
阿里云流存储Fluss版是基于 Apache Fluss (Incubating) 打造的高性能列式流存储系统,具备毫秒级读写响应、实时数据更新及部分字段更新能力。同时Fluss 提供 CDC(变更数据捕获)日志订阅功能,保障全量与增量数据的一致性读取,满足实时数据消费场景需求。
前置概念
阅读本文前,可以按需了解基础概念:
什么是Apache Paimon?
什么是数据湖?
产品概述
阿里云流存储Fluss版的“湖流一体”架构,实现与Apache Paimon等数据湖格式的无缝对接,在确保数据高时效性的基础上,显著降低实时数仓的构建与运维成本。通过统一的数据流与湖仓协同机制,Fluss助力企业打破数据孤岛,加速湖上数据价值的深度挖掘与高效共享。
能力特点 | 说明 |
毫秒级流读流写 | Fluss 支持低延迟的流式读写能力,结合 Apache Flink 可构建高吞吐、低延迟的实时数仓,适用于各类实时数据处理场景。 |
流式查询下推 | Fluss 底层采用Apache Arrow列存格式,支持列裁剪、分区下推、条件下推、聚合下推等查询加速能力,显著降低 I/O 开销,查询性能提升可达 10 倍。 |
CDC日志订阅与全增量一致性 | Fluss 内置变更数据捕获(CDC)机制,支持 Binlog 实时订阅,保障全量与增量数据的一致性读取。在实时数仓中可实现去重更新、分层治理与端到端低延迟的数据加工。 |
部分列更新 | Fluss 支持主键粒度的部分列更新,实现多流数据的实时拼接,避免传统双流 Join 的大状态问题。即使在 Partial Update 场景下,仍可生成完整 Binlog,确保全链路实时化。 |
Delta Join | 基于 Fluss 的流读能力和索引点查能力,构建的 Delta Join 方案可替代传统双流 Join,显著降低内存和 CPU 使用率。实测生产环境下,Flink 内存与 CPU 消耗下降超 86%,Checkpoint 耗时从 90s 缩短至 1s。 |
二级索引与 KV 点查 | Fluss 支持二级索引构建,提供高效的 Key-Value 点查能力,用户可直接对 DWD/DWS 层数据进行排查与验证,无需导出至其他系统。 |
冷热数据分层与湖流一体化 | Fluss 支持冷热数据自动分层存储,兼顾性能与成本。同时无缝对接 Apache Paimon 等湖格式,实现湖流数据统一管理与共享,提升实时数仓性价比。 |
产品架构
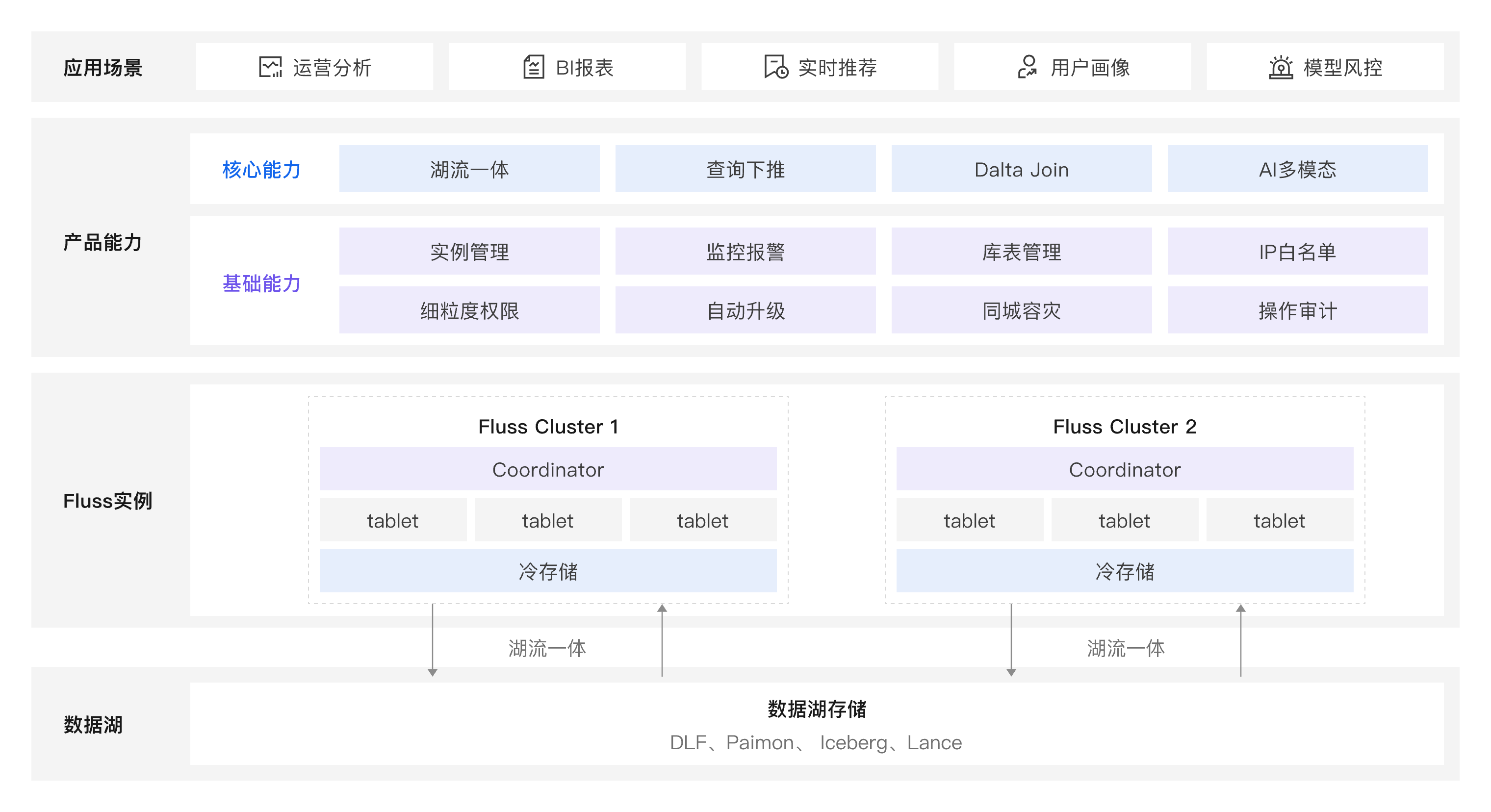
1. 湖流一体架构
特点:
以数据湖为底层存储,实现历史数据的低成本持久化,同时依托湖生态提供高效的批式查询与分析能力。
内置流式入湖能力,支持流数据实时写入并立即可见,无需依赖外部数据集成工具。
支持数据在流存储与数据湖之间的智能分层管理,查询与消费时自动合并多层数据,提供统一访问视图。
采用开源开放架构,兼容主流湖格式(如 DLF、Paimon、Iceberg、Lance)和查询引擎(如 Flink、Spark、StarRocks),支持灵活扩展。
优势:
流批一体架构 :统一支持流处理与批处理,降低系统架构复杂度与运维成本。
数据统一存储 :流与湖共享同一份数据副本,避免重复存储,显著降低总体存储成本。
统一数据治理 :提供统一的权限控制与元数据管理,简化数据治理流程,保障数据安全与一致性。
2. 分布式集群架构
结构:
每个 Fluss Cluster 包含一个 Coordinator 和多个 TabletServer 节点。
Coordinator 负责元数据管理、任务调度和全局协调。
TabletServer 节点负责实际的数据存储、计算和查询执行。
优势:
高可用性:通过多副本备份机制和分布式节点设计,确保数据的高可靠性和高可用性。
可扩展性:支持按需增加 TabletServer 或集群,满足业务增长需求。
冷存储层用于长期归档,减少热数据存储成本。
3. 强大的多能力支撑
核心能力
湖流一体
实现数据湖与流处理的深度融合,支持实时数据处理和历史数据分析。
流式查询下推
将列裁剪、分区裁剪等查询逻辑下推到 TabletServer 层执行,减少数据传输,提升流式查询性能。
Delta Join
支持流式数据与静态数据的高效关联分析,适用于实时推荐、用户画像等场景。
实时更新与点查
支持百万级QPS实时更新、部分列更新、维表点查,支持实时生成 CDC 变更日志,无缝集成 Flink 构建全链路实时数仓。
基础能力
监控报警
实时监控系统运行状态,提供告警机制,确保问题及时发现和处理。
库表管理
支持对数据库和表的创建、修改、删除等操作,方便数据管理和权限控制。
同城容灾
提供同城备份和容灾能力,确保数据安全性和业务连续性。
自动升级
支持在线升级,减少停机时间,保障服务的持续可用性。
产品优势
流批一体秒级湖仓方案
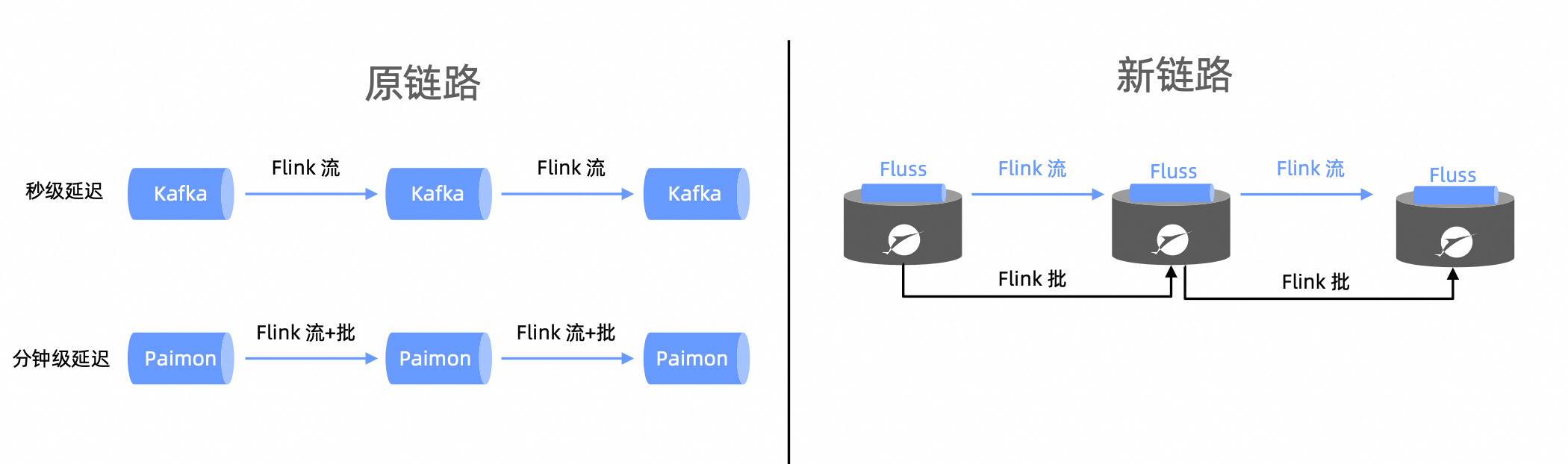
Fluss 的设计理念旨在帮助企业解决实时数据处理中的痛点,提升数据价值挖掘效率,具体体现在以下方面:
实时性与低延迟
Fluss 支持毫秒级读写,结合 Flink 等流式计算引擎,构建高吞吐、低延迟的实时数仓,满足金融交易、电商推荐等对时效性要求极高的场景。
成本优化
冷热分层存储策略显著降低存储成本,同时湖流一体架构减少了数据冗余与重复计算,整体 TCO 最优。
数据分析效率提升
查询下推、Delta Join 等技术大幅提高查询性能,缩短数据加工链路,加速业务洞察。
数据治理与安全性
统一的数据管理平台,支持多租户隔离、权限管控与操作审计,确保数据安全合规。
灵活扩展性
支持按需弹性伸缩,轻松应对业务高峰期或突发流量,无需担心资源瓶颈。