
本文为您介绍在源端表结构变更、数据逻辑增强(注入元数据/计算列/逻辑删除)、异构路由(分表合并、整库同步)及精准管控(表过滤、时间戳启动)等复杂业务场景下使用Flink CDC数据摄入作业的最佳实践。
同步新增表
在Flink CDC数据摄入作业中,支持两种情况下的新增表:
增量空表热同步:新增表无历史数据(仅包含后续变更),作业无需重启即可动态捕获。
带历史数据表同步:新增表已存在历史数据,需全量+增量同步且重启作业生效
热同步新增空表,不存在历史数据
Flink CDC作业通过开启scan.binlog.newly-added-table.enabled参数,可在不重启的情况下实时同步增量阶段新创建的无历史数据空表。建议配置,无需重启作业。
当Flink CDC数据摄入作业正在同步MySQL dlf_test库中的所有表时,源库新建了无历史数据的空表products,只需在作业中启用scan.binlog.newly-added-table.enabled: true参数配置,即可实现不重启作业同步新增表。请参考如下配置:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步增量阶段新创建的表的数据
scan.binlog.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true这样配置的CDC YAML作业运行后会自动在目标端创建dlf_test数据库下的全部新增表。
带历史数据表同步
假设MySQL数据库中已存在表customers和products,但是启动时只需要同步customers表,作业配置如下:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.customers
server-id: 8601-8604
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true作业运行一段时间后,如果需要额外同步该数据库下全部的表和历史数据,需要重启作业,按照如下步骤操作:
保留Savepoint停止作业。
修改MySQL数据源tables配置为需要匹配的表,同时MySQL数据源去掉
scan.binlog.newly-added-table.enabled参数并开启scan.newly-added-table.enabled。
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true从保留的Savepoint重启作业。
不支持同时开启scan.binlog.newly-added-table.enabled和scan.newly-added-table.enabled。
排除指定表
在Flink CDC数据摄入作业中,支持对某些表进行过滤以避免在下游对这些表进行创建和数据同步。
例如MySQL数据库dlf_test中有customers和products等多张表,但是您希望排除名为products_tmp的表,作业需要如下配置:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
#(可选)排除某些不希望同步的表
tables.exclude: dlf_test.products_tmp
server-id: 8601-8604
#(可选)同步增量阶段新创建的表的数据
scan.binlog.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true启用此配置的Flink CDC数据摄入作业将自动在目标端动态创建dlf_test库下所有表(排除products_tmp表),实时保持表结构与数据同步。
tables.exclude参数支持通过正则匹配多张表。如果 tables.exclude排除的表与tables需要同步的表存在重叠,这些重叠的表将被排除,最终不会被同步。请确保两个参数配置的表集的交集被正确处理。
元数据列与计算列增强
添加元数据列
写入数据时,可以使用transform模块添加元数据列到数据中。例如如下的作业配置,可以将表名、操作时间和类型写入到下游表数据中,详情请见Transform模块。
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
# 将操作时间作为元数据
metadata-column.include-list: op_ts
transform:
- source-table: dlf_test.customers
projection: __schema_name__ || '.' || __table_name__ as identifier, op_ts, __data_event_type__ as op, *
#(可选)修改主键
primary-keys: id,identifier
description: add identifier, op_ts and op
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true使用MySQL作为Source时,需要添加metadata-column.include-list: op_ts才会将操作时间作为元数据发送到下游。详情请参见MySQL。
数据摄入作业的源表包含完整的变更类型,如果希望写入的下游表为将删除操作转化为插入操作实现逻辑删除的功能,您可以在transform模块中添加converter-after-transform: SOFT_DELETE配置以实现该需求。
添加计算列
写入数据时,可以使用transform模块添加计算列到数据中。例如如下的作业配置,通过对created_at字段进行转换生成dt字段,并作为下游表的分区字段。
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
# 将操作时间作为元数据
metadata-column.include-list: op_ts
transform:
- source-table: dlf_test.customers
projection: DATE_FORMAT(created_at, 'yyyyMMdd') as dt, *
#(可选)设置分区字段
partition-keys: dt
description: add dt
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true使用MySQL作为Source时,需要添加metadata-column.include-list: op_ts才会将操作时间作为元数据发送到下游。详情请参见MySQL。
表名映射
在将上游表同步到下游表的过程中,您可能还有使用route模块对表名进行替换的需求,下面两种列出了对表名进行替换的典型场景和Flink CDC数据摄入作业配置案例。
分库分表合并
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
route:
# 将dlf_test库下所有以product_开头和数字结尾作为表名的表合并到dlf.products中
- source-table: dlf_test.product_[0-9]+
sink-table: dlf.products
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true整库同步
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
route:
# 统一修改表名,将dlf_test库下所有表同步到dlf库中以ods_加源表表名作为表名的表中
- source-table: dlf_test.\.*
sink-table: dlf.ods_<>
replace-symbol: <>
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true构建复杂业务综合案例
下面的Flink CDC数据摄入作业展示了一个综合使用上述功能构建复杂业务的案例,您可以基于此代码进行适当调整实现业务需求。
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
#(可选)排除某些不希望同步的表
tables.exclude: dlf_test.products_tmp
server-id: 8601-8604
#(可选)同步新增表的全量和增量数据
scan.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
# 将操作时间作为元数据
metadata-column.include-list: op_ts
transform:
- source-table: dlf_test.customers
projection: __schema_name__ || '.' || __table_name__ as identifier, op_ts, __data_event_type__ as op, DATE_FORMAT(created_at, 'yyyyMMdd') as dt, *
#(可选)修改主键
primary-keys: id,identifier
#(可选)设置分区字段
partition-keys: dt
#(可选)将删除的数据会转化为插入
converter-after-transform: SOFT_DELETE
route:
# 将dlf_test库下所有表同步到dlf库中以ods_加源表表名作为表名的表中
- source-table: dlf_test.\.*
sink-table: dlf.ods_<>
replace-symbol: <>
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true指定时间戳启动
在无状态启动Flink CDC数据摄入作业时,支持指定数据源的开始时间,帮助您从指定的Binlog位置恢复数据的读取。
运维页面配置
在作业运维页面,在点选作业无状态启动时可以指定源表开始时间。
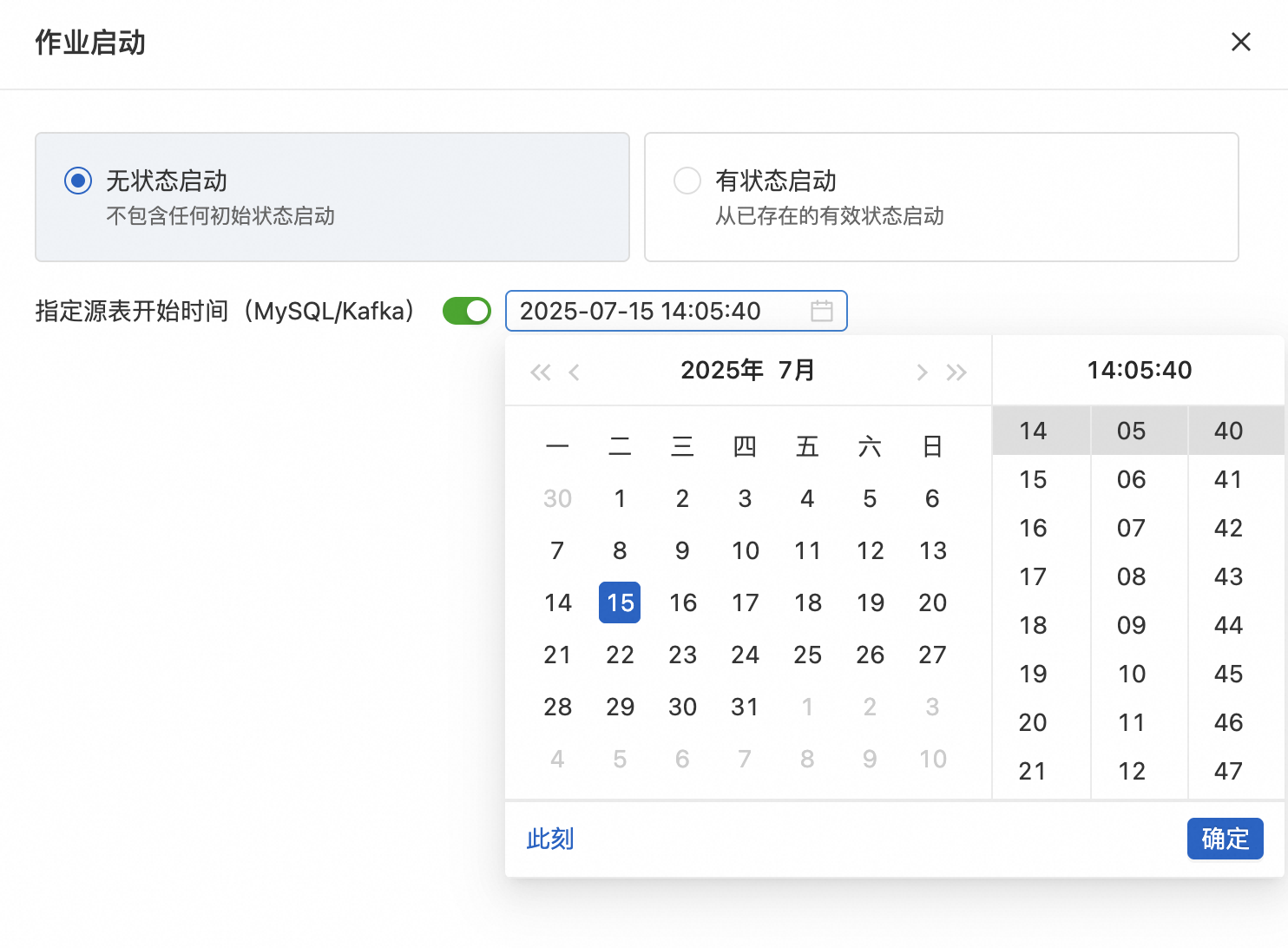
作业参数配置
在作业草稿中,可以通过配置参数指定源表开始时间。
以MySQL Source为例,您可以在作业配置中设置scan.startup.mode: timestamp以指定源表开始时间,作业配置示例如下:
source:
type: mysql
name: MySQL Source
hostname: localhost
port: 3306
username: username
password: password
tables: dlf_test.\.*
server-id: 8601-8604
#(可选)以指定源表开始时间模式启动
scan.startup.mode: timestamp
# 在时间戳启动模式下指定启动时间戳
scan.startup.timestamp-millis: 1667232000000
#(可选)同步增量阶段新创建的表的数据
scan.binlog.newly-added-table.enabled: true
#(可选)同步表注释和字段注释
include-comments.enabled: true
#(可选)优先分发无界的分片以避免可能出现的TaskManager OutOfMemory问题
scan.incremental.snapshot.unbounded-chunk-first.enabled: true
#(可选)开启解析过滤,加速读取
scan.only.deserialize.captured.tables.changelog.enabled: true
sink:
type: paimon
catalog.properties.metastore: rest
catalog.properties.uri: dlf_uri
catalog.properties.warehouse: your_warehouse
catalog.properties.token.provider: dlf
#(可选)提交用户名,建议为不同作业设置不同的提交用户以避免冲突
commit.user: your_job_name
#(可选)开启删除向量,提升读取性能
table.properties.deletion-vectors.enabled: true指定源表启动时间优先级:运维界面配置 > 作业参数配置。