本文将为您介绍Delta Join的用法与实现。
Delta Join:基于Fluss的双流Join新方案
在实时数仓场景下,往往需要依赖多张实时数据表来构建统一的宽表。基于开源Flink + Kafka搭建的实时数仓,只能使用多个Kafka的Topic通过Flink Join拼接形成一张大宽表,来实现无论哪个Topic发生更新时,总能对整个宽表完成更新。
由于Kafka本身并非面向分析场景设计,因此只能依托开源Flink的流式Join来实现这个场景,因为需要双边驱动更新,并在缓存全量上游数据,会导致开源Flink状态体积庞大,带来资源成本高、运维复杂、效率低等问题。
Fluss对比Kafka实现了Delta Join的能力。这是一种新型的 Join 方案,能够在保持双流 Join 语义的同时,将数据更新行为下沉到Fluss表中完成,从而显著降低Flink的资源消耗,提升作业的稳定性和执行效率。
Delta Join的优势
无 Join State:省去冗余数据存储。
低成本:仅依赖 Fluss 主键表和二级索引。
更稳定高效 :避免大状态带来的性能瓶颈。

Delta Join使用限制
左右表必须为 Fluss 的主键表(支持分区表)。
Fluss 主键表的分桶键(Bucket Key)需要为主键(Primary Key)前缀。
Delta Join 的 Join Key 必须包含 Fluss 主键表定义的分桶键(Bucket Key),如果是分区表,则 Join Key 还需要包含分区键(Partition Key)。
说明例如定义:
PRIMARY KEY (user_id, order_id, order_data),且'bucket.key' = 'user_id'。Bucket key是主键的前缀,因此现在用户可以把
user_id当作二级索引进行高效的数据查找。对于查询:
JOIN users u ON o.user_id = u.user_id;此时Join Key为
user_id,包含了定义的分桶键,因此该查询会被优化成 Delta Join。
使用示例
创建表
CREATE TABLE `fluss-catalog`.`my_db`.`orders` (
user_id BIGINT,
order_date DATE,
order_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY (user_id, order_id, order_date) NOT ENFORCED
) WITH (
'bucket.key' = 'user_id, order_id'
);
CREATE TABLE `fluss-catalog`.`my_db`.`order_enhance` (
user_id BIGINT,
order_id BIGINT,
risk_level TINYINT,
is_fraud BOOLEAN,
update_time TIMESTAMP(3),
PRIMARY KEY (user_id, order_id) NOT ENFORCED
) WITH (
'bucket.key' = 'user_id, order_id'
);SQL作业
对于 Delta Join,其作业写法和 Inner Join 一致, 对于符合前提要求的SQL作业会自动生成使用Delta Join大的查询计划。
-- join key 为两张表对应的 bucket key
SELECT * FROM `fluss-catalog`.`my_db`.`orders` o
INNER JOIN `fluss-catalog`.`my_db`.`order_enhance` e
ON o.user_id = e.user_id AND o.order_id = e.order_id;还可以通过 hint options 调整 fluss 的部分参数,提高 prefixLookup 的性能。
参数 | 类型 | 默认值 | 说明 |
client.lookup.queue-size | Integer | 25600 | Pending状态的Lookup 操作数量上限 |
client.lookup.max-batch-size | Integer | 128 | 单个Lookup请求中合并攒批的Lookup操作数上限 |
client.lookup.max-inflight-requests | Integer | 128 | 未响应确认的Lookup请求数上限 |
client.lookup.batch-timeout | Duration | 100ms | Lookup操作攒批的超时时间上限,当攒批数量满或触发超时时间,将结束攒批并发送Lookup请求。 |
使用示例:例如把client.lookup.queue-size设置为 2560。
-- join key 为两张表对应的 bucket key
SELECT * FROM `fluss-catalog`.`my_db`.`orders` o /*+ OPTIONS('client.lookup.queue-size'='2560') */
INNER JOIN `fluss-catalog`.`my_db`.`order_enhance` e /*+ OPTIONS('client.lookup.queue-size'='2560') */
ON o.user_id = e.user_id AND o.order_id = e.order_id;作业上线
部署作业后,还需要添加额外的配置才能开启Delta Join。
在作业运维页,单击相应作业。
在中填写如下参数。
# 以下为默认建议值 table.exec.delta-join.cache-enabled: 'true' table.exec.async-lookup.buffer-capacity: '3000' table.optimizer.delta-join.strategy: FORCE table.exec.delta-join.left.cache-size: '100' table.exec.delta-join.right.cache-size: '1000'参数名
默认值
说明
table.optimizer.delta-join.strategy
AUTO
是否开启 Delta Join 优化。可以设置为 AUTO, FORCE 或者 NONE。
推荐设置为 FORCE,在无法优化为Delta Join的场景显式报错,方便查看原因。
table.exec.async-lookup.buffer-capacity
100
Delta Join 节点最多支持的异步请求数量。
如果Fluss集群压力和Delta Join内存压力都不大,可以设置高一些。
推荐设置到 “千” 及以上级别。
table.exec.delta-join.cache-enabled
false
是否开启本地内存的缓存。开启后可以减少请求 Fluss 的请求数。
在内存压力不大的情况下,推荐设置为true。
table.exec.delta-join.left.cache-size
10000
左表可放入内存的缓存 key 数量,可减少对左Fluss表的请求数量。
仅当table.exec.delta-join.cache-enabled 为 true 时生效。
该参数会占用一部分内存,因此配置该参数时,需要结合每条数据大小、TM内存大小、右表可能的热点数据量来综合考虑。
在内存压力不大的情况下,可以先用默认值试一下。GC 频繁时适量减小。Fluss集群点查压力大时,适量增大。
table.exec.delta-join.right.cache-size
10000
右表可放入内存的缓存 key 数量,可减少对右Fluss表的请求数量。
仅当table.exec.delta-join.cache-enabled 为 true 时生效。
该参数会占用一部分内存,因此配置该参数时,需要结合每条数据大小、TM内存大小、左表可能的热点数据量来综合考虑。
在内存压力不大的情况下,可以先用默认值试一下。GC 频繁时适量减小。Fluss集群点查压力大时,适量增大。
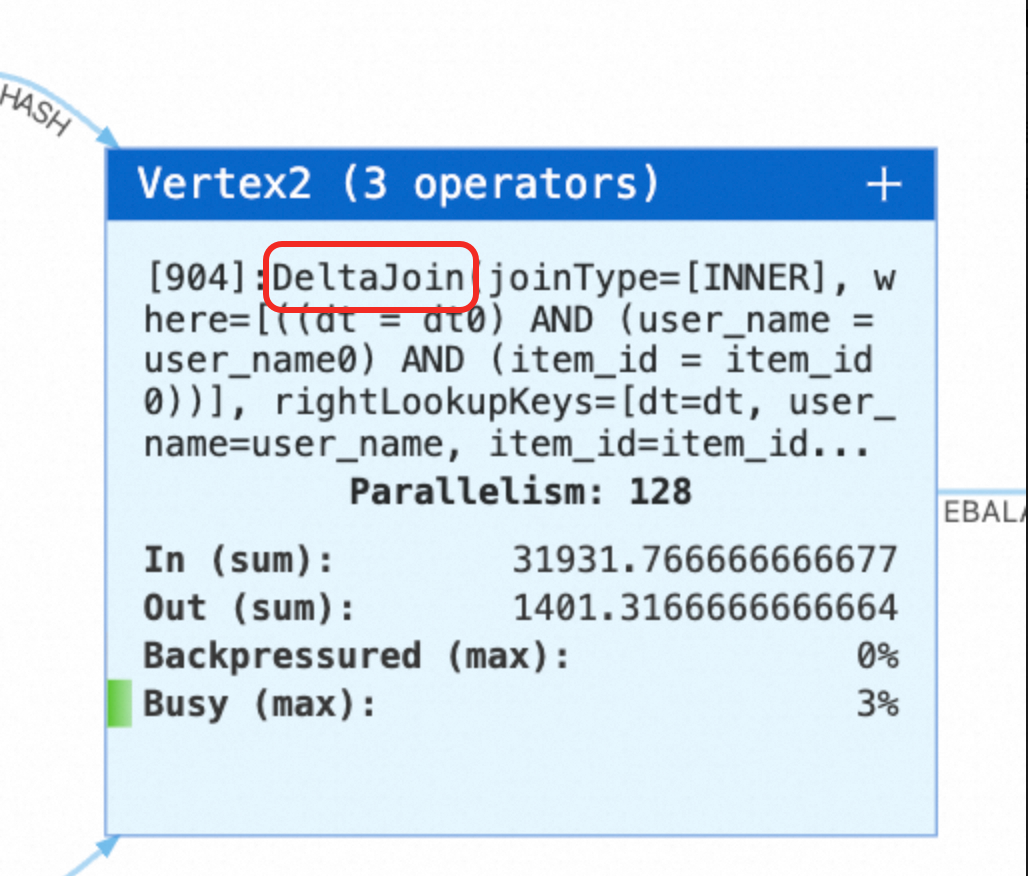
保存参数配置,运行作业后,在状态总览页,看到 Delta Join 节点,则表示 Inner Join 变更为 Delta Join 成功。