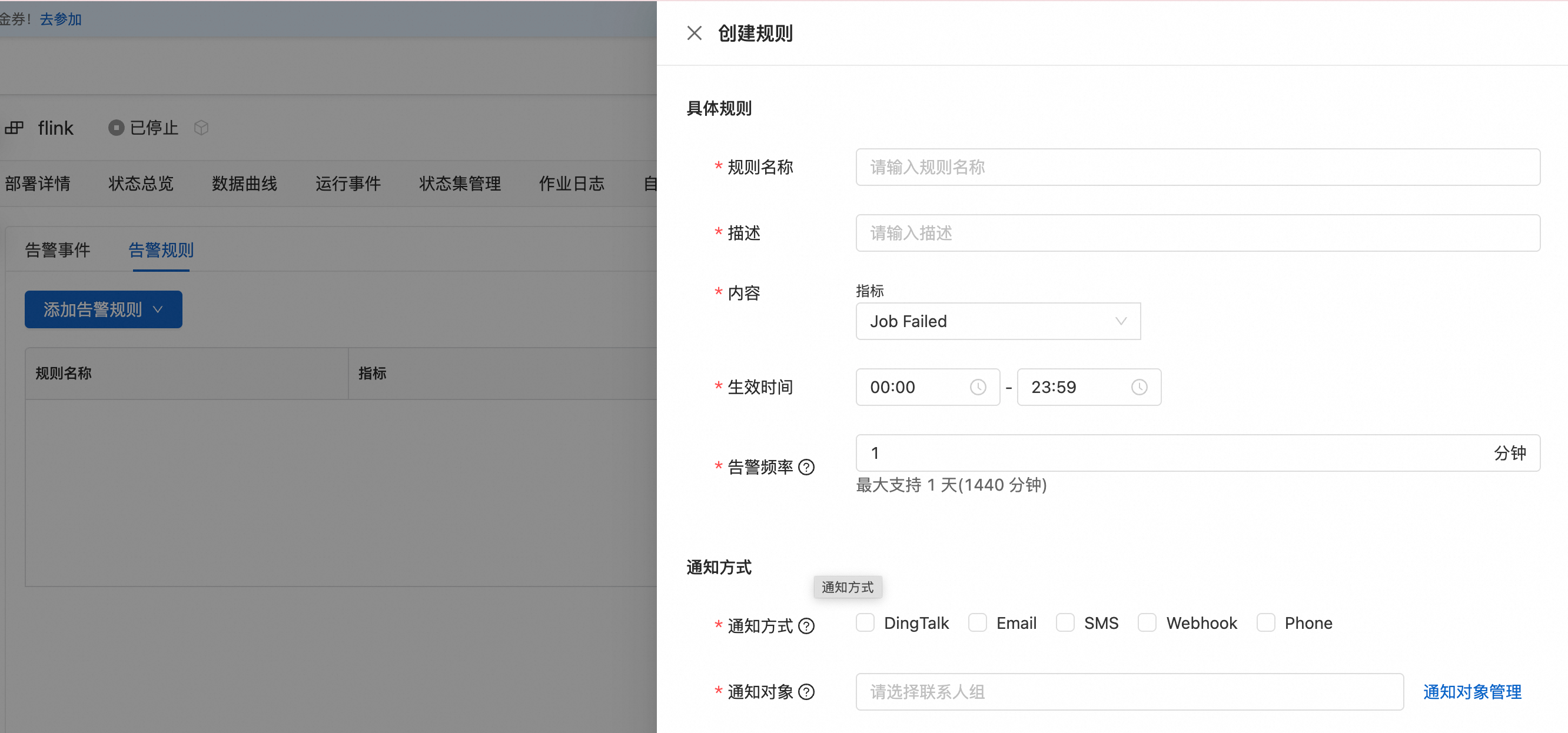
云监控
登录云监控控制。
在左侧导航栏,选择。
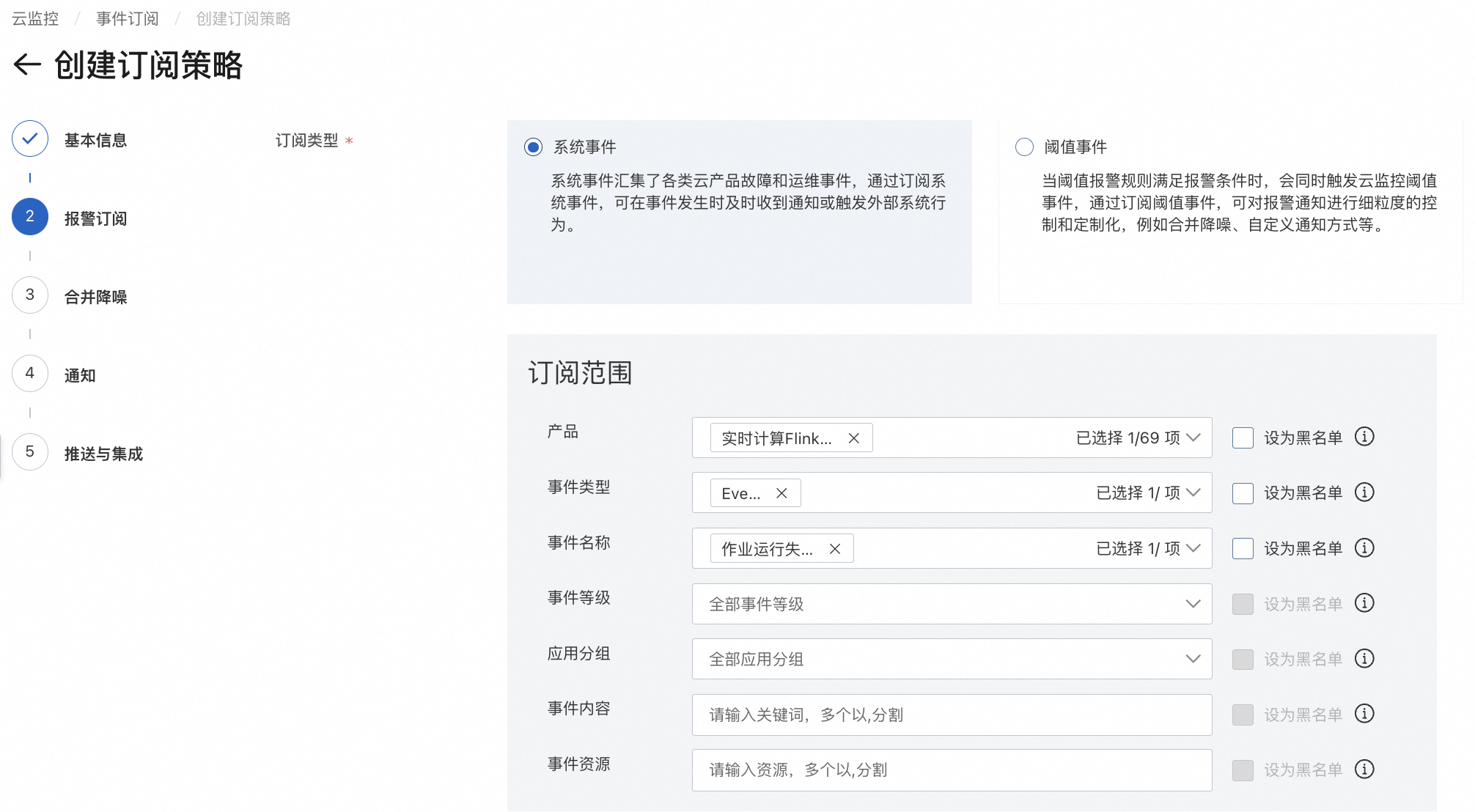
在订阅策略页签,单击创建订阅策略。
在创建订阅策略页面,配置相关参数,参数详情请参见管理事件订阅(推荐)。
作业稳定性
防止 JobManager 频繁重启
指标:
作业每分钟错误恢复次数规则:1 分钟内作业重启报警
配置建议:
作业每分钟错误恢复次数监控值 >= 1
时间周期:1分钟
通知:电话+短信+邮件+WebHook(Critical)
Checkpoint 成功率保障
指标:
每分钟完成checkpoint数量规则:Checkpoint5分钟无成功报警
配置建议:
每分钟完成checkpoint数量监控值 <= 0
时间周期:5分钟
通知:电话+短信+邮件+WebHook(Critical)
数据实时性
保障 SLA 延迟
指标:
业务延时每秒Source端输入记录数
规则:有数据流入且业务延时超过5分钟则告警(阈值和报警级别可根据业务调整)
配置建议:
业务延时最大值 >= 300000
每秒Source端输入记录数监控值 > 0
时间周期:5分钟
上游数据流中断检测
指标:
每秒Source端输入记录数源端未处理数据的时间
规则:有数据流入且业务延时超过5分钟则告警(阈值和报警级别可根据业务调整)
配置建议:
每秒Source端输入记录数监控值 <= 0
源端未处理数据的时间最大值 > 60000
时间周期:5分钟
下游数据无输出检测
指标:
每秒输出到Sink端记录数规则:无数据输出超过5分钟则告警(阈值和报警级别可根据业务调整)
配置建议:
每秒输出到Sink端记录数监控值 <= 0
时间周期:5分钟
资源性能瓶颈
CPU性能瓶颈
指标:
单个TM CPU的利用率规则:CPU使用率大于85%超过10分钟则告警
配置建议:
单个TM CPU的利用率最大值 >= 85
时间周期:10分钟
内存性能瓶颈
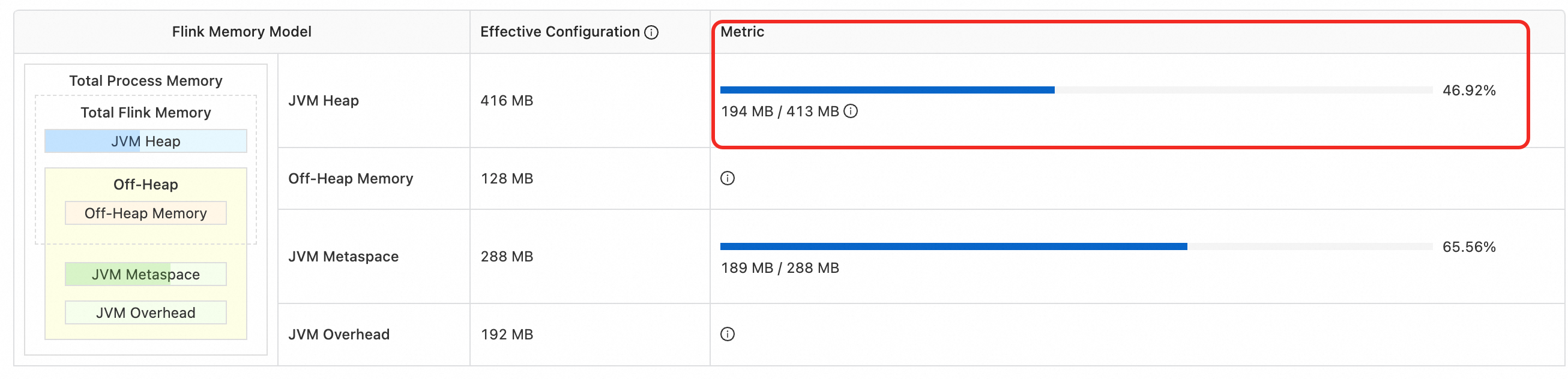
指标:TM的堆内存已使用
规则:堆内存使用率大于90%超过10分钟则告警
配置建议:
TM的堆内存已使用最大值 >= 阈值(90%)
该阈值可在中查看,如图 194 MB / 413 MB。可以设置阈值为372 MB。
时间周期:10分钟