
本文为您介绍实时计算Flink版的作业运行异常问题。
作业启动不起来,应该如何排查?
问题现象
单击启动按钮后,作业状态从启动中等待一段时间后转为已失败。
解决方案
在运行事件页签,单击左侧
 展开详情,根据报错信息定位报错原因。
展开详情,根据报错信息定位报错原因。在作业日志页签的启动日志中,查看是否存在异常信息,根据异常信息排查。
如果JobManager启动成功,可以在作业日志的JobManager日志中查看详细JobManager或TaskManager日志。
常见报错
报错详情
原因
解决方案
ERROR:exceeded quota: resourcequota当前资源队列剩余资源不足。
对当前资源队列进行资源变配或降低作业启动资源。
ERROR:the vswitch ip is not enough当前项目空间剩余的IP数小于启动作业产生的TM数。
减少并发、合理配置槽位(slots),或对工作空间虚拟交换机进行修改。
ERROR: pooler: ***: authentication failed代码中填写的AccessKey不正确或者没权限。
输入正确且有权限的AccessKey。
页面右侧出现数据库链接错误弹窗,该如何排查?
问题详情
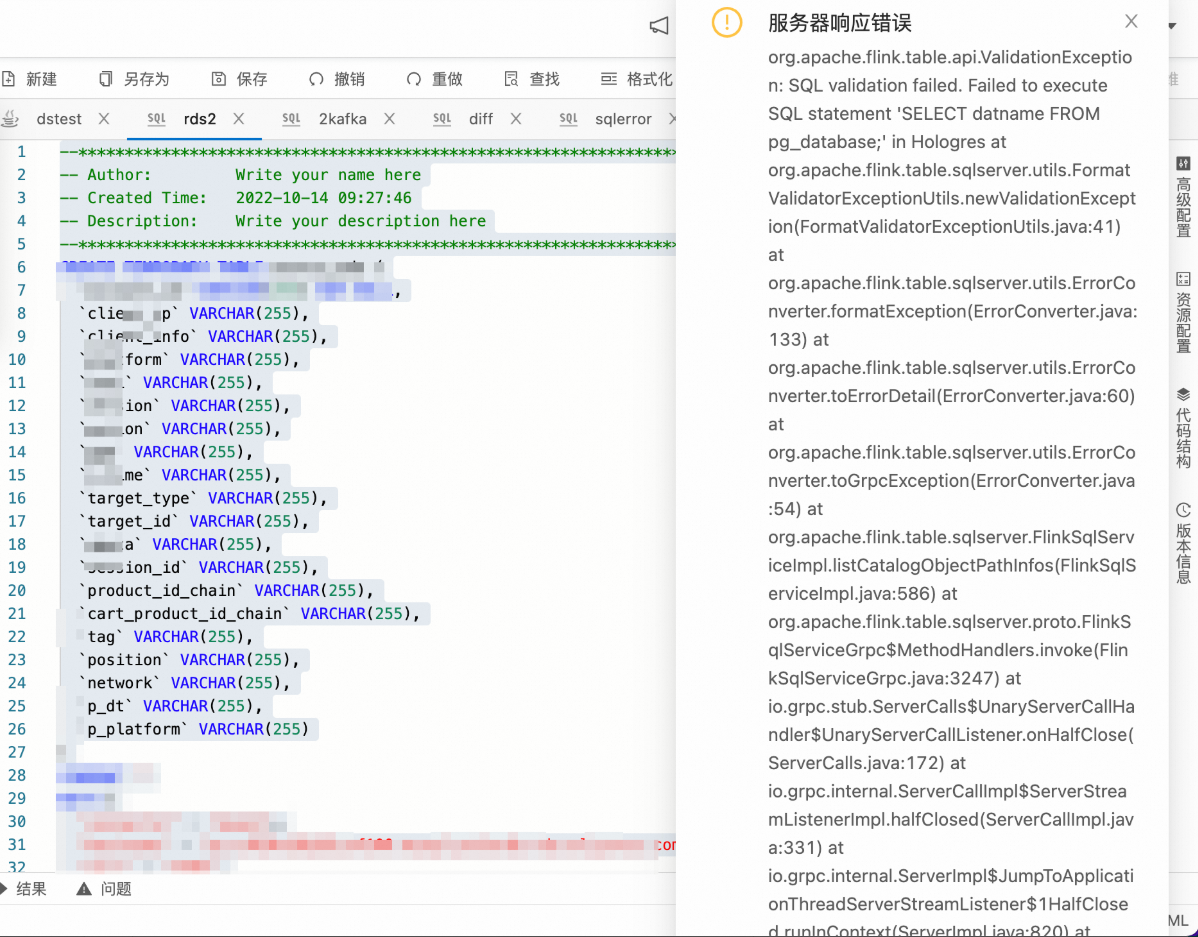
问题原因
已注册的Catalog失效无法正确连接。
解决方案
在数据管理页面查看所有的Catalog,将显示为灰色的Catalog删除后重新注册对应的Catalog。
作业运行后,链路中的数据不产生消费,应该如何排查?
网络连通性排查
如果发生上下游组件没有生产和消费情况,首先在启动日志页面查找是否有报错信息,如果有TimeOut类的报错,排查相应组件网络连接问题。
任务执行状态排查
在状态总览页面查看Source端是否发送数据,以及Sink端是否接收数据,以确定问题发生位置。

数据链路详细排查
在每个链路加print结果表来排查。
作业运行后出现重启,应该如何排查呢?
在对应作业的作业日志页签进行排查:
查看异常信息。
在异常信息页签,查看抛出的异常,根据异常信息进行排查。
查看JM和TM的日志。
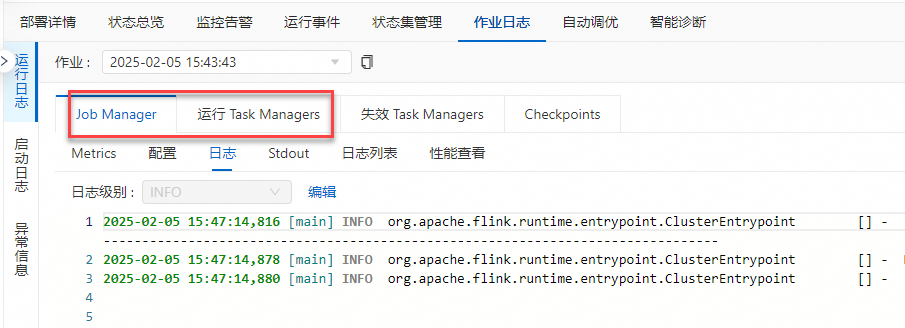
查看失效Task Manager日志。
有些异常可能会导致TM失败,而新调度的TM日志不全,可以查看上一个失效的TM日志进行排查。
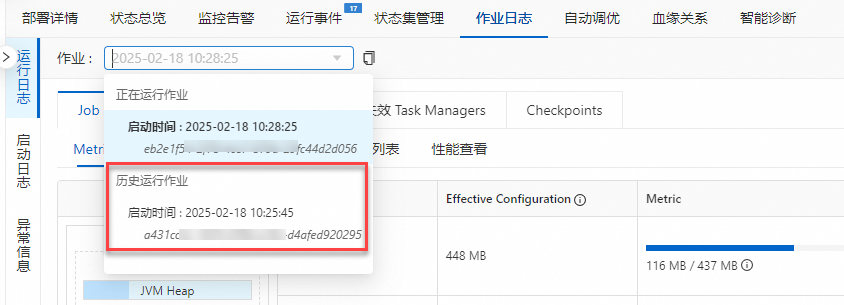
查看历史运行作业的日志。
选择当前作业的历史运行作业日志,查找作业失败的原因。

为什么数据在LocalGroupAggregate节点中长时间卡住,无输出?
作业代码
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as PROCTIME(), PRIMARY KEY (a) NOT ENFORCED ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random', 'fields.b.min'='0', 'fields.b.max'='10' ); CREATE TEMPORARY TABLE sink ( a BIGINT, b BIGINT ) WITH ( 'connector'='print' ); CREATE TEMPORARY VIEW window_view AS SELECT window_start, window_end, a, sum(b) as b_sum FROM TABLE(TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '2' SECONDS)) GROUP BY window_start, window_end, a; INSERT INTO sink SELECT count(distinct a), b_sum FROM window_view GROUP BY b_sum;问题描述
LocalGroupAggregate节点中长时间卡住无数据输出,且无MiniBatchAssigner节点。
问题原因
在作业中同时包含WindowAggregate和GroupAggregate,且WindowAggregate的时间列为事件时间(proctime)时,如果
table.exec.mini-batch.size未配置或者设置为负值,MiniBatch处理模式会使用Managed Memory缓存数据,而且无法生成MiniBatchAssigner节点。因此计算节点无法收到MinibatchAssigner节点发送的Watermark消息后触发计算和输出,只能在三种条件(Managed Memory已满、进行Checkpoint前和作业停止时)之一触发计算和输出,详情请参见table.exec.mini-batch.size。如果此时Checkpoint间隔设置过大,就会导致数据积攒在LocalGroupAggregate节点中,长时间无法输出。
解决方案
调小Checkpoint间隔,让LocalGroupAggregate节点在执行Checkpoint前自动触发输出。Checkpoint间隔时间设置详情请参见Tuning Checkpoint。
通过Heap Memory来缓存数据,让LocalGroupAggregate节点内缓存数据达到N条时自动触发输出。即设置
table.exec.mini-batch.size参数为正值N,参数配置详情请参见如何配置自定义的作业运行参数?

上游连接器单partition无数据进入,导致Watermark无法推进、窗口输出延迟,如何解决?
以Kafka为例,上游有5个partition,每分钟有2条新数据进入,但是并不是每个partition都是实时有数据进入的,当源端在超时时间内没有收到任何元素时,它将被标记为暂时空闲。Watermark无法推进,窗口无法及时结束,结果不能实时输出。
此时,您需要设置一个过期时间来表明这个Partition无数据了,使得在计算Watermark时将其排除在外,等有数据后再将其列入计算Watermark的范畴。详情请参见Configuration。
在其他配置中添加如下代码信息,具体操作请参见如何配置自定义的作业运行参数?。
table.exec.source.idle-timeout: 1sJobManager没有运行起来,如何快速定位问题?
JobManager没有运行起来则无法进入Flink UI页面。此时,您可以通过以下操作进行问题定位:
在页面,单击目标作业名称。
单击运行事件页签。
通过快捷键搜索error,获取异常信息。
Windows系统:Ctrl+F
Mac系统:Command+F
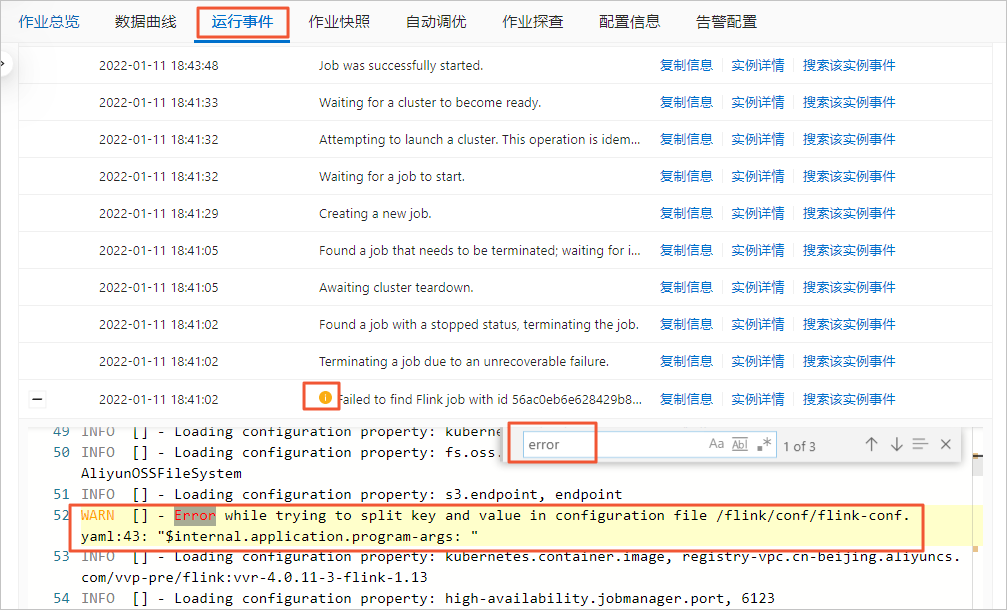
INFO:org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss
报错详情
报错原因
存储类型为OSS Bucket,OSS每次创建新目录时,会先检查是否存在该目录,如果不存在,就会报这个INFO信息,但该INFO信息不影响Flink作业运行。
解决方案
在日志模板中添加
<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>。详情请参见配置作业日志输出。

报错:akka.pattern.AskTimeoutException
报错原因
因为JobManager或TaskManager的内存不足导致持续GC,从而导致JM和TM之间的心跳和RPC请求超时。
因为作业规模较大,即RPC请求量较大,但JM资源不足,从而导致RPC请求积压,因此导致JM和TM之间的心跳和RPC请求超时。
因为作业超时参数值设置过小,当第三方产品连接失败时,系统会进行多次重试,导致在超时前未能抛出连接失败的错误。
解决方案
如果是持续GC导致的报错,则建议通过作业内存情况和GC日志确认GC的耗时和频率,如果确实存在高频GC或GC耗时的问题,则需要增加JM和TM内存。
如果是作业规模较大导致的报错,则建议增加JM的CPU和内存资源,同时调大
akka.ask.timeout和heartbeat.timeout参数取值。重要建议只在大规模作业上调整以上两个参数,小规模作业通常不是由于该配置较小导致。
建议按需设置该参数,因为该参数调整过大,会导致在TaskManager异常退出时,作业恢复的时间变长。
如果连接失败是由第三方产品连接失败导致的超时,请先调大以下四个参数的值,让第三方报错抛出来,然后解决第三方报错。
client.timeout:默认值为60 s,推荐值为600 s。akka.ask.timeout:默认值为10 s,推荐值为600 s。client.heartbeat.timeout:默认值为180000 s,推荐值为600000 s。填写时请确保取值不带单位,否则可能导致启动报错。例如,您可以直接填写为client.heartbeat.timeout: 600000。heartbeat.timeout:默认值为50000 ms。推荐值为600000 ms。填写时请确保取值不带单位,否则可能导致启动报错。例如,您可以直接填写为heartbeat.timeout: 600000。
例如
Caused by: java.sql.SQLTransientConnectionException: connection-pool-xxx.mysql.rds.aliyuncs.com:3306 - Connection is not available, request timed out after 30000ms,说明MySQL连接池已满,需要调大MySQL WITH参数中的connection.pool.size值(默认值为20)。说明您可以根据超时报错提示确定以上参数调整的最小值,例如
pattern.AskTimeoutException: Ask timed out on [Actor[akka://flink/user/rpc/dispatcher_1#1064915964]] after [60000 ms].中的60000 ms是目前client.timeout的值。
报错:Task did not exit gracefully within 180 + seconds.
报错详情
Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852861506+08:00 stdout F org.apache.flink.util.FlinkRuntimeException: Task did not exit gracefully within 180 + seconds. 2022-04-22T17:32:25.852865065+08:00 stdout F at org.apache.flink.runtime.taskmanager.Task$TaskCancelerWatchDog.run(Task.java:1709) [flink-dist_2.11-1.12-vvr-3.0.4-SNAPSHOT.jar:1.12-vvr-3.0.4-SNAPSHOT] 2022-04-22T17:32:25.852867996+08:00 stdout F at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102] log_level:ERROR报错原因
该报错不是作业异常的根因。因为Task退出的超时
task.cancellation.timeout参数的默认值为180 s,当作业Failover或退出过程中,可能会因某种原因阻塞Task的退出。当阻塞时间达到超时时间后,Flink会判定该Task已卡死无法恢复,主动停止该Task所在的TaskManager,让Failover或退出流程继续下去,所以在日志中会出现这样的报错。真正的原因可能是您自定义函数的实现有问题,例如close方法的实现中长时间阻塞或者计算方法长时间未返回等。
解决方案
设置Task退出的超时时间参数
task.cancellation.timeout取值为0,配置方法请参见如何配置自定义的作业运行参数?配置为0时,Task退出阻塞将不会超时,该Task会持续等待退出完成。重启作业后再次发现作业在Failover或退出过程中长时间阻塞时,需要找到处于Cancelling状态的Task,查看该Task的栈,排查问题的根因,然后根据排查到的根因再针对性解决问题。重要task.cancellation.timeout参数用于作业调试,请不要在生产作业上配置该参数值为0。
报错: Can not retract a non-existent record. This should never happen.
报错详情
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen. at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:196) at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:55) at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:135) at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:106) at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:424) at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204) at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:685) at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:640) at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:651) at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:624) at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:799) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:586) at java.lang.Thread.run(Thread.java:877)报错原因及解决方案
场景
原因
解决方案
场景1
由代码中
now()导致。因为TopN不支持非确定性的字段作为排序字段(ORDER BY)或分组字段(PARTITION BY),
now()每次输出的值不同,所以导致Retraction无法找到之前的值。使用源表中定义的只会产生确定性值的字段作为排序字段(ORDER BY)和分组字段(PARTITION BY)。
场景2
table.exec.state.ttl参数值设置过小,State因过期被清理,retract时找不到对应keystate。调大
table.exec.state.ttl参数值。配置方法请参见如何配置自定义的作业运行参数?。
报错:The GRPC call timed out in sqlserver
报错详情
org.apache.flink.table.sqlserver.utils.ExecutionTimeoutException: The GRPC call timed out in sqlserver, please check the thread stacktrace for root cause: Thread name: sqlserver-operation-pool-thread-4, thread state: TIMED_WAITING, thread stacktrace: at java.lang.Thread.sleep0(Native Method) at java.lang.Thread.sleep(Thread.java:360) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.processWaitTimeAndRetryInfo(RetryInvocationHandler.java:130) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:107) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy195.getFileInfo(Unknown Source) at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1661) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1577) at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1574) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1589) at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1683) at org.apache.flink.connectors.hive.HiveSourceFileEnumerator.getNumFiles(HiveSourceFileEnumerator.java:118) at org.apache.flink.connectors.hive.HiveTableSource.lambda$getDataStream$0(HiveTableSource.java:209) at org.apache.flink.connectors.hive.HiveTableSource$$Lambda$972/1139330351.get(Unknown Source) at org.apache.flink.connectors.hive.HiveParallelismInference.logRunningTime(HiveParallelismInference.java:118) at org.apache.flink.connectors.hive.HiveParallelismInference.infer(HiveParallelismInference.java:100) at org.apache.flink.connectors.hive.HiveTableSource.getDataStream(HiveTableSource.java:207) at org.apache.flink.connectors.hive.HiveTableSource$1.produceDataStream(HiveTableSource.java:123) at org.apache.flink.table.planner.plan.nodes.exec.common.CommonExecTableSourceScan.translateToPlanInternal(CommonExecTableSourceScan.java:127) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecExchange.translateToPlanInternal(StreamExecExchange.java:87) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecGroupAggregate.translateToPlanInternal(StreamExecGroupAggregate.java:148) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.plan.nodes.exec.ExecEdge.translateToPlan(ExecEdge.java:290) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.lambda$translateInputToPlan$5(ExecNodeBase.java:267) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase$$Lambda$949/77002396.apply(Unknown Source) at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193) at java.util.stream.ReferencePipeline$2$1.accept(ReferencePipeline.java:175) at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374) at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481) at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471) at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708) at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234) at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:268) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateInputToPlan(ExecNodeBase.java:241) at org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecSink.translateToPlanInternal(StreamExecSink.java:108) at org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase.translateToPlan(ExecNodeBase.java:226) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:74) at org.apache.flink.table.planner.delegation.StreamPlanner$$anonfun$1.apply(StreamPlanner.scala:73) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at scala.collection.IterableLike$class.foreach(IterableLike.scala:72) at scala.collection.AbstractIterable.foreach(Iterable.scala:54) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.AbstractTraversable.map(Traversable.scala:104) at org.apache.flink.table.planner.delegation.StreamPlanner.translateToPlan(StreamPlanner.scala:73) at org.apache.flink.table.planner.delegation.StreamExecutor.createStreamGraph(StreamExecutor.java:52) at org.apache.flink.table.planner.delegation.PlannerBase.createStreamGraph(PlannerBase.scala:610) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraphInternal(StreamPlanner.scala:166) at org.apache.flink.table.planner.delegation.StreamPlanner.explainExecNodeGraph(StreamPlanner.scala:159) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:304) at org.apache.flink.table.sqlserver.execution.OperationExecutorImpl.validate(OperationExecutorImpl.java:288) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$validate$22(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$394/1626790418.run(Unknown Source) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapClassLoader(DelegateOperationExecutor.java:250) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.lambda$wrapExecutor$26(DelegateOperationExecutor.java:275) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor$$Lambda$395/1157752141.run(Unknown Source) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:281) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:786) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834) Caused by: java.util.concurrent.TimeoutException at java.util.concurrent.FutureTask.get(FutureTask.java:205) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:277) ... 11 more报错原因
可能是SQL过于复杂而导致超时异常。
解决方案
在其他配置中添加如下代码,调大默认的120秒超时限制。具体操作请参见如何配置自定义的作业运行参数?。
flink.sqlserver.rpc.execution.timeout: 600s
报错:RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051
报错详情
Caused by: io.grpc.StatusRuntimeException: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051 at io.grpc.stub.ClientCalls.toStatusRuntimeException(ClientCalls.java:244) at io.grpc.stub.ClientCalls.getUnchecked(ClientCalls.java:225) at io.grpc.stub.ClientCalls.blockingUnaryCall(ClientCalls.java:142) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$FlinkSqlServiceBlockingStub.generateJobGraph(FlinkSqlServiceGrpc.java:2478) at org.apache.flink.table.sqlserver.api.client.FlinkSqlServerProtoClientImpl.generateJobGraph(FlinkSqlServerProtoClientImpl.java:456) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.lambda$generateJobGraph$25(ErrorHandlingProtoClient.java:251) at org.apache.flink.table.sqlserver.api.client.ErrorHandlingProtoClient.invokeRequest(ErrorHandlingProtoClient.java:335) ... 6 more Cause: RESOURCE_EXHAUSTED: gRPC message exceeds maximum size 41943040: 58384051)报错原因
由于作业逻辑非常复杂,因此生成的JobGraph过大,导致校验报错或启停卡住。
解决方案
在其他配置中添加如下代码,具体操作请参见如何配置自定义的作业运行参数?。
table.exec.operator-name.max-length: 1000
报错:Caused by: java.lang.NoSuchMethodError
报错详情
报错:Caused by: java.lang.NoSuchMethodError: org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery.getUpsertKeysInKeyGroupRange(Lorg/apache/calcite/rel/RelNode;[I)Ljava/util/Set报错原因
如果您依赖了社区的internal API,而这个internal API阿里云上的版本做了一些优化,可能会导致包冲突等异常。
解决方案
Flink源代码中只有明确标注了@Public或者@PublicEvolving的才是公开供您调用的方法,阿里云只对这些方法的兼容性做出产品保证。
报错:java.lang.ClassCastException: org.codehaus.janino.CompilerFactory cannot be cast to org.codehaus.commons.compiler.ICompilerFactory
报错详情
Causedby:java.lang.ClassCastException:org.codehaus.janino.CompilerFactorycannotbecasttoorg.codehaus.commons.compiler.ICompilerFactory atorg.codehaus.commons.compiler.CompilerFactoryFactory.getCompilerFactory(CompilerFactoryFactory.java:129) atorg.codehaus.commons.compiler.CompilerFactoryFactory.getDefaultCompilerFactory(CompilerFactoryFactory.java:79) atorg.apache.calcite.rel.metadata.JaninoRelMetadataProvider.compile(JaninoRelMetadataProvider.java:426) ...66more报错原因
JAR包中引入了会发生冲突的janino依赖。
UDF JAR或连接器JAR中,引入了以
Flink -开头的JAR。例如flink-table-planner和flink-table-runtime。
解决方案
分析JAR包里面是否含有org.codehaus.janino.CompilerFactory。因为在不同机器上的Class加载顺序不一样,所以有时候出现类冲突。该问题的解决步骤如下:
在页面,单击目标作业名称。
在部署详情页签,单击运行参数配置区域右侧的编辑。
在其他配置文本框,输入如下参数后,单击保存。
classloader.parent-first-patterns.additional: org.codehaus.janino其中,参数的value值需要替换为冲突的类。
Flink相关依赖,作用域请使用provided,即在依赖中添加
<scope>provided</scope>。主要包含org.apache.flink组下以flink-开头的非Connector依赖。